
关于大数据的学习资料来源

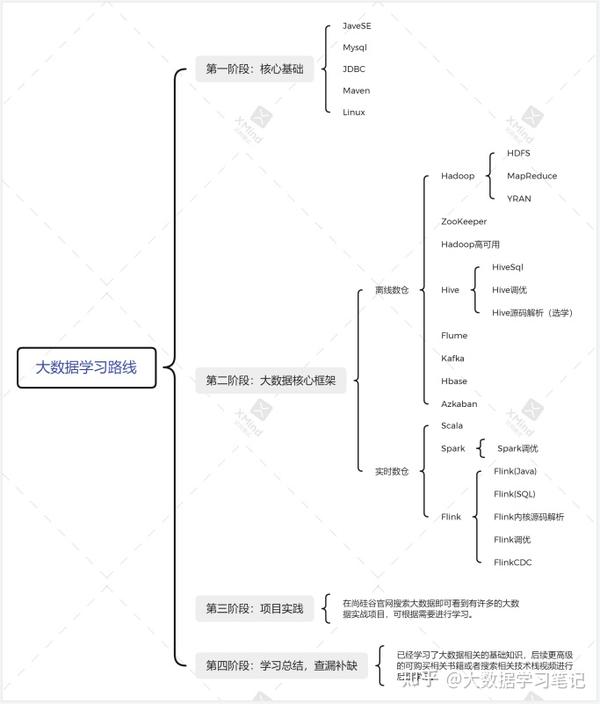

上篇文章已经提到过,我的学习路线是根据尚硅谷官网上的学习路线来指定的。所以我的学习资料,基本上来自尚硅谷免费发布的学习视频。
下面说一下具体的学习视频地址
JAVA核心基础
由于大数据开发是需要一定的编程基础的,并且hadoop是通过java语言实现的。所以java是我们学习大数据必须要掌握的一门语言。当然,我们并不是为了做java后端开发,所以并不需要学的太深,我们仅需要掌握java的核心基础即可。如果后续想要在大数据中走的更远更深,则需要对源码有一定的解读和修改能力,那么对于java就要更加深入的学习了。
Mysql学习 :除了语言的学习,我们在正式学习大数据前还需要掌握数据的相关技术知识。
Linux和shell :大数据平台毕竟是部署在linux上的,那么对于linux和shell 我们也要有一定的操作和编程能力
第二阶段:hadoop核心框架
1.Hadoop是一个由Apache基金会所开发的分布式系统基础架构,一个能够对大量数据进行分布式处理的软件框架; Hadoop以一种可靠、高效、可伸缩的方式进行数据处理;用户可以在不了解分布式底层细节的情况下,开发分布式程序
2.ZooKeeper是一个经典的分布式数据一致性解决方案,致力于为分布式应用提供一个高性能、高可用,且具有严格顺序访问控制能力的分布式协调服务。
分布式应用程序可以基于ZooKeeper实现数据发布与订阅、负载均衡、命名服务、分布式协调与通知、集群管理、Leader选举、分布式锁、分布式队列等功能。
3.hadoop高可用集群搭建: Hadoop实现高可用主要有两种方式,一种是使用共享日志编辑系统(QJM),另一种是基于网络文件系统(NFS)的高可用方案。基于NFS的高可用方案需要额外安装NFS服务器,而QJM的高可用方案不需要安装额外的服务器。两种高可用方案都依赖于Zookeeper。
4.hive:hive是基于 Hadoop的一个 数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供 SQL查询功能,能将 SQL语句转变成 MapReduce任务来执行。Hive的优点是学习成本低,可以通过类似SQL语句实现快速MapReduce统计,使MapReduce变得更加简单,而不必开发专门的MapReduce应用程序。hive十分适合对数据仓库进行统计分析。
5.Flume最早是Cloudera提供的日志收集系统,是Apache下的一个孵化项目,Flume支持在日志系统中定制各类数据发送方,用于收集数据。
6.Kafka是由 Apache软件基金会开发的一个开源流处理平台,由 Scala和 Java编写。Kafka是一种高吞吐量的 分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像 Hadoop一样的 日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过 Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过 集群来提供实时的消息。
7.HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的 分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
8.Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通过简单的key:value对的方式,通过配置中的dependencies 来设置依赖关系,这个依赖关系必须是无环的,否则会被视为无效的工作流。Azkaban使用job配置文件建立任务之间的依赖关系,并提供一个易于使用的web用户界面维护和跟踪你的工作流。
9.Scala 是一种多范式的编程语言,其设计的初衷是要集成面向 对象编程和函数式编程的各种特性。Scala 运行于 Java 平台 (Java 虚拟机),并兼容现有的 Java 程序。
10.spark是一种快速通用的大规模数据处理引擎
11.Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
第三阶段:项目实战
1.离线数仓项目
2.实时数仓项目
以上,便是我在学习大数据时用到的学习资料。
除了这些在线学习的视频地址,还有很多文字资料保存在网盘中。有朋友想要的话可以私信我。