
评价指标|precision recall ROC AUC | mAP |人脸识别指标 | 图像质量评价指标

1. 分类
1.1 True vs False, Positive vs Negative
以二分类为例,分类结果共有四种可能:(混淆矩阵)


第一个单词表示模型是否预测正确,True即表示模型预测结果是对的,False表示模型预测结果是错的,第二个单词表示模型预测的类别为正还是负,Positive则表示模型预测某样本为正类,Negative表示模型预测某样本为负类。
True Positive表示模型预测为正类,且预测对了
True Negative表示模型预测为负类,也预测对了
False Positive表示模型预测为正类,但预测错了,也就是该样本的正确类别为负,误报
False Negative表示模型预测结果为负类,但预测错了,也就是该样本的正确类别为正,漏报
另外,根据TP TN FP FN会有一些指标的计算:(下面这四个指标都是行指标,分母都是行的和)
真阳性率(True Positive Rate,TPR) / 灵敏度(Sensitivity) / 召回率(Recall) : 在所有实际为正类的样本中,有多少比例的样本被正确地判断为正类;随机拿一个正类样本时,有多大的概率会将其预测为正类,越大越好
TPR = Sensitivity = Recall = \frac{TP}{TP+FN}
真阴性率(True Negative Rate,TNR) /特异度(Specificity):在所有实际为负类的样本中,有多少比例的样本被正确地判断为负类,其实本质是对负样本的召回能力
TNR = Specificity = \frac{TN}{TN+FP}
假阴性率(False Negative Rate,TNR) / 漏诊率 / (1-灵敏度):在所有实际为正类的样本中,被错误地判断为负类的比率
FNR = \frac{FN}{FN+TP}
假阳性率(False Positive Rate,FPR) / 误诊率 / (1-特异度):在所有实际为负类的样本中,被错误地判断为正类的比率;随机拿一个负类样本,有多大概率会将其预测成正类,越小越好
FPR = \frac{FP}{FP+TN}
以上四个指标,分母都是表1中行上的加和 (即TP+FN,或者FP+TN),具体算的是什么率分子上就是什么。
1.2 Accuracy, Precision, Recall
accuracy表示模型预测正确的比例,=预测正确的样本数量/总样本数量。对于二分类任务来说,
accuracy = \frac{TP+TN}{TP+TN+FP+FN}
看一个肿瘤预测的例子来深入理解这个指标。
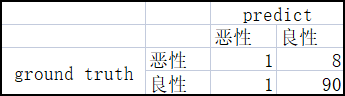
accuracy=(90+1)/(90+1+8+1)=91%,模型的accuracy有91%,乍一看是不是表示模型挺好的?
在这个例子中,一共100个样本,91个是良性的,9个是恶性的。在91个良性肿瘤中,模型预测对了90个,表现不错,但在9个恶性肿瘤中,只预测对了一个,有8个恶性肿瘤没有被诊断处理,这就很可怕了,说明这个模型根本不可以。假设有另一个分类器它总是预测为良性,对这100个样本来说,它的accuracy也有91%,但它一味的预测为良性,是没有任何判别恶性/良性的能力的。
在数据集存在类别不平衡时,accuracy这个指标并不能说明全部的情况,两个更好的指标是precision和recall。
precision解决的问题是 在模型预测为正类的这些样本中,有多少是预测正确的,比如上面的例子,模型预测了2个恶性,但只有1个预测对了,那么precision=1/(1+1)=50%。换句话说,当它预测一个肿瘤是恶性的时候,它有50%的正确率。
recall解决的问题是 在所有的正类样本中,模型预测出来多少,比如上面的例子,真实情况一共有9个恶性,但模型只预测出来1个,那么recall=1/(1+8)=11%。换句话说,它能正确识别11%的恶性肿瘤。
precision = \frac{TP}{TP+FP} , (分母是列向的加和),假设模型预测的正类有100个,只有90个是对的,precision=90/100=90%
recall = \frac{TP}{TP+FN} ,(分母是横向的加和),假设正类真实有200个,但模型只预测到其中的90张,则recall=90/200=45%
要评估一个模型的有效性,要同时查看precision和recall这两个指标,但不幸的是这两个指标通常是处于拔河状态,提高precision通常会降低recall,反之亦然。
下面再来看一个垃圾邮件分类的例子,一共30个样本,阈值右边的判定为垃圾邮件,左边的判定为非垃圾邮件。
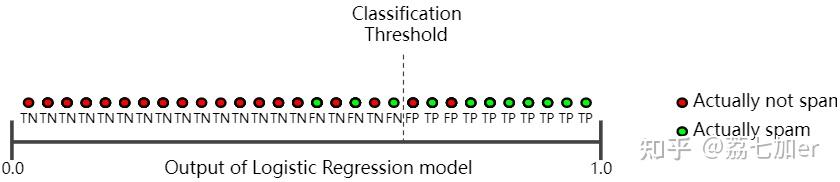


precision表示模型预测的垃圾邮件中是正确的百分比,即阈值线右边绿色的点/阈值线右边所有的点
recall表示在所有的垃圾邮件中被正确预测出来的百分比,即阈值线右边绿色的点/所有绿色的点
precision=8/(8+2)=80%, recall=8/(8+3)=73%
接下来看一下调大阈值的情况:
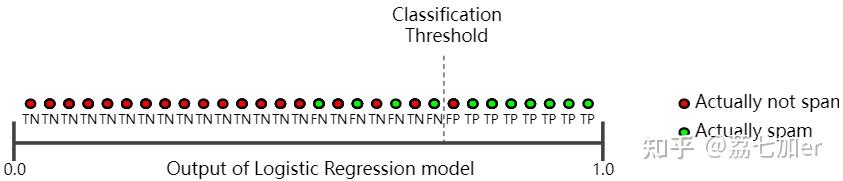

precision=7/(7+1)=88%, recall=7/(7+4)=64%
再来看看降低阈值的情况:
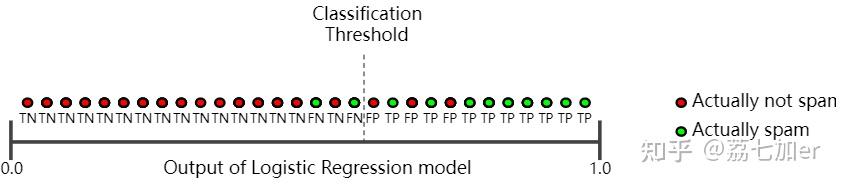

precision=9/(9+3)=75%, recall=9/(9+2)=82%
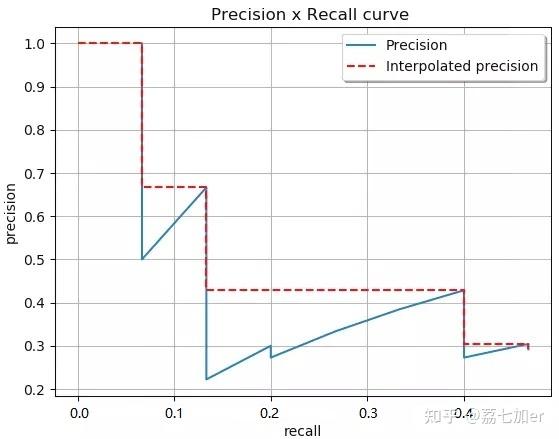
1.3 PR曲线
纵坐标为precision,横坐标为recall,这两个指标都聚焦于正样本。
曲线上的每个点表示在不同阈值下的P和R。假设有30个样本,模型对每个样本都会得到一个预测为正类的scores,根据这个scores进行排序,然后将每个score依次作为阈值,这样就能得到30组Precision vs Recall,便可以做出PR曲线图。
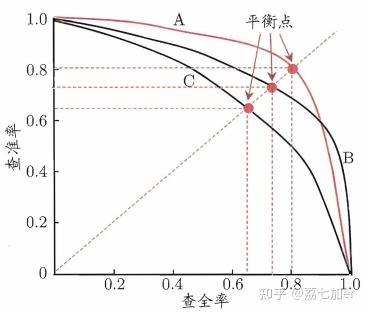
PR曲线越靠近右上角,分类器效果越好。如果一个模型的曲线完全把另一个模型的曲线包住(如上图中的A和C),则前者的性能更优。如果两个模型的PR曲线发生了交叉(如上图中的A和B),则不好轻易判断谁好谁坏。可以考虑的思路有(1)曲线下的面积,在一定程度上表征了分类器在P和R上取得“双高”的比例;(2)平衡点(Break-Event Point, BEP),即precision=recall时的取值,谁大谁好;(3)F1-score,F1是precision和recall的调和平均值, F_{1} = \frac{2\times P\times R}{P+R} ,\frac{1}{F_{1}} = \frac{1}{2}\cdot(\frac{1}{P}+\frac{1}{R}) 。
1.4 ROC, AUC
ROC曲线(receiver operating characteristic curve, 受试者工作特征曲线)也是显示分类模型在所有分类阈值下的性能的图形。共包含两个参数,True Positive Rate(TPR, 真阳性率,y轴) 和 False Positive Rate(FPR, 假阳性率,误诊率,x轴)。
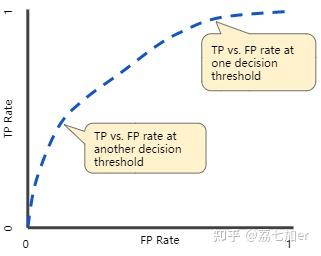
在医生诊断病人时,目标是尽量把有病的找出来,也就是TPR要越高越好,而FPR表示把没病的误诊为有病的,这个要越低越好。这两个指标也是相互制约的。如果某个医生对于有病的症状比较敏感,小症状也判断为有病,那么他的TPR指标应该比较高,同时FPR也会升高,极端情况他把所有样本都看作有病,那么TPR和FPR均为1。

点(0,1),即FPR=0,TPR=1,最完美的情况,预测全对。
点(1,0),即FPR=1,TPR=0,最糟糕的情况,预测全错。
点(0,0),即FPR=0,TPR=0,所有样本都预测为负类,此时分类阈值采用的最大。
点(1,1),即FPR=1,TPR=1,所有样本都预测为正类,此时分类阈值采用的最小。
点A处,TPR>FPR, 判断大体上是正确的;点B处,TPR=FPR, 判断是随机的,一半对,一半错;点C处,TPR<FPR, 判断大体上都是错误的。
FPR越大,预测正类中实际负类越多;TPR越大,预测正类中实际正类越多。
如果一个点越接近左上角,那么说明模型的预测效果越好。曲线距离左上角越近,说明分类器效果越好。
若要得到ROC曲线上的点,可以用不同的分类阈值多次评估分类模型。假设有30个样本,模型对每个样本都会得到一个预测为正类的概率scores,根据这个scores进行排序,然后将每次概率值依次作为阈值,这样就能得到30组TPR vs FPR,便可以做出ROC曲线图。
降低分类阈值将会把更多的样本分为正类,因此会同时增加false positive和true positive。阈值从1到0慢慢移动时,FPR会越来越大,即假正例会越来越多,ROC曲线上从左到右阈值是逐渐减小。
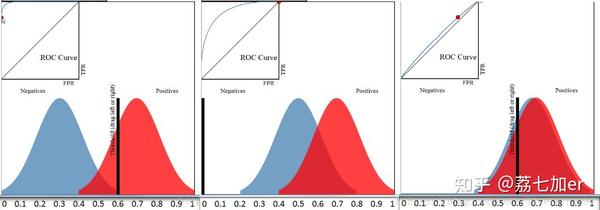

上图中横轴表示模型预测为正例的概率,纵轴表示样本数。蓝色区域表示所有负例样本的概率分布,红色区域表示所有正例样本的概率分布。红色区域越接近1越好,蓝色区域越接近0越好,蓝红区域越能分离开,模型效果越好。在上面三幅图中,左图蓝红重叠区域最小,ROC曲线最接近左上角;随着重叠区域增大,模型效果越差,ROC曲线越接近中线。
当一个分类器训练好了之后,上图中的那个红色和蓝色的小山就已经确定下来了,但是TPR和FPR是不确定的,因为它们可以根据选择的阈值发生变化。当我们不断地去调整阈值,就会得到不同的点,将这些点连起来就得到了ROC曲线。所以ROC曲线是反应红色和蓝色小山分布情况的一条曲线。一个分类器分类能力越强,那么这两个小山就离得越远。 ——引用自 参考链接4
AUC表示ROC曲线下的面积,area under the ROC Curve,如下图阴影区域的面积即为AUC。AUC的一种解释就是模型对一个随机正样本的得分高于一个随机负样本得分的概率。

AUC取值范围从0到1,值越大表示分类器效果越好,0表示预测全错,1表示预测全对。AUC=1时,是个完美分类器,表示该模型至少存在一个阈值能做出全对的预测,所有的正例都排在负例的前面。AUC=0.8,表示有百分之八十的正例排在负例的前面。AUC<=0.5,模型就没啥价值了。


AUC有两个特性:与尺度无关,它表示的是预测结果排名的好坏,如果对所有样本的概率值乘上2,AUC还是一样的;与分类阈值无关。
1.5 ROC曲线 vs PR曲线
ROC曲线有一个特性:当测试集中的正负样本分布发生变化了,ROC曲线可以保持不变。在实际的数据集中经常会出现类不平衡现象。下图是ROC曲线和PR曲线的对比:
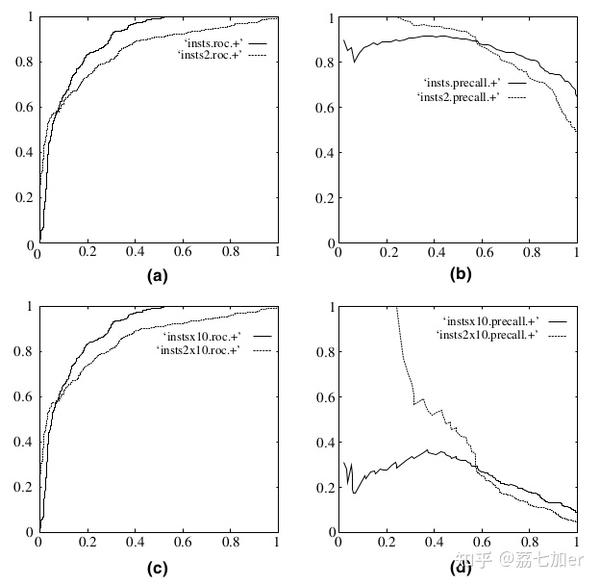

可以明显的看出,ROC曲线基本没变,而PR曲线变化较大。
我们的测试数据集中的反例数目远远多于正例的数目,假设负样本:正样本=1000:10.在这种情况下,当阈值为最大时,真正率和假正率还是都为0,随着我们不断调小阈值真正率和假正率还是在不断提高, 当阈值最小时真正率和假正率达到最大.因此ROC曲线没有很好地体现出样本类别分布不平衡对模型产生的影响,甚至导致对模型性能有错误的解释.
样本不平衡时,负样本有很多,这导致FPR的增长不明显,FP的大幅增长只能换来FPR的微小改变,所以虽然大量负例被错判成正例,在ROC曲线上却无法直观地看出来,ROC曲线会呈现一个过分乐观的效果估计。
举个栗子看看~
数据集正负样本比例1:1,下表是模型采用某一阈值时的分类结果,此时TPR=Recall=90/(90+10)=90%, FPR=60/(60+40)=60%,precision=90/(90+50)=64%

当负样本变为10倍时,预测的概率分布不会有很大变化,此时TPR还是等于90/(90+10)=90%,FPR=600/(600+400)=60%,precision=90/(90+600)=13%

上面的例子中,TPR和FPR没什么变化,而precision却出现了明显的下降,所以当样本不平衡时,在ROC曲线上可能反应不出来,而在PR曲线上可以看到明显变化。
当测试集类别分布大致均衡的时候可以用ROC曲线,当类别分布非常不均衡的时候采用PR曲线。PR曲线的两个指标都聚焦于正例,类别不平衡问题中主要关心正例,所以在此情况下PR曲线更优。
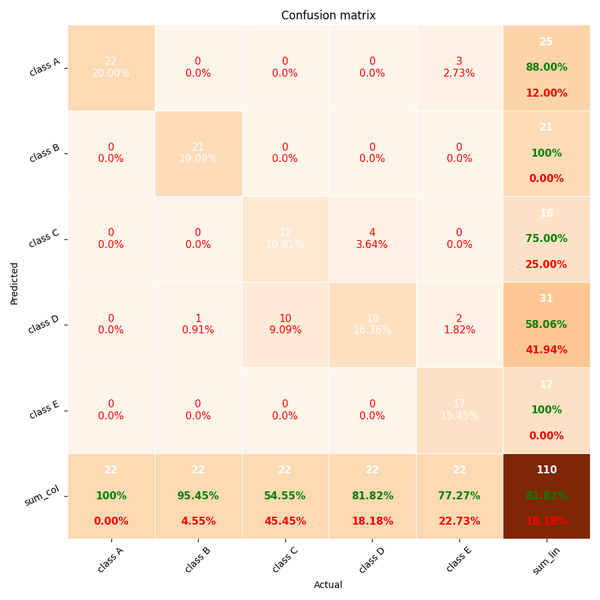
1.6 计算confusion matrix的代码库
pretty-print-confusion-matrix
示例图:

2. 检测
2.1. mAP
mAP:average of AP for each class
AP: average of precision at different recalls, PR曲线下的面积
TP: 与ground truth的IOU > 0.5
FP: 与ground truth的IOU <= 0.5,同一个ground truth的多余检测框
FN: 没有检测到的ground truth
mAP@.5:IOU>0.5认为是TP
mAP@.5:.95:IOU分别取0.5,0.55,0.6,0.65 ... 0.95,得到多个mAP,然后取平均
每个预测的box都会有一个关于某个类别的置信度,首先按照confidence从高到低的顺序进行排序,然后计算P = TP / (TP + FP)和R = TP / (TP + FN) for each possible rank k = 1 up to the number of predictions. So now you have a (P, R) for each rank those P and R are the "raw" Precision-Recall curve. To compute the interpolated P-R curve foreach value of R you select the maximum P that has a corresponding R' >= R.
有两种方式来采样PR曲线上的点,在VOC2010以前,select the maximum P obtained for any R' >= R, which R belongs to 0, 0.1, ..., 1 (eleven points),AP就是这11个precision的平均值。在VOC2010及以后,still select the maximum P for any R' >= R, while R belongs to all unique recall values (include 0 and 1)。AP就是PR曲线下的面积。Notice that in the case that you don't have a value of P with Recall above some of the thresholds the Precision value is 0.
计算示例:
假设对于aeroplane类别,有如下输出,BB表示预测的box的序号,一共有7个ground truth,除了检测到的五个以外,还有两个没被检测到,也就是FN=2,BB3是BB1的重复检测。从下表中可以看出,TP有5个(BB1, BB2, BB6, BB9, BB10),FP也有5个(BB3, BB4, BB5, BB7, BB8)。
| BB | confidence | 对应的gt的序号 | ||
|---|---|---|---|---|
| 1 | BB1 | 0.9 | 1 | |
| 2 | BB2 | 0.9 | 2 | |
| 3 | BB3 | 0.8 | 1 | |
| 4 | BB4 | 0.7 | 无gt对应 | |
| 5 | BB5 | 0.7 | 无gt对应 | |
| 6 | BB6 | 0.7 | 3 | |
| 7 | BB7 | 0.7 | 无gt对应 | |
| 8 | BB8 | 0.7 | 无gt对应 | |
| 9 | BB9 | 0.7 | 4 | |
| 10 | BB10 | 0.7 | 5 |
然后就可以按照confidence的排序给出各处的PR值,(上表已经是按照confidence排序的),计算结果如下:
rank1 precision=1/1=1 recall=1/7=0.14
rank2 precision=2/2=1 recall=2/7=0.29
rank3 precision=2/3=0.67 recall=2/7=0.29
rank4 precision=2/4=0.5 recall=2/7=0.29
rank5 precision=2/5=0.4 recall=2/7=0.29
rank6 precision=3/6=0.5 recall=3/7=0.43
rank7 precision=3/7=0.43 recall=3/7=0.43
rank8 precision=3/8=0.38 recall=3/7=0.43
rank9 precision=4/9=0.44 recall=4/7=0.57
rank10 precision=5/10=0.5 recall=5/7=0.71计算出来各个PR值以后,就可以计算AP了,
VOC2010之前,recall选取0, 0.1,...,1, 我们计算的PR值,并没有正好在recall=0处有precision,所以取recall>=0时的precision的最大值,recall=0.1时,取recall>=0.1时的precision的最大值,同理直到recall=1。所有这11处的precision分别为1, 1, 1, 0.5, 0.5, 0.5, 0.5, 0.5, 0, 0, 0, 此时aeroplane类别的AP为 5.5/11=0.5.
VOC2010及以后,recall选取0, 0.14, 0.29, 0.43, 0.57, 0.71, 1,同样是取recall>=0, 0.14, ..., 1的precision的最大值,分别为1, 1, 1, 0.5, 0.5, 0.5, 0,此时aeroplane类别的AP为 (0.14-0)*1 + (0.29-0.14)*1 + (0.43-0.29)*0.5 + (0.57-0.43)*0.5 + (0.71-0.57)*0.5 + (1-0.71)*0= 0.5.



mAP就是对每一个类别都计算出AP然后再取所有AP的平均值。
3. 人脸识别
人脸的性能度量中涉及到的三个数据集:
(1)底库数据集G(gallary)
(2)测试集p_G,G中的人员但与G中的图像不同(库内人员的测试图像)
(3)测试集p_N,不属于G中的人员图像组成(库外人员的测试图像)
人脸验证(face verification): are you who you say you are? 你是不是你说的那个人。1:1,比较两张照片(底库数量为1),判断是不是同一个人。
人脸识别(face identification): who are you? 你是谁。1:N,给定一张图像,判断其是底库中的谁,可以理解为底库数量为N的1:1,即回答N次are you who you say you are。
3.1 face verification的指标
TP:相似度大于给定阈值,且真实为同一个人的 图像对
FP:相似度大于给定阈值,且真实不是同一个人的 图像对
FN:相似度小于给定阈值,且真实为同一个人的 图像对
TN:相似度小于给定阈值,且真实不是同一个人的图像对
通过率(True accept rate,TAR), 正确地接受了,也就是TPR,(也就是分类中的召回)。
误识率(false acceptance rate,FAR),错误地接受了,不同人脸的匹配分数大于阈值,从而被认为是相同的人脸,把不应该匹配的人当成匹配的比例,也就是FPR。认错人了
拒识率(false rejection rate,FRR),错误地拒绝了,相同人脸的匹配分数低于阈值,从而被认为是不同人脸,把应该匹配的人当成不匹配的比例,也就是FNR。本该认识你,却没认出来
TAR和FAR作的图就是ROC曲线图。
FAR=\frac{非同人分数>T的次数}{非同人比较的次数} , TAR=\frac{同人分数>T的次数}{同人比较的次数}
一般会计算FAR固定值(如 10^{-3},10^{-6} )下的TAR
3.2 face identification的指标
闭集测试:
rank-K@底库规模,rank-K是指对每幅测试图像,按照相似度对结果进行排序,前K个结果中包含真实label的图像数量占所有测试图像的比例,K要小于等于底库规模,当K=底库规模时,rank-K就等于1了。假设底库有1000个人,对于100张测试图像,其首位就识别正确的图像有90张,则rank-1为90%@1000.
K值越大,rank-K也就越大,以K为横轴,rank-K为纵轴,画的图就是CMC曲线。
开集测试:
常用的指标有rank-K@FAR,TAR@FAR。
开集测试中,测试结果共有5种情况:
(1)库内人员的测试图像,相似度大于阈值,识别结果正确,这样的样本个数记作 IBC(in/bigger/correct)
(2)库内人员的测试图像,相似度大于阈值,识别结果错误,这样的样本个数记作 IBE(in/bigger/error)
(3)库内人员的测试图像,相似度小于阈值,这样的样本个数记作IS(in/smaller)
(4)库外人员的测试图像,相似度大于阈值,这样的样本个数记作OB(out/bigger)
(5)库外人员的测试图像,相似度小于阈值,这样的样本个数记作OS(out/smaller)
rank-K@FAR: (越大越好)
rank-K = \frac{前K个结果中包含正确label的IBC}{库内人员的测试集数量} , FAR=\frac{OB}{库外人员的测试集数量}
根据FAR的取值确定阈值,报告各阈值下的rank-K值。
TAR@FAR:(越大越好)
TAR=\frac{IBC}{库内人员的测试集数量}
根据FAR的取值确定阈值,报告各阈值下的TAR值。
FRR@FAR:(越小越好)某个阈值下有多大比例的库内人员没有识别结果
FRR=\frac{IS}{库内人员的测试集数量}
根据FAR的取值确定阈值,报告各阈值下的FRR值。
4. 图像/视频质量评价
为了衡量方法测试结果与主观评价之间的一致性,视频质量专家组VQEG(video quality experts group)提出了四个可以验证客观评价结果与主观评价结果之间的紧密程度的指标:PLCC,SROCC,KROCC,RMSE。
RMSE
假设 p_i 和 s_i 分别表示算法预测得分和主观质量分数(MOS)
RMSE = \sqrt{\frac{\sum_{i=1}^{n}{(s_i-p_i)^2}}{n}}
rmse越接近0,表示算法的性能越好。比较的是预测结果和MOS之间的绝对误差,如果MOS取值不一样,则rmse的计算受影响,所以计算前需要先进行归一化。
PLCC(皮尔逊系数)
PLCC = \frac{S和P的协方差}{S的标准差*P的标准差}= \frac{\sum_{i=1}^{n}{(p_i-\bar{p})(s_i-\bar{s})}}{\sqrt{\sum_{i=1}^{n}{(p_i-\bar{p})^2}} \sqrt{\sum_{i=1}^{n}{(s_i-\bar{s})^2}}}
取值范围-1~1,在0-1表示正相关,值越大表示正相关性越强。
协方差是有单位的,除以各自的标准差后,单位就约掉了,(无量纲化),不同变量之间的相关系数就可以进行比较了。协方差会受两个变量实际数值大小的影响,有可能出现两对变量相关度差不多,但协方差数值差异很大。
两个变量有不同的取值范围,也是可以算PLCC的,比如年龄和体重、身高和体重等,但算rmse不可以。
协方差的理解看这篇 马同学:如何通俗地理解协方差和相关系数? 里面有图展示了协方差/相关系数是如何表示了相关性的,通俗易懂
SROCC
SROCC和KROCC将具体数值抽象成排序等级。
SROCC是和“距离远近”有关的,而KROCC进一步跳过了这种“远近”描述,评价的依据是两两组成的“逆序对”。
举个例子看SROCC是如何计算的:


公式1:SROCC = 1-\frac{6\sum_{i=1}^{n}{d_i^2}}{n(n^2-1)} 每个变量内没有相等的值时使用
用上面的例子计算srocc = 1 - 6(表格中最后一列的加和)/(10*99) = 1-6*54/990
公式2: SROCC= \frac{\sum_{i=1}^{n}{(kp_i-\overline{kp})(ks_i-\overline{ks})}}{\sqrt{\sum_{i=1}^{n}{(kp_i-\overline{kp})^2}} \sqrt{\sum_{i=1}^{n}{(ks_i-\overline{ks})^2}}} , kp 表示rank(p), ks 表示rank(s),公式2在S内或者P内有相等的值出现时使用,比如把上面表格第九行第一个数76也改为80,那么两个80分就是前两名,则他们的等级都定为1.5,如果两个样本是并列第3名,则他们的等级定位3.5(第三第四的平均),后面的样本就是第5名。
可以看出srocc就是“等级”的plcc系数, SROCC(S,P) = PLCC(R(S),R(P))
KROCC
(s_1,p_1), (s_2,p_2), ……, (s_n,p_n) 是一些数据对,比如 (s_i,p_i) 就表示第i个样本的主观质量分数和算法预测得分。从n个数据对中任选2对,组成 [(x_i,y_i),(x_j,y_j)], i\ne j ,一共会有n(n+1)/2对,把这些对按照下面的情况进行划分:
P: x_i > x_j \ and \ y_i > y_j 或者 x_i < x_j \ and \ y_i < y_j 同序对
Q:x_i > x_j \ and \ y_i < y_j 或者 x_i < x_j \ and \ y_i > y_j 逆序对
X0:x_i = x_j \ and \ y_i > y_j 或者 x_i = x_j \ and \ y_i < y_j
Y0:x_i > x_j \ and \ y_i = y_j 或者 x_i < x_j \ and \ y_i = y_j
XY0:x_i = x_j \ and \ y_i = y_j
P,Q,X0,Y0表示的是满足条件的对数。
KROCC= \frac{P-Q}{\sqrt{(p+Q+X_0)(P+Q+Y_0)}}
在上面的例子中,P=34,Q=11,KROCC=23/45
总结
SROCC和PLCC是最重要的,可以很好的来衡量非线性相关性和线性相关性,SROCC只与元素的排列有关,因此即使X或Y被任何单调的非线性变换(如对数变换等)作用,也不会影响SROCC,但会影响PLCC。
参考链接
ROC曲线TPR和FPR
Classification | Machine Learning Crash Course | Google Developers
visionshao:ROC曲线和AUC值
讲道理的蔡老师:【面试看这篇就够了】如何理解ROC与AUC
全面了解ROC曲线
机器学习之分类性能度量指标 : ROC曲线、AUC值、正确率、召回率
样本不平衡时ROC稳定不变而PRC非常敏感_euler1983的专栏-CSDN博客
目标检测中的mAP是什么含义?
https://datascience.stackexchange.com/questions/25119/how-to-calculate-map-for-detection-task-for-the-pascal-voc-challenge
人脸识别性能指标_cdknight_happy的博客-CSDN博客_人脸识别性能指标
lucio:人脸识别随笔
评估图像质量评价算法性能的几个常用的标准_qqssss121dfd的博客-CSDN博客
相关性指标RMSE/PLCC/SROCC/KROCC理解_让让噢的博客-CSDN博客
wikipedia-Spearmans_rank_correlation_coefficient 可以看维基百科中文,也有计算的例子
文章被以下专栏收录
