首发于 菜菜编程
切换模式
java爬虫爬取小说

学习
学生
首先要介绍这个小说网站
输入一个小说名


返回小说列表


然后根据选择的对用小说,得到章节目录列表。


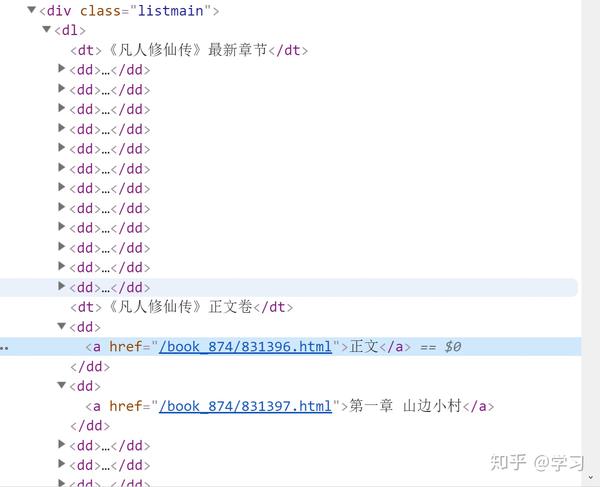
然后根据隐藏在html中的href,爬取具体小说内容。

介绍一下开发环境
Maven项目
依赖
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.httpcomponents/httpclient -->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/net.sourceforge.htmlcleaner/htmlcleaner -->
<dependency>
<groupId>net.sourceforge.htmlcleaner</groupId>
<artifactId>htmlcleaner</artifactId>
<version>2.21</version>
</dependency>几个简单的bean


package com.ym.reptile.bean;
public class Chapter {
private String id;
private String name;
private String url;
public Chapter(String id, String name, String url) {
this.id = id;
this.name = name;
this.url = url;
}
public Chapter() {
}
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
@Override
public String toString() {
return "Chapter{" +
"id='" + id + '\'' +
", name='" + name + '\'' +
", url='" + url + '\'' +
'}';
}
public void doSPrint(){
System.out.println("id="+id+"\tname="+name+"\thref="+url);
}
}Fiction类
package com.ym.reptile.bean;
import java.util.List;
public class Fiction {
private String name;
private List<String> sections;
public Fiction(String name, List<String> sections) {
this.name = name;
this.sections = sections;
}
public Fiction() {
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public List<String> getSections() {
return sections;
}
public void setSections(List<String> sections) {
this.sections = sections;
}
@Override
public String toString() {
return "Fiction{" +
"name='" + name + '\'' +
", sections=" + sections +
'}';
}
public void print(){
System.out.println(name);
for (String s:
sections) {
System.out.println("\t"+s);
}
}
}Production类
package com.ym.reptile.bean;
public class Production {
private int id;
private String name;
private String ChapterDirectoryHref;
private String author;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getChapterDirectoryHref() {
return ChapterDirectoryHref;
}
public void setChapterDirectoryHref(String chapterDirectoryHref) {
ChapterDirectoryHref = chapterDirectoryHref;
}
public Production(int id, String name, String author) {
this.id = id;
this.name = name;
this.author = author;
}
public Production(String name, String author) {
this.name = name;
this.author = author;
}
public Production() {
}
@Override
public String toString() {
return "Production{" +
"id=" + id +
", name='" + name + '\'' +
", ChapterDirectoryHref='" + ChapterDirectoryHref + '\'' +
", author='" + author + '\'' +
'}';
}
public void print(){
System.out.println(id+"\t"+name+"\t"+author+"\t"+getChapterDirectoryHref());
}
}可能会用到的几个工具类

package com.ym.reptile.util;
public class Number {
char[] danWei = { '万','千', '百', '十' };
/**
* 把单位数字转换成汉字--->作为返回值
*/
public char hanZi(int i) {
switch (i) {
case 1:
return '一';
case 2:
return '二';
case 3:
return '三';
case 4:
return '四';
case 5:
return '五';
case 6:
return '六';
case 7:
return '七';
case 8:
return '八';
case 9:
return '九';
default:
return '零';
}
}
/**
* 把char类型的单位数字转换成int类型返回
* @param c
* @return
*/
public int charToInt(char c) {
switch (c) {
case '1':
return 1;
case '2':
return 2;
case '3':
return 3;
case '4':
return 4;
case '5':
return 5;
case '6':
return 6;
case '7':
return 7;
case '8':
return 8;
case '9':
return 9;
default:
return 0;
}
}
/**
* 返回数字的长度,即该数字有几位
* @param strNumber
* @return
*/
public int numberLength(String strNumber) {
return strNumber.length();
}
/**
* 将int类型的数字转换为String类型返回
* @param i
* @return
*/
public String numberToString(int i) {
return String.valueOf(i);
}
public void output() {
for (int i = 0; i < 10000; i++) {
if (i < 10) {
System.out.println(hanZi(i));
} else {
//char类型的数组,用来存储每位的数字
char[] numToChar = new char[100];
String numberToString = numberToString(i);
//int类型的数组,用来存储每位的数字
int[] arrayNumber = new int[100];
//numLength获取数字的位数
int numLength = numberLength(numberToString);
//左到右遍历数字,分别存入char和int数组
for (int j = 0; j < numLength; j++) {
numToChar[j] = numberToString.charAt(j);
arrayNumber[j] = charToInt(numToChar[j]);
}
// 数字-->数字数组 正确
//获取单位下标的起始位置
int danWeiIndex = danWei.length - numLength;
//从左到右遍历数字
for (int k = 0; k < numLength; k++) {
// 第K位的数字
int everyStateNum = arrayNumber[k];
boolean flag = false;
if (everyStateNum == 0) {
// 左到右遍历,碰到第一个0开始如果后面一直是零则不输出,否则输出一个零
for (int q = k + 1; q < numLength; q++) {
danWeiIndex++;
if (arrayNumber[q] != 0) {
k = q - 1;
System.out.print("零");
flag = true;
break;
}
if (danWeiIndex == danWei.length) {
break;
}
}
if (flag) {
continue;
} else {
break;
}
} else {
System.out.print(hanZi(everyStateNum));
danWeiIndex++;
//控制单位数组的下标不能越界,到个位数字时候直接输出数字,但不输出单位
if (danWeiIndex == danWei.length) {
break;
}
System.out.print(danWei[danWeiIndex]);
}
}
System.out.println();
}
}
}
}爬虫工具类Reptile
package com.ym.reptile.util;
import org.apache.http.HttpEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.util.EntityUtils;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.Map;
/*
* @author ym
* date 2019-08-07
* */
public class Reptile {
//get HTML pages by url
public StringBuilder fromURLGetHtml(String url){
StringBuilder ret = new StringBuilder();
try {
URL realUrl = new URL(url);
//连接url
URLConnection connection = realUrl.openConnection();
//读取url流
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(connection.getInputStream()));
while(bufferedReader.readLine() != null) {
String str = bufferedReader.readLine();
ret.append(str);
}
bufferedReader.close();
}catch(MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return ret;
}
public void sendPost(String url, Map<String, Object> params) throws IOException {
String response = null;
}
public StringBuilder getPage(String url) throws IOException {
StringBuilder ret = new StringBuilder();
HttpClientBuilder builder = HttpClients.custom();
CloseableHttpClient client = builder.build();
HttpGet request = new HttpGet(url);
CloseableHttpResponse response = client.execute(request);
HttpEntity entity = response.getEntity();
System.out.println(response.getStatusLine());
ret.append(EntityUtils.toString(entity));
return ret;
}
public String ChineseToEnglishTranslationLink(String query) throws Exception {
String url = "http://dict.youdao.com/search";
String newQuery = new StringOperation().toURLCode(query);
url = url+"?q="+newQuery+"&keyfrom=new-fanyi.smartResult";
return url;
}
public String fromEnglishGetDetail(String query) throws UnsupportedEncodingException {
String url ="http://dict.youdao.com/w/eng/";
String newQuery = new StringOperation().toURLCode(query);
url+=newQuery+"/";
return url;
}
}字符串编码处理类StringOperation
package com.ym.reptile.util;
import java.io.UnsupportedEncodingException;
import java.net.URLDecoder;
import java.net.URLEncoder;
public class StringOperation {
public String toUpperString(String string){
return string.toUpperCase();
}
public String toLowerString(String string){
String s = string.toLowerCase();
return s;
}
public boolean isLowercaseCharacter(char c){
boolean ret = false;
if(c>='a' && c<='z'){
ret = true;
}
return ret;
}
public boolean isUppercaseCharacter(char c){
boolean ret = false;
if(c>='A' && c<='Z'){
ret = true;
}
return ret;
}
public boolean isCharacter(char c){
boolean ret = false;
if((c>='A' && c<='Z') ||(c>='a' && c<='z')){
ret = true;
}
return ret;
}
public String toUnicode(String s){
char[] chars = s.toCharArray();
StringBuilder builder = new StringBuilder();
for(char c:chars){
builder.append("\\u"+ Integer.toHexString((int)c)+"");
}
return builder.toString();
}
public String fromUnicode(String unicode){
String[] ss = unicode.split("\\\\u");
String ret = "";
for(int i=1;i<ss.length;i++){
ret += (char) Integer.valueOf(ss[i], 16).intValue();
}
return ret;
}
public String toURLCode(String s) throws UnsupportedEncodingException {
return URLEncoder.encode(s,"UTF-8");
}
public String toURLCodeGBK(String s)throws UnsupportedEncodingException{
return URLEncoder.encode(s,"gbk");
}
public String fromURLCode(String s) throws UnsupportedEncodingException {
return URLDecoder.decode(s,"UTF-8");
}
public String Encode(String content, String code) throws UnsupportedEncodingException {
return URLEncoder.encode(content,code);
}
public String Decode(String content, String code) throws UnsupportedEncodingException {
return URLDecoder.decode(content,code);
}
public String deleteLeftAndRight(String s){
return s.substring(1,s.length()-1);
}
public String deleteRedundantSpace(String initialString){
return initialString.replaceAll("\\s+"," ");
}
private String deleteNumber(String s ){ //删除数字
return s.replaceAll("\\d+", "").trim();
}
private int getNumber(String s){ //获得字符串中的数字
String ret = "";
for(int i =0;i<s.length();i++){
if(s.charAt(i)>='0' &&s.charAt(i)<='9'){
ret+=s.charAt(i);
}
}
return Integer.parseInt(ret);
}
}query 的小说名,转url链接




多尝试几次小说名之后,我们发现s对应的这个9157106854577873494值并不会改变
而q的值应该是query的urlcode形式,根据前面的ie=gbk,我们可以揣测如下代码


public String toURLCodeGBK(String s)throws UnsupportedEncodingException{
return URLEncoder.encode(s,"gbk");
}
private String getQueryCode(String query){
String ret ="";
try {
return new StringOperation().toURLCodeGBK(query);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return ret;
}
public String getChapterDirectoryUrl(String query){
return "https://so.biqusoso.com/s.php?ie=gbk&siteid=biqugex.com&s="+s+"&q="+getQueryCode(query);
}
public List<Production> getALLProductions(String html){
ArrayList<Production> ret = new ArrayList<Production>();
Document document = Jsoup.parse(html);
Elements elements = document.select("a");
int len = elements.size()-2;
for(int i = 0 ;i<len;i++){
String s = elements.get(i).text();
s= s.replaceAll( " ","");
String[] ss = s.split("作者:");
Production po = new Production();
po.setId(i+1);
po.setName(ss[0]);
po.setAuthor(ss[1]);
po.setChapterDirectoryHref(elements.get(i).attr("href"));
ret.add(po);
}
return ret;
}
public List<Production> queryAllLikeProductions(String query){
Reptile reptile = new Reptile();
String url = new ProductionService().getChapterDirectoryUrl(query);
String html = reptile.fromURLGetHtml(url).toString();
return getALLProductions(html);
}

上图证实猜想正确。
根据作品url获取各章节url
public List<Chapter>getAllChapter(String url){
ArrayList<Chapter> allChapters = new ArrayList<Chapter>();
try {
Document document =Jsoup.connect(url).timeout(3000).get();
Elements elements = document.select(".listmain dl dd a");
int len = elements.size();
for(int i = 0;i<len;i++){
String name = elements.get(i).text();
String[] ss = name.split(" ");
String id = "";
if(ss.length>1){
name = ss[ss.length-1];
id = ss[0];
}
String href = "https://www.biqugex.com"+elements.get(i).attr("href");
Chapter chapter = new Chapter();
chapter.setName(name);
chapter.setUrl(href);
chapter.setId(id);
allChapters.add(chapter);
}
} catch (IOException e) {
e.printStackTrace();
}
return allChapters;
}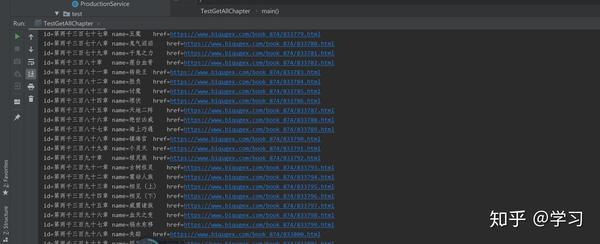

完成章节获取
爬取章节内容 也就是小说内容。
public Fiction getFictionByUrl(String url){
Fiction ret = new Fiction();
try {
Document document = Jsoup.connect(url).get();
Element element = document.select("#content").get(0);
String content = element.text();
content.replaceAll("(","")
.replaceAll(")","")
.replaceAll("\\(","")
.replaceAll("\\)","")
.replaceAll("《","")
.replaceAll("》","");
StringOperation so = new StringOperation();
content = so.deleteRedundantSpace(content);
String[] ss = content.split(" ");
ret.setName(ss[0]);
ArrayList<String> alls = new ArrayList<String>();
for(int i =1;i<ss.length;i++){
alls.add(ss[i]);
}
ret.setSections(alls);
} catch (IOException e) {
e.printStackTrace();
}
return ret;
}最终类ProductionService
package com.ym.reptile.service;
import com.ym.reptile.bean.Chapter;
import com.ym.reptile.bean.Fiction;
import com.ym.reptile.bean.Production;
import com.ym.reptile.util.Reptile;
import com.ym.reptile.util.StringOperation;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.w3c.dom.stylesheets.DocumentStyle;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.lang.reflect.Array;
import java.util.ArrayList;
import java.util.List;
public class ProductionService {
private String s = "9157106854577873494";
public void setSimpleCode(String s){
this.s =s;
}
private String getQueryCode(String query){
String ret ="";
try {
return new StringOperation().toURLCodeGBK(query);
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
return ret;
}
public String getChapterDirectoryUrl(String query){
return "https://so.biqusoso.com/s.php?ie=gbk&siteid=biqugex.com&s="+s+"&q="+getQueryCode(query);
}
public List<Production> getALLProductions(String html){
ArrayList<Production> ret = new ArrayList<Production>();
Document document = Jsoup.parse(html);
Elements elements = document.select("a");
int len = elements.size()-2;
for(int i = 0 ;i<len;i++){
String s = elements.get(i).text();
s= s.replaceAll( " ","");
String[] ss = s.split("作者:");
Production po = new Production();
po.setId(i+1);
po.setName(ss[0]);
po.setAuthor(ss[1]);
po.setChapterDirectoryHref(elements.get(i).attr("href"));
ret.add(po);
}
return ret;
}
public List<Production> queryAllLikeProductions(String query){
Reptile reptile = new Reptile();
String url = new ProductionService().getChapterDirectoryUrl(query);
String html = reptile.fromURLGetHtml(url).toString();
return getALLProductions(html);
}
public List<Chapter>getAllChapter(String url){
ArrayList<Chapter> allChapters = new ArrayList<Chapter>();
try {
Document document =Jsoup.connect(url).timeout(3000).get();
Elements elements = document.select(".listmain dl dd a");
int len = elements.size();
for(int i = 0;i<len;i++){
String name = elements.get(i).text();
String[] ss = name.split(" ");
String id = "";
if(ss.length>1){
name = ss[ss.length-1];
id = ss[0];
}
String href = "https://www.biqugex.com"+elements.get(i).attr("href");
Chapter chapter = new Chapter();
chapter.setName(name);
chapter.setUrl(href);
chapter.setId(id);
allChapters.add(chapter);
}
} catch (IOException e) {
e.printStackTrace();
}
return allChapters;
}
public Fiction getFictionByUrl(String url){
Fiction ret = new Fiction();
try {
Document document = Jsoup.connect(url).get();
Element element = document.select("#content").get(0);
String content = element.text();
content.replaceAll("(","")
.replaceAll(")","")
.replaceAll("\\(","")
.replaceAll("\\)","")
.replaceAll("《","")
.replaceAll("》","");
StringOperation so = new StringOperation();
content = so.deleteRedundantSpace(content);
String[] ss = content.split(" ");
ret.setName(ss[0]);
ArrayList<String> alls = new ArrayList<String>();
for(int i =1;i<ss.length;i++){
alls.add(ss[i]);
}
ret.setSections(alls);
} catch (IOException e) {
e.printStackTrace();
}
return ret;
}
}编辑于 2019-09-03 09:19
Java 编程
网页爬虫
Java爬虫
文章被以下专栏收录
