Python爬虫数据提取之bs4的使用方法

之前的爬虫文章中我们给大家简单介绍了一下网页的基本结构,同时也认识了一些常见的HTML标签。因为爬虫就是从这些标签中提取数据。比如以我的知乎页面为例,要想提取文章列表中的每篇文章的标题和内容简介等信息,就要读懂HTML:
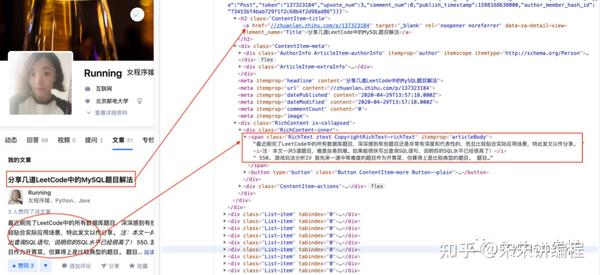

我们如何解析出来HTML标签中的内容呢?解析页面局部的文本内容,一般都会在标签之间或者标签对应的属性中进行存储,我们可以通过:
首先使用开发者工具进行标签的定位,然后提取标签或者标签对应的属性中存储的数据值
常见的方式有:
- 正则表达式
- bs4
- xpath
正则我们已经给大家简单介绍过了,本次主要介绍bs4的使用。
关注后台回复:”bs4爬取知乎“ 获取源码
Beautiful Soup 的简介
Beautiful Soup 是 python 的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup 提供一些简单的、python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据。
因为它属于第三方库,所以需要使用pip下载安装
pip install bs4 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install lxml -i https://pypi.tuna.tsinghua.edu.cn/simple安装的lxml是bs4在解析过程中所要使用的一种解析器。
除了lxml之外还有:
| 解析器 | 优点 | 缺点 |
|---|---|---|
| Python标准库 | Python的内置标准库、执行速度适中 、文档容错能力强 | Python 2.7.3 or 3.2.2前的版本中文容错能力差 |
| lxml | 速度快、文档容错能力强 | 需要安装C语言库 |
| html5lib | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
如果需要使用html5lib解析器,也是需要单独安装下载的
pip install html5lib如何使用
无论哪种解析器都需要导入BeautifulSoup,即: from bs4 import BeautifulSoup
from bs4 import BeautifulSoup
soup = BeautifulSoup(markup, "lxml") # 参数位置的markup表示从网络获取的网页页面当使用不同的解析器时只需要改变上面代码的第二个参数即可:
soup = BeautifulSoup(markup, "html.parser") # Python标准库
或者
soup = BeautifulSoup(markup, "html5lib") # html5lib库推荐使用lxml作为解析器,因为效率更高。
对象的种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag ,NavigableString ,BeautifulSoup , Comment 。
1.Tag
Tag即HTML中的标签,比如<div></div>,<p></p>,....
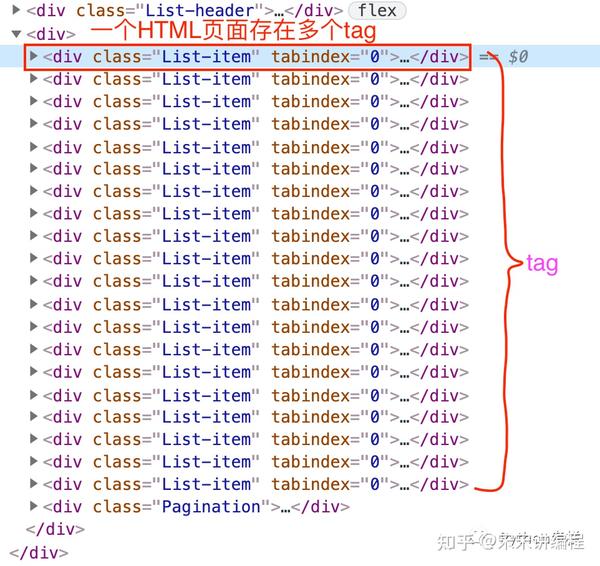
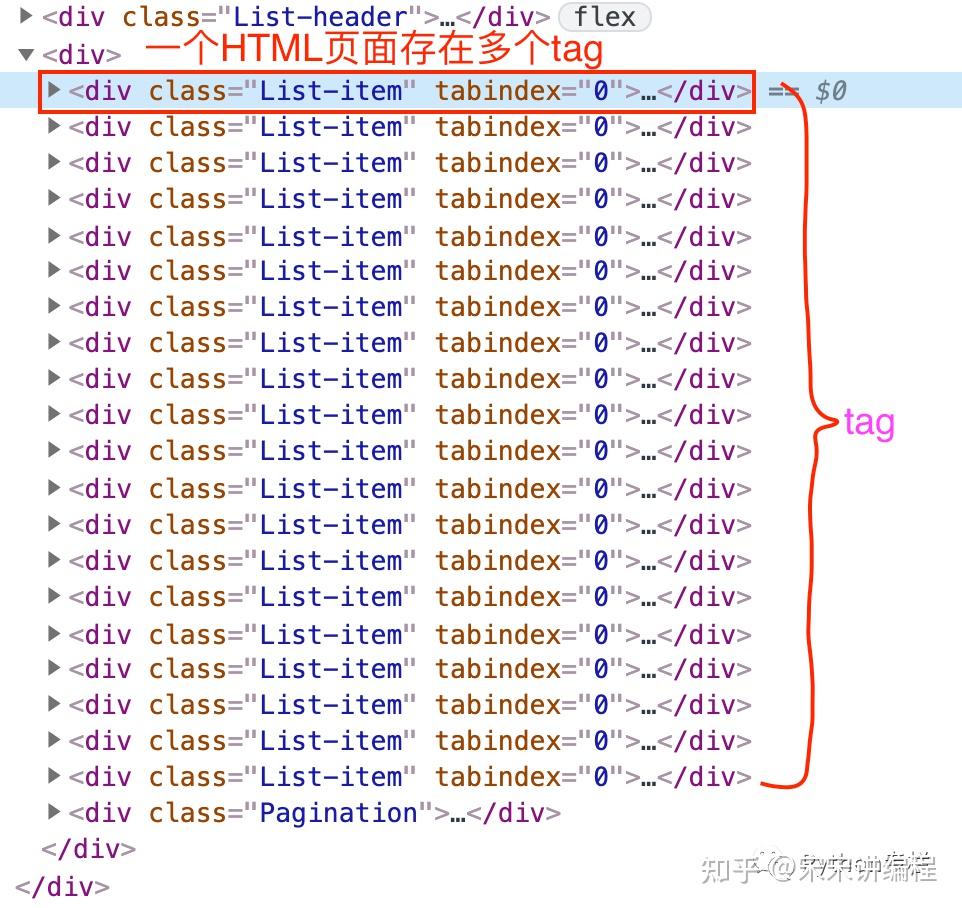
一个tag可能有很多个属性。比如
<a href="//zhuanlan.zhihu.com/p/137323184" target="_blank" rel="noopener noreferrer" data-za-detail-view-element_name="Title">分享几道LeetCode中的MySQL题目解法</a>
有 “href” 的属性,值为 “// http://zhuanlan.zhihu.com/p/137323184” ,有target属性,值为_blank。对于 Tag,它有两个重要的属性,是 name 和 attrs。
from bs4 import BeautifulSoup
markup = '<a href="//zhuanlan.zhihu.com/p/137323184" target="_blank" rel="noopener noreferrer" data-za-detail-view-element_name="Title">分享几道LeetCode中的MySQL题目解法</a>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.a) # 获取soup中的a标签对象
# 获取a标签对象的name和attrs属性
print(soup.a.name) # 获取标签名
print(soup.a.attrs) # 获取标签属性结果:
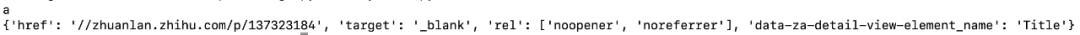

我们可以发现tag的属性的操作方法与字典相同,所以可以像操作字典一样操作属性。
print(soup.a.get('href'))
或者
print(soup.a.['href']))2.NavigableString
字符串常被包含在tag内. Beautiful Soup用 NavigableString 类来包装tag中的字符串。
from bs4 import BeautifulSoup
xml_soup = BeautifulSoup('<p class="body strikeout">我是一个段落</p>', 'lxml')
tag = xml_soup.p
print(tag['class']) # 获取class属性值
print(tag.string) # 获取tag中的文本内容
3.BeautifulSoup 和Comment(此部分了解即可不做举例)
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 TagTag , NavigableString , BeautifulSoup 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象是文档的注释部分Comment。Comment 对象是一个特殊类型的 NavigableString 对象
遍历文档树
遍历文档树就是把整个文档看成一颗树形结构。如下图
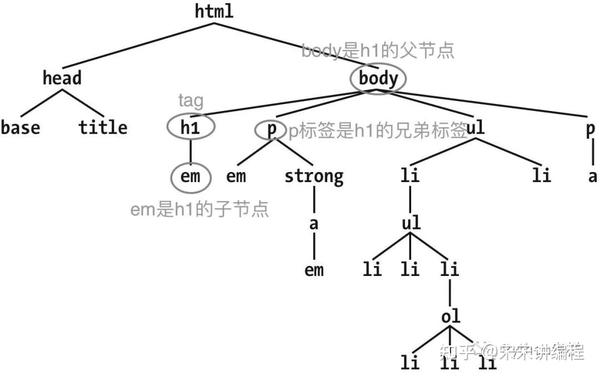

见上图我们以body为例:子节点一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。Beautiful Soup提供了许多操作和遍历子节点的属性。操作文档树最简单的方法就是告诉它你想获取的tag的name。
from bs4 import BeautifulSoup
markup = '<head><title>The Dormouse\'s story</title></head> <body><h1>我是<em>标题</em></h1><p><em>段落1</em><strong><a href="#"><em>链接测试</em></a></strong></p></body>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.body.name)
print(soup.body.contents)结果:


获取某个tag中的字标签可以使用属性:contents,返回结果是一个列表,也可以使用children属性,返回结果是一个生成器,可以通过for循环迭代输出每个子标签。如果想获取所有子孙节点可以使用:.descendants属性文本内容的获取如果想获取某个标签的文本内容可以使用.string 或者text,但是需要注意:
1.如果tag只有一个NavigableString类型子节点,那么这个tag可以使用.string得到子节点:
2.如果tag包含了多个子节点,tag就无法确定.string方法应该调用哪个子节点的内容,.string的输出结果是None.此时可以考虑使用text
for child in soup.body.children:
print(child.string)结果:
None
None
但是如果换成:
for child in soup.body.children:
print(child.text) # 也可以使用child.get_text() 两种方式是一样的结果只不过一个是属性,一个是调用方法。结果:
我是标题
段落1链接测试
父节点
每个tag或字符串都有父节点:被包含在某个tag中。如果想获取父节点或者所有的父节点可以考虑使用 .parent 属性或者 .parents 属性
from bs4 import BeautifulSoup
markup = '<html><head><title>The Dormouse\'s story</title></head> <body><h1>我是<em>标题</em></h1><p><em>段落1</em><strong><a href="#"><em>链接测试</em></a></strong></p></body></html>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.em.parent)结果:
<h1>我是标题</h1>
兄弟节点
next_sibling .previous_sibling 属性: .next_sibling 属性获取了该节点的下一个兄弟节点,.previous_sibling 则与之相反,如果节点不存在,则返回 None.next_siblings .previous_siblings 属性: 通过 .next_siblings 和 .previous_siblings 属性可以对当前节点的兄弟节点迭代输出
前后节点
.next_element .previous_element 属性与 .next_sibling .previous_sibling 不同,它并不是针对于兄弟节点,可以获取到临近它的上/下一个节点,而不分层次关系。
from bs4 import BeautifulSoup
markup = '<html><head><title>The Dormouse\'s story</title></head> <body><h1>我是<em>标题</em></h1><p><em>段落1</em><strong><a href="#"><em>链接测试</em></a></strong></p><div>div1</div><div>div2</div></body></html>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.p.next_sibling) # p的兄弟标签
print(soup.p.next_element) # 临近的节点结果:
<div>div1
<em>段落1
搜索文档树
- find_all( name , attrs , recursive , text , **kwargs ):find_all () 方法搜索当前 tag 的所有 tag 子节点,并判断是否符合过滤器的条件
name 参数 name 参数可以查找所有名字为 name 的 tag,当然name位置可以使用正则表达式、列表。keywords参数 即在find_all中可以跟关键字的参数部分,比如id = ‘div1’等等,但是需要注意的是**如果想用 class 过滤,不过 class 是 python 的关键词,这怎么办?加个下划线就可以即class_='xxxx'的形式,也可以通过 find_all () 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的 tag**
比如:
html结构的截图:
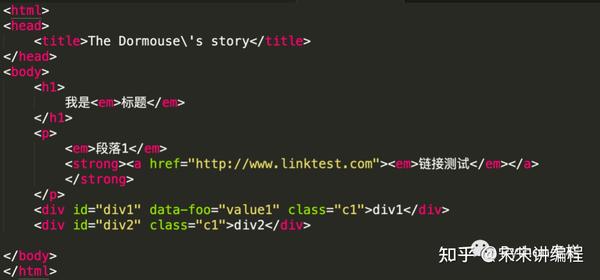
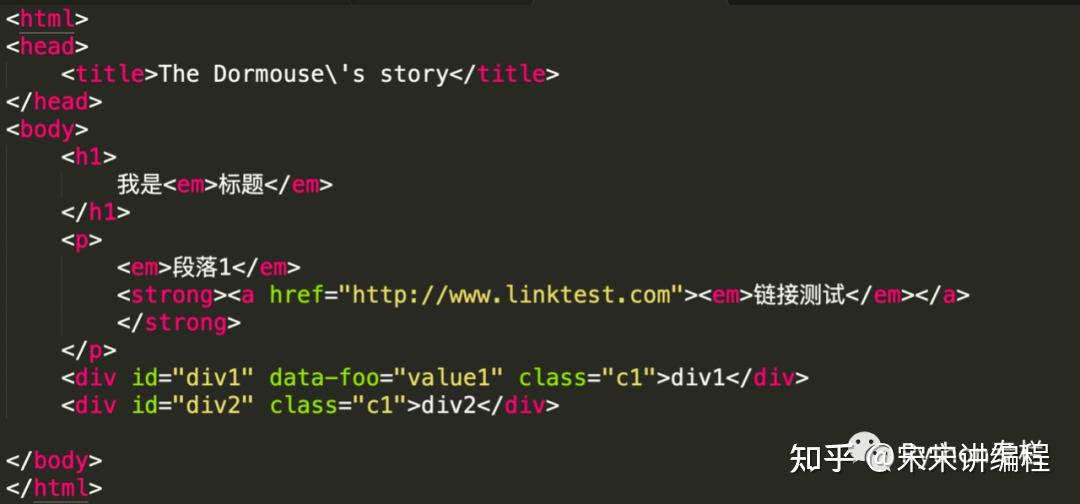
from bs4 import BeautifulSoup
markup = '<html><head><title>The Dormouse\'s story</title></head> <body><h1>我是<em >标题</em></h1><p><em>段落1</em><strong><a href="http://www.linktest.com"><em>链接测试</em></a></strong></p><div id="div1" data-foo="value1" class="c1">div1</div><div id="div2" class="c1">div2</div></body></html>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.find_all(name='div')) #查找所有的div标签
print(soup.find_all(id='div1')) # 查找id是div1的标签
print(soup.find_all(name='div',class_='c1')) # 查找有class=c1的div标签
print(soup.find_all(attrs={'data-foo':'value1'})) # 查找所有有属性是data-foo的标签

我们再看一个正则的例子(html内容不变):
import re
from bs4 import BeautifulSoup
markup = '<html><head><title>The Dormouse\'s story</title></head> <body><h1>我是<em >标题</em></h1><p><em>段落1</em><strong><a href="http://www.linktest.com"><em>链接测试</em></a></strong></p><div id="div1" data-foo="value1" class="c1">div1</div><div id="div2" class="c1">div2</div></body></html>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.find_all(href=re.compile("link"))) # href也是关键字的形式,值这个部分可以使用正则搜索查找
print(soup.find_all(text=re.compile("div"))) # tag中文本存在div的标签tag对象结果:


find( name , attrs , recursive , text , **kwargs )它与 find_all () 方法唯一的区别是 find_all () 方法的返回结果是值包含一个元素的列表,而 find () 方法直接返回结果。
from bs4 import BeautifulSoup
markup = '<html><head><title>The Dormouse\'s story</title></head> <body><h1>我是<em >标题</em></h1><p><em>段落1</em><strong><a href="http://www.linktest.com"><em>链接测试</em></a></strong></p><div id="div1" data-foo="value1" class="c1">div1</div><div id="div2" class="c1">div2</div></body></html>'
soup = BeautifulSoup(markup, 'lxml')
print(soup.find(name='div')) #查找所有的div标签,只返回一个
print(soup.find(id='div1')) # 查找id是div1的标签,只返回一个对象
print(soup.find(name='div',class_='c1')) # 查找有class=c1的div标签,只返回一个
print(soup.find(attrs={'data-foo':'value1'})) # 查找所有有属性是data-foo的标签,只返回一个结果:


css样式
我们在写 CSS 时,标签名不加任何修饰,类名前加点,id 名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
from bs4 import BeautifulSoup
markup = '<html><head><title>The Dormouse\'s story</title></head> <body><h1>我是<em >标题</em></h1><p><em>段落1</em><strong><a href="http://www.linktest.com"><em>链接测试</em></a></strong></p><div id="div1" data-foo="value1" class="c1">div1</div><div id="div2" class="c1">div2</div></body></html>'
# 创建soup对象
soup = BeautifulSoup(markup, 'lxml')
# 使用select选择器选择查找
print(soup.select('div')) # 通过标签选择器查找
print(soup.select('#div1')) # 查找id选择器是div1的标签
print(soup.select('.c1')) # 查找class类选择器是c1的标签结果:


也可以通过组合查找即和写 class 文件时,标签名与类名、id 名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1 的内容,二者需要用空格分开
print(soup.select('p em')) # 查找p中em标签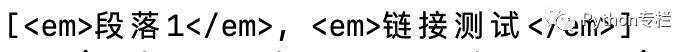

在选择器中查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print(soup.select("div[data-foo]")) # 查找有data-foo属性的div标签select的使用与 find_all 方法有异曲同工之妙的查找方法,是不是感觉很方便?
案例思考
爬取Running的知乎文章列表并保存到csv文件中,如何实现?
关注回复:”bs4爬取知乎“ 获取源码
系列文章
- 第1天:初识爬虫
- 第2天:HTTP协议和Chrome浏览器开发者工具的使用
- 第3天:urllib模块的基本使用
- 第4天:一文带你轻松掌握requests模块
- 第5天:正则表达式真的很6,可惜你不会写
- 第6天:搞定MySQL数据库,看这一篇就够了!
- 第7天:菜鸟用Python操作MongoDB,看这一篇就够了
- 第8天:redis在爬虫中的应用
- 第9天:HTML结构分析
最后,推荐一套Python视频,非常适合初学者和想深入了解Python语言的小伙伴,让你学习无忧!
期待大家学习完爬虫的全部课程之后,能有一个不错的收获~~~,Good Luck!!!
文章被以下专栏收录
