
【论文速递2-10】近端策略优化PPO方向优质的论文及其代码

Proximal Policy Optimization - 近端策略优化
1. 【Proximal Policy Optimization】Rethinking Pre-training and Self-training
【近端策略优化】重新思考预训练和自我训练

作者:Barret Zoph, Golnaz Ghiasi, Tsung-Yi Lin, Yin Cui, Hanxiao Liu, Ekin D. Cubuk, Quoc V. Le
链接:
https://arxiv.org/abs/2006.06882v2
代码:
https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/self_training
英文摘要:
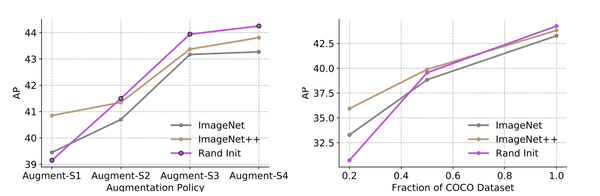
Pre-training is a dominant paradigm in computer vision. For example, supervised ImageNet pre-training is commonly used to initialize the backbones of object detection and segmentation models. He et al., however, show a surprising result that ImageNet pre-training has limited impact on COCO object detection. Here we investigate self-training as another method to utilize additional data on the same setup and contrast it against ImageNet pre-training. Our study reveals the generality and flexibility of self-training with three additional insights: 1) stronger data augmentation and more labeled data further diminish the value of pre-training, 2) unlike pre-training, self-training is always helpful when using stronger data augmentation, in both low-data and high-data regimes, and 3) in the case that pre-training is helpful, self-training improves upon pre-training. For example, on the COCO object detection dataset, pre-training benefits when we use one fifth of the labeled data, and hurts accuracy when we use all labeled data. Self-training, on the other hand, shows positive improvements from +1.3 to +3.4AP across all dataset sizes. In other words, self-training works well exactly on the same setup that pre-training does not work (using ImageNet to help COCO). On the PASCAL segmentation dataset, which is a much smaller dataset than COCO, though pre-training does help significantly, self-training improves upon the pre-trained model. On COCO object detection, we achieve 54.3AP, an improvement of +1.5AP over the strongest SpineNet model. On PASCAL segmentation, we achieve 90.5 mIOU, an improvement of +1.5% mIOU over the previous state-of-the-art result by DeepLabv3+.
中文摘要:
预训练是计算机视觉中的主导范式。例如,有监督的ImageNet预训练通常用于初始化对象检测和分割模型的主干。然而,他等人展示了一个令人惊讶的结果,即ImageNet预训练对COCO对象检测的影响有限。在这里,我们将自我训练作为另一种在相同设置上利用额外数据并将其与ImageNet预训练进行对比的方法进行研究。我们的研究通过三个额外的见解揭示了自我训练的普遍性和灵活性:1)更强的数据增强和更多的标记数据进一步降低了预训练的价值,2)与预训练不同,当使用更强的训练时,自我训练总是有帮助的数据增强,在低数据和高数据情况下,以及3)在预训练有帮助的情况下,自我训练在预训练的基础上得到改进。例如,在COCO对象检测数据集上,当我们使用五分之一的标记数据时,预训练会受益,而当我们使用所有标记数据时,会损害准确性。另一方面,自我训练在所有数据集大小上显示出从+1.3到+3.4AP的积极改进。换句话说,自我训练在预训练不起作用的相同设置上运行良好(使用ImageNet帮助COCO)。在PASCAL分割数据集上,这是一个比COCO小得多的数据集,尽管预训练确实有很大帮助,但自训练改进了预训练模型。在COCO对象检测上,我们实现了54.3AP,比最强的SpineNet模型提高了+1.5AP。在PASCAL分割上,我们实现了90.5mIOU,比DeepLabv3+之前的最先进结果提高了+1.5%mIOU。


2. 【Proximal Policy Optimization】ShapeMask: Learning to Segment Novel Objects by Refining Shape Priors
【近端策略优化】ShapeMask:通过优化形状先验学习分割新物体

作者:Weicheng Kuo, Anelia Angelova, Jitendra Malik, Tsung-Yi Lin
链接:
https://arxiv.org/abs/1904.03239v1
代码:
https://github.com/tensorflow/tpu/tree/master/models/official/detection
英文摘要:
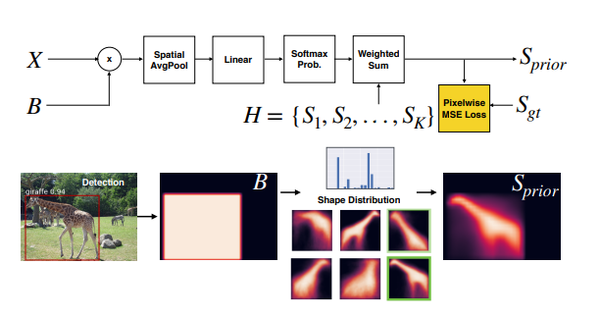
Instance segmentation aims to detect and segment individual objects in a scene. Most existing methods rely on precise mask annotations of every category. However, it is difficult and costly to segment objects in novel categories because a large number of mask annotations is required. We introduce ShapeMask, which learns the intermediate concept of object shape to address the problem of generalization in instance segmentation to novel categories. ShapeMask starts with a bounding box detection and gradually refines it by first estimating the shape of the detected object through a collection of shape priors. Next, ShapeMask refines the coarse shape into an instance level mask by learning instance embeddings. The shape priors provide a strong cue for object-like prediction, and the instance embeddings model the instance specific appearance information. ShapeMask significantly outperforms the state-of-the-art by 6.4 and 3.8 AP when learning across categories, and obtains competitive performance in the fully supervised setting. It is also robust to inaccurate detections, decreased model capacity, and small training data. Moreover, it runs efficiently with 150ms inference time and trains within 11 hours on TPUs. With a larger backbone model, ShapeMask increases the gap with state-of-the-art to 9.4 and 6.2 AP across categories. Code will be released.
中文摘要:
实例分割旨在检测和分割场景中的单个对象。大多数现有方法依赖于每个类别的精确掩码注释。然而,由于需要大量的掩码注释,因此在新类别中分割对象既困难又昂贵。我们介绍了ShapeMask,它学习了对象形状的中间概念,以解决实例分割到新类别的泛化问题。ShapeMask从边界框检测开始,并通过首先通过一组形状先验估计检测到的对象的形状来逐步细化它。接下来,ShapeMask通过学习实例嵌入将粗略的形状细化为实例级掩码。形状先验为类对象预测提供了强有力的线索,实例嵌入对实例特定的外观信息进行建模。在跨类别学习时,ShapeMask显着优于最先进的6.4和3.8AP,并在完全监督的环境中获得有竞争力的表现。对于不准确的检测、降低的模型容量和小的训练数据,它也很健壮。此外,它以150毫秒的推理时间高效运行,并在TPU上训练在11小时内。借助更大的骨干模型,ShapeMask将与state-of-the-art的差距扩大到9.4和6.2AP各类别。代码将被发布。


3. 【Proximal Policy Optimization】Simple Copy-Paste is a Strong Data Augmentation Method for Instance Segmentation
【近端策略优化】简单的复制粘贴是用于实例分割的强大数据增强方法


作者:Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, Tsung-Yi Lin, Ekin D. Cubuk, Quoc V. Le, Barret Zoph
链接:
https://arxiv.org/abs/2012.07177v2
代码:
https://github.com/conradry/copy-paste-aug
英文摘要:
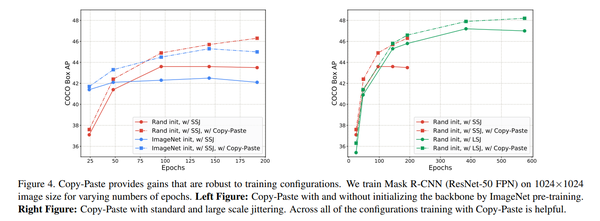
Building instance segmentation models that are data-efficient and can handle rare object categories is an important challenge in computer vision. Leveraging data augmentations is a promising direction towards addressing this challenge. Here, we perform a systematic study of the Copy-Paste augmentation ([13, 12]) for instance segmentation where we randomly paste objects onto an image. Prior studies on Copy-Paste relied on modeling the surrounding visual context for pasting the objects. However, we find that the simple mechanism of pasting objects randomly is good enough and can provide solid gains on top of strong baselines. Furthermore, we show Copy-Paste is additive with semi-supervised methods that leverage extra data through pseudo labeling (e.g. self-training). On COCO instance segmentation, we achieve 49.1 mask AP and 57.3 box AP, an improvement of +0.6 mask AP and +1.5 box AP over the previous state-of-the-art. We further demonstrate that Copy-Paste can lead to significant improvements on the LVIS benchmark. Our baseline model outperforms the LVIS 2020 Challenge winning entry by +3.6 mask AP on rare categories.
中文摘要:
构建数据高效且可以处理稀有对象类别的实例分割模型是计算机视觉中的一项重要挑战。利用数据增强是解决这一挑战的一个有希望的方向。在这里,我们对复制粘贴增强([13,12])进行了系统研究,例如我们将对象随机粘贴到图像上的实例分割。先前关于复制粘贴的研究依赖于对周围的视觉上下文进行建模以粘贴对象。然而,我们发现随机粘贴对象的简单机制已经足够好,并且可以在强大的基线之上提供可靠的收益。此外,我们展示了Copy-Paste与半监督方法相加,这些方法通过伪标记(例如自我训练)利用额外数据。在COCO实例分割上,我们实现了49.1maskAP和57.3boxAP,比之前的state-of-the-art提高了+0.6maskAP和+1.5boxAP。我们进一步证明复制粘贴可以显着改进LVIS基准。我们的基准模型在稀有类别上的表现优于LVIS2020挑战赛获胜参赛作品+3.6掩码AP。

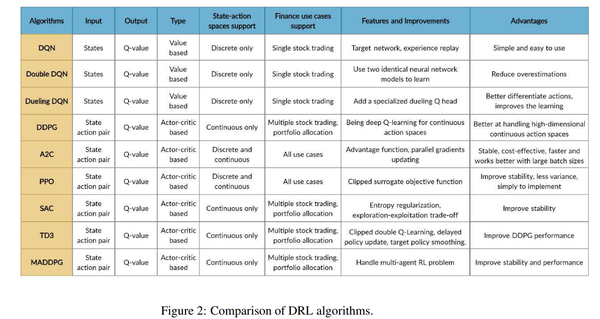
4. 【Proximal Policy Optimization】FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance
【近端策略优化】FinRL:用于量化金融中自动股票交易的深度强化学习库

作者:Xiao-Yang Liu, Hongyang Yang, Qian Chen, Runjia Zhang, Liuqing Yang, Bowen Xiao, Christina Dan Wang
链接:
https://arxiv.org/abs/2011.09607v1
代码:
https://github.com/AI4Finance-LLC/FinRL
英文摘要:
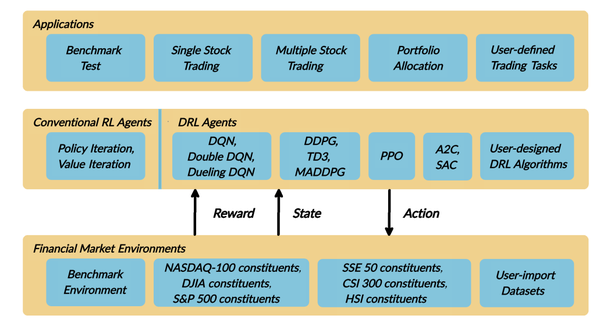
As deep reinforcement learning (DRL) has been recognized as an effective approach in quantitative finance, getting hands-on experiences is attractive to beginners. However, to train a practical DRL trading agent that decides where to trade, at what price, and what quantity involves error-prone and arduous development and debugging. In this paper, we introduce a DRL library FinRL that facilitates beginners to expose themselves to quantitative finance and to develop their own stock trading strategies. Along with easily-reproducible tutorials, FinRL library allows users to streamline their own developments and to compare with existing schemes easily. Within FinRL, virtual environments are configured with stock market datasets, trading agents are trained with neural networks, and extensive backtesting is analyzed via trading performance. Moreover, it incorporates important trading constraints such as transaction cost, market liquidity and the investor's degree of risk-aversion. FinRL is featured with completeness, hands-on tutorial and reproducibility that favors beginners: (i) at multiple levels of time granularity, FinRL simulates trading environments across various stock markets, including NASDAQ-100, DJIA, S&P 500, HSI, SSE 50, and CSI 300; (ii) organized in a layered architecture with modular structure, FinRL provides fine-tuned state-of-the-art DRL algorithms (DQN, DDPG, PPO, SAC, A2C, TD3, etc.), commonly-used reward functions and standard evaluation baselines to alleviate the debugging workloads and promote the reproducibility, and (iii) being highly extendable, FinRL reserves a complete set of user-import interfaces. Furthermore, we incorporated three application demonstrations, namely single stock trading, multiple stock trading, and portfolio allocation.
中文摘要:
由于深度强化学习(DRL)已被公认为量化金融中的一种有效方法,因此获得实践经验对初学者很有吸引力。但是,要训练一个实用的DRL交易代理来决定交易地点、价格和数量,这涉及到容易出错和艰巨的开发和调试。在本文中,我们介绍了一个DRL库FinRL,它可以帮助初学者接触量化金融并制定自己的股票交易策略。除了易于复制的教程外,FinRL库还允许用户简化自己的开发并轻松与现有方案进行比较。在FinRL中,虚拟环境配置有股票市场数据集,交易代理使用神经网络进行训练,并通过交易性能分析广泛的回测。此外,它还包含重要的交易约束,例如交易成本、市场流动性和投资者的风险规避程度。FinRL具有适合初学者的完整性、实践教程和可重复性:(i)在多个时间粒度级别,FinRL模拟各种股票市场的交易环境,包括NASDAQ-100、DJIA、S&P500、HSI、SSE50、和沪深300;(ii)以模块化结构的分层架构组织,FinRL提供微调的最先进的DRL算法(DQN、DDPG、PPO、SAC、A2C、TD3等)、常用的奖励函数和标准评估基线以减轻调试工作量并提高可重复性,并且(iii)具有高度可扩展性,FinRL保留了一套完整的用户导入接口。此外,我们还加入了三个应用演示,分别是单只股票交易、多只股票交易和组合配置。

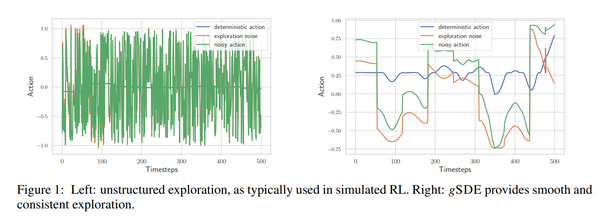
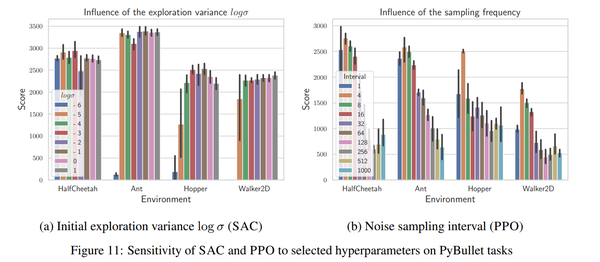
5. 【Proximal Policy Optimization】Smooth Exploration for Robotic Reinforcement Learning
【近端策略优化】机器人强化学习的平滑探索

作者:Antonin Raffin, Jens Kober, Freek Stulp
链接:
https://arxiv.org/abs/2005.05719v2
代码:
https://github.com/DLR-RM/rl-baselines3-zoo
英文摘要:
Reinforcement learning (RL) enables robots to learn skills from interactions with the real world. In practice, the unstructured step-based exploration used in Deep RL -- often very successful in simulation -- leads to jerky motion patterns on real robots. Consequences of the resulting shaky behavior are poor exploration, or even damage to the robot. We address these issues by adapting state-dependent exploration (SDE) to current Deep RL algorithms. To enable this adaptation, we propose two extensions to the original SDE, using more general features and re-sampling the noise periodically, which leads to a new exploration method generalized state-dependent exploration (gSDE). We evaluate gSDE both in simulation, on PyBullet continuous control tasks, and directly on three different real robots: a tendon-driven elastic robot, a quadruped and an RC car. The noise sampling interval of gSDE permits to have a compromise between performance and smoothness, which allows training directly on the real robots without loss of performance.
中文摘要:
强化学习(RL)使机器人能够从与现实世界的交互中学习技能。在实践中,DeepRL中使用的基于步骤的非结构化探索(通常在模拟中非常成功)会导致真实机器人的运动模式不稳定。由此产生的不稳定行为的后果是探索不力,甚至对机器人造成损害。我们通过使状态相关探索(SDE)适应当前的深度强化学习算法来解决这些问题。为了实现这种适应,我们提出了对原始SDE的两个扩展,使用更通用的特征并定期重新采样噪声,这导致了一种新的探索方法广义状态相关探索(gSDE)。我们在模拟、PyBullet连续控制任务以及直接在三个不同的真实机器人上评估gSDE:肌腱驱动的弹性机器人、四足机器人和遥控车。gSDE的噪声采样间隔允许在性能和平滑度之间进行折衷,这允许直接在真实机器人上进行训练而不会损失性能。

AI&R是人工智能与机器人垂直领域的综合信息平台。我们的愿景是成为通往AGI(通用人工智能)的高速公路,连接人与人、人与信息,信息与信息,让人工智能与机器人没有门槛。
欢迎各位AI与机器人爱好者关注我们,每天给你有深度的内容。
微信搜索公众号【AIandR艾尔】关注我们,获取更多资源❤biubiubiu~