
研究生新生如何查找论文并下载参考文献?(1)

01
真实场景交代
我是一名计算机视觉研究生,研究方向是「目标检测(Object Detection)」。在详细阅读相关文献之前,我需要先了解这个领域的发展历程及每个时间段有代表性的文献。
02
遇到的困难
如何找到这些相关的文献?
03
明确目标
我希望尽可能找到所有与当前研究领域相关的文献。
04
工具准备
4.1 领域相关的关键词表:目标检测、Object Detection 等。
4.2 搜索引擎:Google、百度、Bing 等。
4.3 目标网页(数据源)列表:Google 学术、 http://arXiv.org、百度学术、中国知网 等。
4.4 Web Scraper 数据采集工具。
05
5.1 确定使用哪个搜索引擎
Google浏览器(PS:需合理使用),并从「谷歌学术」上搜索我们要的学术文献。如图 1 所示。
5.2 确定使用什么关键词进行搜索
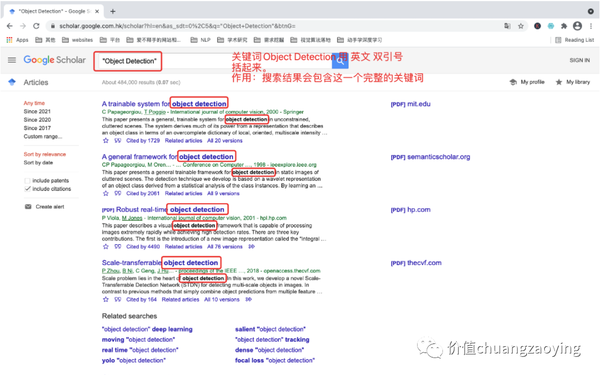
我们希望目标网页包含 Object Detection 这个词汇,一共有 484000 项匹配结果。如图 2 所示。
5.3 明确采集的数据项
我们的目的是什么?
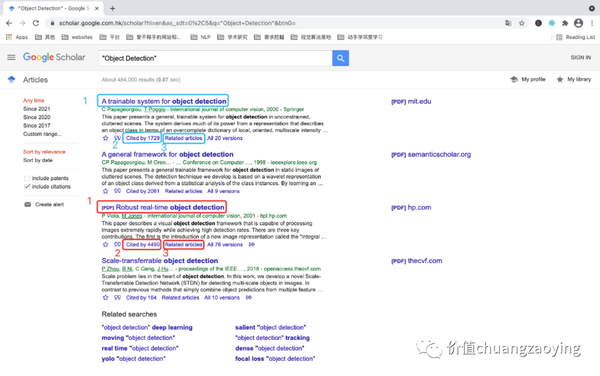
我们想知道某一个研究领域的发展历程,那么可以有「文献名称」、「论文引用量」、「相关文献」这三项参考指标(当然还有其他判别指标)。
所以,本次共采集三项数据:“论文名称”、“论文引用量”、“相关文献”。如图 3 所示。
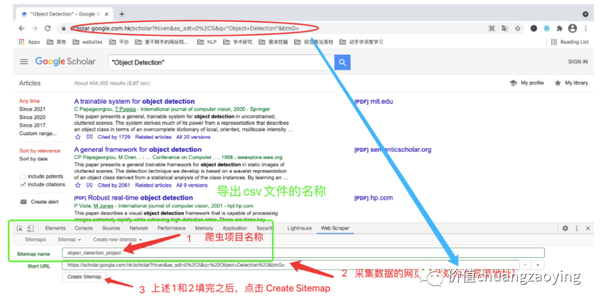
5.4 打开 Web Scraper 并新建一个工程
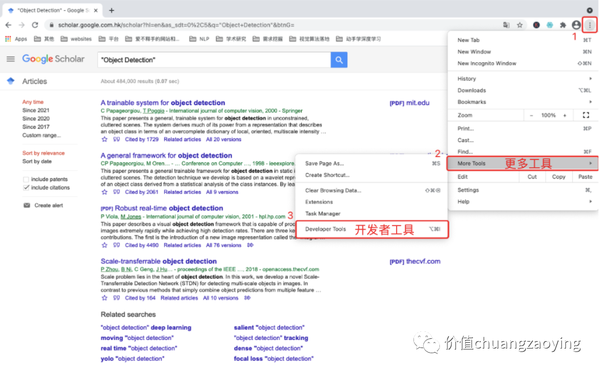
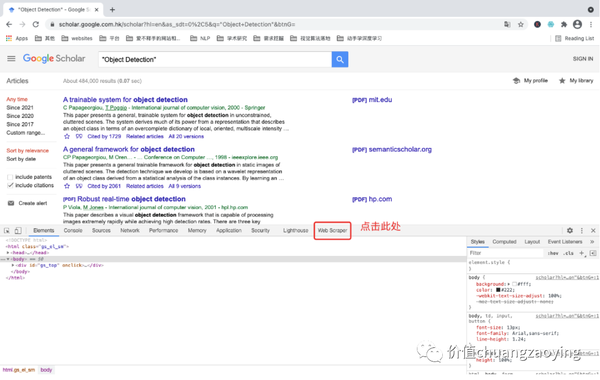
点击右侧三个点 -> More Tools -> Developer Tools 。如图 4 所示。
点击工具栏的三个点并将工具栏调整至浏览器下方。如图 5 所示。

点击 Web Scraper 。如图 6 所示。
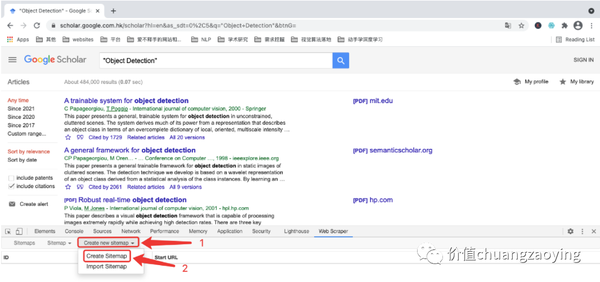
点击 Create new sitemap ,通过 Create Sitemap 方式新建一个项目。如图 7 所示。
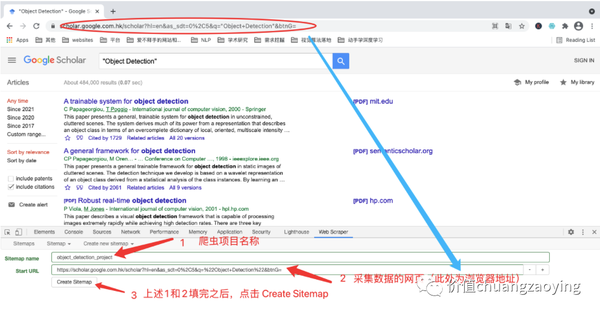
填充 Sitemap name 和 Start URL 两项内容,填充完毕之后点击 Create Sitemap 。如图 8 所示。
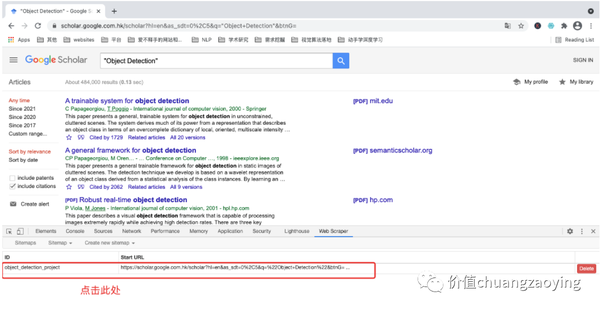
本文,我们采集搜索结果第 1 页的数据。如图 9 所示。

我们给采集的每一个数据项分别命名为:title(论文名称)、cited_num(论文引用量)、related_articles(相关文献)。
5.5 设置数据抓取规则
点击刚刚创建的项目。如图 10 所示。
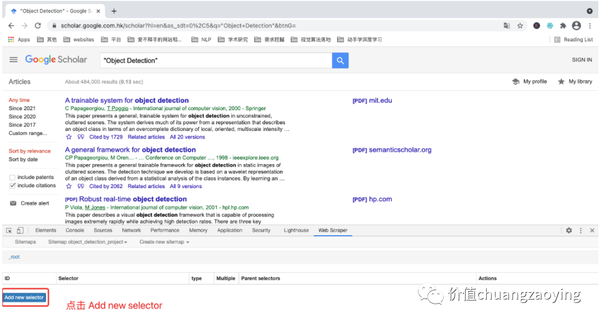
进入项目之后,点击 Add new selector 。如图 11 所示。
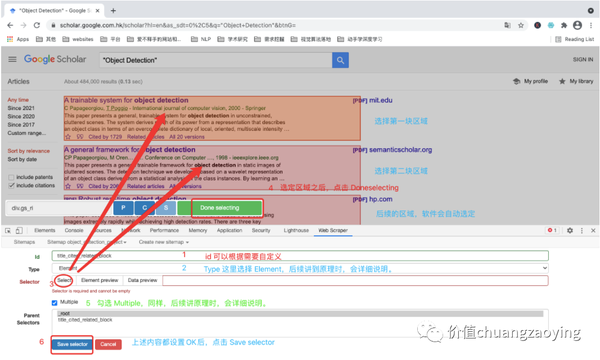
进入具体的规则设定界面,需要填充 id、Type、Selector、Parent Selecto、是否勾选 Multiple 这五项内容,设置完毕后点击 Save selector 。如图 12 所示。
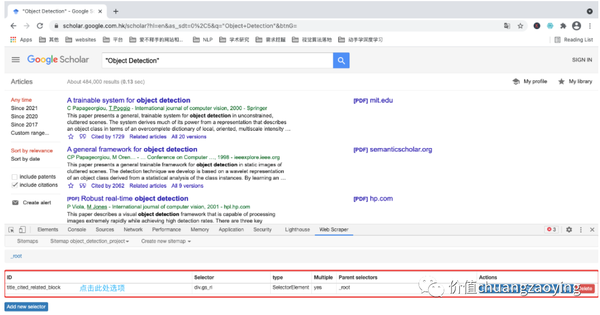
首先,我们先采集 title(文献名称)这一数据项。点击刚刚命名的 id 。如图 13 所示。
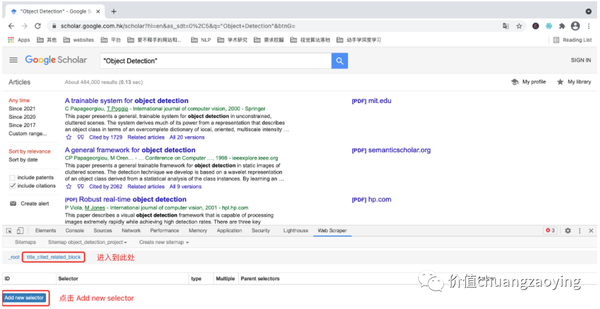
进入一个“新结点”,再次点击 Add new selector。如图 14 所示。
和上述类似,分别设置以下几个规则。如图 15 所示。
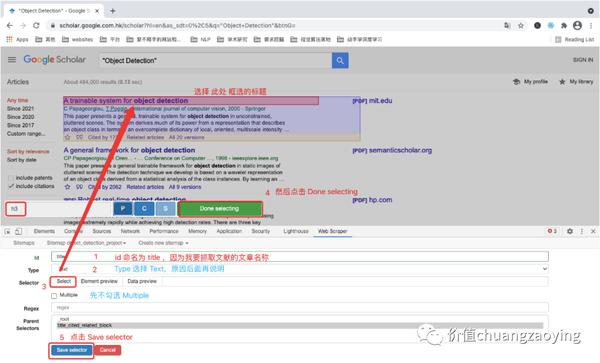
点击 Element preview ,目的是查看数据采集位置是否正确。如图 16 所示。
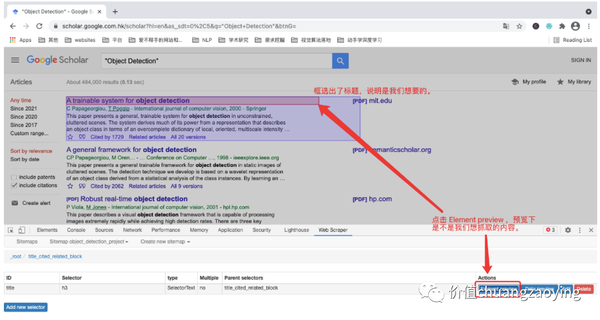
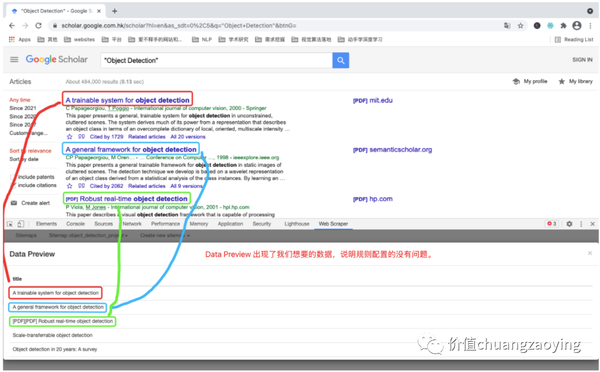
点击 Data preview ,目的是预览数据,确保采集的数据是我们想要的。如图 17 所示。

点击 Data preview 之后看到的数据内容,即最终我们采集到的数据就是这样子。如图 18 所示。
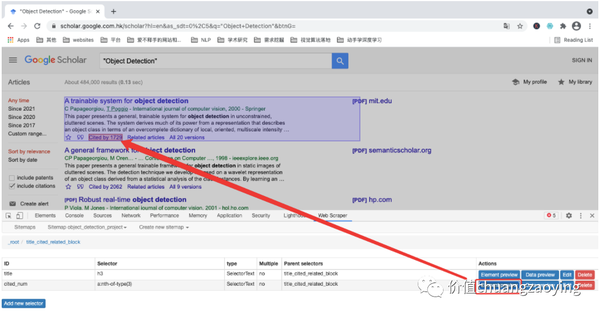
接着,我们采集第二个数据项 —— cited_num(文献被引用次数)
在“当前结点”点击 Add new selector ,新建一个采集规则。如图 19 所示。

和上述类似,设置对应的采集规则。如图 20 所示。
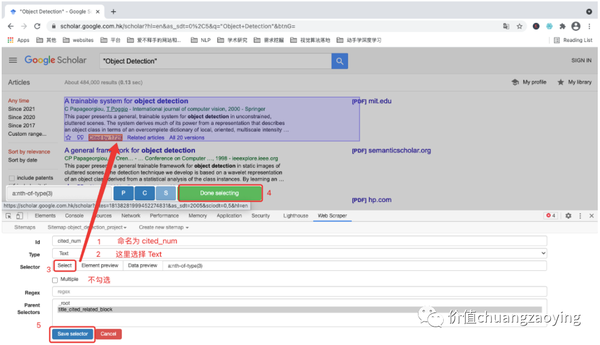
点击 Element preview。如图 21 所示。
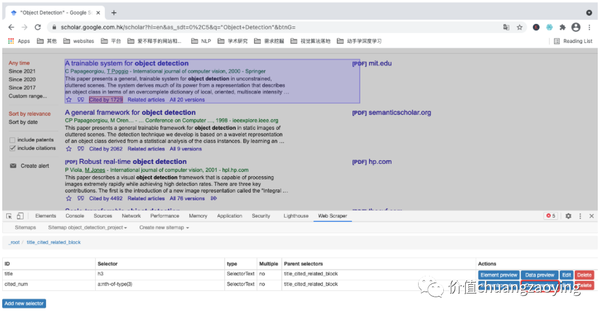
点击 Data preview。如图 22 所示。
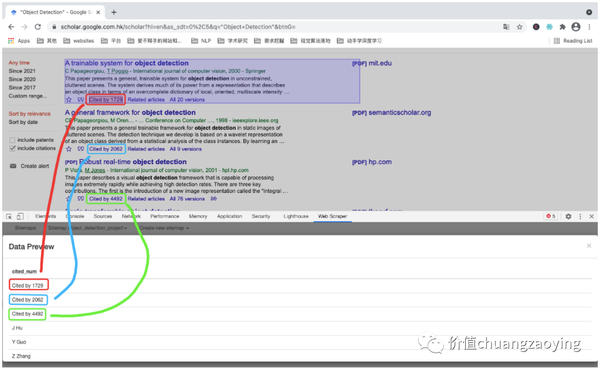
验证下我们预览数据和网页数据是不是一一对应。如图 23 所示。
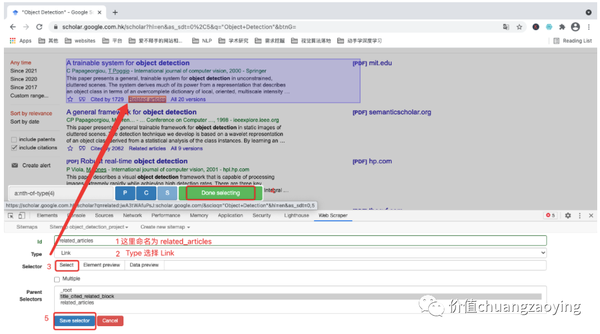
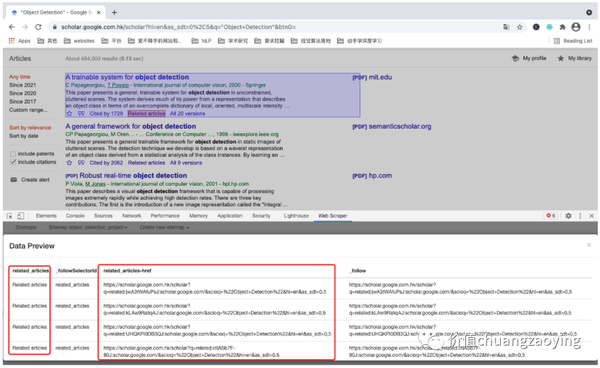
最后,采集 related_articles (和本文献相关联的文章)数据项设置对应规则。如图 24 所示。
点击 Element preview。如图 25 所示。

点击 Data preview 。如图 26 所示。
5.6 开始采集数据
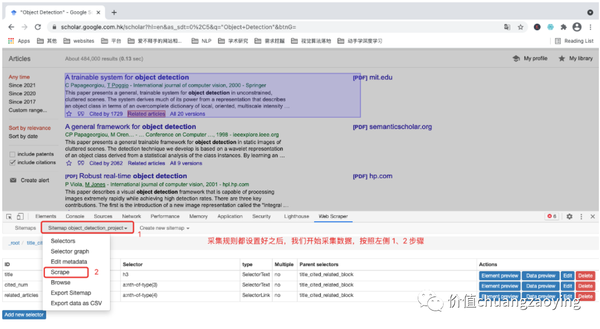
点击项目名称后,再选择 Scrape 。如图 27 所示。
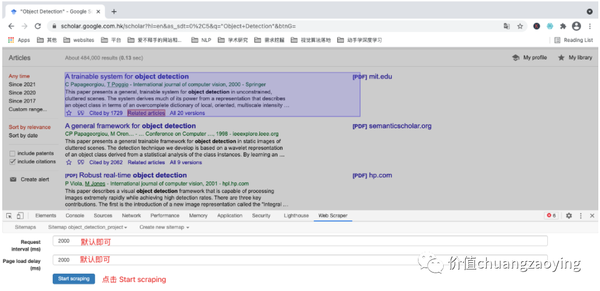
Request interval 和 Page load delay 两项默认即可,点击 Start scraping 。如图 28 所示。
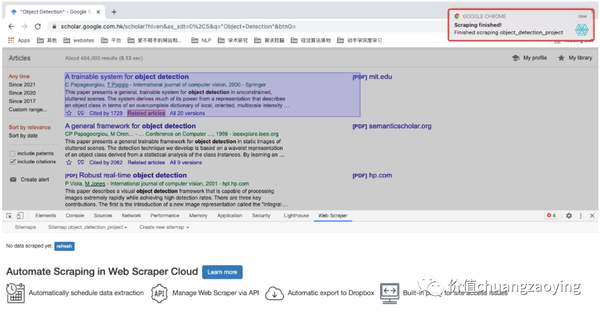
点击 Start scraping 之后,会重新开启一个网页,此时就是程序正在采集数据的过程,采集结束之后,会自动关闭该窗口。
采集结束后会出现弹框提醒,如图 29 所示。
5.7 导出数据
点击项目名称,选择 Export data as CSV。如图 30 所示。
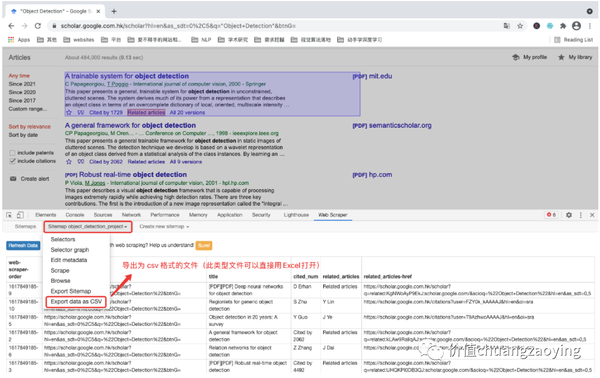
接着会出现如下界面,点击 Download now! 即可。如图 31 所示。
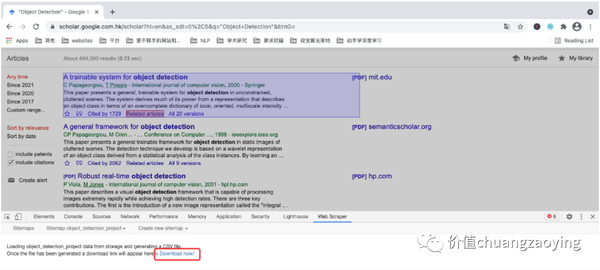
点击下载之后,“双击打开”或者“在文件夹中显示”都可以。如图 32 所示。
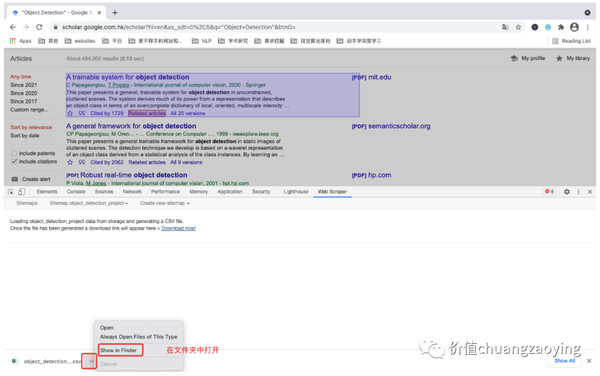
我们可以看到,这个文件就是我们采集到的数据。如图 33 所示。

导出的文件名称为 object_detection_project.csv 和我们建项目时的名称一致。如图 34 所示。
5.8 进行简单的数据清洗
由于 Web Scraper 抓取数据时并不是按照指定顺序的,所以顺序上会出现偏差,我们按照 web-scraper-order 排序下即可。如图 35 所示。
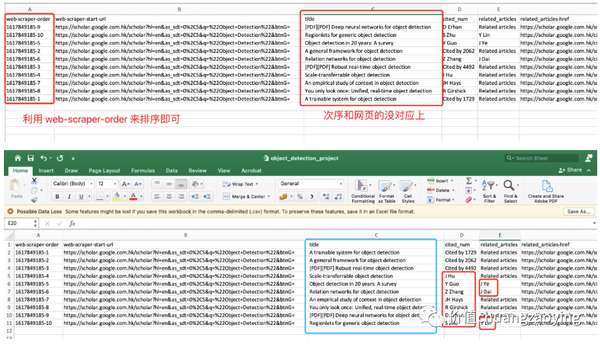
至此,我们已经成功(了一半)地抓取了 Object Detection 关键词在谷歌学术搜索结果首页的相关信息。
但是,在 验证 我们采集的数据和网页上的数据是否一致时,我们发现了问题:
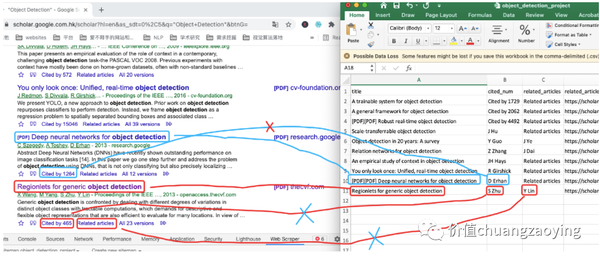
问题1
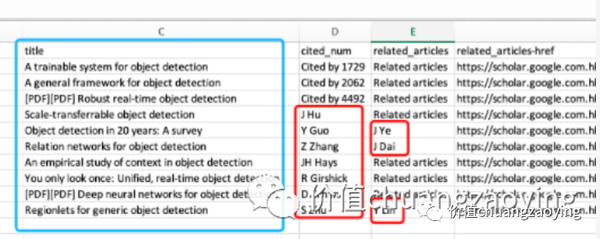
cited_num 部分抓取的是人名,而不是对应的引用数量。如图 36 所示。
问题2
related_articles 部分抓取的也是人名,而不是对应的文字和链接。如图 36 所示。
另外,我也想抓取文献的具体下载地址,后续可以直接访问地址并下载文献。
上述的「两个问题 + 抓取文献下载地址」,我们放到下一篇文章来分析。
文章操作内容详细见如下视频:
如果文章对你有微不足道的帮助,like一下就是对我最大的支持 ,我们下期再见,
文章被以下专栏收录
