
超硬核 | 多传感器融合感知知识点汇总

整理不易,点个赞再走吧!

免费领取知识导图啦!

一.基本原理
1.坐标转换
世界坐标系是用户定义的三维世界的坐标系,可以用来描述目标物体在真实世界中的位置。
从真实世界坐标系转换到相机坐标系,通过旋转矩阵R和平移向量t完成三维点到三维点的转换。
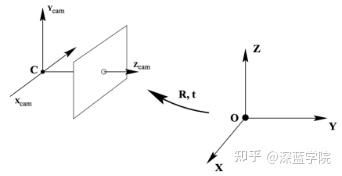
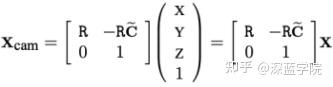
x=KR[I|-\tilde{C}]X
在这里认为旋转矩阵R为单位矩阵I,平移矩阵t都为0,则: P=K[I|0]
根据上述变化可得投影矩阵P的公式: P=K[R|t]
2.相机模型
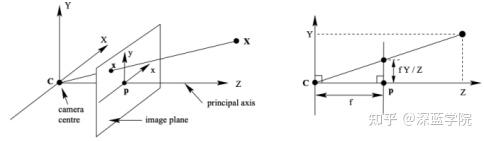
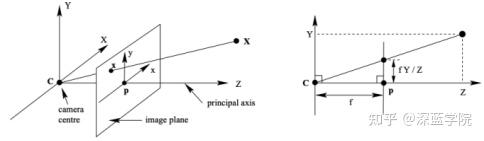
相机模型是光学成像模型的简化,具体使用针孔成像模型,成像过程包括四个坐标系:世界坐标系、相机坐标系、图像坐标系和像素坐标系之间的转换关系。
从相机坐标系转换为图像坐标系,就是从三维点到二维点的转换,包括相机内参K等参数。可推算出像主点的偏移:

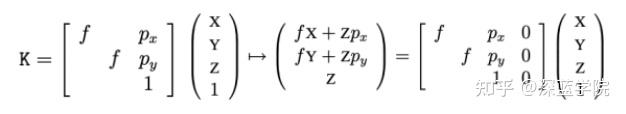
上式坐标待求的K为内参矩阵,包括焦距f和主点坐标等信息,只由相机的内部结构确定。
X=K[I|0]X_{cam}
3.单应性矩阵
单应性矩阵是描述物体在世界坐标系和像素坐标系之间的位置映射关系,这里的变换矩阵就是单应性矩阵。
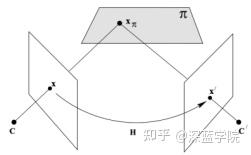
P=[I|0] P^{'}=[A|a] x^{'}=Hx
x^{'}=P^{'}X=[A|a]X
=Ax-av^{T}x=(A-av^{T})x
\pi^{T}X=0with\pi=(v^{T},1)^{T}
4.相机标定
相机标定的目的就是获取相机的内参和外参矩阵,通过内参和外参系数对拍摄的图像进行校正,使拍摄的图像畸变变小。
相机标定输入的是标定图像上所有内角点的图像坐标,标定板上所有内角点的空间三维坐标,输出的是相机的内参和外参系数。
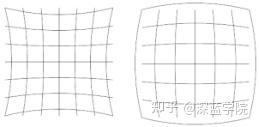
下图为枕形畸变,也称为鞍形形变,视野中边缘区域的放大率远大于光轴中心区域的放大率。
相机的针孔模型,只是真实相机的一个近似,由于存在各种镜头的畸变和变形,所以真实的相机要比模型复杂的多。在引入各种非线性的畸变修正之后,就形成看复杂的非线性成像模型。镜头的畸变主要分为径向畸变、离心畸变和薄棱镜畸变三类。
相机畸变问题通过相机标定来解决。相机内参加上相机外参一共有至少8个参数,而要想消除相机的畸变,就要靠相机标定来求解这8个未知参数。相机标定是为了求解上面这8个参数的,那求解出这8个参数可以干什么呢?可以进行软件消除畸变,也就是在得知上面8个参数后,利用相关计算式,将每个偏移的像素点归位。在完成标定后会返回相机的内参和外参。有了相机内参外参后,就可以进行相机消畸变了。
通过标定板,如下图,可以得到n个对应的世界坐标三维点和对应的图像坐标二维点,这些三维点到二维点的转换都可以通过上面提到的相机内参K,相机外参R和 t,以及畸变参数D经过一系列的矩阵变换得到。现在就用这些对应关系来求解这些相机参数。最后就是用线性方法求解方程式。
(1) x^{'}=x/z
y^{'}=y/z
(2) x^{''}=x^{'}(1+k_{1}r^{2}+k_{2}r^{4})+2p_{1}x^{'}y^{'}+p_{2}(r^{2}+2x^{'2}) y^{''}=y^{'}(1+k_{1}r^{2}+k_{2}r^{4})+2p_{2}x^{'}y^{'}+p_{1}(r^{2}+2y^{'2})
where r^{2}=x^{'2}+y^{'2}
(3) u=f_{x}·x^{''}+c_{x}
u=f_{y}·y^{''}+c_{y}
5.calibration Tree-Pase Graph Optimization
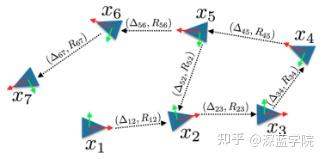
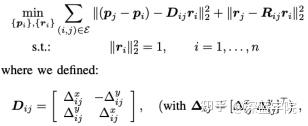
6.激光雷达和相机的联合标定
激光雷达和相机的李娜和标定是在空间中进行,其联合标定结果是得到激光雷达相对于相机的旋转和平移,标定的步骤分为获取相机的内参以及获取相机-雷达的外参。目前的联合标定方法有Autoware,apollo,lidar_camera_calibration和but_velodyne。先安装标定的工具,然后将图像和点云融合,得到着色的点云。
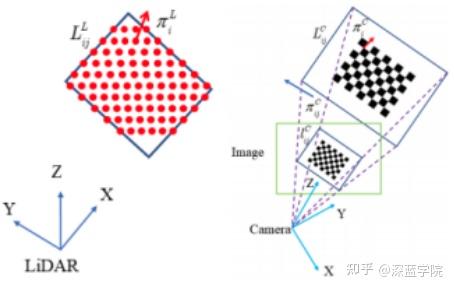
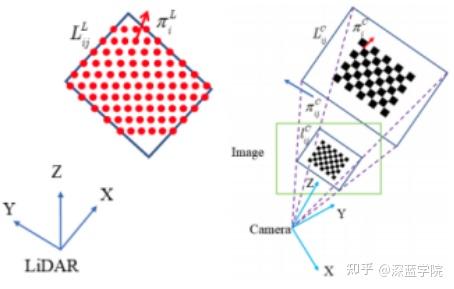
7.光线跟踪
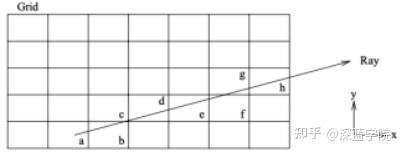
光线跟踪可以真实地显示物体,沿着到达视点的光心的相反方向跟踪,经过屏幕上的每一个像素,找出与视线所交的物体表面点,并继续进行跟踪,找到影响该点光强的所有光源,计算出这个交点上精确的光照强度。
最初,上帝说要有光,于是便有了光。在自然界中,光源发出的光线会不断地向前传播,直到遇到一个妨碍它继续传播的物体表面——把“光线”看作在一串在同样路径中传输的光子流的话,在完全的真空中,这条光线将是一条标准的直线。但是实际上,由于大气折射,引力效应、材质反射等多种因素——在现实中,光子流实际上是会被吸收、反射与折射的——物体表面可能在一个或者多个方向反射全部或者部分的光线,并有可能吸收部分光线,使得最终光线以种种形式,不同的强度,反射或者折射进人的眼睛。
而物理学中的光线追踪,指的就是一种通过种种方法对光线进行追踪的方法。

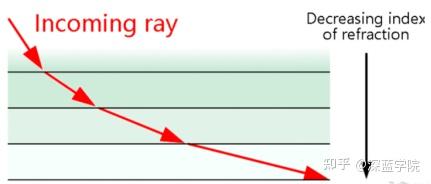
不过,这一点在计算机图形学中却有所不同——作为三维计算机图形学中的特殊渲染算法,光线追踪的原理颇有把物理中“光线追踪”方法反过来用的意味——它通过将光的路径跟踪为图像平面中的像素并模拟其与虚拟对象的相遇来生成图像,从而产生高度拟真的光影效果,还可以轻松模拟各种光学效果(例如反射和折射,散射和色散现象(例如色差))——唯一的缺点,就是它相对较高的计算成本了。
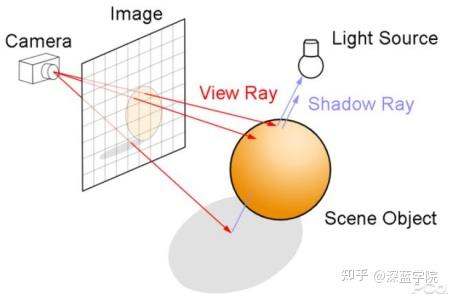
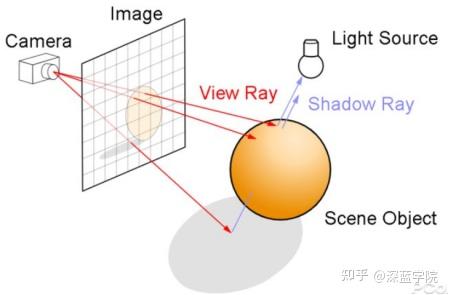
光线投射的基础是从眼睛(游戏镜头)投射光线到物体上的每个点,查找阻挡光线的最近物体,并根据材料的特性以及场景中的光线效果,来确定物体的光影及浓淡效果——比如说,如果表面面向光线,那么这个表面就会在渲染的时候被判定为明面(而不是处于阴影中)。
从眼睛到场景投射光线却并不跟踪这些光线的算法,虽然解决了计算机图形学中光照的基本明暗交错的问题,但对于模拟现实中复杂的光照情况却无能为力。当光线碰到一个物体表面的时候,实际上是会产生三种新类型的光线的:它们分别是反射、折射与阴影——对于光滑的物体表面而言,将光线按照镜像反射的方向反射出去,直接投射相应的光照效果和阴影就可以了,但是透明物质呢?
在透明物质中传输的光线虽然会以类似的方式传播,但是想要实现与现实世界相同的折射效果,就需要在计算机模拟场景中跟踪这些光线的光路了,而实现这一跟踪的效果,就需要复杂的算法、函数来实现了。
二.特征融合
1. 图像目标检测
图像目标检测方法分为传统检测方法和基于深度学习的检测方法,其中传统检测方法有VJ检测、HOG检测、DPM检测和AlexNet检测,基于深度学习的检测方法又可以分为单阶段检测和两阶段检测,单阶段检测方法有YOLO、SSD、RetinaNet、SequeezeDet和CornerNet,两阶段检测方法有RCNN、SPPNET、FastRCNN、FasterRCNN、MaskRCNN和FPN。

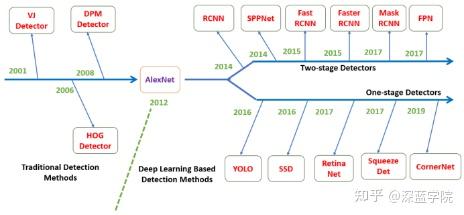
(1).图像目标检测算法
SSD&YOLO

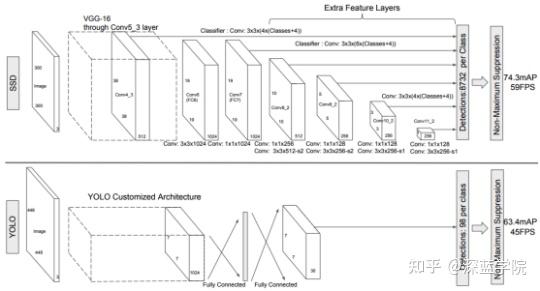
YOLO和SSD都是one-stage方法,用一个网络同时进行兴趣区域检测和分类。
YOLO的速度快,基本的YOLO模型可以达到45FPS,将整张图像作为输入,在卷积层后接全连接层,只利用了最高层的特征图。
SSD采用金字塔结构,利用大小不同的特征图在多个特征图上同时进行softmax分类和位置回归,速度可以达到59FPS。
SSD的平均精度高于YOLO。
cornerNet
目前大部分常用的目标检测算法都是基于anchor的,比如Faster RCNN系列,SSD,YOLO(v2、v3)等,引入anchor后检测效果提升确实比较明显(比如YOLO v1和YOLO v2),但是引入anchor的缺点在于:1、正负样本不均衡。大部分检测算法的anchor数量都成千上万,但是一张图中的目标数量并没有那么多,这就导致正样本数量会远远小于负样本,因此有了对负样本做欠采样以及focal loss等算法来解决这个问题。2、引入更多的超参数,比如anchor的数量、大小和宽高比等。因此这篇不采用anchor却能有不错效果的CornerNet就省去了这几个额外的操作。
CornerNet将目标检测问题当作关键点检测问题来解决,也就是通过检测目标框的左上角和右下角两个关键点得到预测框,因此CornerNet算法中没有anchor的概念,这种做法在目标检测领域是比较创新的而且能够取得不错效果是很难的。整个检测网络的训练是从头开始的,并不基于预训练的分类模型,这使得用户能够自由设计特征提取网络,不用受预训练模型的限制。

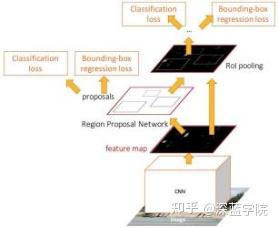
Faster RCNN
Faster RCNN组成部分主要包括:
(1)数据集,image input
(2)卷积层CNN等基础网络,提取特征得到feature map
(3-1)RPN层,再在经过卷积层提取到的feature map上用一个3x3的slide window,去遍历整个feature map,在遍历过程中每个window中心按rate,scale(1:2,1:1,2:1)生成9个anchors,然后再利用全连接对每个anchors做二分类(是前景还是背景)和初步bbox regression,最后输出比较精确的300个ROIs。
(3-2)把经过卷积层feature map用ROI pooling固定全连接层的输入维度。
(4)然后把经过RPN输出的rois映射到ROIpooling的feature map上进行bbox回归和分类。
Camera-Lidar Fusion for Object Dectection相机-雷达融合的目标检测
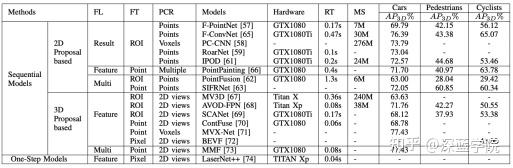
从2014年发展至今,相机-雷达融合的目标检测方法有DepthRCNN、Sliding Shapes、DepthRCNN+、Deep Sliding Shapes、MV3D、PC-CNN、AVOD、PointFusion、ContFuse、F-PointNet、ScanNet、SIFRNet、PointFusion、F-ConvNet、RoarNet、MVX-Net、PointPainting和LaserNet++等。

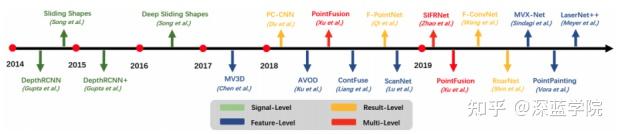
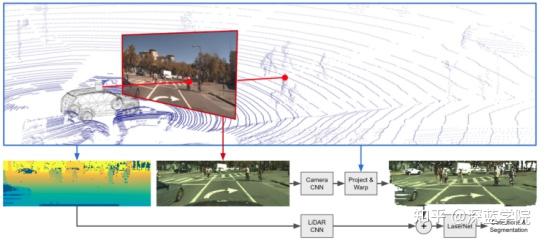
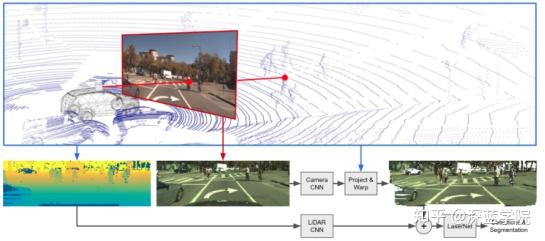
Fusion-Laser Net++
雷达和相机分别通过CNN方法,相机CNN方法后进行投影和包装,然后与激光雷达CNN后的结果融合为激光数据,最后进行检测和分割操作。
LaserNet++是一种以端到端的方式学习3D物体概率检测的有效方法,分别用两个网络来提取camera数据与lidar点云的特征,然后通过特征投影,将两种特征通过相加的方式组合成新的特征,再使用lasernet完成3D目标检测。
投影过程也是分为两步,首先在源数据上建立camera/range view图像与图像像素的对应关系,然后再利用对应关系得到两种传感器相对应的特征。Lasernet++在做点云特征提取时,使用了camera/rang view的表达方式,因此,建立点云与图像像素对应关系也分为两步:
(1)计算点云与range view图像的对应关系,如下式,其中p为点云坐标:
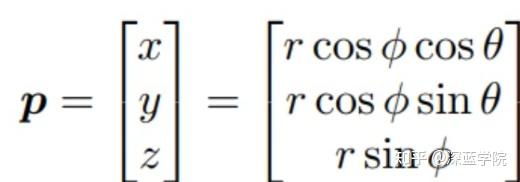
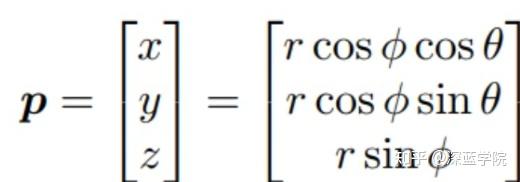
(2)计算点云与图像像素的对应关系。
(2).3D目标检测
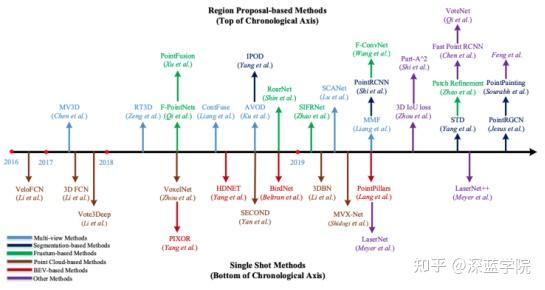
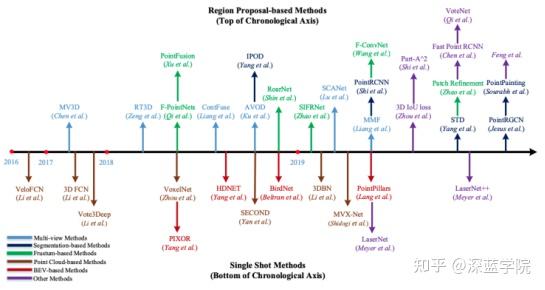
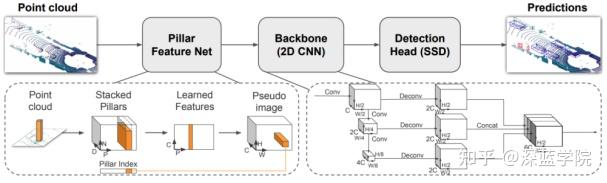
pointpillars
Pointpillars使用对3D的投影得到其2维的图像,再使用2D CNN,这样做无疑是会出现信息损失的,另外呢,先把3D点云分割成若干个体素小块,再把点个数当做二维像素值,再使用2D CNN结构,这又只使用了密度信息,没有局部几何信息。
先对点的局部提取点特征(这都要归功于pointnet),然后在利用卷积进行处理; voxelnet是第一篇提取局部特征后去做检测的,但是使用了3D voxel检测,后续再把深度信息和通道结合成一个维度,采用二维的RPN。
提出了一种新的encoding points的方式:pillar,pillar的编码方式是point clouds --> (D, P, N),其中p 是non-empty pillar number,N是一个pillar内有points的数目,D是 channel number。其网络结果的过程其实是(D, P, N)--> (C, P, N) --> (C, P) --> (C, H, W) --> (6C, H/2, W/2) --> bbox,主要分为三个部分:(1)Pillar Net特征提取,并变成一个 presudo-2d image (伪2D图);(2)使用2D CNN处理;(3)基于SSD的目标检测头进行bbox回归。
Pointpillars的优点就是快速,是因为pillar的方式使得每个位置只有一个pillar而不是很多像素点,元素变少了,处理速度自然就快了。

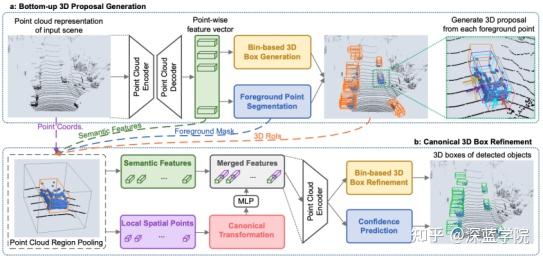
PointRCNN
PointRCNN是用于从原始点云中检测三维物体的两阶段方法,所提出的Stage-1网络以自下而上的方式直接从点云生成3D方案,比以前的方案生成方法具有更高的召回率。Stage-2网络将语义特征和局部空间特征结合起来,在规范坐标中对提案进行了优化。此外,新提出的基于bin的损失证明了它在三维边界框回归中的有效性。可以直接在三维点云上运行,具有高鲁棒性和准确的三维检测性能。

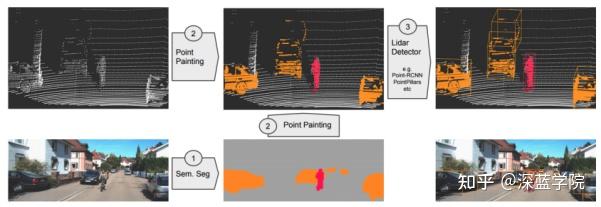
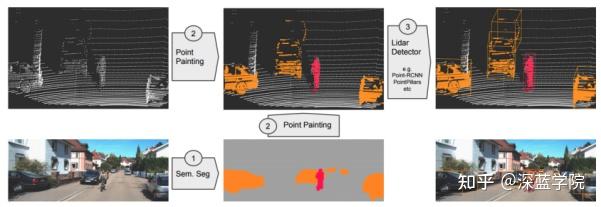
Fusion Point Painting融合点绘制
首先进行图像分割,然后绘制点,最后使用激光雷达探测分割的图像目标。
PointPainting是一种新的融合方法,通过图像点云增强了点云。实验证明pointPainting是:
(1)通用–与KITTI和nuScenes基准测试中的3种仅使用激光雷达的顶级方法一起使用时,实现了重大改进;
(2)准确– PointRCNN的painted版本在KITTI基准上达到了最先进的水平;
(3)强大– PointRCNN和PointPillars的painted版本分别改善了KITTI和nuScenes测试集上所有类的性能。
(4)快速-通过流水化图像和激光雷达处理步骤可以实现低延迟融合。
PointPainting接受点云和图像作为输入,并估计3D的边界框。它包括三个主要阶段:
(1)语义分割:基于图像的sem. seg.网络计算像素细分分数。
(2)融合:基于sem. seg.网络得到的分数,激光雷达点被喷涂。
(3)3D目标检测:基于激光雷达的3D检测网络。
三. 目标跟踪与信息融合
多目标跟踪
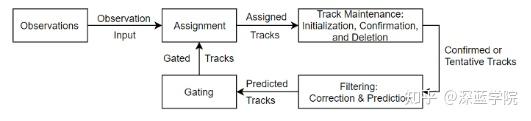
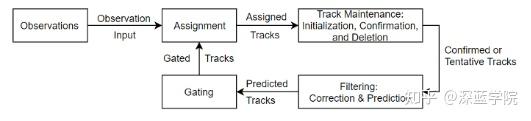
输入观测,然后进入任务,使用任务的追踪进行跟踪、维护:初始化、确认、删除,然后通过确定或暂定的跟踪进行滤波:修正和预测,接着预测跟踪,输入门控,然后使用门控轨道返回到任务,直至所有跟踪全部预测完成。
Validation Gating
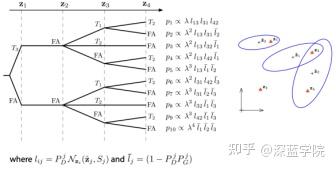
验证门用于目标跟踪,以剔除不太可能的度量来跟踪关联,然后通过更全面(且更昂贵)的数据关联方案处理剩余的关联模糊性。门的基本特性是接受高百分比的正确关联,从而最大限度地提高跟踪精度,但提供足够紧密的界限,以最大限度地减少不明确关联的数量。对于线性高斯系统,椭球验证门是标准的,并且具有统计特性,即给定的阈值将接受一定百分比的真实关联。此属性不适用于非线性非高斯模型。当系统偏离线性高斯时,椭球门倾向于拒绝高于预期的正确关联比例,并允许过多的错误关联。
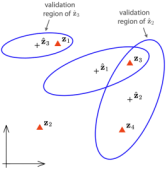
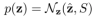
\nu(\gamma)=\left\{ z:d^{2} \leq \gamma \right\}d^{2}=\nu^{T}S^{-1}\nu
c=\frac{1}{(2\pi)^{D/2}|\Sigma |^{1/2}}exp\left\{ -\frac{1}{2}\nu^{T}S^{-1}\nu \right\}
n-dimensional observations and \mu={x}^\wedge(K+1),\Sigma=S(K+1)
d^{2}=(z-\mu)^{T}\Sigma^{-1}(z-\mu)
多假设跟踪算法
多假设跟踪MHT(Multiple Hypothesis Tracking)是数据关联另一种算法。它的基本思想是:与联合概率数据关联不同的是,MHT算法保留真实目标的所有假设,并让其继续传递,从后续的观测数据中来消除当前扫描周期的不确定性。在理想条件下,MHT是处理数据关联的最优算法,它能检测出目标的终结和新目标的生成。但是当杂波密度增大时,计算复杂度成指数增长,在实际应用中,要想实现目标与测量的配对也是比较困难的。
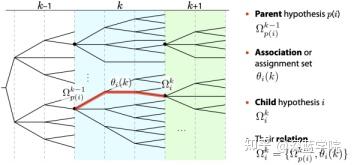
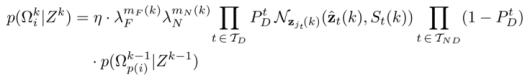
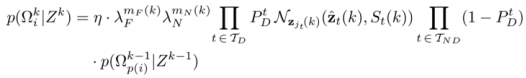

运动模型
运动模型包括状态空间和转换矩阵两种形式的,从布朗尼运动,恒定速度和恒定加速度三个角度进行分析。
概率校准
Brier分数是衡量概率校准的一个参数。Brier分数可以被认为是对一组概率预测的“校准”的量度,或者称为“ 成本函数 ”,这一组概率对应的情况必须互斥,并且概率之和必须为1。Brier分数对于一组预测值越低,预测校准越好。
概率校准就是对分类函数做出的分类预测概率重新进行计算,并且计算Brier分数,然后依据Brier分数的大小判断对初始预测结果是支持还是反对。
精确校准的分类器是概率分类器, 其可以将 predict_proba 方法的输出直接解释为 confidence level(置信度级别). 例如,一个经过良好校准的(二元的)分类器应该对样本进行分类, 使得在给出一个接近 0.8 的 prediction_proba 值的样本中, 大约 80% 实际上属于正类. 以下图表比较了校准不同分类器的概率预测的良好程度:
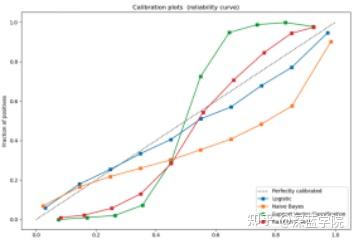
概率校准曲线,说明实际概率与预测概率的关系。可见Logistic回归预测概率比较准(模型本身的特点),朴素贝叶斯过于自信(可能由于冗余特征所致,违背了特征独立性前提)呈反sigmoid曲线,SVM很不自信呈sigmoid曲线,随机森林也是。
条件概率与贝叶斯理论
条件概率其实很简单,就是在某事发生的前提下,另一件事情发生的概率。构成贝叶斯推理基础的核心思想就是条件概率。在贝叶斯统计中,概率测量的是可信度。贝叶斯定理表明了不考虑证据的可信度和考虑了证据的可信度之间的关系。
P(x|Y=y^{'})=\frac{p(x,Y=y^{'})}{\int p(x,Y=y^{'})dx}=\frac{p(x,Y=y^{'})}{p(Y=y^{'})}
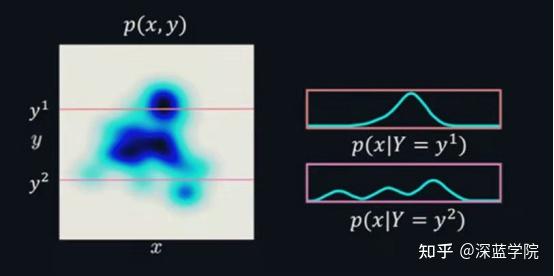
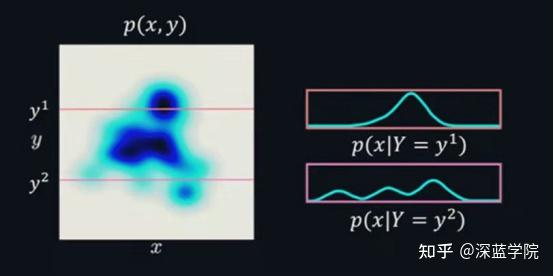
全局最临近算法
最近邻算法利用加权欧式距离计算每一个观测数据到真实目标的距离,然后再取其最近的一个观测数据作为目标真实状态,所以,当我们收到传感器传回来的观测数据时,首先计算加权欧式距离,然后再取其最近的点迹。全局最近邻问题就是使总的距离或关联代价达到最小,最优分配:

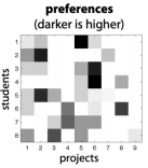
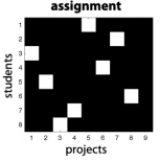
A=\left[ d^{2}_{ij} \right] d^{2}_{ij}=\nu_{ij}(k)^{T}S_{ij}(k)^{-1}\nu_{ij}(k)
min\sum{d_{ij}^{2}}·x_{ij} with x_{ij}\in\left\{ 0,1 \right\}
\sum_{i}{x_{ij}}=1 \sum_{j}{x_{ij}}=1
最近邻数据关联算法的优点是运算量小,易于硬件的实现,但是只能适用于稀疏目标和杂波环境的目标跟踪系统。当在目标或者杂波密度较大时,很容易出现误跟和漏跟现象,同时算法跟踪性能不高。
联合概率数据互联
联合概率数据互联JPDA(Joint Probabilistic Data Association)是数据关联算法之一,它的基本思想是:对应于观测数据落入跟踪门相交区域的情况,这些观测数据可能来源于多个目标。JPDA的目的在于计算观测数据与每一个目标之间的关联概率,且认为所有的有效回波都可能源于每个特定目标,只是它们源于不同目标的概率不同。JPDA算法的优点在于它不需要任何关于目标和杂波的先验信息,是在杂波环境中对多目标进行跟踪的较好方法之一。然而当目标和量测数目增多时,JPDA算法的计算量将出现组合爆炸现象,从而造成计算复杂。
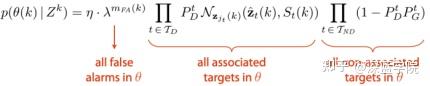
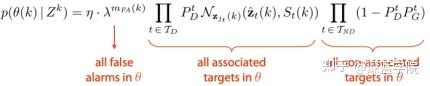
扩展卡尔曼滤波
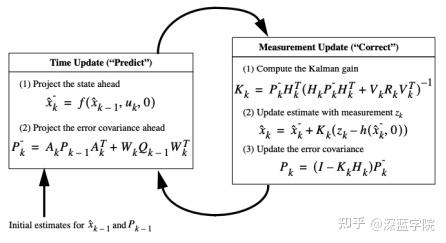
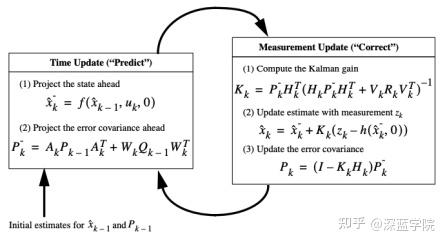
扩展卡尔曼滤波(Extended Kalman Filter,EKF)是标准卡尔曼滤波在非线性情形下的一种扩展形式,是一种高效的递归滤波器。EKF的基本思想是利用泰勒级数展开将非线性系统线性化,然后采用卡尔曼滤波框架对信号进行滤波,这是一种次优滤波。
包括时间更新(预测)和测量更新(校正),x是平均状态向量,P是状态协方差矩阵,Q是过程协方差矩阵。状态协方差矩阵P包含关于对象的位置和速度的不确定性的信息,过程协方差矩阵Q是与状态中的噪声相关联的协方差矩阵。
https://zhuanlan.zhihu.com/p/156120390
Zk是观测值, h(x_{k}^{-},0) 是预测部分得到的估计值进行h变换,也是最小均方误差MMSE。
粒子滤波
所谓粒子滤波就是指:通过寻找一组在状态空间中传播的随机样本来近似的表示 概率密度函数,用样本均值代替积分运算,进而获得系统状态的最小方差估计的过程,这些样本被形象的称为“粒子”,故而叫粒子滤波。
粒子滤波(PF: Particle Filter)的思想基于 蒙特卡洛方法(Monte Carlo methods),它是利用粒子集来表示概率,可以用在任何形式的 状态空间模型上。其核心思想是通过从 后验概率中抽取的随机状态粒子来表达其分布,是一种顺序 重要性采样法(Sequential Importance Sampling)。简单来说,粒子滤波法是指通过寻找一组在状态空间传播的随机样本对 概率密度函数进行近似,以 样本均值代替积分运算,从而获得状态最小方差分布的过程。这里的样本即指粒子,当样本数量N→∝时可以逼近任何形式的概率密度分布。
粒子滤波技术在 非线性、非 高斯系统表现出来的优越性,决定了它的应用范围非常广泛。另外,粒子滤波器的 多模态处理能力,也是它应用广泛的原因之一。国际上,粒子滤波已被应用于各个领域。在经济学领域,它被应用在 经济数据预测;在军事领域已经被应用于雷达跟踪空中飞行物,空对空、空对地的被动式跟踪;在交通管制领域它被应用在对车或人视频监控;它还用于机器人的全局定位。汇总
文章被以下专栏收录
