神经网络权重矩阵初始化的意义?
15 个回答

也说说我的看法,神经网络要优化一个非常复杂的非线性模型,而且基本没有全局最优解,初始化在其中扮演着非常重要的作用,尤其在没有BN等技术的早期,它直接影响模型能否收敛。下面从几个方向来说,参考
01 初始化的重要性
2006年Hinton等人在science期刊上发表了论文“Reducing the dimensionality of data with neural networks”,揭开了新的训练深层神经网络算法的序幕。
利用无监督的RBM网络来进行预训练,进行图像的降维,取得比PCA更好的结果,通常这被认为是深度学习兴起的开篇。


这么看来,是因为好的初始化方法的出现,才有了深层神经网络工程化落地的可能性。
好的初始化应该满足以下两个条件:
(1) 让神经元各层激活值不会出现饱和现象;
(2) 各层激活值也不能为0。
也就是激活值不要太大,也不要太小,应该刚刚好,当然这还只是最基本的要求。
我们都知道在早期,sigmoid激活函数是多层感知器模型的标配,上面这篇文章同样也是用sigmoid激活函数,没有那么多问题,是因为使用了预训练。
如果不使用预训练会如何?在Xavier Glorot和Yoshua Bengio提出xavier初始化方法的论文【1】中就对不同的激活函数使用不同的数据集做过实验。
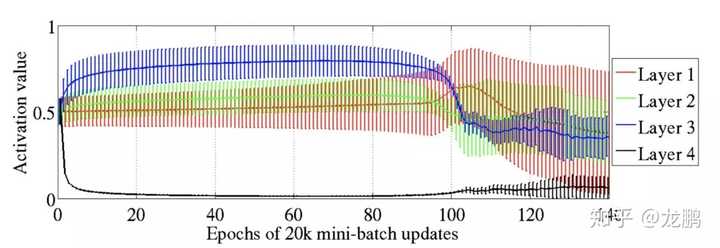

上面是一个四层的神经网络在sigmoid函数激活下的训练过程,可以看到最深的layer4层刚开始的时候很快就进入了饱和区域(激活值很低),其他几层则比较平稳,在训练的后期才能进行正常的更新。
为什么会这样呢?网络中有两类参数需要学习,一个是权重,一个是偏置。对于上面的结果作者们提出了一个假设,就是在网络的学习过程中,偏置项总是学的更快,网络真正的输出就是直接由layer4决定的,输出就是softmax(b+Wh)。既然偏置项学的快,那Wh就没有这么重要了,所以激活值可以低一点。
解释虽然比较牵强,但是毕竟实验结果摆在那里,从tanh函数的激活值来看会更直观。
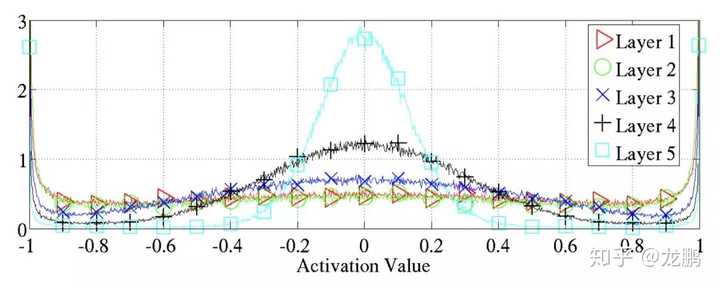

这个图有个特点是,0,1和-1的值都不少,而中间段的就比较少。在0值,逼近线性函数,它不能为网络的非线性能力作出贡献。对于1,-1,则是饱和区,没有用。
02 常用的初始化方法
1、全零初始化和随机初始化
如果神经元的权重被初始化为0, 在第一次更新的时候,除了输出之外,所有的中间层的节点的值都为零。一般神经网络拥有对称的结构,那么在进行第一次误差反向传播时,更新后的网络参数将会相同,在下一次更新时,相同的网络参数学习提取不到有用的特征,因此深度学习模型都不会使用0初始化所有参数。
而随机初始化就是搞一些很小的值进行初始化,实验表明大了就容易饱和,小的就激活不动,再说了这个没技术含量,不必再讨论。
2.标准初始化
对于均匀分布,X~U(a,b),概率密度函数等于:


它的期望等于0,方差等于(b-a)^2/12,如果b=1,a=-1,就是1/3。
下面我们首先计算一下,输出输入以及权重的方差关系公式:


如果我们希望每一层的激活值是稳定的,w就应该用n的平方根进行归一化,n为每个神经元的输入数量。
所以标准的初始化方法其权重参数就是以下分布:


它保证了参数均值为0,方差为常量1/3,和网络的层数无关。
3.Xavier初始化
首先有一个共识必须先提出:神经网络如果保持每层的信息流动是同一方差,那么会更加有利于优化。不然大家也不会去争先恐后地研究各种normalization方法。
不过,Xavier Glorot认为还不够,应该增强这个条件,好的初始化应该使得各层的激活值和梯度的方差在传播过程中保持一致,这个被称为Glorot条件。
如果反向传播每层梯度保持近似的方差,则信息能反馈到各层。而前向传播激活值方差近似相等,有利于平稳地学习。
当然为了做到这一点,对激活函数也必须作出一些约定。
(1) 激活函数是线性的,至少在0点附近,而且导数为1。
(2) 激活值关于0对称。
这两个都不适用于sigmoid函数和ReLU函数,而适合tanh函数。
要满足上面的两个条件,就是下面的式子。
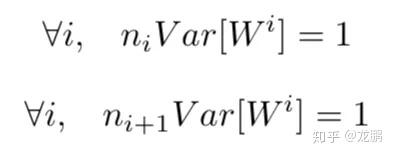
推导可以参考前面标准初始化的方法,这里的ni,ni+1分别就是输入和输出的神经元个数了,因为输入输出不相等,作为一种权衡,文中就建议使用输入和输出的均值来代替。
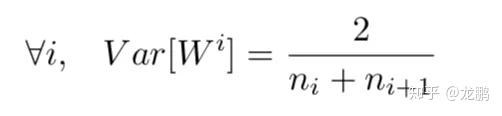

再带入前面的均匀分布的方差(b-a)^2/12,就得到了对于tanh函数的xavier初始化方法。


下面这两个图分别是标准初始化和xavier初始化带来的各层的反传梯度方差,可以看出xavier确实保持了一致性。


4.He初始化
Xavier初始化虽然美妙,但它是针对tanh函数设计的,而激活函数现在是ReLU的天下,ReLU只有一半的激活,另一半是不激活的,所以前面的计算输入输出的方差的式子多了一个1/2,如下。


因为这一次没有使用均匀初始化,而是使用了正态分布,所以对下面这个式子:


需要的就是这样的正态分布。

综上,对于两大最经典的激活函数,各自有了对应的初始化方法。虽然后面还提出了一些其他的初始化方法,但是在我们这个系列中就不再详述了。
03 关于初始化的一些思考
初始化这个问题明显比较麻烦,不然大家也不会这么喜欢用pretrained模型了。
从前面我们可以看到,大家努力的方向有这么几个。
(1) 预训练啊。
机智地一比,甩锅给别人, 。
(2) 从激活函数入手,让梯度流动起来不要进入饱和区,则什么初始化咱们都可以接受。
这其实就要回到上次我们说的激活函数了,ReLU系列的激活函数天生可以缓解这个问题,反过来,像何凯明等提出的方法,也是可以反哺激活函数ReLU。
(3) 归一化,让每一层的输入输出的分布比较一致,降低学习难度。
回想一下,这不就是BN干的活吗?所以才会有了BN之后,初始化方法不再需要小心翼翼地选择。假如不用BN,要解决这个问题有几个思路,我觉得分为两派。
首先是理论派,就是咱们从理论上分析出设计一个怎么样的函数是最合适的。
对于Sigmoid等函数,xavier设计出了xavier初始化方法,对于ReLU函数,何凯明设计了he初始化方法。
在此之上,有研究者分别针对零点平滑的激活函数和零点不平滑的激活函数提出了统一的框架,见文【2】,比如对于sigmoid,tanh等函数,方差和导数的关系如此。
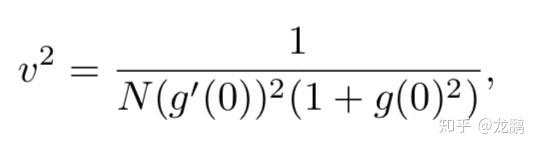

然后是实践派,在训练的时候手动将权重归一化的,见文【3】,这就是向归一化方法靠拢了,下期咱们再讲。
好的初始化方法就是赢在起跑线,不过现在的初始化方法也不是对什么数据集都有效,毕竟不同数据集的分布不同,咱们以后再谈。
下期预告:论深度学习中的归一化
[1] Glorot X, Bengio Y. Understanding the difficulty of training deep feedforward neural networks[C]//Proceedings of the thirteenth international conference on artificial intelligence and statistics. 2010: 249-256.
[2] Kumar S K. On weight initialization in deep neural networks[J]. arXiv preprint arXiv:1704.08863, 2017.
[3] Mishkin D, Matas J. All you need is a good init[J]. arXiv preprint arXiv:1511.06422, 2015.

因为随随便便初始化可能碰到这种情况:


从图中,我们可以直观地看到网络有不少问题:
- 左上,后几层的Z值区间太窄了,几乎消失了。
- 左下,经过tanh激活之后的输出,和Z值可以说是难兄难弟。
- 右上,权重也好不到哪里去,缩在正负0.02这么小的一个范围。
- 右下,最后一层的梯度步向消亡。
这些都是训练的不利因素。
把 \sigma 放大呢?
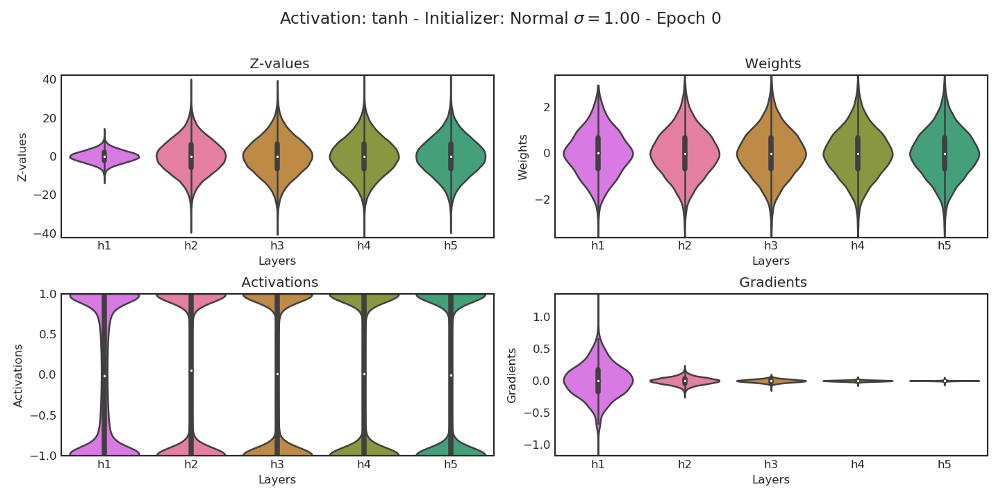

好了,我们又碰到了新问题:
- 左上,Z值的区间太宽了(正负20)
- 左下,受Z值所累,激活塌缩到大多数值要么是零要么是一的严重两级分化的情形
- 右下,有没有发现从最后一个隐藏层反向传播至第一个隐藏层的过程中,梯度越来越大?很不幸,我们碰到了梯度爆炸。
然后对比一下Glorot初始化方案的效果:


多漂亮!
Z值、梯度、激活值在所有层上都类似,并且处于适宜的区间。这对深度学习而言很重要。层与层之间相似,意味着我们可以轻松地堆叠很多层(毕竟都叫“深度”了,没有很多层怎么行?)也不再受梯度消失、爆炸的困扰。
另外,初始化方案还取决于激活函数。比如Glorot搭配ReLU就不那么合适了:


ReLU和He才是良配:


最后交代下上面的网络配置:5个隐藏层,每层100个神经元,典型的二元分类输出层。输入是从一个十维球中抽取的1000个随机数据点(均值为零,单位标准差)。球半径一半以内的数据点为负面情形(0),剩余数据点为正面情形(1)。
本回答基于 Daniel Godoy授权论智编译的 《可视化超参数作用机制:二、权重初始化》改编。

其实在实际写神经网络的时候,不管你是否可以去初始化,权重和偏置都是有初始值的。
没有图可能不太好解释,之前玩过一个应该是tensorflow的一个playground,里面可以玩神经网络流图,很直观,其中有提供初始化值的内容。多玩几次之后你会发现,对不同的数据情况,一个好的初始化,可以让拟合过程大大缩短,成功率大大增加,而一个极差的初始化,有可能让拟合过程变得极为漫长,甚至无法正确拟合。
如果我们在一开始没有对神经网络权重和偏置进行好的初始化,拟合过程会变得极为漫长,即使CPU和GPU非常强劲,也未必能成功拟合(更有可能出现人工神经元死亡的情况,在一些特定的激励函数下),而一个好的初始化,就好像给这个神经网络赋予了这一方面的天赋,使得整个工作变得简单许多。
所以说白了,初始化神经网络的权重和偏置,就好比是赋予它一种天赋,一种能适应需要处理的数据情况的天赋。
tensorflow playground 网址在这里:
http://playground.tensorflow.org

目前有很多关于如何做权重参数初始化的研究。因为深度学习权重初始化很重要,如果有问题就不会有好结果。这是一个非常重要的问题。
如果权值初始化为0的话,用梯度下降算法,那会完全失效。因为如果权重初始化为0,每个神经元将会输出同样的结果,方向传播时就会计算出同样的梯度,最后会得到完全相同的参数更新,所以算法失效。
如果用很小的随机数值初始化。比如用高斯分布乘以一个很小的常数进行初始化:W = 0.01 * np.random.randn()。对于层数较少的神经网络效果很好,但是随着层数的增加,对于初始化更为敏感。
实验表明随着隐含层隐藏层的增加,前面的层还是服从高斯分布的,但是越到后面的隐藏层隐含层输出值的分布图会趋近于0。
Glorot的文章 http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf这篇论文中,作者推荐的初始化方式是W=2/(n1+n2),其中n1是前一层的单元个数,n2是后一层的单元个数。Tensorflow的tf.contrib.layers.xavier_initializer()函数即使用的该方法。
Kai minghe发表的文章 https://arxiv-web3.library.cornell.edu/abs/1502.01852也做出了很多关于这方面的最新研究。这篇论文中作者推荐的初始化方式是:W = np.random.randn(n) * sqrt(2.0/n)

初始化的重要性
神经网络的参数学习是一个非凸优化问题.当使用梯度下降法来进行优化 网络参数时,参数初始值的选取十分关键,关系到网络的优化效率和泛化能力
要构建机器学习算法,通常你会定义一个架构(例如逻辑回归、支持向量机、神经网络)并训练它来学习参数。下面是一个常见的神经网络训练过程:
- 初始化参数
- 选择优化算法
- 重复这些步骤:
- 前向传播输入
- 计算成本函数
- 使用反向传播计算成本相对于参数的梯度
- 根据优化算法,使用梯度更新每个参数
初始化步骤对模型的最终性能至关重要
当初始化方法为零时,会发生什么?
用零初始化所有权重会导致神经元在训练期间学习相同的特征
考虑这个 9 层神经网络。


假设激活函数是线性的 (恒等函数,即y=x).
注意:激活函数必须使用非线性的,这里只是为了便于展示
\hat{y} = a^{[L]} = W^{[L]}W^{[L-1]}W^{[L-2]}\dots W^{[3]}W^{[2]}W^{[1]}x
其中神经网络的层数L=10, W^{[1]},W^{[2]},\dots,W^{[L-1]} 是 (2,2) 的矩阵,每个神经元有两个输入
假设 W^{[1]} = W^{[2]} = \dots = W^{[L-1]} = W
则可以得到 y^=W^{[L]}W^{L−1}x
其中 W^{L−1} 代表矩阵 W 的 L-1 次方, W^{[L]} 表示第 L 的矩阵
过大的初始化导致梯度爆炸
考虑每个权重的初始化略大于单位矩阵的情况
W^{[1]} = W^{[2]} = \dots = W^{[L-1]}=\begin{bmatrix}1.5 & 0 \\ 0 & 1.5\end{bmatrix}
可以简化为 \hat{y} = W^{[L]}1.5^{L-1}x ,随着指数增长。当用于反向传播时,这会导致梯度爆炸问题
太小的初始化导致梯度消失
W^{[1]} = W^{[2]} = \dots = W^{[L-1]}=\begin{bmatrix}0.5 & 0 \\ 0 & 0.5\end{bmatrix}
可以简化为 \hat{y} = W^{[L]}0.5^{L-1}x y ,随着指数下降。当用于反向传播时,这会导致梯度消失问题
预训练初始化
不同的参数初始值会收敛到不同的局部最优解.虽然 这些局部最优解在训练集上的损失比较接近,但是它们的泛化能力差异很大.一 个好的初始值会使得网络收敛到一个泛化能力高的局部最优解.
通常情况下,一 个已经在大规模数据上训练过的模型可以提供一个好的参数初始值,这种初始 化方法称为预训练初始化(Pre-trained Initialization). 预训练任务可以为监督学习或无监督学习任务.由于无监督学习任务更容 易获取大规模的训练数据,因此被广泛采用.预训练模型在目标任务上的学习过 程也称为精调(Fine-Tuning)
预训练初始化通常会提升模型泛化能力的一种解释是预训练任务起到一定的正则化作用.
随机初始化
在线性模型的训练(比如感知器和Logistic回归)中,我 们一般将参数全部初始化为 0.但是这在神经网络的训练中会存在一些问题.因 为如果参数都为 0,在第一遍前向计算时,所有的隐藏层神经元的激活值都相 同;在反向传播时,所有权重的更新也都相同,这样会导致隐藏层神经元没有区 分性.这种现象也称为对称权重现象.为了打破这个平衡,比较好的方式是对每 个参数都随机初始化(Random Initialization),使得不同神经元之间的区分性更好.
固定值初始化
对于一些特殊的参数,我们可以根据经验用一个特殊 的固定值来进行初始化.比如偏置(Bias)通常用 0 来初始化,但是有时可以设置某些经验值以提高优化效率.在 LSTM 网络的遗忘门中,偏置通常初始化为1或2,使得时序上的梯度变大.对于使用ReLU的神经元,有时也可以将偏置设为 0.01,使得 ReLU 神经元在训练初期更容易激活,从而获得一定的梯度来进行误差反向传播
Xavier初始化
来源
Xavier 初始化方法, Xavier是发明者Xavier Glorot 的名字.Xavier 初始化也称为Glorot初始化
来源论文:
目标:
初始化权重,使得激活的方差在每一层都相同。这种恒定的方差有助于防止梯度爆炸或消失
理论知识:
假设在一个神经网络中,第 l 层的一个神经元 a^{ (l )} ,其接收前一层的 M_{l −1 } 个 神经元的输出 a^{( l−1)}_{i} , 1 ≤i ≤ M_{i −1} ,偏置初始化为0
a^{(l)} = f( \sum^ {M_ {l−1}}_ {i= 1} w ^ {(l)} _ {i} a ^ {(l−1)} _ i)
其中 f (⋅) 为激活函数, w ^ {(l)}_i 为参数, M_ {l−1} 是第 l− 1 层神经元个数.为简单起见, 这里令激活函数 f (⋅) 为恒等函数,即 f(x) = x
同时考虑信号在前向和反向传播中都不被放大或缩小,可以设置
var( w ^ {(l)}_{i})=\frac{2}{M_{l-1}+M_l}
在计算出参数的理想方差后,可以通过高斯分布或均匀分布来随机初始化参数.
若采用高斯分布来随机初始化参数,连接权重 w ^ {(l)}_i 可以按 N(0,\frac{2}{M_{l-1}+M_l}) 的高斯分布进行初始化.
若采用区间为 [−r , r ] 的均匀分布来初始化w ^ {(l)}_i,则 的 取值为 \sqrt \frac{6}{M_{l-1}+M_l}
TensorFlow实现:
# Standalone usage:
initializer = tf.keras.initializers.GlorotUniform()
values = initializer(shape=(2, 2))
# Usage in a Keras layer:
initializer = tf.keras.initializers.GlorotUniform()
layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)Kaiming初始化(He初始化 )
理论知识:
当第 层神经元使用ReLU激活函数时,通常有一半的神经元输出为0,因此 其分布的方差也近似为使用恒等函数时的一半.这样,只考虑前向传播时,参数w ^ {(l)}_i的理想方差为
var(w ^ {(l)}_{i})=\frac{2}{M_{l-1}}
其中M_{l-1} 是第 − 1 层神经元个数
因此当使用 ReLU 激活函数时,若采用高斯分布来初始化参数w ^ {(l)}_i ,其方差为 \frac{2}{M_{l-1}} ;若采用区间为 [−r , r ] 的均匀分布来初始化参数w ^ {(l)}_i,则 r= \sqrt\frac{6}{M_{l-1}}
TensorFlow实现:
# Standalone usage:
initializer = tf.keras.initializers.HeNormal()
values = initializer(shape=(2, 2))
# Usage in a Keras layer:
initializer = tf.keras.initializers.HeNormal()
layer = tf.keras.layers.Dense(3, kernel_initializer=initializer)

参考:
- 邱锡鹏《神经网络与深度学习》
2. https://www.tensorflow.org/api_docs/python/tf/keras/initializers/

在没有任何正则化的情况下,训练神经网络令人望而却步,因为要对权重初始化条件进行微调。这也是神经网络经历过寒冬的一个原因。因为 dropout 与批规范化技术,该问题有所改进,但我们不能用对称的方式初始化权重(例如都是 0),也不能把它们初始化的太大。一个好的 heuristic 是


参考自: https://www.jiqizhixin.com/articles/2017-09-07-9

神经网络训练的过程就是对网络权重不断学习更新的过程,网络初始权重对网络的训练非常重要。不合适的初始化方法可能会导致网络参数传播过程中产生梯度消失、梯度爆炸等现象。
常用的初始化方法有随机初始化、Xavier初始化、he初始化等
1 零初始化
对于逻辑回归,网络权重是可以初始化为0的;对于深度神经网络,网络权重和偏置是不可以一起初始化为0的,不然会造成每层的网络所有节点输出是一致的,具体分析可以参考
2 随机初始化
随机初始化的时候常常采用高斯或均匀分布初始化网络权重。这种方法相对0初始化要好许多,但是在遇到激活函数为sigmoid / tanh的时候,可能会出现梯度消失或者爆炸现象
以四层网络,参数为w_1, b_1, w_2, b_2, w_3, b_3, w_4, b_4,激活函数为sigmoid,\sigma(x) = \frac{1}{1+e^{-x}}。
y_i = \sigma(z_i) \\z_i = w_i y_{i-1} + b_i \\
sigmoid函数求导数\sigma^{'} = \sigma (1-\sigma)后,峰值为0.25;损失函数C对b_1的导数为
\frac{\partial C}{\partial b_1} = \frac{\partial C}{\partial y_4} \frac{\partial y_4}{\partial z_4} \frac{\partial z_4}{\partial y_3} \frac{\partial y_3}{\partial z_3} \frac{\partial z_3}{\partial y_2} \frac{\partial y_2}{\partial z_2} \frac{\partial z_2}{\partial y_1} \frac{\partial y_1}{\partial z_1} \frac{\partial z_1}{\partial b_1} = \frac{\partial C}{\partial y_4} \sigma(z_4)^{'} w_4 \sigma(z_3)^{'} w_3 \sigma(z_2)^{'} w_2 \sigma(z_1)^{'} 1 \\
sigmoid 函数对于大到10的值,sigmoid的值几乎是1,对于小到-10的值,sigmoid的值几乎为0。意味着如果权值矩阵被初始化成过大的值,权重w_i连乘会出现梯度爆炸的现象,反之,当权值矩阵被初始化成太小的值,可能会出现梯度消失
3 Xavier初始化
Xavier初始化通过保持输入和输出的方差一致(服从相同的分布)避免梯度消失和梯度爆炸问题,使得信号在神经网络中可以传递得更深,在经过多层神经元后保持在合理的范围(不至于太小或太大)。
xavier均匀分布
w \sim U[-\frac{\sqrt{6}}{\sqrt{n_{in}+n_{out}}},\frac{\sqrt{6}}{\sqrt{n_{in}+n_{out}}}] \\
xavier正态分布
w \sim N[mean=0, std=\frac{\sqrt{2}}{\sqrt{n_{in}+n_{out}}}] \\
适用于激活函数为tanh的深层网络,但不适用于RELU
4 He初始化
He初始化解决的问题:ReLU网络每一层有一半的神经元被激活,另一半为0(x负半轴中是不激活的),所以要保持variance不变,只需要在Xavier的基础上再除以2。
He均匀分布
w \sim U[-\frac{\sqrt{6}}{2\sqrt{n_{in}+n_{out}}},\frac{\sqrt{6}}{2\sqrt{n_{in}+n_{out}}}] \\
He正态分布
w \sim N[mean=0, std=\frac{\sqrt{2}}{\sqrt{n_{in}}}]\ \\
参考
1、 参数初始化
2、 网络权重初始化方法总结
欢迎关注微信公众号(算法工程师面试那些事儿),本公众号聚焦于算法工程师面试,期待和大家一起刷leecode,刷机器学习、深度学习面试题等,共勉~


权重有效初始化可以防止激活值在深度神经网络的正向传递过程中出现梯度爆炸或者梯度消失。 模型经过权重初始化后,在训练、更新权重时主要会出现以下2种情况:
1)如果初始权重太小,导致神经元的输入过小, 随着层数的不断增加,会出现信号消失的问题,也会导致 sigmoid激活函数中强调的丢失非线性的能 力,因为在0附近 sigmoid 函数是近似线性的。
2)如果初始权重太大,会导致输入状态也较大, 对sigmoid激活函数来讲,激活函数的值会变得饱和,从而出现梯度消失的问题。
无论上述哪一种情况发生,损失梯度要么太大或要么太小,更新信息都无法有效地向后传递,网络 则需要很长时间才能收敛。因此很多学者研究了各种初始化方法来避免这些问题,如:通过保持一层网络的输入和输出方差不变来防止梯度消失的 Xavier 初始化方法;He初始化方法通过加重权重方差的方式弥补ReLU 激活函数1/2为零的状态。
目前针对权重初始化方法的思路更多偏向于正态分布和均匀分布,但还不能更好地以合适的数据对深度学习网络进行初始化。若使模型的初始权重分布与训练后模型权重的分布接近,将有助于模型 获得最优解,减少模型的训练时间,因此假如你自己研究领域的先验可以作为一个有效的创新点。

王辉


PyTorch不同层都有默认不同的初始化方法,最开始并且最常见的初始化方法就叫做 Xavier初始化或者glorot初始化,(翻译 泽维尔)
2010年论文 Understanding the difficulty of training deep feed forward neural networks
模型初始化是非常影响模型性能的,先想最简单的一种方法,全零初始化方法,




因此对于参数全0初始化的话,会出现 \sigma_1和\sigma_2 有完全相同的参数更新,最下面也会出现同样的情况,即这样来看会出现每一层的参数都会是一样的情况,这种现象称作参数的绝对对称问题,如果对linear层来说每一层的神经网络都会退化成单一神经元,可以理解为若具有相同 激活函数的两个隐藏单元连接到相同输入,如果它们具有相同的初始参数,应用到确定性损失和确定性的学习算法,它们的参数将一直以相同的方式更新。
这样的方法不行,所以需要探究合适的参数初始化方法。
首先,为了能够让网络中的信息更好的传递,每一层的特征的方差要尽可能相等。因为每一层特征的方差都不断的震荡的话,后面的网络很难捕捉到有用的数据特征,模型难以进行训练,2015年Google提出了Batch normalization, 其论文中提出了一个概念:(Internal Covariance Shift,ICS),就是这种前面的层老动,后面的层难以静下心学习。现在就要从参数初始化这个方向解决这个问题。
对于输入 x_1,x_2...x_n ,经过神经网络的方差定义为:


假定输入的数据的均值为0,初始化权值的均值也为0,上面的方程可以转化为:

并且假设输入数据的方差为1

为了使得 var(s)=1,有

保证量纲和期望一致,将方差转化为标准差,确保标准差为 \frac{1}{\sqrt{n}}
即,无论采用何种初始化方法,确保标准差为 \frac{1}{\sqrt{n}}既可。
从正向传播来看,有 var(w)=\frac{1}{\sqrt{n_{in}}} ,从反向传播来看,有 var(w)=\frac{1}{\sqrt{n_{out}}}
可能 n_{in} 和 n_{out} 维度不同,平均既可,有 n = \frac{n_{in}+n_{out}}{2}
1. Xavier初始化 (glorot初始化)
对于均匀分布U(a,b),,期望和方差分别是

假定均匀分布为

在这里d为神经元的个数,则有期望和方差为

根据代入到下面表达式中,

可以得到:

因此为了保证最终的方差为1,因此方差需要乘以3,标准差则需要乘以√3。因此一般均匀分布的初始化值可以选择

则考虑输入和输出的维度,则均匀分布的初始化值为:

这个也就是init_xavier_uniform (笔者称之为 泽维尔-均匀分布初始化)
当然标准-均匀初始化就是:

因为,对于动态图网络,每一层是不知道后面层的,所以在Pytorch中一般采用这种初始化方法,如果对于静态图结构来说,xavier_uniform相对是一种更好的初始化方法。


同理,对于正太分布初始化是一样的方法,总结一下,有:

- 标准均匀初始化方法保证了激活函数的输入值的均值为0,方差为常量1/3,和网络的层数和神经元的数量无关。标准正太初始化方法,保证激活函数的输入均值为,方差为1。
- 对于sigmoid激活函数来说,可以确保自变量处于有梯度的范围内。 对于sigmoid函数,输出是大于0的,因此,对于前面的一系列假设中的数据的均值为0不成立,因此,标准初始化方法更适合 tanh激活函数。


- 该方法有一定限制,其推导过程假设激活函数在零点附近接近线性函数,且激活值关于0对称。sigmoid函数和relu函数不满足这些假设。
2. Kaiming初始化
https://www.cv-foundation.org/openaccess/content_iccv_2015/papers/He_Delving_Deep_into_ICCV_2015_paper.pdf
Xavier在tanh函数上表现可以,但对 ReLU,Sigmoid 等激活函数效果不好,何凯明引入了一种更鲁棒的权重初始化方法--He Initialization。
He初始化基本思想是,当使用ReLU做为激活函数时,Xavier的效果不好,原因在于,当RelU的输入小于0时,其输出为0,相当于该神经元被关闭了,影响了输出的分布模式。
因此He初始化,在Xavier的基础上,假设每层网络有一半的神经元被关闭,于是其分布的方差也会变小。经过验证发现当对初始化值缩小一半时效果最好,故He初始化可以认为是Xavier初始/2的结果。
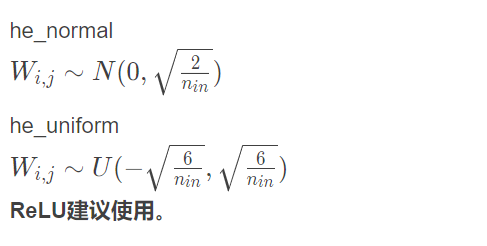

He Initialization适用于使用ReLU、Leaky ReLU这样的非线性激活函数的网络。因为,在CV领域,Relu激活函数是经常被使用的,因此,Kaiming应该是我们的首选权重初始化策略。
REF:
Xavier Glorot参数初始化: 理解训练Deep DNN的难点 https://www.cnblogs.com/yifanrensheng/p/13583219.html

我只说一句:非凸优化

Weight subcloning: direct initialization of transformers using larger pretrained ones


本文介绍了一种将预训练模型的权重初始化到更小的变体中,从而将预训练模型的知识转移到更小的模型中的方法,且通过从更大的预训练模型中初始化权重还可加速较小尺寸transformer的训练。权重子克隆对预训练模型进行操作以获得等效初始化的缩放模型,它包括两个关键步骤:首先,引入神经元重要性排名来降低在预训练模型中每个层中的嵌入维度。然后从Transformer模型中删除块以匹配缩放后网络中的层数。与随机初始化相比,它在训练速度上取得了显著的提高。例如,对于ViT在图像分类以及GPT中实现了4倍的训练速度。
Faster Diffusion: Rethinking the Role of UNet Encoder in Diffusion Models


该文对UNet编码器进行了全面研究,发现编码器的特征变化平缓,而解码器特征在不同时间步长上存在较大变化。基于这一观察,文章引入了一种简单而有效的编码器传播方案,以加速各种任务的扩散采样过程。此外,文章还引入了先验噪声注入方法来改善生成图像的纹理细节。除了标准文本到图像任务外,文章还在其他任务上验证了该方法的有效性,如文本到视频、个性化生成和参考导向生成。在不使用任何知识蒸馏技术的情况下,该方法加速了Stable Diffusion (SD)和DeepFloyd-IF模型的采样速度,分别提高了41%和24%,同时保持了高质量的生成性能。
DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models


本文提出了一种DreamTalk框架,来解锁Diffusion模型在生成具有表现力的talking head方面的潜力。DreamTalk由三个关键组件组成:去噪网络、嘴型风格感知和风格预测器。基于Diffusion的去噪网络能够在不同表情间合成一致的高质量音频驱动的面部动作。为了增强嘴唇动作的表现力和准确性,作者引入了一个嘴型风格感知模型,该模块可以引导嘴唇同步,同时注意说话风格。为了消除对表情参考视频或文本的需求,又使用额外的基于Diffusion的风格预测器直接从音频预测目标情绪。通过这种方式,DreamTalk可以利用强大的Diffusion模型高效地生成面部表情,减少对风格参考的依赖。实验结果表明,DreamTalk能够生成具有多种说话风格的真实照片般的talking face,并实现准确的嘴唇动作。
Agent Attention: On the Integration of Softmax and Linear Attention


本文提出了一种新的注意力机制:Agent Attention,它在计算效率和表示能力之间达到了良好的平衡。Agent Attention通过引入额外的agent tokens来改进传统的注意力模块。这些agent tokens首先为query tokens 从K和V中聚合信息,然后将信息广播回Q。由于agent tokens的数量可以设计得比query tokens少得多,因此agent attention比广泛采用的Softmax attention更高效,同时保留了全局上下文建模能力,作者证明了所提出的agent attention等效于一般化的线性注意力形式。大量实验表明,agent attention对各种视觉Transformers以及多种视觉任务(包括图像分类、目标检测、语义分割和图像生成)都有效。值得注意的是,由于其线性attention性质,agent attention在处理高分辨率场景时很出色。例如,当应用于Stable Diffusion时,agent attention可加速生成过程,并显著提高了图像生成质量,且无需任何额外训练。
Neural Video Fields Editing


扩散模型在文本驱动的视频编辑方面面临两个挑战:随着帧数增加,图形内存需求迅速增加;编辑视频的帧间一致性不一致。本文提出了NVEdit,旨在减轻内存开销并提高对长视频进行一致性编辑的能力。首先构建了一个由三平面和稀疏网格驱动的神经视频场,以有效地编码包含数百帧的长视频。然后通过现成的文本到图像(T2I)模型来更新视频场,以产生文本驱动的编辑效果。同时还开发了一种渐进优化策略,以保留原始的时间先验。实验表明,该方法能够成功编辑数百帧,并具有很好的一致性。
VideoLCM: Video Latent Consistency Model
 https://www.zhihu.com/video/1720184172126314496
https://www.zhihu.com/video/1720184172126314496本文提出了VideoLCM框架,其利用一致性模型的概念,通过最少的步骤合成高质量视频。它建立在现有的潜在视频扩散模型之上,并采用一致性蒸馏技术训练潜在一致性模型。实验结果表明,VideoLCM在计算效率、保真度和时间一致性方面都很有效,在仅用四步采样时也可实现高保真和平滑的视频合成。

因为神经网络是非convex问题,所以有多个local minima,这样的话,初始化值不一样,最后收敛的minima也不一样。也就是说,初始化值不一样,最后的模型不一样。

本视频详细说明了神经网络权重矩阵初始化的意义主要是为了避免在多层网络传播的过程中带来的数据特征分布的改变。
更多课程内容见

权重初始化原则
神经元基本模型:假设输入为x^{[l]},经过线性层后为y^{[l]},经过激活函数\sigma后为z^{[l]},如下图所示。


基本原则
- 一般情况下,对权重大小和正负缺乏先验,所以应该初始化在0附近,但不能全为0或常数,所以要有一定的随机性,即要求数学期望E(\omega)=0
- 因为梯度消失和梯度爆炸,权重不宜过大或过小,所以要对权重的方差\operatorname{Var}(\omega)有所控制
- 深度神经网络的多层结构中,每个激活层的输出对后面的层而言都是输入,所以我们希望不同激活层输出的方差相同,这也就意味着不同激活层输入的方差相同,即\operatorname{Var}(z^{[l]})=\operatorname{Var}(z^{[l-1]})
- 模型有前向传播和后向传播两个过程,权重的数值范围应该考虑前向和后向两个过程,一般分两种初始化方法。
一些初始化方法
权重的随机初始化过程可以看成是从某个概率分布随机采样的过程,常用的分布有高斯分布、均匀分布等,对权重期望和方差的控制可转化为概率分布参数的控制,权重初始化问题也就变成了概率分布的参数设置问题。
一般的权重初始化方法如下图总结。


对于多层感知机而言,fan\_in和fan\_out分别是当前全连接层的输入和输出的数量。对于卷积层而言,如果输入通道为c_1,输出通道为c_2,卷积核尺寸为k_1\times k_2,则fan\_in=c_1\times k_1\times k_2,fan\_out=c_2\times k_1\times k_2.
期望和方差性质
对于随机变量X,方差定义为
\operatorname{Var}(X)=E(X^2)-E^2(X)\\
如果有两个随机变量X和Y,那么它们的协方差定义为
\operatorname{Cov}(X, Y)=E[(X-E(X))(Y-E(Y))]\\
如果两个随机变量相互独立,那么
\operatorname{Cov}(X, Y)=0 \Leftrightarrow E(XY)=E(X)E(Y) \\
可以证明两个独立随机变量和的方差和两个独立随机变量积的方差有如下性质
\operatorname{Var}(X+Y)=\operatorname{Var}(X)+\operatorname{Var}(Y)\\ \operatorname{Var}(XY)=\operatorname{Var}(X)\operatorname{Var}(Y)+E^2(X)\operatorname{Var}(Y)+\operatorname{Var}(X)E^2(Y) \\
线性层方差分析
在初始化阶段,将每个权重及其每个输入视为随机变量,可做如下假设和推断: - 网络输入的每个元素x_1,x_2,\cdots,x_{fan\\_in}为独立同分布,且期望E(x)=0; - 每层的权重随机初始化,权重w_1,w_2\cdots,w_{fan\\_in}独立同分布,且期望E(w)=0; - 每层的权重w和输入x随机初始化且相互独立,所以两者之积的随机变量也相互独立,且同分布;所以经过这一层的输出也独立同分布。
需要注意的是,上面独立同分布假设只有在初始化阶段成立,当模型开始训练时,根据反向传播公式,权重更新后不再相互独立。
在初始化阶段,假设偏置b=0,输出方差和输入的关系为
\begin{aligned} \operatorname{Var}(y)&=\operatorname{Var}(\sum_{i=1}^{fan\_in}w_i x_i)\\ &=fan\_in\times \operatorname{Var}(wx)\\ &=fan\_in\times (\operatorname{Var}(w)\operatorname{Var}(x)+E^2(w)\operatorname{Var}(x)+\operatorname{Var}(w)E^2(x))\\ &=fan\_in \times\operatorname{Var}(w)\operatorname{Var}(x) \end{aligned} \\
那么,如果要使得经过线性层的方差保持不变,可以推导出权重的方差需要初始化为
\operatorname{Var}(w)=\frac{1}{fan\_in} \\
如果使用高斯分布初始化,那么
w\sim \mathcal N(\mu=0, \sigma=\sqrt{\frac{1}{fan\_in}}) \\
如果使用均匀分布初始化,由于\operatorname{Var}U(a,b)=\frac{(b-a)^2}{12},那么
w\sim U(a=-\sqrt{\frac{3}{fan\_in}}, b=\sqrt{\frac{3}{fan\_in}}) \\
tanh方差分析
假设在激活函数过原点且原点处的斜率为k,由于输入数据分布在原点附近,初始化时激活函数的作用近似为z=ky,那么经过线性层和这个激活函数后的方差为
\operatorname{Var}(z)=k^2 \operatorname{Var}(y)=\frac{k^2}{fan\_in} \\
tanh激活函数在原点的导数为k=1,可以推导出使用tanh激活函数的线性层需要初始化为
w\sim \mathcal N(\mu=0, \sigma=\sqrt{\frac{1}{fan\_in}}) \\
PReLU方差分析
数据经过如ReLU、PReLU这类的激活函数后不再保持零均值的特性,对于下一层而言,输入的期望E(x)\neq 0,那么在线性层方差分析中推导出的输出方差和输入的关系就变为
\begin{aligned} \operatorname{Var}(y)&=fan\_in\times (\operatorname{Var}(w)\operatorname{Var}(x)+\operatorname{Var}(w)E^2(x))\\ &=fan\_in\times (\operatorname{Var}(w)(E(x^2)-E^2(x))+\operatorname{Var}(w)E^2(x))\\ &=fan\_in\times \operatorname{Var}(w)\times E(x^2) \end{aligned}\\
ReLU激活函数是特殊的PReLU激活函数,以PReLU为例进行方差分析,其定义为
\operatorname{PReLU}(y)=\begin{cases} y, &\text{ if }y\geq 0\\ ay, &\text{otherwise} \end{cases} \\
初始化的权重w和数据x是独立的,有E(y)=E(\sum_{i=1}^{n} w_i x_i)=nE(w)E(x),又因为E(w)=0,故E(y)=0。这表明经过线性层后的数据均值总是为零。此外,由于y的分布是对称的,即p(y)=p(-y),则有E_{y\sim (-\infty,0)}(y)=E_{y\sim(0,\infty)}(y)。可以推导出
\begin{aligned} E(z^2)&=\int_{-\infty}^{\infty}z^2p_z(z)dz\\ &=\int_{-\infty}^0z^2p_z(z)dz+\int_0^{\infty}z^2p_z(z)dz\\ &=\int_{-\infty}^0a^2y^2p_z(z)dz+\int_0^{\infty}y^2p_y(y)dy\\ &=\int_{-\infty}^0a^2y^2p_y(y)dy+\int_0^{\infty}y^2p_y(y)dy\quad \text{(第一项利用对应点概率微元相等)}\\ &=\int_0^{\infty}a^2y^2p_y(y)dy+\int_0^{\infty}y^2p_y(y)dy\\ &=\frac{a^2+1}{2}\int_{-\infty}^{\infty}y^2p_y(y)dy\\ &=\frac{a^2+1}{2}E(y^2)\quad\text{(利用y均值为零条件)}\\ &=\frac{a^2+1}{2}\operatorname{Var}(y) \end{aligned} \\
假设上一层也是使用PReLU激活函数,那么E(z^2)=E(x^2),带入方差关系可以解得
\operatorname{Var}(w)=\frac{2}{(a^2+1)fan\_in} \\

初始化对梯度下降过程中找到全局最优解或避免进入不好的局部最优解有帮助。还有良好的初始化有利于深度网络的梯度传播,避免梯度消失或爆炸。具体可参考cs231n相关课程。