
基于商品包含关系的飞猪搜索排序优化

分享嘉宾:黄仔 阿里巴巴 高级算法工程师
编辑整理:王妍红 谢菲尔德大学
出品平台:DataFunTalk
导读:飞猪的商品有别于传统电商的商品,主要分为两大类,单品和复杂商品。复杂商品和单品之间存在着包含关系,这就给我们的优化搜索排序带来了挑战。本文将分享基于商品包含关系的飞猪搜索排序优化,主要包括以下几大方面:
- 飞猪搜索介绍
- 基于商品包含关系的排序优化挑战
- 模型介绍
- 离线实验评估
- 在线部署
--
01 飞猪搜索介绍
首先给大家介绍一下飞猪搜索。
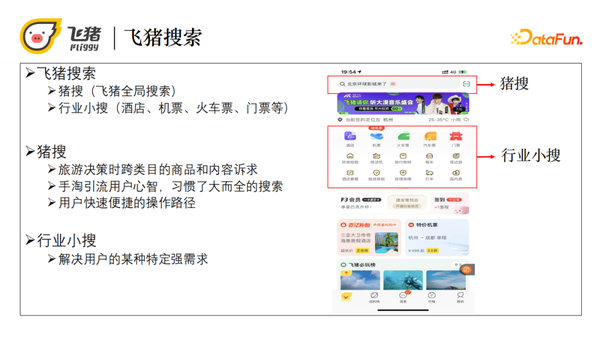

飞猪的搜索业务主要分为两大块:猪搜和行业小搜。猪搜是位于界面顶端的搜索框,主要是解决用户旅行决策时跨类目商品和内容诉求。很多用户习惯于使用大而全的搜索方式,因此猪搜为用户提供了一个快速便捷的操作入口。而界面中间的行业小搜主要解决用户的某种特定类目(如酒店、机票、火车票等)的强需求。
飞猪搜索业务中的排序主要起到的作用是流量分发和辅助用户购买决策。接下来依次介绍一下猪搜结果页排序的基本架构。
- QP(Query Planner):解析用户发出Query请求的意图。
- 召回:包含文本召回、商品属性召回、用户LBS城市召回、query和商品间的向量召回、图召回。
- 粗排:通过简单的规则将庞大的商品集合中取出一小部分。
- 精排:将CTR、CVR、GMV预估、类目预测等作为输入,输入到LTR模型中,从而得到最终候选商品的排序分。


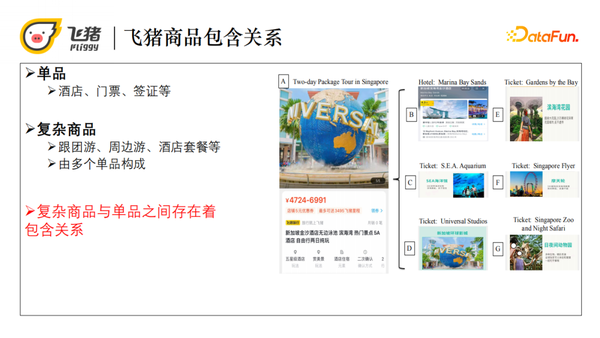
有别于传统电商的商品,飞猪的商品主要分为两大类:单品和复杂商品。例如,单品有酒店、门票、签证等,复杂商品有跟团游、周边游、酒店套餐等,它们是由多个单品构成。举个例子,请看下图,商品A是一个周边游的商品,它包含一个酒店和五张门票。所以复杂商品和单品之间存在着包含关系,这就给我们的优化排序到来了挑战。

--
02 基于商品包含关系的排序优化挑战
1. 挑战一
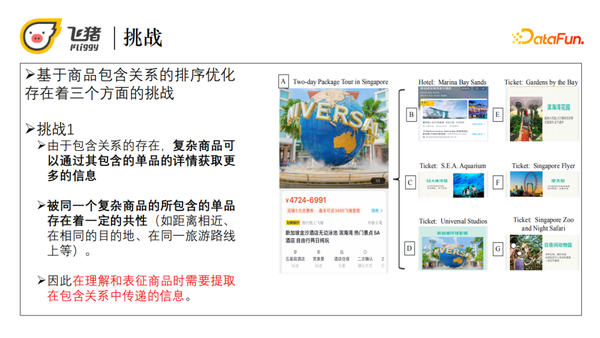
复杂商品可以通过它包含的商品来获取更多的信息,比如景点或者是某个目的地,被同一个复杂商品所包含的单品存在着一定的共性,例如它们存在相同的目的地,或在同一条旅行线上。因此在理解和表征商品时需要提取包含关系中传递的信息,就是商品之间的包含关系中传递的信息。

2. 挑战二
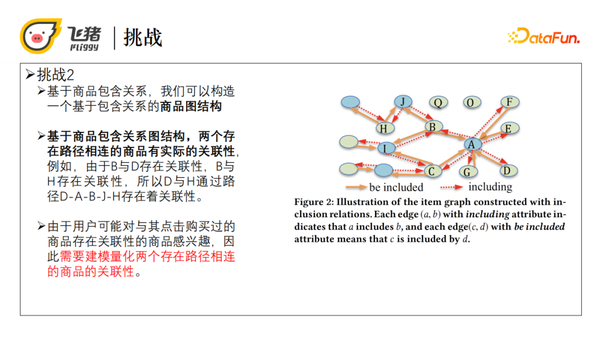
基于商品包含关系,我们可以构造一个基于包含关系的商品图结构,有了这个图结构就能发现两个存在路径相连的商品是有实际关联的,比如物理关联。举个例子,商品B和D都包含于同一个商品A,而商品B和H都包含于同一个商品J,所以他们就有一定的关联性。通过关联的传递性,商品D和商品H就通过路径D-A-B-J-H存在了关联性。用户可能对其点击或购买商品存在关联性的另一些商品感兴趣,所以需要在排序过程中建模量化两个存在路径相连的商品的关联性。

3. 挑战三
近年来很多研究都表明,通过衡量候选商品和用户点击加购的商品之间的相似性来获取用户的兴趣,可以很有效地进行CTR、CVR预估。所以除了基于商品表征空间的相似性,建模商品与商品之间的相关性之外,还需要考虑存在路径相连的商品的关联性,从而可以更好的获取用户的兴趣。
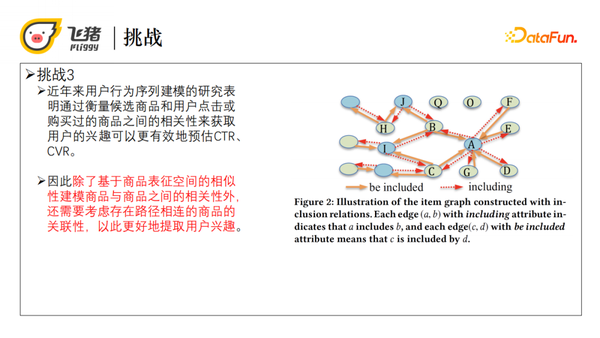

--
03 模型介绍
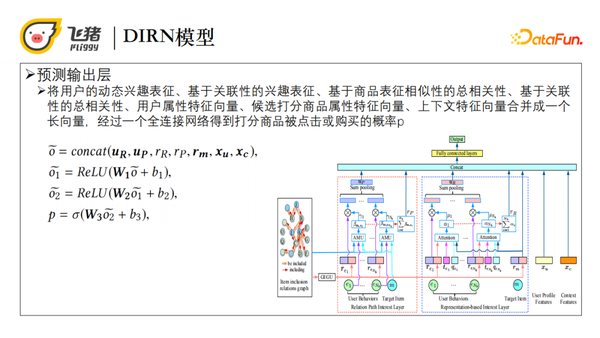
针对上述挑战,我们提出了DIRN模型,这个模型分为三个部分,第一部分是基于图的Embedding生成模块,第二部分是基于商品表征空间的相似性的用户兴趣层,第三部分是基于包含关系路径的用户兴趣层。模型的输入特征包括商品包含关系图、用户点击或购买行为序列、用户特征、打分商品特征、上下文特征等。而模型输出的是打分商品被点击或购买的概率。


首先介绍一下基于图的Embedding生成模块。我们利用GraphSAGE表征每个商品,提取在包含关系中传递的信息。具体来说就是通过预训练的GraphSAGE得到基于图的商品embedding表示,然后结合商品属性特征的向量,得到商品的向量表示。


基于商品表征的兴趣层主要是通过Attention计算商品之间的相关性,再根据商品的相关性获取用户的兴趣表征。由于用户的兴趣表征是动态变化的,我们引入了用户历史点击或购买序列的位置以及与当前请求时间的时间间隔。此处的Attention(αi),使用传统的Attention计算结构,表示商品和行为序列中第i个商品的相似性,从而得到用户的动态兴趣表征,即根据用户的列行为商品的表示μi后求加权和。最后对商品相似性αi求和得出基于商品表征相似性的总相关性。


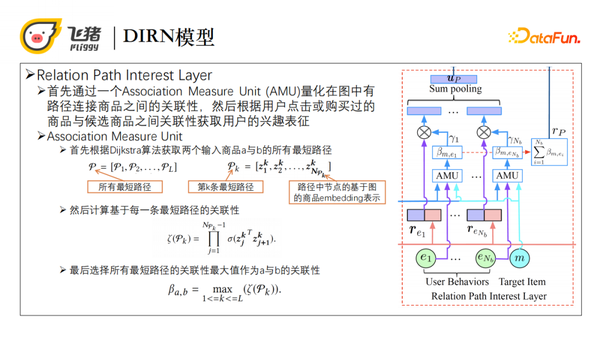
基于关系路径的兴趣层主要是通过AMU单元,量化有路径连接商品之间的关联性,根据历史点击或购买过的商品与候选商品之间的关联性,得到用户的兴趣表征。Association Measure Unit(AMU)实施路径是首先根据Dijkstra算法获取任意两个输入商品的所有最短路径。例如商品a和商品b的最短路径有L条,对于第k条最短路径,其中所有路径节点都是通GraphSAGE做的基于图的商品Embedding表示。第二步对每一条最短路径计算其关联性。由于关联性具有传递性,我们首先用内积的方式计算两个相邻节点之间的关联性,sigmoid后得到[0,1]的关联性,接着将所有节点两两点乘得到整条路径的关联性。最后我们选择所有最短路径中关联性最大的值作为a和b的关联性。

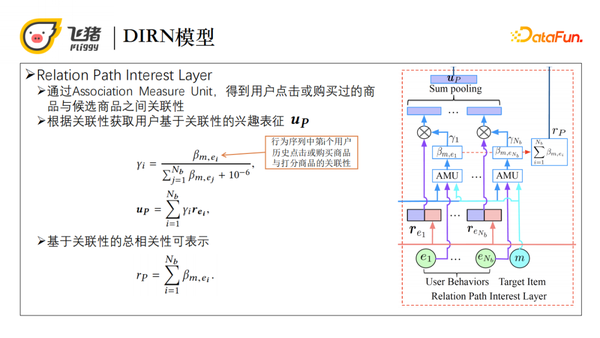
通过AMU我们得到了用户行为序列中历史点击或购买商品与候选商品的关联性,接着对关联性做归一化处理,进而获取用户基于兴趣的表征。

最后我们将用户的动态兴趣表征、基于关联性的兴趣表征、基于商品表征相似性的总相关性、基于关联性的总相关性、用户属性特征向量、候选打分商品属性特征向量、上下文特征向量合并成长向量,经过全连接网络最终得出候选商品被点击或购买的概率。

我们的模型训练分为三步。首先基于包含关系的图结构对GraphSAGE做预训练,从而得到每个商品基于图的embedding表示。接着使用Dijkstra算法得出任意两路径相连商品之间的所有最短路径,离线计算得到两商品之间的关联性。最后通过传统的LR分类方法,用CTR、CVR预估的损失来训练DIRN模型中的其他参数。


--
04 离线实验评估
用于实验的数据集来自猪搜结果页排序的一部分场景,包含1.56亿曝光点击样本。在这个数据集中,总共有130万以上的商品,其中超过30万商品是复杂商品,平均每个复杂商品中包含3.4个单品。我们将30天的点击样本作为训练集,将其后一天的样本作为测试集。商品特征包括商品ID,类目ID,城市ID特征,用户特征包括用户ID、年龄、性别。


我们使用业界中比较成功的模型作为基准模型,通过对比实验结果,我们可以发现DIRN模型在预测CTR指标的AUC和Logloss指标上的表现都是最理想的。相比于表现最好的基准模型DMR(Deep Match to Rank),DIRN模型在AUC指标上取得了0.75%的绝对增益。


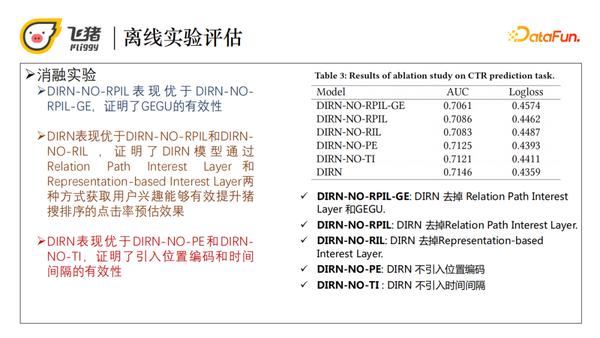
接下来我们做了消融实验,也就是把DIRN模型去掉一个组件(如关系路径兴趣层、基于图的表征层GEGU等)对比实验效果,实验结果请看下表3。仅去除关系路径兴趣层的DIRN模型(DIRN-NO-RPIL模型)表现优于去除所有图相关组件的DIRN-NORPIL-GE模型,证明基于图的表征层GEGU的有效性。
DIRN模型表现优于DIRN-NO-RPIL和DIRNNO-RIL , 证 明 了 DIRN 模 型 通 过Relation Path Interest Layer 和 Representation-based Interest Layer两种方式获取用户兴趣能够有效提升猪搜排序的点击率预估效果。DIRN表现优于去除位置编码和时间间隔的模型,从而证明了引入这些特征的有效性。

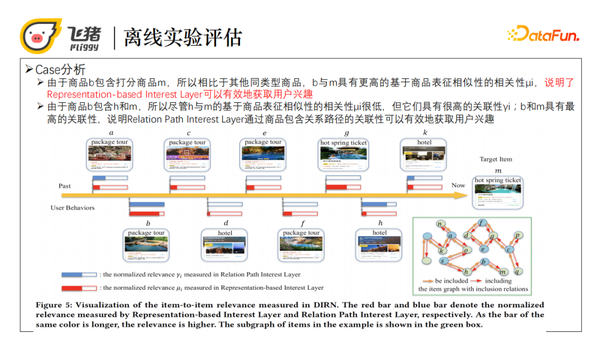
我们通过案例分析可视化模型中的基于表征相关性μi和基于关系路径的关联性γi,请看下图,商品b是一个周边游,它包含了打分候选商品m,所以相比于其他同类型商品,b与m具有更高的基于商品表征相似性的相关性μi,说明Representation-based Interest Layer的有效性。另一个例子是商品b包含商品h和商品m,尽管h与m基于商品表征相似性的相关性μi很低,但它们由于路径相连有较高的关联性γi,从而说明Relation Path Interest Layer通过商品包含关系路径的关联性是有效的。

--
05 在线部署
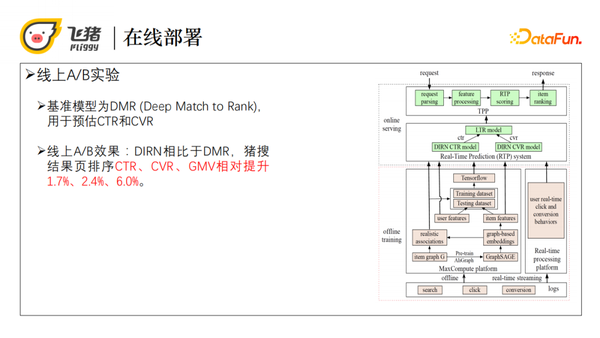
模型的在线部署主要分为两大块,包括离线训练和在线服务。
离线训练时我们首先利用阿里的AliGraph来预训练GraphSAGE,得到每个商品基于图的embedding表示,将其放入商品特征表中。然后计算任意两个有路径相连的商品的关联性,将其存入item graph中用于线上预估。最后CTR和CVR模型通过ESMM多任务学习的方式同时进行训练,并部署到RTP上。
在线服务主要是排序任务,我们的排序任务在阿里的服务平台TPP上进行。TPP首先处理输入请求参数、得到用户、query等特征以及获取候选打分商品集合,然后根据获取到的用户点击购买行为序列,调用RTP中CTR和CVR模型计算的打分候选商品的预估值,接着将CTR、CVR预估值与GMV、类目预估等其他预估值一起输入到LTR模型,最后得到每个候选商品的排序分。TPP根据LTR的排序分对候选商品集合排序,返回给猪搜结果页排序服务,透出给用户。


线上A/B实验的基准模型是去年阿里的一个用于预测CTR和CVR的模型DMR(Deep Match to Rank)。从线上A/B实验的效果看,DIRN相比于DMR,猪搜结果页排序CTR、CVR、GMV相对提升1.7%、2.4%、6.0%。

最后总结一下,本次分享介绍了商品包含关系在飞猪搜索排序的重要性和挑战,我们针对存在的挑战,提出了一个新的DIRN模型,充分利用商品包含关系优化猪搜排序的CTR、CVR预估。我们使用猪搜结果页排序的数据集进行了大量实验,对比SOTA模型,实验结果证明了DIRN模型的有效性。通过A/B实验,证明DIRN在CTR、CVR、GMV上取得了显著的提升。


--
06 精彩问答
Q1:GraphSAGE得到的商品embedding比用embedding lookup得到商品embedding有明显的提高吗?
A1:是有明显的提高。因为lookup是随机学习的,而GraphSAGE是预训练的,GraphSAGE的预训练是使得两个相邻节点的内积是最大的,所以说这部分对于关联性的学习是很重要的。
Q2:Embedding是怎么做的,embedding的维度大小是如何确定的,有什么具体的方式吗?
A2:这个问题更多是依靠业务经验的,在我们这里,GraphSAGE得到的embedding的维度大小一般是16或32维就可以表征很大的信息量了。
Q3:请问搜索排序中,单个商品和套餐类型的商品是用同一个模型进行混排的吗?
A3:是的,单品和套餐类型的商品是用同一个模型进行排序的
Q4:请问用户的动态兴趣数据形式是使用用户对每个列别的偏好数值,还是通过历史一个月的点击得到的偏好嵌入?
A4:我们是根据用户行为的商品embedding表示用户的兴趣,通过attention聚合产生用户兴趣的向量表示。还有一个兴趣值得表示是对所有相关性求和,这个值越高表示相关性越高。
Q5:请问你们的测评指标是直接看CTR一类的提升指标吗?有没有开源代码?
A5:最后的线上A/B测试效果是看线上用户的CTR、CVR、GMV等的提升显著程度。开源的代码目前暂时还没有。
今天的分享就到这里,谢谢大家。
阅读更多技术干货文章,请关注微信公众号“DataFunTalk”
添加小助手链接:
1.免费资料领取:点击上方链接添加小助手回复【大数据合集】免费领取《大数据典藏版合集》
回复【算法合集】免费领取《互联网核心算法合集》
2.添加交流群:点击上方链接添加小助手回复【大数据交流群】加入“大数据交流群”
回复【算法交流群】加入“算法交流群”
分享嘉宾:


关于我们:
DataFun:专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100+线下和100+线上沙龙、论坛及峰会,已邀请超过2000位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章600+,百万+阅读,13万+精准粉丝。
注:欢迎转载,转载请留言或私信。
文章被以下专栏收录
