
R语言(3)-四张图检验线性回归模型

好久不见,之前期中考然后生病然后出去旅游所以断更了一个星期。
话说上期简单线性回归的结尾提到了,有模型是件很简单的事情,但是模型可不可靠就是另一回事了。线性回归模型会出哪些问题呢?
- 原本的数据不是线性关系,不能简单用线性模型来描述
- 极端的样本点,包括三种情况:Leverage point, Outlier, 和Influential point,后面会详细介绍
- 误差不是一个常数
- 误差不服从正态分布
- 误差之间不相互独立
有人肯定觉得,那我画个散点图不就好了吗?
是,很多时候画个散点图用眼睛就能看出来是不是线性关系,有没有极端样本点。但是,第一,这是二维的情况,如果高维连图都没法画;第二,眼睛看并不准确,比如极端样本点到底多极端才会影响模型?误差到底是不是正态分布?
这时候就需要R的帮助了,有了一个拟合fit之后:
fit <- lm(y~x)
par(mfrow=c(2,2)) #用来把四张图同屏显示
plot(fit)锵锵锵锵!

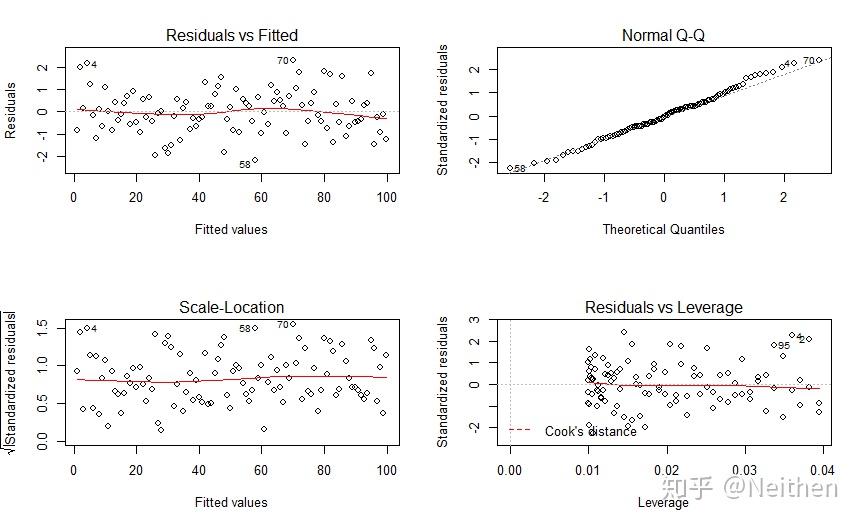
R产生了四幅图片,它们分别是做什么的呢?我们来一张一张看一下。
Residuals vs Fitted
这张图中横轴是y值(Fitted value),纵轴是残差(Residuals)。在这幅图中,我们希望看到残差的分布是比较均匀的,这样就代表误差分布符合Guaasian-Markov Condition。如果残差随着y值的增大而有增大或减小的趋势,或者残差的分布更近似于一个二次曲线,那么就意味着可能原本的数据并不是线性关系。这时候可以做一些求对数、求指数、求平方根等变换,然后再进行线性回归。


明显的非线性关系
Normal Q-Q
Q-Q图,全程Quantile-Quantile图,是把两个分布的quantile放在一起进行比较,来判断这两个分布是不是相似的。这幅图的作用就是检验误差是不是服从正态分布。如果是,这张图上的点将会贴近 y=x 这条直线。


从qq图上可以得到的信息
Scale-Location
这张图的作用基本和Residuals vs Fitted差不多,只不过换成了standardized residuals。可以更方便地看出误差分布的范围。

随着y的增加,误差分布得更广了
Residuals vs Leverage
这张图就是判断极端样本点最有用的图了。
首先讲一讲极端样本点的三个分类:
- Outlier:那些距离回归直线很远,无法被模型很好解释的点称为outliers。
- Leverage point:这样的点拥有很极端的x值。比如其他样本点的x值都只有几十,而有一个样本点的x值超过了100,这时候这个点将会极大地影响回归模型。就像物理中的力矩一样,这种样本点有很高的leverage,所以叫做leverage points。有的leverage points可以很好地融入模型中,不会对模型造成很大的影响,通常也叫做good leverage points。有时,这种good leverage points证明了模型的普适性;但是它们同时会增大 R^2 ,使我们对模型过度自信。所以good leverage points也并不是完全没有弊端。
- Influential point:有good leverage points自然有bad leverage points。既是leverage points又是outliers的点就被称为bad leverage points,也就是influential points。它们的存在极大地影响了模型的可靠性,因为它们会把回归直线向自己的方向“拉扯”。

在这张图上,横轴是leverage。通常大于 \frac{4}{n} (n是样本点的数目)的就算leverage points。
纵轴是residuals,通常小样本大于2,大样本大于4的算作outliers。
合起来,既有很高的leverage,又有很高的residual的就是influential points。用图上的Cook‘s distance来判定。小样本大于1,大样本大于 \frac{4}{n} 。

图上的49就是一个influential point
最近确实写专栏的新鲜劲逐渐消退,不知道有什么有趣的东西可以写。大家想看什么留个言叭,我也可以去学习一波。
文章被以下专栏收录
