
WEB开发日常2(Web项目的结构)

系列授权转载自 @李明的简书
简书原文
一个Web项目, 可大可小, 大到整个阿里巴巴, 小到你自己的博客, 留言板. 虽然所采用的技术不一样, 规模不一样, 但是都由一些执行相同作用的组件所构成的, 当然根据规模的不同, 要实现的功能的不同, 有一些组件并不一定是必须, 但是当一个项目从小到大的演变过程中, 需要加入的组件都是大致功能类似的. 下面我们就从最简单的Web项目开始, 到随着功能, 规模的递增, 看看有那些组件需要加入, 和各自的作用.
1. 种子规模
这个规模的项目最好的实例就是个人博客, 留言板, 公司介绍网站等, 基本结构如下
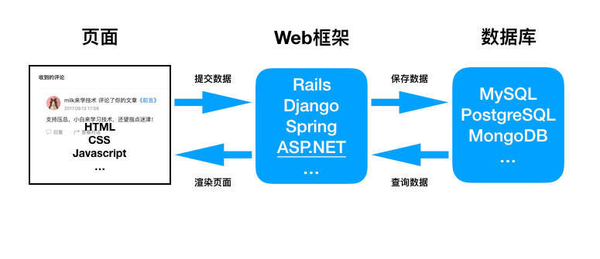

种子规模项目结构这是最简单的模式, 基本上可以概括为 请求-响应 模式. 主要的组件是由Web框架 和 数据库两个部分组成, Web框架负责为开发者提供基础的应用程序结构和功能: 1. 接收HTTP请求 2.渲染返回的HTML页面, 数据库则负责持久化数据: 比如留言的内容.
随着使用人数的上升, 性能很快入不敷出, 你开始觉得访问的时候速度不如原来快了. 但是你在用top命令查看系统开销的时候会发现, 其实系统的CPU占用并不是很高. 原来这个时候大部分的时候CPU都在等带数据库查询的结果, 而数据库查询结果很多时候是重复的, 比如当没有人留言的时候, 返回的最新留言列表. 为了避免无谓的IO开销, 我们需要用一个比数据库快N倍的存储设备来缓存查询的结果, 这样当我们发现查询结果不会有变化的时候, 就能通过更快的存储设备拿到结果, 比如内存就是用户级应用程序能访问的最快, 而且现在看来容量也够大(将来会越来越大)的存储设备了. 这个时候我们需要引入一个新的组件: 内存缓存
2. 发芽规模(开始扩展了)
引入缓存后, 项目的基本结构如下图所示:
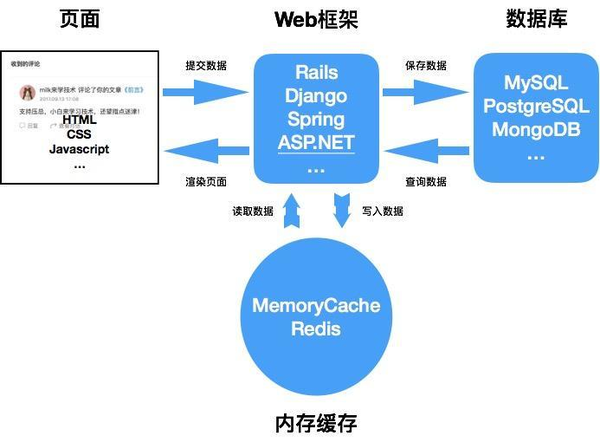

带缓存的项目结构目前最常用的内存缓存基本上就MemoryCache和Redis两个了, MemoryCache就是个单存的内存缓存, 而Redis不光快, 还是个啥都能干的万金油, 你可以将其视作为一个在线内存数据结构服务, 除了KV之外还提供了SET, List, Hash等多种数据结构, 功能太强我们后面还会提到详细说.
缓存大体上有两种使用的方式, 一种是输出缓存, 另一种是数据缓存.
输出缓存是作用在Web框架输出端, 基本的作用过程是这样子的.
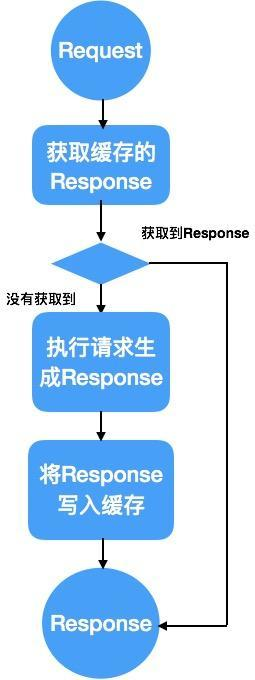
输出缓存执行逻辑当读取的频率大于写入或者更新的时候, 输出缓存能够很大程度上的提升性能, 因为大部分原本需要通过数据库去获取的数据直接通过内存获得了, 而内存的速度是数据库的N倍, 所以系统的容量能够成倍的增长.
但是, 如果输出的内容需要在数据的基础上做一些处理, 比如返回了留言列表, 但是要根据和当前日期的比对显示留言的时间, 最近的几条显示诸如: 刚刚, 1分钟前, 半小时前... 等. 随着时间的变动, 返回的留言没变, 但是留言时间的显示需要变化, 那么这个时候输出缓存就无能为力了, 我们需要数据缓存来满足需求.
数据缓存的执行逻辑如下图所示:
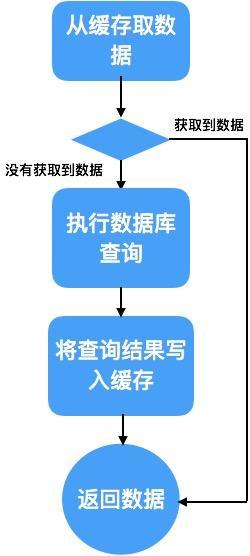
数据缓存执行逻辑但是这两种缓存模式都是在项目中根据需要来使用, 大多数时候一个项目中两种模式都会存在.在实际的项目中缓存并非只有自建一种选择, 还有客户端缓存和CDN之类的缓存形式, 我们在缓存的部分专门展开来详细介绍.
随着规模的增长, 功能的增加, 有的时候我们需要在项目中增加一些很耗时的操作, 比如上传了视频后需要压缩视频等操作, 会产生大量的IO等待, 又比如一些汇总查询, 都是很耗时的操作, 这个时候我们就需要将这些操作放到别的进程去执行, 那么就又需要加入两个新的组件: 消息总线和任务服务.
3.小苗规模
这个阶段呢, 有一些需求会需要访问慢IO, 或者产生高CPU运算的任务, 会严重影响系统的吞吐量. 这个时候我们需要充分的运用多核CPU的优势, 将耗时的工作交给别的CPU去搞定, 所以需要一个进程管理器来管理一组进程来专门接收-执行这些任务, 而为了通知这些进程来获取要执行任务的数据, 需要消息总线来负责在Web应用和进程管理器之间来传递消息.
加上这两个组件后, 项目的结构变成了这样子:
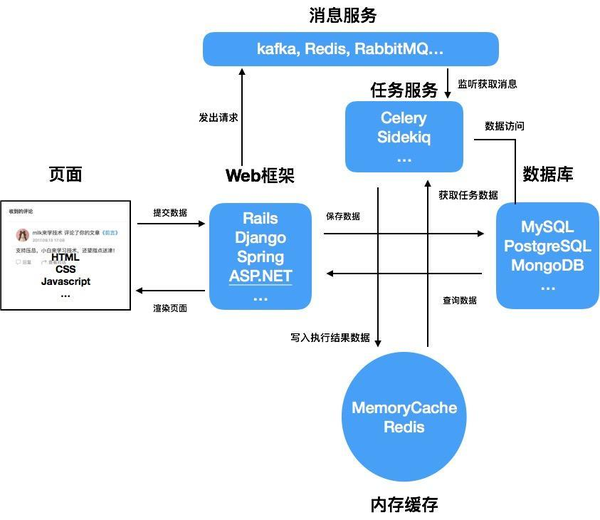
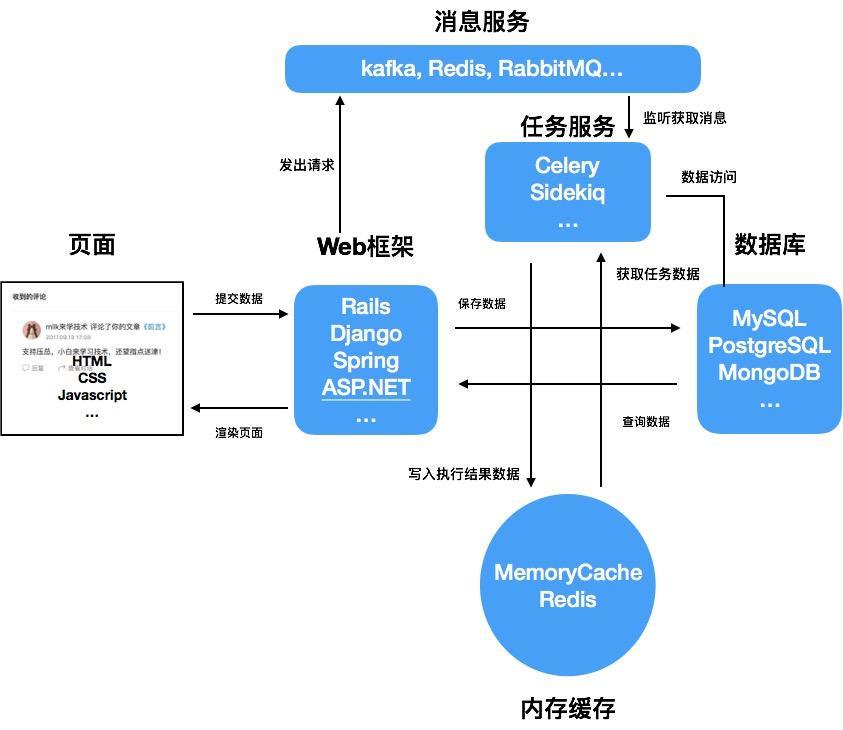
在这个阶段, 我们已经可以精细的将不同开销的任务解藕开, 将高开销, 高耗时的逻辑从Web的主进程中剥离出来, 从而满足进一步扩大系统吞吐量的目的.
而消息服务的引入进一步扩展了系统的弹性, 我们可以将不同的功能分解成独立的服务, 各自通过消息服务整合起来, 从而实现了整个系统的微服务化.
在这个结构下, 一个开销很大的请求的执行过程如下:
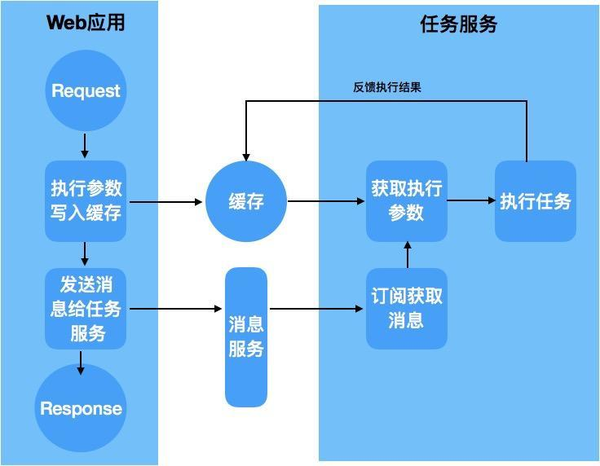

由任务服务处理的请求执行过程在这个阶段, 各个模块已经实现了基本上的解藕, 无论是功能或者容量上的扩展都比较方便了, 所以接下来的目标就是针对一个特殊的需求添加必要的组件了
4. 小树规模(生长枝条)
演变到这个阶段, 系统的大体模型已经固定下来了, 生下来的是根据不同的需要添加一些特殊的组件了.结构如下:
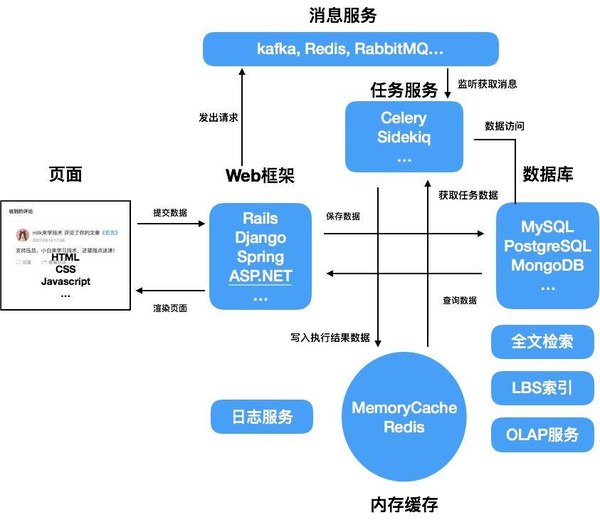

4.1 全文检索
在传统的关系型数据库中, 类似 Like '% 张三 %' 这类的查询都是会丢失索引, 所以类似这样的查询只有通过全文检索引擎来搜索才能有足够的效率, 在互联网领域用得最多的MySQL在全文检索方面的功能太过于孱弱, 所以现在而今眼目下业内大多用Solr, Elasticsearch等全文检索引擎来提供全文检索服务. 如果你是PostgreSQL党的话就会省心很多, 数据库自带的Gist, Gin, Brin这些类型的索引都能提供很好的全文检索能力.
4.2 日志系统(收集+存储+检索)
当整个系统都微服务化后, 服务进程数量很多, 且会分布在不同的主机上, 这个时候再将日志写到本地磁盘上, 采集整理日志会非常的痛苦, 所以需要统一的日志系统来处理系统日志.
一般的日志系统都是由 前端采集器 - 采集对列 - 写入器 三个部分构成, 数据存储基本上都由全文检索引擎来搞定了, 这样方便了后续对日志的处理.
4.3 LBS索引
在传统的关系型数据库中没有Gist索引, 所以没有办法对经纬度等数据进行索引, 所以需要单独的LBS索引服务. 当然对于PostgreSQL来说并没有这个必要.
4.4 OLAP数据仓库(数据分析)
我们常用的MySQL, PostgreSQL都是OLTP型的关系型数据库, 也就是针对联机事务处理优化模式工作的数据库, 俗话说就是针对 增删改查等操作专门优化, 跑起来傻快傻快的, 但是对于要做汇总查询之类的就速度上不行了. 如果要对数据进行专门的挖掘钻取的话, 需要把数据存入专门对数据分析优化的OLAP类型的数据仓库中. 术业有专攻, 这个领域不是强项所以简略带过, 后面有机会再详细说
以上所有的服务我们在后面都有相应的主题来详细描述, 这里就简略带过了.
5. 大树规模(群集化, 超大规模)
在这个阶段, 结构得到了充分的展开, 每一个组件充分的解藕, 就能够根据具体的系统负载来针对特定的瓶颈来优化, 扩容, 升级. 这个时候并没有一个固定的模式了, 不同的业务需求, 不同的数据类型都会造成在这个阶段的需求是不一样的, 结构也是不一样的, 所以我们会单独拿一个主题来详细说明.
下一节主题: Web框架如何快速入门
文章被以下专栏收录
