
图像描述:基于项的注意力机制

我们以图像描述(Image Caption)为例来讲解基于项的注意力机制。图像描述任务是输入一张图片,生成对该图像的描述文本,可以表示为单词编码序列
y=\{\bm{y}_1,\cdots,\bm{y}_C\}, \bm{y}_i\in\mathbb{R}^K,
其中 K 是词表的大小, C 是描述文本的长度。
对于原图像,使用CNN来抽取它的特征,最后一个卷积层的输出可以产生 L 个向量,每一个向量是原图中一个区域的 D 维表示,可以看成一个序列
a=\{\bm{a}_1,\cdots,\bm{a}_L\}, \bm{a}_i\in\mathbb{R}^D.
一种不使用注意力机制的简单做法就是将上述向量 a 取平均池化或最大池化,然后输入到RNN解码器中做文本序列的生成,如下图所示。这种方法把图片每个部分的特征等权重对待,不能更细化地针对不同部位来生成每个单词,而注意力机制正合适解决这种问题。

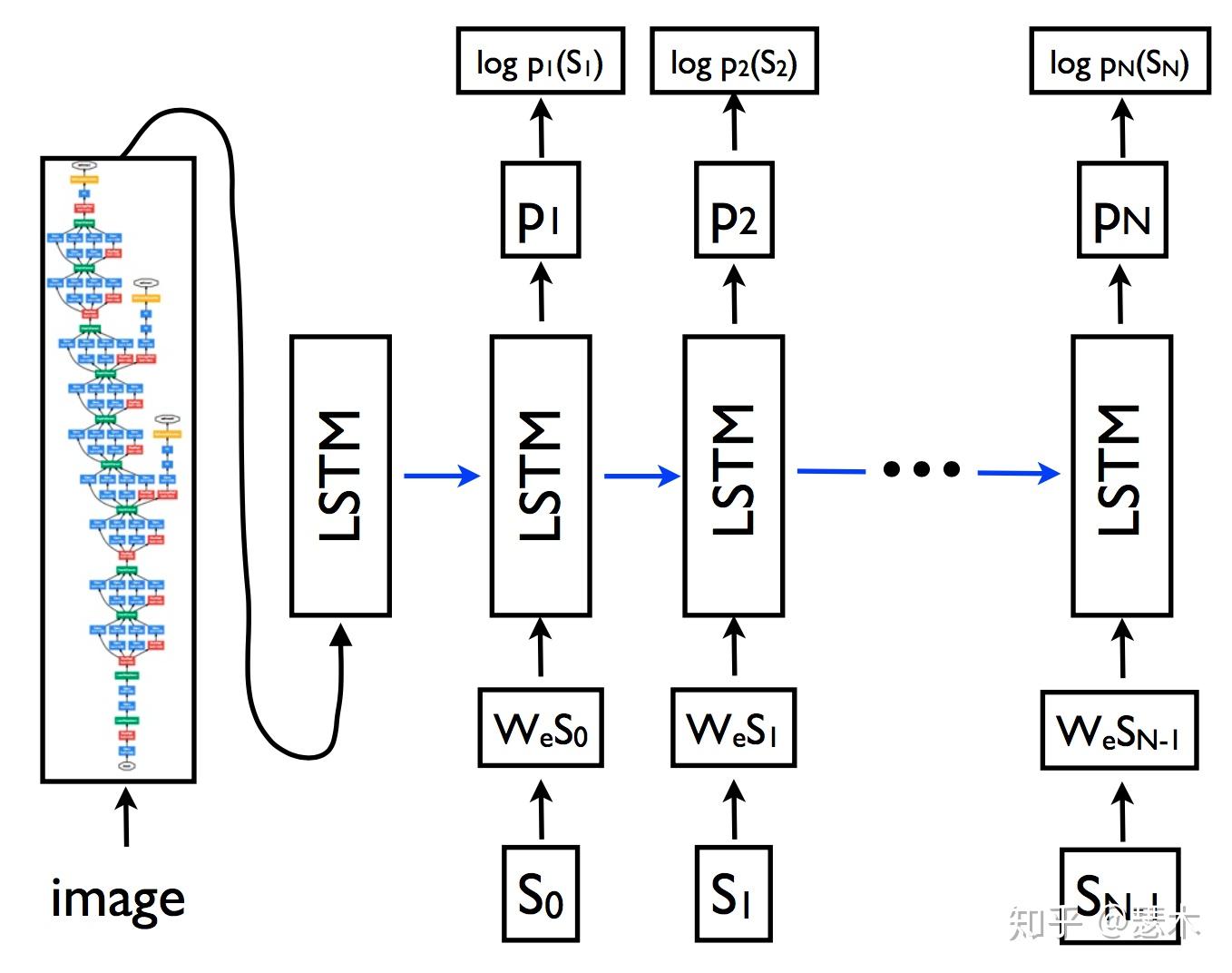
这里注意力机制要处理的是包含明确的项的序列 a ,所以采用基于项的注意力(如下图所示)。注意力机制要计算出当前时刻 t 每个向量 \bm{a}_i 的权重 \alpha_{t,i} ,这里注意力模块 f_{\text{att}} 采用多层感知机,输入是向量 \bm{a}_i 和解码器上个时刻的状态 \bm{h}_{t-1} 。
\begin{align} e_{ti} &=f_{\text{att}}(\bm{a}_i,\bm{h}_{t-1}), \\ \alpha_{t,i} &= \frac{\exp(e_{ti})}{\sum_{k=1}^{L}\exp(e_{tk})}. \end{align}


权重计算好之后,注意力机制就可以对输入序列$a$进行选择了
\begin{equation} \hat{\bm{z}}_t = \phi(\{\bm{a}_i\},\{\alpha_{t,i}\}), \end{equation}
其中 \phi 是一个函数,根据输入向量序列和对应的权重输出一个向量,它决定了注意力机制是硬性还是柔性的,具体下一段讲。有了注意力机制加工过的特征向量 \hat{\bm{z}}_t ,把它输入到解码器,通过全连接层输出该时刻应该是每个单词。训练时使用对数似然函数 \log p(\bm{y}_t|a,\bm{y}_{t-1}) 作为目标函数。
硬性注意力
在生成时刻 t 的单词时,对于 L 个图像区域特征 \bm{a}_i ,硬性注意力会从中选一个出来。令 s_t 为模型做决定的独热码向量,如果 \bm{a}_i 被选中,那么 s_{t,i}=1 。我们可以把 \alpha_{t,i} 看作概率,由它构成的多项分布用来做选择:
\begin{align}\label{eq:s} & p(s_{t,i}=1|s_{j<t},\bm{a}) =\alpha_{t,i}, \\ & \hat{\bm{z}}_t = \sum_{i}s_{t,i}\bm{a}_i. \end{align}
关于硬性注意力机制的训练,由于它是离散式进行选择,梯度无法直接计算,一个常见的做法是采用强化学习中的优化技术。因此,我们定义一个原目标函数的下界 L_s 作为新的目标函数
\begin{align} L_s &= \sum_{s}p(s|a)\log p(\bm{y}|s,a) \\ &\leq \log \sum_{s}p(s|a)p(\bm{y}|s,a) \\ &= \log p(\bm{y}|a). \end{align}
新的目标函数 L_s 对模型参数 \theta 的梯度为
\begin{align} \frac{\partial L_s}{\partial \theta} &= \sum_{s}\left( p(s|a)\frac{\partial\log p(\bm{y}|s,a)}{\partial\theta} + \log p(\bm{y}|s,a)\frac{\partial p(s|a)}{\partial\theta} \right) \\ &= \sum_{s}p(s|a)\left( \frac{\partial\log p(\bm{y}|s,a)}{\partial\theta} + \log p(\bm{y}|s,a)\frac{\partial\log p(s|a)}{\partial\theta} \right). \end{align}
由于 s 是由上面的多项分布生成的,所以 p(\bm{y}|s,a) 和 \frac{\partial\log p(s|a)}{\partial\theta} 可以通过蒙特卡洛采样来估计:
\begin{equation} \frac{\partial L_s}{\partial \theta} \approx \frac{1}{M}\sum_{m=1}^M\left( \frac{\partial\log p(\bm{y}|s^m,a)}{\partial\theta} + \log p(\bm{y}|s^m,a)\frac{\partial\log p(s^m|a)}{\partial\theta} \right) \end{equation}
其中 s^m 是第 m 次采样的结果, M 是采样次数。这样,整个模型就可以通过梯度下降进行训练了。
柔性注意力
硬性注意力需要做随机的选择,我们也可以采用求 \hat{\bm{z}}_t 的期望的方式,这就是柔性注意力,
\begin{equation} \mathbb{E}_{p(s_t|a)}[\hat{\bm{z}}_t]=\sum_{i=1}^{L}\alpha_{t,i}\bm{a}_i, \end{equation}
也就是说, \phi 是一个线性加权函数 \phi(\{\bm{a}_i\},\{\alpha_{t,i}\})=\sum_{i=1}^{L}\alpha_{t,i}\bm{a}_i 。
柔性注意力的训练直接用标准的梯度下降即可,因为整个模型都是可微的。
注意力机制全集:
- 计算机视觉中的注意力机制
- 图像描述:基于项的注意力机制
- 数字串识别:基于位置的硬性注意力机制
- 图像识别:基于位置的柔性注意力机制
参考文献:
Wang F, Tax D M J. Survey on the attention based RNN model and its applications in computer vision[J]. arXiv preprint arXiv:1601.06823, 2016.
Xu K, Ba J, Kiros R, et al. Show, attend and tell: Neural image caption generation with visual attention[C]//International Conference on Machine Learning. 2015: 2048-2057.
Vinyals O, Toshev A, Bengio S, et al. Show and tell: A neural image caption generator[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3156-3164.
文章被以下专栏收录

机器爱学习

计算视觉与深度学习的小屋
