
David Silver 增强学习——Lecture 2 马尔可夫决策过程(二)

其他lecture
【1】 搬砖的旺财:David Silver 增强学习——笔记合集(持续更新)
目录
**David Silver 增强学习——Lecture 2 马尔可夫决策过程(一)**
1. 前言
----1.1 数学规范
----1.2 马尔可夫性
----1.3 状态转移矩阵
----1.4 片段(episode)
----1.5 马尔可夫过程(Markov Process,MP)
----1.6 马尔可夫链(Markov Chain)
----1.7 生成模式(Generating Patterns)
--------1.7.1 确定性模式(Deterministic Patterns):确定性系统
--------1.7.2 非确定性模式(Non-deterministic patterns):马尔可夫
--------1.7.3 隐藏模式(Hidden Patterns):隐马尔科夫
**David Silver 增强学习——Lecture 2 马尔可夫决策过程(二)**
2. 马尔科夫决策过程(Markov Decision Process,MDP)
----2.1 马尔科夫奖励过程(Markov Reward Process,MRP)
----2.2 举例说明收获和价值的计算
**David Silver 增强学习——Lecture 2 马尔可夫决策过程(三)**
----2.3 Bellman方程的矩阵形式和求解
**David Silver 增强学习——Lecture 2 马尔可夫决策过程(四)**
----2.4 马尔可夫决策过程(Markov Decision Processes,MDPs)
--------2.4.1 示例——学生MDP
--------2.4.2 策略(Policy)
--------2.4.3 基于策略 \pi 的价值函数
--------2.4.4 Bellman期望方程(Bellman Expectation Equation)
--------2.4.5 学生MDP示例
--------2.4.6 Bellman期望方程矩阵形式
--------2.4.7 最优价值函数
--------2.4.8、最优策略
--------2.4.9 寻找最优策略
**David Silver 增强学习——Lecture 2 马尔可夫决策过程(五)**
--------2.4.10 学生MDP最优策略示例
--------2.4.11 Bellman最优方程(Bellman Optimality Equation)
--------2.4.12 Bellman最优方程求解学生MDP示例
--------2.4.13 求解Bellman最优方程
3. 参考文献
2. 马尔科夫决策过程(Markov Decision Process,MDP)
MDP是对完全可观测(Fully observable)的环境进行描述的,也就是说观测到的状态内容完整地决定了决策需要的特征;几乎所有的强化学习问题都可以转化为MDP。
2.1 马尔科夫奖励过程(Markov Reward Process,MRP)
MRP是带有values的Markov Chain,是一个数组 \left\{ {\cal S},{\cal P},{\cal R},\gamma \right\}
\cal S 是有限的状态集
\cal P 是状态转移矩阵,{\cal P}_{ss^{'}}={\Bbb P}\left[ {S}_{t+1}=s^{'}|{S_t}=s \right]
\cal R 是奖励函数,标量,描述了在状态 s 的奖励,\mathop{\underline{{\cal R}_s}}\limits_{函数}={\Bbb E}\left[ \mathop{\underline{R_{t+1}}}_{具体的奖励值}|S_t=s \right]
\gamma 是衰减系数(Discount factor),并且 \gamma \in \left[ 0,1 \right] ,其中有数学表达的方便,避免陷入无限循环,远期利益具有一定的不确定性,符合人类对于眼前利益的追求,符合金融学上获得的利益能够产生新的利益因而更有价值等等; \gamma\rightarrow0 代表更青睐于当前的利益(“myopic” evaluation); \gamma\rightarrow1 代表更有远见(“far-sighted” evaluation)
G_{t} 是从时间序列 t 开始所有的折扣回报:
针对连续性任务而言, G_{t}=R_{t+1}+\gamma R_{t+2}+...=\sum_{k=0}^{\infty}{\gamma^{k}R_{t+k+1}}
针对片段性任务而言, G_{t}=R_{t+1}+\gamma R_{t+2}+...+\gamma^{T-t-1}R_T=\sum_{k=0}^{T-t-1}{\gamma^{k}R_{t+k+1}}
当然我们也可以将终止状态等价于自身转移概率为1,奖励为0的的状态,由此能够将片段性任务和连续性任务统一表达, G_{t}=\sum_{k=0}^{T-t-1}{\gamma^{k}R_{t+k+1}} 。
其中:
T\rightarrow \infty 表示连续性任务,否则为片段性任务。


(注:奖励是针对状态的,回报是针对片段的!)
状态价值函数 v(s) 是从状态 s 开始的期望回报: v\left( s \right)={\Bbb E}\left[ G_{t}|S_{t}=s \right]
值函数存在的意义:回报值是一次片段(or一次采样)的结果,存在很大的样本偏差;
回报值的角标是 t ,值函数关注的是状态 s ,所以又被称为状态价值函数。
状态价值函数可以被分解为两部分:立即回报 R_{t+1} 和后续状态的折扣值函数 \gamma v\left( S_{t+1} \right)
贝尔曼方程: \begin{align*} v\left( s \right) &={\Bbb E}\left[ G_{t}|S_{t}=s \right]\\ &={\Bbb E}\left[ R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+...|S_{t}=s \right]\\ &={\Bbb E}\left[ R_{t+1}+\gamma \left( R_{t+2}+\gamma R_{t+3}+... \right)|S_{t}=s \right]\\ &={\Bbb E}\left[ R_{t+1}+\gamma G_{t+1}|S_{t}=s \right]\\ &\left( 分别对R_{t+1}和G_{t+1}求期望,和的期望等于期望的和 \right)\\ &={\Bbb E}\left[ R_{t+1}+\gamma v\left( S_{t+1} \right)|S_{t}=s \right] \\&\left( 注意v\left( S_{t+1} \right)用大写的S_{t+1}是因为S_t=s后下一个状态是随机的 \right)\\ &\left( 如果我们已知转移矩阵{\cal P},则可将上式展开 \right)\\ &={\Bbb E}\left[ R_{t+1}|S_t=s \right]+\gamma {\Bbb E}\left[ v\left( S_{t+1} \right)|S_t=s \right]\\ &\left( 对随机变量求期望请参考下面的定义 \right)\\ &={\cal R}_{s}+\gamma \sum_{s'\in {\cal S}}{{\cal P}_{ss'}v\left( s' \right)}\\ \end{align*}
对于大范围MRPs,有许多迭代理论来计算状态价值函数,如动态规划、蒙特卡洛估计、时间差分学习。
附数学期望的定义:
离散型随机变量 X 有概率函数 P\left( X=x_k \right)=P_k\left( k=1,2,... \right) ,若级数 \sum_{k=1}^{\infty}{x_kp_k} 绝对收敛,则称这个级数为 X 的数学期望。
2.2 举例说明收获和价值的计算
下图是一个“马尔科夫奖励过程”图示的例子,在“马尔科夫过程”基础上增加了针对每一个状态的奖励,由于不涉及衰减系数相关的计算,这张图并没有特殊交代衰减系数值的大小。

为方便计算,把“学生马尔科夫奖励过程”示例图表示成下表的形式。表中第二行对应各状态的即时奖励值,中间区域数字为状态转移概率,表示为从所在行状态转移到所在列状态的概率:
{\begin{bmatrix} {States}&{C_1}&{C_2}&{C_3}&{Pass}&{Pub}&{FB}&{Sleep} \\ {Rewards}&{-2}&{-2}&{-2}&{10}&{1}&{-1}&{0}\\{C_1}&{}&{0.5}&{}&{}&{}&{0.5}&{}\\{C_2}&{}&{}&{0.8}&{}&{}&{}&{0.2}\\{C_3}&{}&{}&{}&{0.6}&{0.4}&{}&{}\\{Pass}&{}&{}&{}&{}&{}&{}&{1}\\{Pub}&{0.2}&{0.4}&{0.4}&{}&{}&{}&{}\\{FB}&{0.1}&{}&{}&{}&{}&{0.9}&{}\\{Sleep}&{}&{}&{}&{}&{}&{}&{1}\end{bmatrix}\quad}
考虑如下4个马尔科夫链。现计算当 \gamma=\frac{1}{2} 时,在 t=1 时刻 {S_1}={C_1} 时状态 S_1 的收获分别为:
(公式: G_1=R_2+\gamma R_3+...+\gamma^{T-2}R_T )
C1 - C2 - C3 - Pass - Sleep
v_1=(-2)+(-2)*\frac{1}{2}+(-2)*\left( {\frac{1}{2}} \right)^2+10*\left( {\frac{1}{2}} \right)^3=-2.25
C1 - FB - FB - C1 - C2 - Sleep v_1=(-2)+(-1)*\frac{1}{2}+(-1)*\left( {\frac{1}{2}} \right)^2+(-2)*\left( {\frac{1}{2}} \right)^3+(-2)*\left( {\frac{1}{2}} \right)^4=-3.125
C1 - C2 - C3 - Pub - C2 - C3 - Pass - Sleep v_1=(-2)+(-2)*\frac{1}{2}+(-2)*\left( {\frac{1}{2}} \right)^2+1*\left( {\frac{1}{2}} \right)^3+(-2)*\left( {\frac{1}{2}} \right)^4...=-3.41
C1 - FB - FB - C1 - C2 - C3 - Pub - C1 - FB - FB - FB - C1 - C2 - C3 - Pub - C2 - Sleep v_1=(-2)+(-1)*\frac{1}{2}+(-1)*\left( {\frac{1}{2}} \right)^2+(-2)*\left( {\frac{1}{2}} \right)^3+(-2)*\left( {\frac{1}{2}} \right)^4...=-3.20
由此可以理解到,虽然都是从相同的初始状态开始,但是不同的片段有不同的回报值,而值函数是它们的期望值。
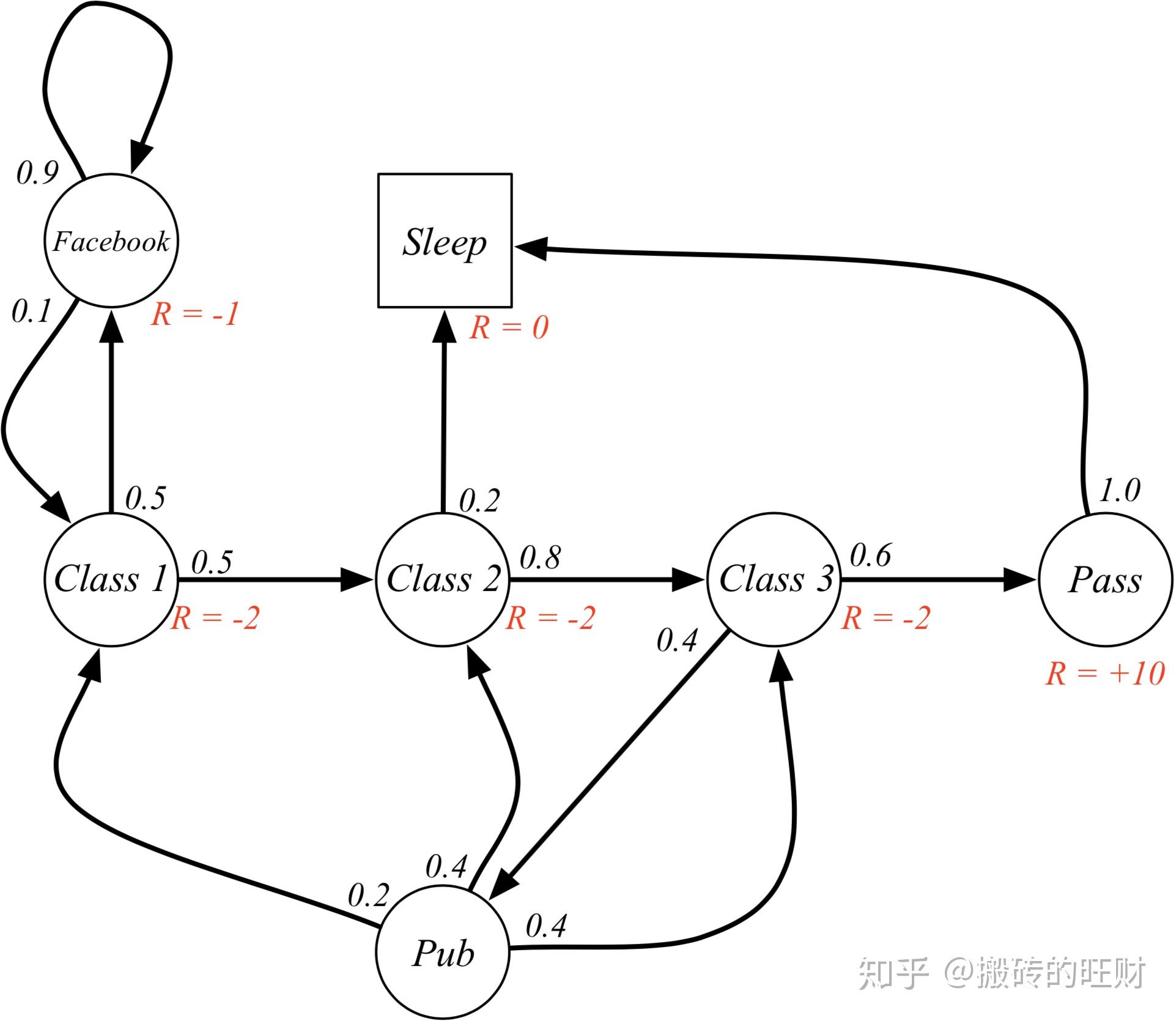
- 当\gamma=0 时,上表描述的MRP 中,各状态的即时奖励就与该状态的价值相同。
- 当 \gamma \neq 0 时,各状态的价值需要通过计算得到。各状态圈内的数字表示该状态的价值,圈外的 R=-2 等表示的是该状态的即时奖励。(推导价值函数的)
\gamma=0 各状态的价值(注:具体的求解过程请参考下文。)
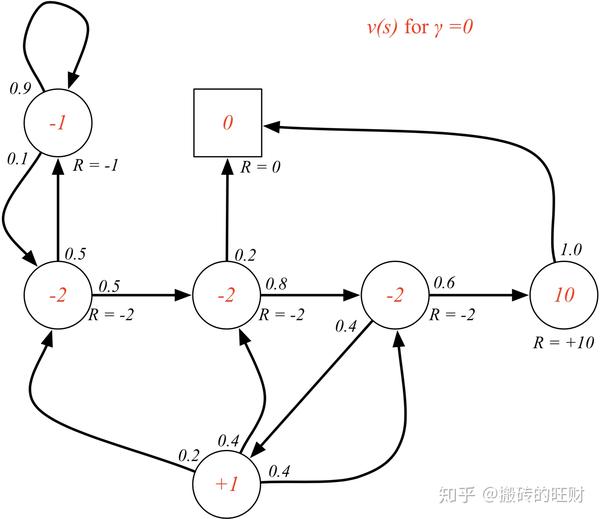

\gamma=0.9 各状态的价值(注:具体的求解过程请参考下文。)
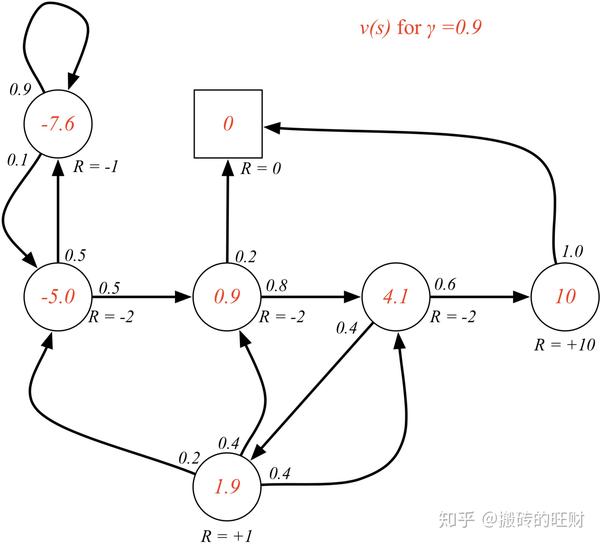

\gamma=1 各状态的价值

状态 C_3 的价值可以通过状态 Pub 和 Pass 的价值以及他们之间的状态转移概率来计算:
(公式: v\left( s \right)={\Bbb E}\left[ R_{t+1}+\gamma v\left( S_{t+1} \right)|S_{t}=s \right]={\cal R}_{s}+\gamma \sum_{s'\in {\cal S}}{{\cal P}_{ss'}v\left( s' \right)} )
v_{C3} = -2\left[ {\cal R}_{C_3} \right] + 1.0\left[ \gamma \right] *\left( 0.6\left[ {\cal P}_{{C_3}Pass} \right] * v_{Pass} + 0.4\left[ {\cal P}_{{C_3}Pub} \right] * v_{Pub}\right)
去掉注释:
v_{C3} = -2+ \left( 0.6*v_{Pass}+ 0.4* v_{Pub}\right)\Rightarrow -4.3=-2+\left( 0.6*10+0.4*0.8 \right)
(注:具体的求解过程请参考下文。)
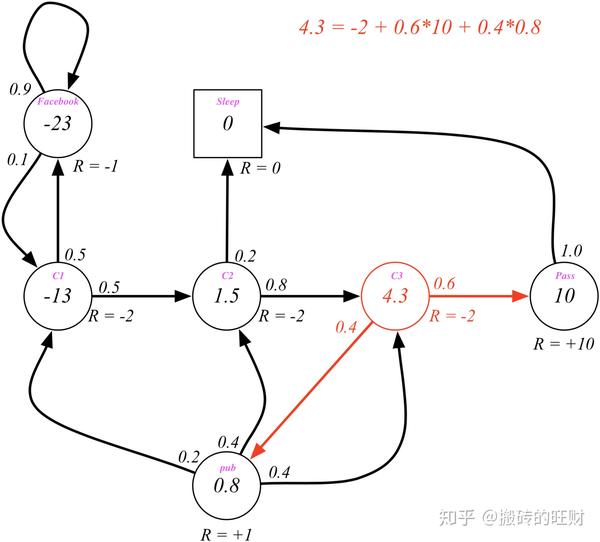

各状态价值的确定是很重要的,RL的许多问题可以归结为求状态的价值问题。因此如何求解各状态的价值,也就是寻找一个价值函数(从状态到价值的映射)就变得很重要了。
3. 参考文献
【1】 一个简单的马尔可夫过程例子
【2】 机器学习十大算法---10. 马尔科夫
【3】 《强化学习》第二讲 马尔科夫决策过程
【4】 深度增强学习David Silver(二)——马尔科夫决策过程MDP
【5】 马尔可夫决策过程MDP
【6】 强化学习(二):马尔科夫决策过程(Markov decision process)
【7】 马尔可夫过程
【8】 3 有限马尔可夫决策过程(Finite Markov Decision Processes)
【9】 强化学习(二)马尔科夫决策过程(MDP)
【10】 matlab奇异矩阵如何处理?
【11】 Total Expected Discounted Reward MDPs : Existence of Optimal Policies
请大家批评指正,谢谢 ~
文章被以下专栏收录
