
David Silver 增强学习——Lecture 7 策略梯度算法(一)

其他Lecture
【1】 搬砖的旺财:David Silver 增强学习——笔记合集(持续更新)
【2】 搬砖的旺财:David Silver 增强学习——Lecture 1 强化学习简介
【3】 搬砖的旺财:David Silver 增强学习——Lecture 2 马尔可夫决策过程
【4】 搬砖的旺财:David Silver 增强学习——Lecture 3 动态规划
【5】 搬砖的旺财:David Silver 增强学习——Lecture 4 不基于模型的预测
【6】 搬砖的旺财:David Silver 增强学习——Lecture 5 不基于模型的控制
【7】 搬砖的旺财:David Silver 增强学习——Lecture 6 值函数逼近
【8】 搬砖的旺财:David Silver 增强学习——Lecture 7 策略梯度算法(二)
【9】 搬砖的旺财:David Silver 增强学习——Lecture 7 策略梯度算法(三)
扩展
Pieter Abbeel在NIPS 2016的演讲:Deep Reinforcement Learning through Policy Optimization。


Pieter Abbeel教授是加州大学伯克利分校机器人与强化学习范畴的教授。他于比利时KU Leuven获电子工程学士、硕士学位,之后在斯坦福大学师从吴恩达,并于2008年取得博士学位。Pieter Abbeel教授自2008年起在加州大学伯克利分校担任教职。在攻读博士期间,Pieter Abbeel教授发表了多篇重要的学术论文,并与导师吴恩达提出了学徒学习(Apprenticeship learning)这一强化学习的全新概念。Pieter Abbeel教授同时担任创业公司Embodied Intelligence的董事长兼首席科学家。
PPT链接: https://media.nips.cc/Conferences/2016/Slides/6198-Slides.pdf
前言
到目前为止,我们所讨论的方法几乎全部都是动作-价值法(action-value method);他们了解动作的价值,然后根据估计的动作价值选择动作;如果没有动作价值估计,他们的策略甚至不会存在。在本章中,我们将考虑的方法是学习一个参数化策略(parameterized policy),该策略可以在不知晓值函数的情况下选择动作。值函数仍然可以用来学习策略参数,但不是动作选择所必需的。


目录
1、简介
····1.1 基于策略的强化学习
····1.2 强化学习分类
····1.3 为什么要使用策略梯度算法?
····1.4 策略模型的建模方式
····1.5 策略梯度算法的优缺点
····1.6 随机策略
····1.7 策略退化
····1.8 收敛性对比
2、策略梯度定理
····2.1 策略梯度目标函数
········2.1.1 Start value
········2.1.2 Average Value
········2.1.3 Average reward per time-step
····2.2 数值法求梯度
····2.3 策略梯度算法
····2.4 策略梯度的推导
········2.4.1 轨迹
········2.4.2 对目标函数U\left( \theta \right)=\sum_{\tau}p_{\theta}\left( \tau \right)R\left( \tau \right)的几点说明
········2.4.3 求解 \nabla_\theta U\left( \theta \right)
········2.4.4 从似然率的角度
········2.4.5 从重要性采样的角度
········2.4.6 似然率梯度的理解
········2.4.7 将轨迹分解成状态和动作
········2.4.8 似然率梯度估计
1、简介
- 1.1 基于策略的强化学习
在过去的课程中我们讲述了基于值函数的方法
上一节中,使用了带参数 \textbf w 的函数去近似值函数
V_{\textbf w}\left( s \right) \approx V^{\pi}\left( s \right)
Q_{\textbf w}\left( s,a \right) \approx Q^{\pi}\left( s,a \right)
策略是从值函数中导出的
使用贪婪的方法导出最优策略
使用 \epsilon 贪婪的方法导出行为策略
现在,我们直接参数化策略 \pi_{\theta}\left( a|s \right)={\Bbb P}\left[ a|s,\theta \right]
(注:建立一个模型,输入是 s ,输出是各动作的概率,即策略,中间没有计算任何的值函数。)
这里仍然考虑无模型的方法
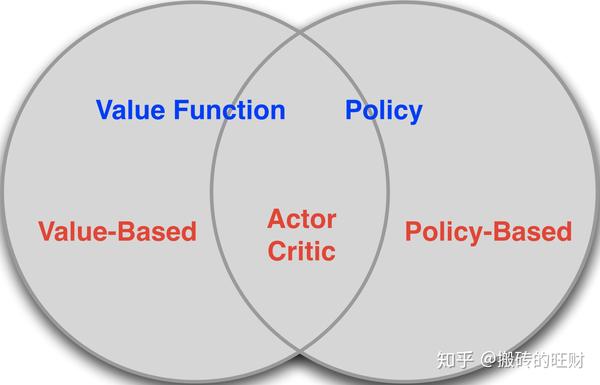
- 1.2 强化学习分类
基于值函数的方法
学习值函数
用值函数导出策略
基于策略的方法
没有值函数
学习策略
Actor-Critic
学习值函数
学习策略

- 1.3 为什么要使用策略梯度算法?
基于值函数方法的局限性:
针对确定性策略
策略退化
难以处理高维度的状态/动作空间——不能处理连续的状态/动作空间
收敛速度慢
- 1.4 策略模型的建模方式
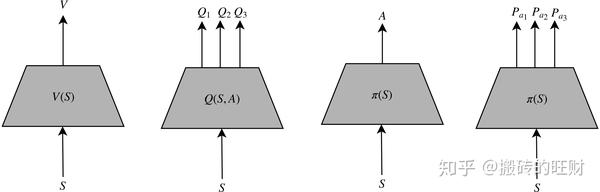

值函数模型
针对函数 V\left( S \right) ——输入状态 S ,输出 V 函数
针对函数 Q\left( S,A \right) ——输入状态 S ,输出多个 Q , Q 的数量等于动作的数量,每个 Q 代表对应动作在当前状态下对应的 Q 函数
策略模型
输入状态 S ,输出在状态 S 下确定性的动作 A
输入状态 S ,输出在状态 S 下每一个动作对应的概率 P_{a_1} 、 P_{a_2} 、 P_{a_3} 等(注:适用于离散动作)
- 1.5 策略梯度算法的优缺点
优点
更好的收敛性
能够有效地处理高维和连续的动作空间
能够学到随机策略
不会导致策略退化
缺点
更容易收敛到局部最优值
难以评价一个策略,而且评价的方差较大
- 1.6 随机策略


石头剪刀布
两个人玩“石头剪刀布”
如果是一个确定性策略——则很容易输掉游戏(注:你一直出剪刀,那对方一直出石头!)
一个均匀分布的随机策略(石头剪刀布随机)才是最优的(满足纳什均衡)
(注:注意区分,随机策略和带随机性的策略是两个不一样的概念!带随机性的策略——例如 \epsilon 贪恋策略,是为了更好的探索!随机策略和探索无关,而是最后求出的策略就是一个随机的策略!)


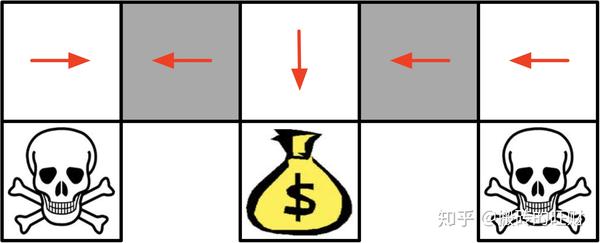

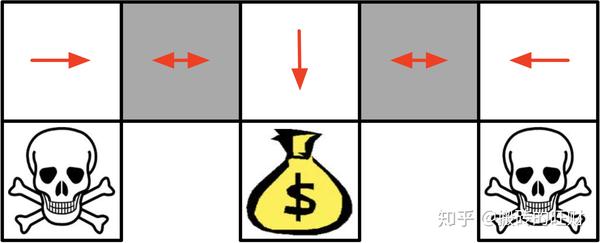

迷宫寻宝
假设灰色区域是部分观测的(即走到灰格子之后不知道该往左边还是右边),因此两个灰色区域是等价的(因此只能在其中一个灰色的区域得到最优的动作)
确定性策略会导致两个灰色区域有相同的动作,即便使用 \epsilon 贪婪策略,也会导致获得长时间的徘徊
最佳的策略是以0.5的概率选择动作
很多时候我们需要一个确定分布的随机动作
- 1.7 策略退化
真实的最优值函数会导致真实的最优策略,然而近似的最优值函数可能导致完全不同的策略
例子
假设有两个动作,A和B,其中动作A的真实Q值为0.5001,动作B的真实Q值为0.4999 (真实的最优策略是选择动作A)
假设对B的估计准确无误
如果对A的Q值估计为0.9999,误差很大,但是导出的最优动作是正确的
如果对A的Q值估计为0.4998,误差很小,但是导出的最优动作是错误的
使用函数近似时,也会产生策略退化
例子
包含两个状态: \left\{ A, B \right\}
假设特征是一维的: A : 2\ \ \ B : 1 (注: A 的特征值是2, B 的特征值是1)
如果设定奖励,使得最优策略 \pi^* 满足 B 的 V 值比 A 大,那么,如果使用线性函数近似 V ,也就是参数 \textbf w 乘以特征,由于 A 的特征值比 B 的特征值大,所以能够满足 B 的 V 值比 A 大的参数 \textbf w 应该是负值,这时就能导出最优策略
但是,基于值函数的做法是要使得 V 值尽量靠近最优的 V 值(假设>0),那么 \textbf w 应该是正值
值函数越准确,策略越差的现象称为策略退化(注:函数模型能力不够)
- 1.8 收敛性对比
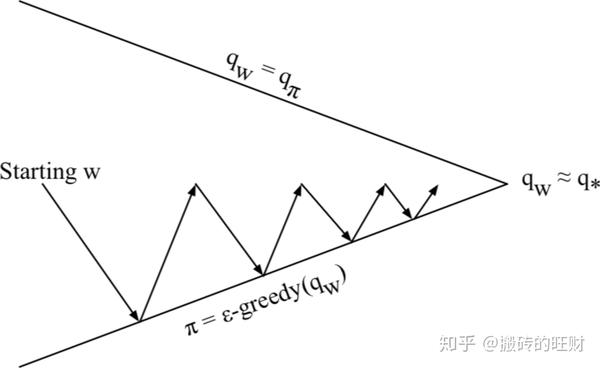
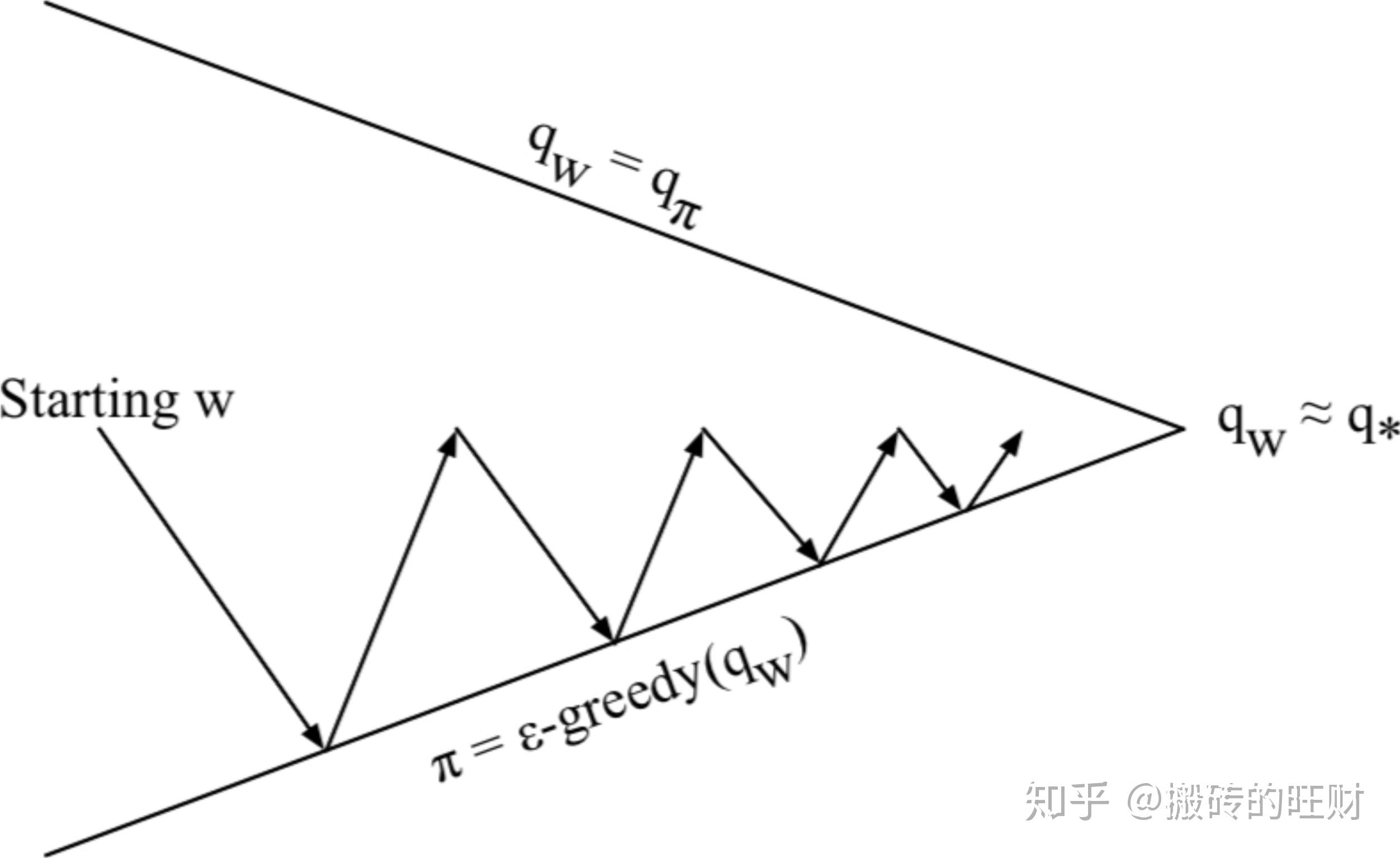
基于值函数的方法
收敛慢——需要对 V(\textrm{or}\ Q) 和 \pi 交替优化
方差小(值函数基于过去的训练样本得到,置信度较高,而策略基于值函数)
策略梯度方法
收敛快——直接对 \pi 进行优化
方差大
2、策略梯度定理
- 2.1 策略梯度目标函数
用一个参数 \theta 建模策略 \pi_\theta\left( s,a \right) ,如何寻找最优的参数 \theta ?
值函数近似时,优化的目标是使值函数的输出接近目标值
如何评价一个策略 \pi_\theta 的好坏?
(注:以下三种方法都是为了衡量个体在某一时刻的价值!)
- 2.1.1 Start value
一种定义方法,在能够产生完整Episode的环境下,也就是在个体可以到达终止状态时,使用初始状态的值函数Start value来衡量整个策略的优劣: J_1\left( \theta \right)=V^{\pi_{\theta}}\left( s_1 \right)={\Bbb E}_{\pi_{\theta}}\left[ v_1 \right] ,它的意思是如果个体总是从某个状态 s_1 开始,或者以一定的概率分布从 s_1 开始,那么从该状态开始到Episode结束个体将会得到怎样的最终奖励。
关键在于,找到一个策略,当把个体放在状态 s_1 时让它执行当前的策略,能够获得start value的奖励。
于是策略优化问题就变成了:找 \theta 使得最大化 J_1\left( \theta \right) 。
解此类问题有两大类算法:基于梯度(主要关注)的和不基于梯度的。
- 2.1.2 Average Value
J_{\textrm{avV}}\left( \theta \right)= \sum_s \mathop{\underline{d^{\pi_\theta}\left( s \right)}}_{\scriptsize{基于当前策略下}\\{\scriptsize 马尔科夫链关于}\\{\scriptsize状态的静态分布}} V^{\pi_\theta}\left( s \right)
连续环境状态(无开始状态)下,个体一直与环境进行交互,此时应该针对每个可能的状态计算从该时刻开始一直持续与环境交互下去能够得到的奖励,按该时刻各状态的概率分布求和。
- 2.1.3 Average reward per time-step
J_{\textrm{av}R}\left( \theta \right)= \sum_s \mathop{\underline{d^{\pi_\theta}\left( s \right)}}_{\scriptsize{基于当前策略下}\\{\scriptsize 马尔科夫链关于}\\{\scriptsize状态的静态分布}} \sum_a\pi_\theta\left( s,a \right){\cal R}_s^a
在一个确定的时间步长里,求出每种状态下采取所有行为能够得到的即时奖励,然后按各状态的概率分布求和。
- 2.2 数值法求梯度
目标函数: J_1\left( \theta \right)
策略模型: \pi_\theta\left( a,s \right)
怎么求 \nabla_\theta J_1 ?
数值梯度法
对于 \theta 的每一个维度 k \in \left[ 0,1 \right]
通过给 \theta 的第 k 维加入一点扰动 \varepsilon
然后估计对第 k 维的偏导数 \frac{\partial J\left( \theta \right)}{\partial \theta_k} \approx \frac{\partial J\left( \theta+\varepsilon u_k \right)-J\left( \theta \right)}{\varepsilon}
其中 u_k 是单位向量,第 k 维是1,其他均为0
- 每次求 θ 的梯度需要计算 n 次
- 简单,噪声大,效率低
- 有时很有效,对任意策略均适用,甚至策略不可微的情况也适用
- 2.3 策略梯度算法
已有策略模型: \pi_\theta\left( a,s \right)
策略模型可以微分,即我们能求 \nabla_\theta \pi_\theta
策略梯度算法的出发点:
1. 找到一种合适的目标函数 J ,满足:
最大化 J 相当于最大化期望回报值
并且能够建立 \nabla_\theta J 与 \nabla_\theta \pi_\theta 的关系
2. 可以不需要知道 J 的具体形式,关键是计算 \nabla_\theta J
- 2.4 策略梯度的推导
- 2.4.1 轨迹
用 \tau 表示每次仿真的状态-行为序列 s_1,a_1,s_2,a_2,\cdots,s_\tau,a_\tau ,每一个轨迹代表了强化学习的一个样本。
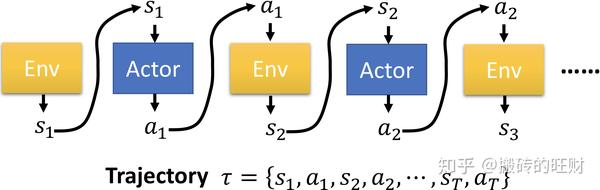

轨迹的回报: R\left( \tau \right)=\sum_{t=1}^{T}\gamma^tR\left( s_t,a_t \right) 。
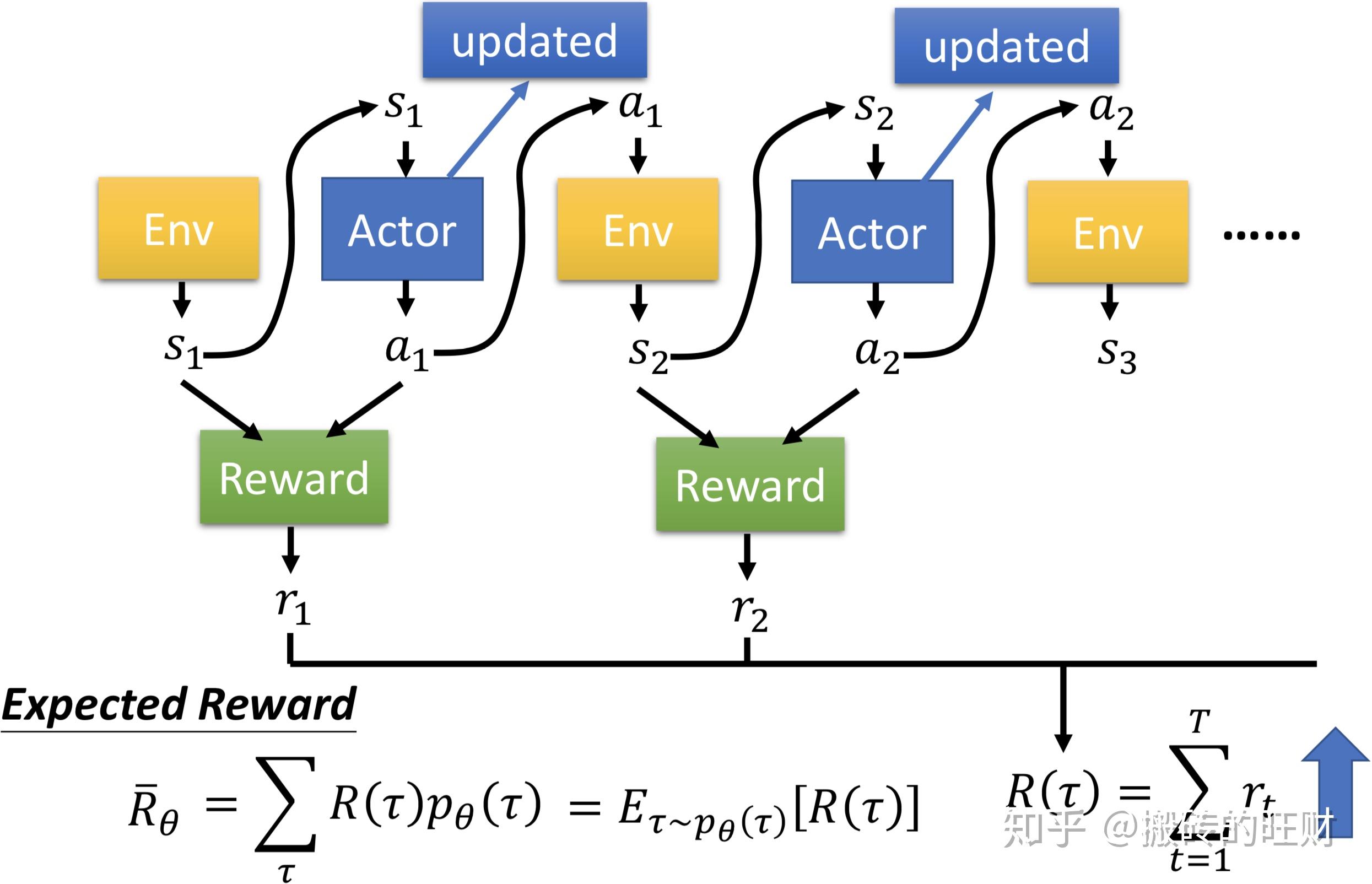
用 p_\theta(\tau) 表示(在参数 \theta 下)轨迹 \tau 出现(完美复现 s_1,a_1,s_2,a_2,\cdots,s_\tau,a_\tau )的概率。
其实, R\left( \tau \right) 是一个随机变量,可以这么理解,
在Agent在给定同样的state时,采取的action是有随机性的
在Environment中给定同样的action时,得到的observation是有随机性的
所以 R\left( \tau \right) 能够求的是期望值,方法如下:
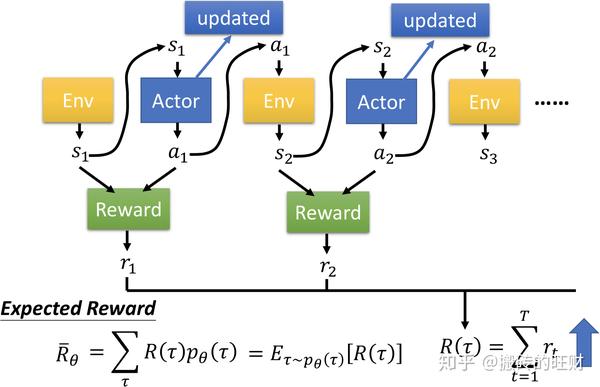
穷举 \tau ,每一个 \tau 有对应的 R(\tau) ,以及它出现的概率 p_\theta \left( \tau \right) (也可以说成是从分布 p_\theta \left( \tau \right) 采样 \tau ),然后计算 R(\tau) 的期望值: \overline{R}_\theta=\sum_\tau R\left( \tau \right)p_\theta\left( \tau \right)=\Bbb E_{\tau \sim p_\theta(\tau)}\left[ R\left( \tau \right) \right] 。
目的:调整参数 \theta 使得 R\left( \tau \right) 越大越好,所以强化学习的目标函数可表示为: U\left( \theta \right)=\sum_{\tau}R\left( \tau \right)p_\theta\left( \tau \right)
(注:轨迹回报的期望值=该轨迹出现的概率 \times 该轨迹的回报值——>加权求和)
2.4.2 对目标函数 U\left( \theta \right)=\sum_{\tau}R\left( \tau \right)p_\theta\left( \tau \right) 的几点说明
强化学习的目标是:
\mathop {\textrm{max}} \limits_{\theta}U\left( \theta \right)={\textrm{max}}\sum_{\tau}R\left( \tau \right)p_\theta\left( \tau \right)
不同的策略 \pi_\theta 影响了不同轨迹出现的概率,换句话说, p_\theta\left( \tau \right) 其实是一个分布,我们感兴趣的是移动这个分布(通过改变参数 \theta )来提高回报值; 在一个固定的环境中,轨迹的 R\left( \tau \right) 是稳定的。
2.4.3 求解 \nabla_\theta U\left( \theta \right)
如何求解 \nabla_\theta U\left( \theta \right) ?
p_\theta\left( \tau \right) 未知
无法用一个可微分的数学模型直接表达 U\left( \theta \right)
策略梯度解决的问题是,即使未知 U\left( \theta \right) 的具体形式,也能求其梯度。
包括两种角度:
似然率的角度
重要性采样的角度
2.4.4 从似然率的角度
\begin{align*} \nabla_\theta U\left( \theta \right) &=\nabla_{\theta}\sum_{\tau}p_\theta\left( \tau \right)R\left( \tau \right)\\ &\scriptsize{求和符号内的式子收敛时,求和符号与梯度符号可以交换}\\ &=\sum_{\tau}\nabla_{\theta}p_\theta\left( \tau \right)R\left( \tau \right)\\ &=\sum_{\tau}\frac{p_\theta\left( \tau \right)}{p_\theta\left( \tau \right)}\nabla_{\theta}p_\theta\left( \tau \right)R\left( \tau \right)\\ &=\sum_{\tau}p_\theta\left( \tau \right)\frac{\nabla_{\theta}p_\theta\left( \tau \right)}{p_\theta\left( \tau \right)}R\left( \tau \right)\\ &\scriptsize{使用了{{\nabla_\theta}\log(z)}={1 \over z}{\nabla_\theta} z}\\ &=\sum_{\tau}p_\theta\left( \tau \right)\nabla_{\theta}{\textrm{log}}p_\theta\left( \tau \right)R\left( \tau \right)\\ &= {\Bbb E}_{\tau \sim p_\theta(\tau)}\left[ \nabla_{\theta}{\textrm{log}}p_\theta\left( \tau \right)R\left( \tau \right) \right] \end{align*}
为什么要推导成这样的形式?
p_\theta\left( \tau \right) 可以通过 \pi_\theta\left( a,s \right) 的模型表达(后面2.4.7会证明)
R\left( \tau \right) 可以通过采样的方式估计
期望符号 {\Bbb E} 可以通过经验平均去估算
利用当前策略 \pi_\theta 采样 m 条轨迹,使用经验平均来估计梯度:
\nabla_{\theta}U\left( \theta \right)=\frac{1}{m}\sum_{i=1}^m\nabla_{\theta}{\textrm{log}}p_\theta\left( \tau \right)R\left( \tau \right)
2.4.5 从重要性采样的角度
对于参数的更新 \theta_{old}\rightarrow\theta ,我们使用参数 \theta_{old} 产生的数据去评估参数 \theta 的回报期望,由重要性采样得到:
\begin{align*} U\left( \theta \right) &=\sum_{\tau}p_\theta\left( \tau \right)R\left( \tau \right)\\ &=\sum_{\tau}p_{\theta_{old}}\left( \tau \right)\frac{p_\theta\left( \tau \right)}{p_{\theta_{old}}\left( \tau \right)}R\left( \tau \right)\\ &={\Bbb E}_{\tau\sim p_{\theta_{\textrm{old}}}}\left[ \frac{p_\theta\left( \tau \right)}{p_{\theta_{old}}\left( \tau \right)}R\left( \tau \right) \right]\\ \end{align*}
此时导数变成了 \nabla_\theta U\left( \theta \right)={\Bbb E}_{\tau\sim p_{\theta_{\textrm{old}}}}\left[ \frac{\nabla_\theta p_\theta\left( \tau \right)}{p_{\theta_{old}}\left( \tau \right)}R\left( \tau \right) \right]
(注: \theta_{\textrm{old}} 是一个过去的值,或者说是已知的值,所以它不带任何参数。)
当 \theta=\theta_{old} 时,我们得到当前策略的导数:
\begin{align*} \nabla_\theta U\left( \theta \right){\Bigg |}_{\theta=\theta_{old}} &={\Bbb E}_{\tau\sim p_{\theta_{\textrm{old}}}}\left[ \frac{\nabla_\theta p_\theta\left( \tau \right){\Bigg |}_{\theta_{old}}}{p_{\theta_{old}}\left( \tau \right)}R\left( \tau \right) \right]\\ &={\Bbb E}_{\tau\sim p_{\theta_{\textrm{old}}}}\left[ \nabla_\theta{\textrm{log}}p_\theta\left( \tau \right){\Bigg |}_{\theta_{old}}R\left( \tau \right) \right] \end{align*}
2.4.6 似然率梯度的理解
\nabla_{\theta}U\left( \theta \right)=\frac{1}{m}\sum_{i=1}^m\nabla_{\theta}{\textrm{log}}p_\theta\left( \tau \right)R\left( \tau \right)
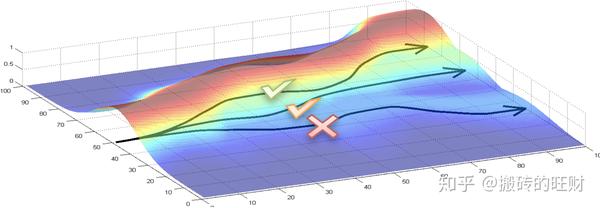

\nabla_{\theta}{\textrm{log}}p_\theta\left( \tau \right) 是轨迹 \tau 的概率随参数 \theta 变化最陡的方向
(注: \textrm{log} 是单调递增的函数,对 {\textrm{log}}p_\theta\left( \tau \right) 求梯度相当于对 p_\theta\left( \tau \right) 求梯度)
沿正方向,轨迹出现的概率会变大
沿负方向,轨迹出现的概率会变小
R\left( \tau \right) 控制了参数更新的方向和步长,正负决定了方向,大小决定了增大(减小)的幅度
策略梯度
增大了高回报轨迹出现的概率,回报值越大增加越多
减少了低回报轨迹出现的概率,回报值越小减少越多
(注:图中有三条轨迹,上面两条轨迹的回报值是正的,下面一条轨迹的回报值是负的,通过参数更新会使得上面两条轨迹出现的概率增大,而使得下面一条轨迹出现的概率降低)
(注:注意到似然率梯度只是改变未来轨迹再次出现的概率,而没有尝试去改变轨迹)
补充说明:
抽取一些轨迹,通过函数 R\left( \tau \right) 估算它们的得分,也为每一个 \tau 估算式子 \nabla_{\theta}{\textrm{log}}p_\theta\left( \tau \right) ——它是一个向量,这个梯度能在参数空间中告诉我们提高一个 \tau 的概率的方向。也就是说,如果我们往 \nabla_{\theta}{\textrm{log}}p_\theta\left( \tau \right) 的方向稍微调整一下 \theta ,我们会看到某个 \tau 的概率有了略微的提升。仔细观察公式,它告诉我们应该在这个方向上乘以标量分数 R\left( \tau \right) 。这将会使得抽取出的分数越高的轨迹越“用力拉拢”概率密度,进行更新时,概率密度将会往分数更高的方向移动,让取得高分的轨迹变得更有可能被选中。
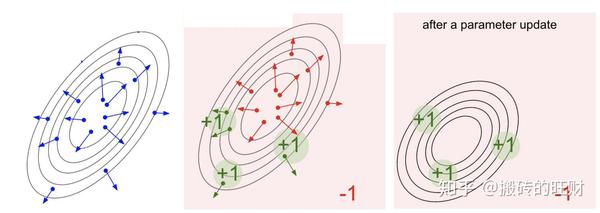

左:高斯分布及一些从中抽取的轨迹(蓝点)。在每个蓝点上,我们根据高斯分布的参数平均值画出了log概率的梯度。箭头表示的是,为了提高该轨迹被选中的概率,高斯分布的平均值应该被“拉动”的方向。
中:某个回报函数在大部分区域都给出了-1,只在小部分区域给出了+1(请注意,这可以是一个任意的、不一定可微分的标量函数)。箭头现在用了不同的颜色,在更新中我们将会对所有的红色箭头的反方向与所有的绿色箭头做平均。
右:在参数完成更新后,绿色箭头和反向的红色箭头将我们拖往了高斯分布的左边和底部。现在,就像我们想要的那样,从这个分布中抽取的轨迹将会有更高的预期分数。 (注:详细讲解请参考 Deep Reinforcement Learning: Pong from Pixels。)
2.4.7 将轨迹分解成状态和动作
借鉴李宏毅教授的ppt详细说明 p_\theta \left( \tau \right) :
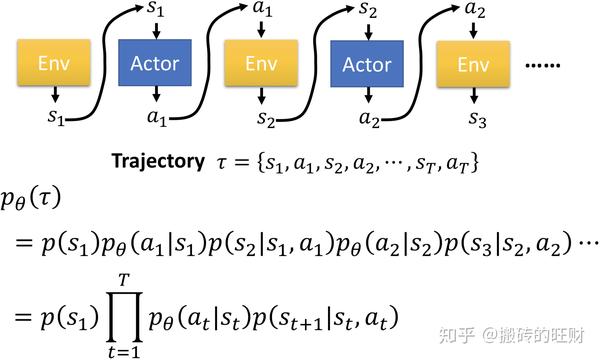

由此得到轨迹的似然率的表达(链式法则):
\begin{align*} p_\theta(\tau^{(i)}) &=p(s_1^{(i)})p_{\theta}(a_1^{(i)}|s_1^{(i)})p(s_2^{(i)}|s_1^{(i)},a_1^{(i)})p_{\theta}(a_2^{(i)}|s_2^{(i)})p(s_3^{(i)}|s_2^{(i)},a_2^{(i)})... \\&=p(s_1^{(i)})\prod^{T}_{t=1}p_{\theta}(a_t^{(i)}|s_t^{(i)})p(s_{t+1}^{(i)}|s_t^{(i)},a_t^{(i)}) \end{align*}
p\left( s_{t+1}^{(i)}|s_t^{(i)},a_t^{(i)} \right) 由Environment决定
p_\theta\left( a_t^{(i)}|s_t^{(i)} \right) 由Agent的策略决定
(注:一条轨迹出现的概率可以表达成每一时刻的环境模型 p\left( s_{t+1}^{\left( i \right)}|s_{t}^{\left( i \right)}, a_{t}^{\left( i \right)}\right) 与策略 p_\theta\left( a_{t}^{\left( i \right)}| s_{t}^{\left( i \right)}\right) 相乘,说的再具体一点,一条轨迹出现的概率等于,在初始状态 s_0^{\left( i \right)} 选择动作 a_0^{\left( i \right)} 跳转到状态 s_1^{\left( i \right)} 的概率 p\left( s_{1}^{\left( i \right)}|s_{0}^{\left( i \right)}, a_{0}^{\left( i \right)}\right) \times 在该状态下选择动作 a_0^{\left( i \right)} 的概率 p_\theta\left( a_{0}^{\left( i \right)}| s_{0}^{\left( i \right)}\right) \times 在状态 s_1^{\left( i \right)} 下选择动作 a_1^{\left( i \right)} 跳转到状态 s_2^{\left( i \right)} 的概率 p\left( s_{2}^{\left( i \right)}|s_{1}^{\left( i \right)}, a_{1}^{\left( i \right)}\right) \times ...,一直乘到和这条轨迹一摸一样的终止状态出现的概率。)
由于状态转移概率 p\left( s_{t+1}^{\left( i \right)}|s_{t}^{\left( i \right)}, a_{t}^{\left( i \right)}\right) 中不包含参数 \theta ,因此求导的过程可以消掉(之所以要写成 {\textrm{log}} 形式的原因),所以:
\begin{align*} \nabla_\theta{\textrm{log}}p_{\theta}\left( \tau^{\left( i \right)} \right) &=\nabla_\theta{\textrm{log}}\left[ p(s_1^{(i)})\prod^{T}_{t=1}p_{\theta}(a_t^{(i)}|s_t^{(i)})p(s_{t+1}^{(i)}|s_t^{(i)},a_t^{(i)}) \right] \\ &=\nabla_\theta{\textrm{log}}\left[\prod^{T}_{t=1}p_\theta\left( a_{t}^{\left( i \right)}| s_{t}^{\left( i \right)}\right)p\left( s_{t+1}^{\left( i \right)}|s_{t}^{\left( i \right)}, a_{t}^{\left( i \right)}\right) \right]\\ &=\nabla_\theta \left[ \sum_{t=1}^{T}{\textrm{log}}p\left( s_{t+1}^{\left( i \right)}|s_{t}^{\left( i \right)}, a_{t}^{\left( i \right)}\right) + \sum_{t=1}^{T}{\textrm{log}}p_\theta\left( a_{t}^{\left( i \right)}| s_{t}^{\left( i \right)}\right) \right]\\ &=\nabla_\theta \left[ \sum_{t=1}^{T}{\textrm{log}}p_\theta\left( a_{t}^{\left( i \right)}| s_{t}^{\left( i \right)}\right) \right]\\ &=\sum_{t=1}^{T}\nabla_\theta{\textrm{log}}p_\theta\left( a_{t}^{\left( i \right)}| s_{t}^{\left( i \right)}\right) \end{align*}
2.4.8 似然率梯度估计
根据之前的推导,我们可以在仅有可微分的策略模型 \pi_\theta 的情况下,求得 \nabla_{\theta}U\left( \theta \right)
\hat\eta=\frac{1}{m}\sum_{i=1}^m\nabla_{\theta}{\textrm{log}}p_{\theta}\left( \tau^{\left( i \right)} \right)R\left( \tau^{\left( i \right)} \right)
这里 \nabla_\theta{\textrm{log}}p_{\theta}\left( \tau^{\left( i \right)} \right)=\sum_{t=1}^{T}\nabla_\theta{\textrm{log}}p_\theta\left( a_{t}^{\left( i \right)}| s_{t}^{\left( i \right)}\right)
所以 \hat\eta=\frac{1}{m}\sum_{i=1}^m\sum_{t=1}^{T}\nabla_\theta{\textrm{log}}p_\theta\left( a_{t}^{\left( i \right)}| s_{t}^{\left( i \right)}\right)R\left( \tau^{\left( i \right)} \right)
\hat\eta 是 \nabla_{\theta}U\left( \theta \right) 的无偏估计 {\Bbb E}\left[ \hat\eta \right]=\nabla_\theta U \left( \theta \right)
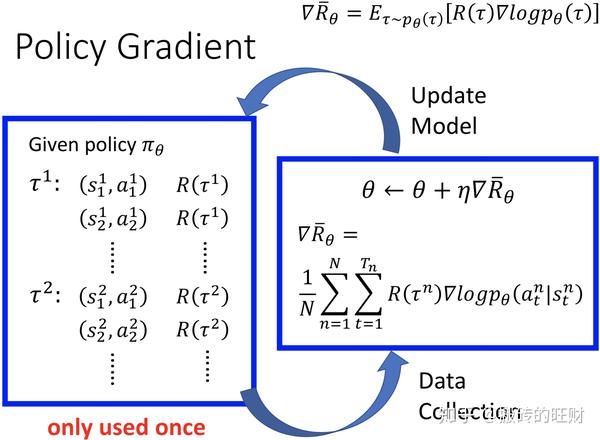

再次借鉴李宏毅教授的ppt,sample一些轨迹,然后就可以带入公式计算。
(注意:由于随机性,不是每次在相同的state都采取同样的动作action~)
更新model后又可以sample一些新的轨迹,循环往复~
请大家批评指正,谢谢 ~
文章被以下专栏收录
