想系统学习机器学习,有什么书值得推荐?
69 个回答


以上各位答主已经回答得挺全面了,那我就从AI工程角度补充一些学习资源吧。 AI工程是一门新兴的学科,市面上的技术专著并不是很多,以下是我认为比较不错的一些书籍和课程,供大家参考:
一、书籍类
1、《机器学习工程实战》(Machine Learning Engineering)


作者:【加拿大】安德烈·布可夫
译者:王海鹏;丁静
本书侧重于讲解机器学习应用和工程实践技术,是对机器学习工程实践和设计模式的全面回顾。按照项目准备、数据收集和准备、特征工程、监督模型训练、模型评估、模型部署、模型服务、监测和维护等方面进行讲解,是为数不多的讲解如何应用机器学习的书籍之一。
2、《机器学习:软件工程方法与实现》


作者:张春强;张和平;唐振
这是一本介绍如何在机器学习项目实践中应用软件工程思想、方法、工具和技术的书籍。作者结合自己10年的工程实践经验,以机器学习核心概念和原理作为出发点,延伸介绍了数据分析和处理、特征选择、模型调参以及大规模模型和系统架构等多方面的应用技术和实践。
3、《机器学习流水线实战》(Building Machine Learning Pipelines)


作者:【美】汉内斯·哈普克;凯瑟琳·纳尔逊
译者:孔晓泉;郑炜;江骏
本书介绍了机器学习流水线每个环节的构建方法,以及如何利用TensorFlow Extended(TFX)构建机器学习流水线,包括数据读取、数据校验、数据预处理、模型训练、模型分析、模型验证、模型部署、模型反馈等环节,涵盖了整个机器学习模型开发的生命周期。
4、《机器学习系统:设计与实现》


作者:麦络、董豪、金雪锋、干志良
书籍由麦络(爱丁堡大学)、董豪(北京大学、鹏程实验室)、金雪锋(MindSpore首席架构师)、干志良(MindSpore架构师)主导,联合学术界、工业界的老师和专家共同写作。
作为一名软件工程师,可以通过市面上大部分的深度学习/机器学习书籍或教程,学习经典算法(如SGM、逻辑回归、朴素贝叶斯)、主流神经网络(CNN、RNN、GNN),并使用框架完成训练、部署和推理。但是,当我们更进一步,想要探究这些算法/模型背后的深度学习框架时,却发现系统性讲解的书籍、教程几乎没有。
最近阅读了 《机器学习系统:设计与实现》这本书,该书作为一本系统讲解机器学习框架的书,它能帮助开发者快速了解机器学习系统的全貌,并对深刻理解框架背后的技术细节有很好的指导。
全书分为3个部分:基础篇介绍了机器学习系统的基础;进阶篇从系统设计的角度,介绍在设计现代机器学习系统中需要考虑的问题和解决方案;拓展篇介绍了机器学习框架下的众多扩展应用。
为方便大家快速了解本书,我整理了 《机器学习系统:设计与实现》读书笔记,欢迎大家阅读&指正。
5、《Kubeflow学习指南:生产级机器学习系统实现》(Kubeflow for Machine Learning)


作者:【美】 特雷弗·格兰特,【加】 霍尔顿·卡劳,【俄】 鲍里斯·卢布林斯基,【美】 理查德·刘,【美】 伊兰·菲洛年科 著
译者:狄卫华
Kubeflow是基于K8S的机器学习工具包,是为数据科学家和数据工程师构建生产级别的机器学习实现而设计的。本书采用循序渐进的方式,从 Kubeflow 的安装、使用和设计开篇,随后从模型训练的整个周期展开,涵盖了数据探索、特征准备、模型训练/调优、模型服务、模型测试、模型监测和模型版本管理等各个环节,既有相关的理论知识也囊括了真实的使用案例,能够让读者在学习 Kubeflow 知识的同时全面了解机器学习的相关知识,是入门和深入学习Kubeflow以及机器学习的良好指南。
二、课程类
1、《实用机器学习》(Practical Machine Learning)
课程地址:
大家耳熟能详的李沐老师带来的又一门AI课程,介绍在模型训练与算法之外的实用机器学习技术,其能够用于各种真实项目中解决实际的工程技术问题。主要内容包括数据收集与处理、高效的模型训练、超参数调优、模型融合、迁移学习等技术。在B站有李沐老师亲自讲解的中文授课视频,老师账号为跟李沐学AI。
2、《Machine Learning in Production / AI Engineering》(CMU 17-445/17-645/17-745/11-695)
课程地址:
卡内基梅隆大学(CMU)的Christian Kästner教授带来的一门AI工程课程,在国内还比较少见这种系统化讲解AI工程技术应用的课程,从需求工程开始,讲解机器学习项目的设计、质量保证、开发过程与团队、负责任的AI等专题技术。该教授也有计划将这门课程写成一本书籍出版。
3、《Machine Learning Engineering for Production (MLOps) 专项课程》
课程地址:
吴恩达(Andrew Ng)老师带来的MLOps专项课程,讲解机器学习项目应用于生产环境的实际项目时,所遇到的种种挑战和技术实践,是Coursera上的热门课程之一。
三、论文类
1、《Teaching Software Engineering for AI-Enabled Systems》(面向AI使能系统的软件工程课程体系)
面对AI课程中很少有解决工程问题的课程现状,卡内基梅隆大学的Christian Kästner和Eunsuk Kang设计了一门新课程,向有ML背景的学生教授软件工程技术,在AI与软件工程结合的方向进行了探索,以论文的形式给大家分享了其教学实践。
为方便大家了解论文内容,我对论文进行了翻译及解读,欢迎大家阅读&指正,详见- 【AI工程论文解读】01-面向AI使能系统的软件工程课程体系。
2、《Hidden Technical Debt in Machine Learning Systems》(机器学习系统中的隐性技术债)
当前在构建机器学习系统时,开发者们更多关注于算法优化和技术创新,较少关注如何构建稳定的系统。谷歌的工程师们基于大量的机器学习系统构建和维护经验,在论文中列举了构建机器学习系统时,可能存在的Technical Debt(技术债)。
为方便大家了解论文内容,我对论文进行了翻译及解读,欢迎大家阅读&指正,详见 【AI工程论文解读】02-聊聊机器学习系统中的技术债。
最后,本人也在梳理AI工程方面的技术实践,大家有兴趣了,可以访问专栏 《AI工程与实践》,并加入我们,一起交流、学习AI技术。

作为数据科学的新手,你是否因为没有实践经验,在面试中屡屡被diss?如果是的话,你可以从《A Collection of Data Science Take-Home Challenges》“借”一个项目经验,让面试官对你刮目相看。
前言
有很多同学私信我,反映我发表的内容有点“硬核”,询问有没有适合算法新手的内容?或者数据科学的知识需要掌握到什么程度才能在互联网行业找到一份入门级别的算法工作?
对于第一点,我是同意的。我发表的关于推荐算法的很多内容,都需要读者有推荐、广告、搜索的实际工作经验,才能理解。否则,你未必能够意识到在小数据集下常规操作,却在“推广搜”海量数据、高维稀疏、在线持续更新的环境下根本不可能完成。意识不到问题的存在,无法对要解决的痛点感同身受,自然也就无法理解算法的精髓。
至于第二点,互联网算法工程师的入门级基本技能有哪些?倒让我想起了我在美国准备进入这个行业时所准备的TakeHome Challenge。
TakeHome Challenge是硅谷大厂考察数据科学人才的基本形式,一般用于一面。
- 筛选简历后,大厂会给候选人发一道考题。
- 题目包含一份数据,一般是该公司真实数据的脱敏版本。数据量不大,一般也就几万条,保证单机能够跑得通。
- 所问的问题,也来自该公司业务的真实场景。
- 要求候选人在规定时间内(不同公司有不同规定,一般1~3天),利用所提供的数据建立模型,回答所提问题,帮助公司改善产品。
- 提交作业的形式,要包含你的代码和你的分析过程。
- 也算是开卷考试,也不怕你请枪手,反正后面还有其他面试环节。
其实这种考察形式还挺重要的,可惜国内用得不多。和面试时让你白板写程序一样,考察的都是候选人的实际动手能力,毕竟talk is cheap, show me your codes。候选人提交的作业能够很大程度上反映他的解决数据问题的真实水平,包括:代码能力、建模能力、产品意识、沟通表达能力等。特别是针对校招生,因为没啥项目经验可聊(如果有的话,这样的校招生就太受欢迎了),如果只考察机器学习算法理论,很难保证招来的人能够干活(编程题考察的是写程序的水平,未必是解决算法实际项目的水平)。其实对于社招也应该适用,毕竟P7跳槽时要被要求白板编程也不算新闻了,再多做一个takehome challenge也不算太过分,毕竟考察的都是基本功,免得招来一个只知道写ppt和周报的“邵式兄弟”。
我亲身经历过Airbnb的takehome challenge,和下图的差不多。因为我对这种考察形式有所准备,也顺利通过了。不过后来就covid-19了,airbnb就开始裁员了,晕:-c。不过说回来了,虽然takehome challenge国内大厂用得不多,但是面试官要考察的点总是相通的,无非就是代码能力、数据处理能力、建模能力、评估能力、表达沟通能力等那几样。知道了考点,候选人可以在面试中主动体现自己在相关能力上的优势,比如“我做过一个项目,提取过几个有意思的特征,......”。我是非常欣赏这种候选人的,说明他是内行人,也是个聪明人。
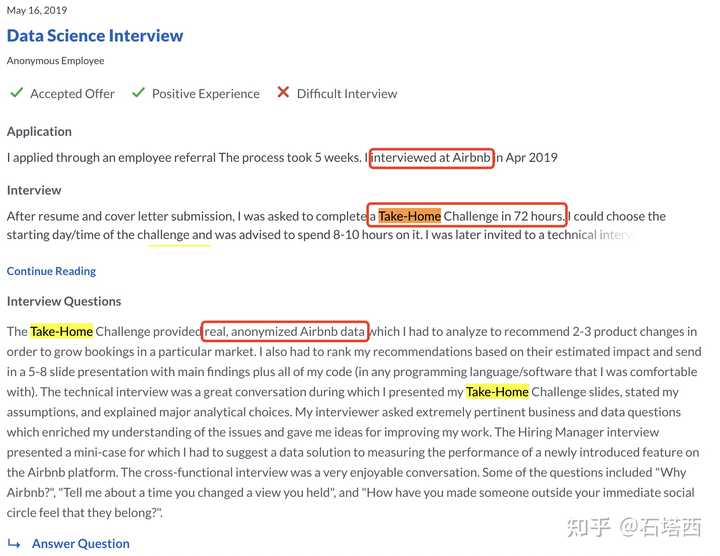

怎么准备TakeHome Challenge?
综上所述,准备takehome chanllenge对于数据科学的工作面试还是大有帮助的,特别是对项目经验不足的校招生。那该如何准备呢?
这里我推荐一本书《A Collection of Data Science Take-Home Challenges》。这本书是我当初跨行进入数据科学领域,准备第一场面试时的复习资料,当初也花了我大几十刀(这还只包括题目和数据集,不包括答案)。这本书出了20道题目,类似高考前的模拟卷,“黄冈真题”。


目前来看,这几十刀还是值得的。
- 一来,从以上内容可以看出,
- 这本书涵盖了多种类型的互联网业务,比如:电商、内容媒体、银行、在线旅游、......等。
- 另外也涵盖几乎所有的数据应用场景,比如:推荐、广告、搜索、风控、运营、数据分析、......等。
- 二来,所提的问题都来源于真实的业务场景,题目中的数据集也能够反映出真实的数据环境,从而帮你加深对某一具体业务的理解,使你在面试中看起来像是个“内行”。
如果你是一个想进入互联网行业从事数据工作的有志打工好青年,看了N本书,上了N门网课,感觉理论知识也学得差不多了,苦于没有项目实战经验,不妨从这本书中“借”一个项目经验。
- 比如,你想面银行或互联网金融的风控岗,仔细看看第10、12题。
- 如果你想面试携程或飞猪,好好看看题目13。
- 如果你想从事电商的数据分析,题目5的漏斗分析简直就是必修课。
- 如果你想进滴滴或高德从事地图业务,认真准备一下题目14。
把对口的“借来”的项目经历写入简历,能帮助你的简历在一大堆没有实战经验的竞争者中脱颖而出;到了面试环节,这份“借来”的项目经历也帮你提升了对面试岗位的业务、数据特点的理解,从而给面试官留下深刻的印象,觉得招来的不是小白,而是“来之能战”。
我把这本书、书中题目所使用的数据、我对各题目的解答,打包放到百度网盘上。想获取这份资源的同学,关注我的公众号“推荐道”,回复takehome,限时一个月,免费领取。
成功的TakeHome Challenge长什么样?
一份帮你求职成功的takehome chanllenge长什么样?面试官希望从中发现候选人的哪些素质?
代码风格
好的代码风格非常重要,在我看来,比多刷几道leetcode还重要,毕竟未来在实际工作中遇到leetcode hard-level的机率是不高的。而目前最现实的需求时,你提交的code是要被面试官review的。如果你写的程序他都看不懂,你的面试结果也就可想而知了。
其实保持一个好的代码风格并不难,能做到如下几点就算不错了:
- 给你的变量、函数、类起一个见名知意的好名字
- 代码模块化。不要一个功能几百行写到底,而是要拆分成函数或类。
- 恰当的注释,帮你的面试官理解你的代码。
另外,一般我们都是用Juypter Notebook来把代码、报告一起提交。你需要熟练掌握Markdown语法,并把你报告中的重要结论用加粗、高亮、放大字体、不同颜色等方式凸显出来,引起面试官的注意。
操作数据的能力
这必须是每个数据打工的人基础功。多表关联、排序、分组、聚合都是常见考点。
如果你使用Python,面试官希望看到,你是能够熟练使用NumPy/Pandas的,包括能提升效率的一些高级技巧。比如你能熟练调用Panads API完成批量操作,而不是自己写了一个for循环。
另外,面试官也希望你能够熟练调用matplotlib/seaborn/plotly等库将复杂的数据可视化。正所谓“一图胜千言”,清晰的图表、曲线反映了候选人的表达能力,特别是在面对非技术背景的合作伙伴的时候。
可惜,takehome chanllenge的数据量都比较小,无法反映候选人面对大数据的处理能力。但是也不排除假想一个Hive场景,让候选人写一个比较复杂的SQL出来。
特征预处理的基本功
我在之前的文章中曾经多次强调特征工程的重要性,正所谓Garbage in, Garbage out。所以特征处理能力,也是takehome chanllenge的关键考点。
第一条就是,不要一上来就把数据往模型里扔,那将是一个大大的减分项。正确的姿势是先做一些explorary data analysis,检查是否存在脏数据。现实场景中的数据没那么干净,你会见到各种奇形怪状的脏数据。对脏数据的警惕程度,能够反映出候选人的专业性。
第二,面试官希望能够看到你在构建特征时的创意。能够提取出好的特征,反映出候选人对这个业务的深入理解。
第三,就是考察候选人的特征处理技巧了。
- 对数值特征:离群点、缺失值、标准化、数据平滑、......
- 对类别特征:如何编码、过滤停用词、......。一般takehome challenge数据不多,用不上hashtrick。但是如果你提到了,比如“如果id类特征太多,可以考虑使用hashtrick”,反映出你对推广搜不陌生,面试官倒是应该高看你一眼。
建模基本功
考察候选人对常用的模型框架,比如xgboost/lightgbm/tensorflow/pytorch的熟练掌握程度。
虽然说,一般takehome challenge给候选人答题的时间是以天计,但是如果你真的花了3天时间,给几万条数据建个模型,说实在的,基本上这面试也就到此为止了,后面没啥机会了。我当初做Airbnb的takehome challenge,从拿到考题到交卷,也就半天的时间。
在有限的时间内完成建模,就要求候选人必须有一件称手的兵器(xgboost/lightgbm/tensorflow/pytorch,sklearn有点小儿科了),并且“招之即来,来之能战”。拿到考题,才想起google某个api的具体用法,就有点拉胯了。
评估模型的基本功
不能正确的评估模型,也就无法对模型做出改进。
划分train/validation/test三个数据集,是最基本的常识。如果你把全部数据都投入训练,并基于训练指标形成结论,那就趁早洗洗睡吧。
遇到label不均衡的数据集是常态,
- 用AUC评价也算是常识。如果新手候选人提到GAUC,我要是面试官,就再高看他一眼。
- 模型一般只能给出概率,而实际业务需要一个确定的结论,做出决策所依赖的threshold到底应该划在哪里?
- 现实场景中几乎看不到正负样本5/5开的数据集,基于threshold=0.5来做出结论的,也趁早洗洗睡吧。
- 采用不同的threshold,precision是多少?recall是多少?结合具体业务,我到底是应该“错杀三千”,还是考虑“放走一个”?
如果候选人除了给出在整个test集上的指标,还知道划分子集并给出每个子集上的指标(比如:新老用户上的不同指标、不同分类的商品上的指标),听我的,千万不要放过他。(说真的,能想到这一层的候选人,也用不着从我这里“借”项目经验。)
以上说的还都是离线评测,有的题目要求候选人设计线上AB实验方案。如何分桶(按人分桶,还是按流量分桶)、如何设计指标反映对业务的提升、......,都是常规考点。
分析并改进的能力
如前所述,一般takehome challenge给你1~3天的时间,但是你千万不要卡着3天的上限交卷。毕竟我们不是在打kaggle比赛,没必要为了auc千分位上的提升,又是建多模型boosting & stacking,又是grid search把整个超参空间搜个遍。
面试官从不期待候选人给出一个完美模型,因为这个东西本来就不存在。takehome challenge有两个考察目的:
- 首先,候选人能够在有限的时间里面(一般就半天),给出一个还不错的模型。这考察的是候选人对知识、技能、工具的熟练掌握程度。
- 然后,候选人能够分析初版模型的问题,并给出改进意见。因为完美模型虽然不存在,但是老板们鞭策我们追求完美的声音却始终萦绕在每个打工人的耳边。
面试官希望看到:
- 第一步分析出,初版模型到底是underfitting还是overfitting?(当然,如果候选人对overfitting有非常规的看法的话,嗯,肯定会有下次面试,咱俩好好唠唠。)然后,根据underfitting还是overfitting,针对性地提出具体改进方案。
- 比如:哪个超参数还需要继续调整?
- 比如:哪些特征还需要加强?怎么加强?
- 比如:是否需要收集更多的数据?怎么收集?
要达到以上目的,候选人需要有能力打开模型的黑盒,比如掌握基本的特征重要性分析方法。
产品意识
毕竟我们不是在实验室从事理论研究,我们希望看到候选人能够从数据中提炼出想法,改善产品,带来切实的收益。
- 比如:发现某个用户分群特征(e.g., 性别、年龄)的重要性非常强,模型在不同人群上的表现差异很大。候选人提出使用运营等手段,加强劣势人群对产品的认知。
- 比如:模型认为某个特征的重要性非常低,但是这与常理不符。这时,候选人提出是不是产品设计有问题,导致这个重要特征发挥不了作用。
另外,如果候选人能够将自己使用app的亲身体验与数据中表现的模式结合起来就更好了,说明招来的是一个热爱这款产品的“同道中人”。
举例说明
刚才讲了这么多,也算是我当过候选人,也当过面试官的切身感受。还是那句话,即使不采用takehome challenge的考察形式,以上内容也算是数据从业者的基本素质,是面试中的常见考点,也希望候选人能够主动展示。
我拿我求解“07.Marketing Email Campaign”这道题的过程,演示一下如何在takehome challenge中向面试官展示自己的能力。
先提前声明:我的solution也是好多年前做的了。当时我也是新手,对第二章强调的几个考点感受也不深,所以我的solution也并非面面俱到,就算是给大家“抛砖引玉”了。
先看题目,这道题的场景是一个邮件营销的场景,业务方关心的是有多少人打开了邮件,又有多少人点击了其中的广告链接。
- What percentage of users opened the email and what percentage clicked on the link within the email? (考察数据处理能力)
- The VP of marketing thinks that it is stupid to send emails to a random subset and in a random way. Based on all the information you have about the emails that were sent, can you build a model to optimize in future email campaigns to maximize the probability of users clicking on the link inside the email? (建模能力)
- By how much do you think your model would improve click through rate ( defined as # of users who click on the link / total users who received the email). How would you test that? (评估模型的能力)
- Did you find any interesting pattern on how the email campaign performed for different segments of users? Explain (分析改进能力,还有产品意识)
我的答案在我的github上,获取方式见本文最后。
帮助面试官理解
我用jupyter notebook撰写代码与报告。报告一上来,我就将我的解题过程列出来,帮助面试官理解我的解题思路。


分析结果多用图表展示。重要结论字体加粗、放大、用醒目颜色,引起面试官的注意。
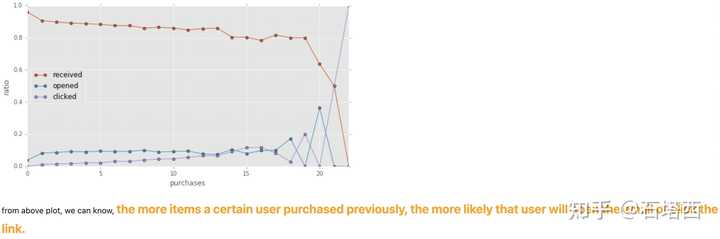

总之一句话,帮助面试官,就是帮助你自己。
改进模型


要让面试官知道,时间所限,这一版模型还凑合,但是我知道如何改进能让它更好。
产品意识
从数据中提取出能够改善产品的观点。


为了能够得出这些结论,我演示了如何从XGBoost获取特征重要性。
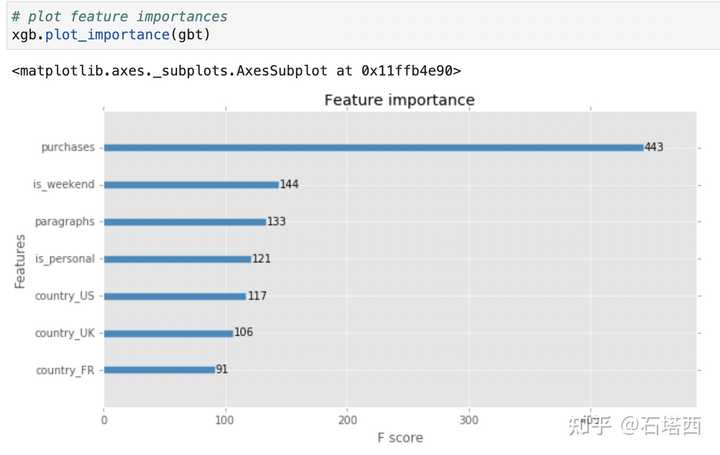

模型评估
给业务方讲AUC来评价你的模型是没有意义的,你必须将它翻译成“人话”。
首先,模型给出的是概率,但是业务方需要的是一个确切、可行动的结论。这里,我用TPR(true postive rate)和FPR(false positive rate)来量化我的不同决策的影响(点开概率超过多少,才发营销邮件)。




基于我的决策,我拿业务方关心的指标来证明模型的有效性,即节省了流量,有些潜在用户可能收不到邮件,但是广告打开率翻倍了,总之广告的效率更高了。


总结
本文介绍了takehome challenge这种硅谷常见的面试数据科学从业者的形式。借着takehome challenge这个话题,根据我做过候选人也当过面试官的亲身感受,我列举了数据科学面试中的常见考点,算是回答了“算法学到什么程度才能找到一份工作”、“怎么才能转行算法工程师”这类新手比较关心的问题。
准备takehome challenge对于已经掌握了数据科学的基本知识,但是苦于缺乏项目实战经验的新手是非常有帮助的。根据你要面试的行业、岗位,新手不妨从我提供的资源中“借”一个项目经验。把“借来”的、对口的项目经历写入简历,能帮助你的简历在一大堆没有实战经验的竞争者中脱颖而出;到了面试环节,这份“借来”的项目经历也帮你提升了对面试岗位的业务、数据特点的理解,从而给面试官留下“来之能战”的深刻印象。
还是那句话,虽然takehome challenge这种考察形式在国内大厂并不多见,但是考点总是相通的。熟练掌握后,候选人可以在面试中主动向面试官展现自己的相关能力。
本文也提供了准备takehome challenge的相关资源。花了我几十美刀的电子书、数据集,还有我对20道题目的答案,都放在百度网盘上,作为我回馈粉丝的福利。关注我的公众号“推荐道”,回复takehome,限时一个月,免费领取。
- END -


还在迷茫学习机器学习用什么书?来,这个回答一步到位!
机器学习是人工智能的一部分,它是为了帮助计算机能像人类一样思考,所研究出的计算机理论。
作为一门理论,机器学习是一门跨学科融合的产物,包含了统计学、概率论等学科。
你可以把它理解为【通过训练数据和算法模型让机器具有人工智能】的方法,这些方法,在程序里,我们称之为算法。
基于上面的描述,机器学习的书籍范围其实也就大体定了。
最近这段时间,借着 chatxx 的火爆,机器学习人工智能的风潮又刮起来了,最近来问我这方面问题的同学越来越多,我很开心看到这种变化,但是也发现很多同学并不知道学习这些内容有什么用,也不知道学了能用来干嘛,只是觉得最近火就想学。
鉴于这种情况,我推荐大家去看一下「知乎知学堂」联合「AGI课堂」推出的【程序员的AI大模型进阶之旅】公开课,一共2天的课程。像我上面说的 Chatxx 就是基于 AI 大模型中的 GPT 模型构建的应用程序,属于机器学习的范畴。这次公开课邀请的都是圈内的技术大佬解读最前沿的技术,了解这次 AI 技术跟以往的变革有什么不同,普通人如何在让自己成为这次变化的受益者,如何借助大模型提高收入的可能性。
希望大家都能好好了解一下,希望你的学习不只是跟风,而是真的从机器学习或者人工智能能够帮助到自己的学习和工作的角度去考虑。
机器学习想要系统学习的话,入门推荐看下面几本书:
《机器学习》
周志华老师的《机器学习》(西瓜书)作为机器学习领域的入门教材,可以说是学习机器学习的必读教材,在内容上基本涵盖了机器学习的很多方面,包括基础知识、经典的机器学习方法以及规则学习和强化学习这些进阶知识。


我当初在学的时候用的是这本书,后来周志华老师又出了一本《机器学习理论引导》,可以买来搭配着看。
《统计学习方法(第2版)》
纯理论的书,怎么说呢,想学机器学习,统计学习是迈不过去的坎~
李航老师这本书强推,全面介绍了统计学习的重要方法,用的都说好!


3. 《 机器学习实战》
这本书是我同学送我的,主要就是介绍机器学习基础,还有就是如何用算法进行分类,还有监督学习和无监督学习的经典算法,再就是机器学习算法里的一些附属工具。

通过一些实例,切入日常工作任务,没有很多学术化的语言,通过实例学习到机器学习的核心算法,算是一本实战经典书。
---
呃,说句题外话:
实战的话,除了上面这本书,其实我更多的还是建议大家直接上 scikitlearn 官网就好了,官网上的内容非常详细,不管是算法说明、参考文档或者对应的案例都应有尽有。
当然了,官网都是英文的,刚开始看还是会有些难度,但是怎么说呢,如果你想搞机器学习,我还是建议你能学会看英文的文档,这个对于我们的学习是很重要的!
---
至于机器学习的进阶,其实就是细化到具体的方向去学习了。
我在研究生的时候接触过深度学习,对深度学习还是比较熟悉的。
所谓“深度学习”,是机器学习领域新的研究方向。在语音和图像识别方面,深度学习的效果更好。机器想要蜕变成人工智能,“深度学习”是必经之路。
深度学习的话我必须要推荐这本神书《动手学深度学习》,豆瓣评分 9.4 分,面向中文读者的能运行、可讨论的深度学习教科书!


(1)每一小节都是可以运行的 Jupyter 记事本!
你可以自由修改代码和超参数来获取及时反馈,从而积累深度学习的实战经验。
(2)公式 + 图示 + 代码
不仅结合文字、公式和图示来阐明深度学习里常用的模型和算法,还提供代码来演示如何从零开始实现它们,并使用真实数据来提供一个交互式的学习体验。


这本书的作者之一, 李沐老师,亚马逊首席科学家(Principal Scientist),加州大学伯克利分校客座助理教授,美国卡内基梅隆大学计算机系博士。
这本书开源了,网上随便看,如果觉得看书不用非得看纸质书,直接看电子版的就可以了。
链接: 《动手学深度学习》:面向中文读者、能运行、可讨论
同时大家可以搭配着李沐老师的深度学习课来看书。


这门课从零开始教授深度学习,你只需要有基础的 Python 编程和数学基础就可以学,主要是包括多层感知机、卷积神经网络、循环神经网络、和 注意力机制四大类模型以及一些计算机视觉和自然语言处理的内容,知乎上直接就能看。
同时对于深度学习来说,看前沿论文是必不可少的。
我再给大家推荐一个深度学习的 Paper 指南的项目,全称“Deep Learning Papers Reading Roadmap”
非常适合学习深度学习,想要看论文但是又不知道该如何下手的小伙伴。
主要包括以下内容:
- 1 深度学习历史与基础
- 1.1 入门书籍
- 1.2 深度学习综述
- 1.3 深度信念网络
- 1.4 ImageNet 发展
- 1.5 语音识别发展
- 2 深度学习
- 2.1 模型
- 2.2 优化器
- 2.3 无监督学习
- 2.4 循环神经网络
- 2.5 神经图灵机
- 2.6 深度强化学习
- 2.7 深度迁移学习
- 2.8 小样本深度学习
- 3 应用
- 3.1 自然语言处理
- 3.2 目标检测
- 3.3 视觉跟踪
- 3.4 图像描述
- 3.5 机器翻译
- 3.6 机器人
- 3.7 艺术
- 3.8 目标分割

这不是知识的讲解,而是里程碑式的论文。
项目地址:https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap
希望对你有所帮助
推荐就先推荐这些,有什么问题大家可以评论区走起。
希望大家能够静下心来好好去学,而不是收藏了就是会了。
祝大家根据自己的需求,早日学会你想学的编程语言,早日修成大佬!
当然如果觉得我写的还不错,记得帮我 @Rocky0429 点个赞呀,让我看到你的支持。

机器学习好书重磅来袭!本书单含机器学习、深度学习、数学基础、神经网络及自然语言处理领域。
机器学习
1、《零基础学机器学习》
- 像漫画书一样有趣的机器学习入门书


一般通过“对话形式”展开的书都十分有趣,《零基础学机器学习》不仅读起来令人轻松愉悦,而且内容全面,实战性强。
本书主人公“小冰”是一只可可爱爱的90后程序媛,一天早上她被老板告知要从零开始跟着“咖哥”学机器学习,于是就这样走上了从零开始学机器学习的道路。


本书包括机器学习快速上手路径、数学和 Python 基础知识、机器学习基础算法(线性回归和逻辑回归)、深度神经网络、卷积神经网络、循环神经网络、经典算法、集成学习、无监督和半监督等非监督学习类型、强化学习实战等内容,并且所有案例均通过 Python 及 Scikit-learn 机器学习库和 Keras 深度学习框架实现,同时还包含丰富的数据分析和数据可视化内容。
机器学习入门必备“小白书”,与小冰一起参加机器学习课堂培训,通过丰富的实战案例学习理论与技术吧!
2、《Python机器学习基础教程》


机器学习已成为许多商业应用和研究项目不可或缺的一部分,海量数据使得机器学习的应用范围远超人们想象。本书将向所有对机器学习技术感兴趣的初学者展示,自己动手构建机器学习解决方案并非难事!
书中重点讨论机器学习算法的实践而不是背后的数学,全面涵盖在实践中实现机器学习算法的所有重要内容,帮助读者使用Python和scikit-learn库一步一步构建一个有效的机器学习应用。
3、《场景化机器学习》


AWS首席开发者布道师费良宏作序推荐;无须精通数学或编程,巧用机器学习成为业务小能手。在新一波数字化转型浪潮中,借助机器学习技术为业务创新赋能,这成了几乎所有公司可以甚至必须探索的方向。有了恰当的工具,无须高深的数学知识或专业的技术背景,你就能在日常业务中享受机器学习带来的便利。
本书凝聚了作者丰富的业务自动化经验,以虚拟人物为主线,展示了如何在客户留存、客户支持等业务场景中应用机器学习技术,从而让流程更快速、工作更高效、决策更明智。
4、《百面机器学习 算法工程师带你去面试》


本书收集了超过100道机器学习的题目,这些题目大部分在近年算法工程师的笔试、面试中出现过,作者试图从实际应用出发,给出详细的解答,打通从理论到应用的障碍。书中还讲述了很多算法背后的小故事,增加读者对问题的理解。
5、《机器学习的数学》


上海交通大学特别研究员、阿里巴巴、百度算法专家、优酷首席科学家、谷歌机器学习开发者专家力荐教材,SIGAI创始人全新力作,彻底解决机器学习的数学问题。
本书的目标是帮助读者全面、系统地学习机器学习所必须的数学知识。全书由8章组成,力求精准、最小地覆盖机器学习的数学知识。包括微积分,线性代数与矩阵论,最优化方法,概率论,信息论,随机过程,以及图论。
本书从机器学习的角度讲授这些数学知识,对它们在该领域的应用举例说明,使读者对某些抽象的数学知识和理论的实际应用有直观、具体的认识。
深度学习
1、《深度学习入门 基于Python的理论与实现》
- 日本深度学习入门经典畅销书


原版上市不足2年印刷已达100 000册。长期位列日亚“人工智能”类图书榜首,众多五星好评。
书中使用Python3,尽量不依赖外部库或工具,从基本的数学知识出发,带领读者从零创建一个经典的深度学习网络,使读者在此过程中逐步理解深度学习。
书中不仅介绍了深度学习和神经网络的概念、特征等基础知识,对误差反向传播法、卷积神经网络等也有深入讲解,此外还介绍了深度学习相关的实用技巧,自动驾驶、图像生成、强化学习等方面的应用,以及为什么加深层可以提高识别精度等疑难的问题。
2、《动手学深度学习》
- 亚马逊科学家作品,被全球超150所高校选为教程


目前市面上有关深度学习介绍的书籍大多可分两类,一类侧重方法介绍,另一类侧重实践和深度学习工具的介绍。本书同时覆盖方法和实践。本书不仅从数学的角度阐述深度学习的技术与应用,还包含可运行的代码,为读者展示如何在实际中解决问题。
为了给读者提供一种交互式的学习体验,本书不但提供免费的教学视频和讨论区,而且提供可运行的Jupyter记事本文件,充分利用Jupyter记事本能将文字、代码、公式和图像统一起来的优势。这样不仅直接将数学公式对应成实际代码,而且可以修改代码、观察结果并及时获取经验,从而带给读者全新的、交互式的深度学习的学习体验。
3、《深度学习》
- AI圣经!深度学习领域奠基性的经典畅销书


长期位居美国亚马逊AI和机器学习类图书榜首!所有数据科学家和机器学习从业者的必读图书!特斯拉CEO埃隆·马斯克等国内外众多专家推荐!
《深度学习》由全球知名的三位专家Ian Goodfellow、Yoshua Bengio 和Aaron Courville撰写,是深度学习领域奠基性的经典教材。
全书的内容包括3个部分:第1部分介绍基本的数学工具和机器学习的概念,它们是深度学习的预备知识;第2部分系统深入地讲解现今已成熟的深度学习方法和技术;第3部分讨论某些具有前瞻性的方向和想法,它们被公认为是深度学习未来的研究重点。
4、《Python深度学习》


《Python深度学习》由Keras之父、现任Google人工智能研究员的Franc.ois Chollet执笔,详尽展示了用Python、Keras、TensorFlow进行深度学习的探索实践,涉及计算机视觉、自然语言处理、生成式模型等应用。
在学习完本书后,读者将了解深度学习、机器学习和神经网络的关键概念,具备搭建自己的深度学习环境、建立图像识别模型、生成图像和文字等能力,学会解决现实世界中的深度学习问题。除此之外,本书还深刻剖析了当前的"人工智能热",从理性的视角展望了深度学习在未来的可能性。
5、《百面深度学习 算法工程师带你去面试》


深度学习是目前学术界和工业界都非常火热的话题,在许多行业有着成功应用。本书由Hulu的近30位算法研究员和算法工程师共同编写完成,专门针对深度学习领域,是《百面机器学习:算法工程师带你去面试》的延伸。
本书仍然采用知识点问答的形式来组织内容,每个问题都给出了难度级和相关知识点,以督促读者进行自我检查和主动思考。书中每个章节精心筛选了对应领域的不同方面、不同层次上的问题,相互搭配,展示深度学习的“百面”精彩,让不同读者都能找到合适的内容。
神经网络
1、《Python神经网络编程》


神经网络是一种模拟人脑的神经网络,以期能够实现类人工智能的机器学习技术。本书揭示神经网络背后的概念,并介绍如何通过Python实现神经网络。全书分为3章和两个附录。
- 第1章介绍了神经网络中所用到的数学思想。
- 第2章介绍使用Python实现神经网络,识别手写数字,并测试神经网络的性能。
- 第3章带领读者进一步了解简单的神经网络,观察已受训练的神经网络内部,尝试进一步改善神经网络的性能,并加深对相关知识的理解。
自然语言处理
1、《自然语言处理入门》


这是一本务实的入门书,助你零起点上手自然语言处理。HanLP 作者何晗汇集多年经验,从基本概念出发,逐步介绍中文分词、词性标注、命名实体识别、信 息抽取、文本聚类、文本分类、句法分析这几个热门问题的算法原理与工程实现。书中通过对多种算法的讲解,比较了它们的优缺点和适用场景,同时详细演示生产级成熟代码,助你真正将自然语言处理应用在生产环境中。随着本书的学习,你将从普通程序员晋级为机器学习工程师,最后进化到自然语言处理工程师。
2、《自然语言处理实战》


本书是介绍自然语言处理(NLP)和深度学习的实战书。NLP已成为深度学习的核心应用领域,而深度学习是NLP研究和应用中的必要工具。本书分为3部分:第一部分介绍NLP基础,包括分词、TF-IDF向量化以及从词频向量到语义向量的转换;第二部分讲述深度学习,包含神经网络、词向量、卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆(LSTM)网络、序列到序列建模和注意力机制等基本的深度学习模型和方法;第三部分介绍实战方面的内容,包括信息提取、问答系统、人机对话等真实世界系统的模型构建、性能挑战以及应对方法。
本书面向中高级Python开发人员,兼具基础理论与编程实战,是现代NLP领域从业者的实用参考书。
关联阅读
========
赠人玫瑰,手留余香,不要忘记点赞、收藏、关注 @人民邮电出版社 哦~
一键三连,感恩有你~



本书介绍
CS 189是加州大学伯克利分校的机器学习课程。本指南可以作为一个全面的课程指南,以便与学生和公众分享我们的知识,并希望吸引其他大学的学生对伯克利的机器学习课程感兴趣。
本书免费获取地址: ML必读基础书籍-《机器学习综述》免费分享
本书目录




内容截图






本书免费pdf下载地址: ML必读基础书籍-《机器学习综述》免费分享
往期精品内容推荐
21量化交易必读新书-《算法交易和强化学习》免费pdf分享
深度学习花书《Deep Learning》-中英文版分享-AI必读10本经典
机器学习经典书籍-《贝叶斯推理与机器学习》免费分享
文档理解相关领域、论文、数据集和工业应用资源分享
肖桐、朱靖波老师新著-《机器翻译统计建模与深度学习方法》中文版书籍分享
历史最全自然语言处理测评基准分享-数据集、基准(预训练)模型、语料库、排行榜
机器学习基础经典书籍分享-《计算机科学和机器学习相关代数、拓扑学、微分学和最优化理论》
自然语言处理圣经-《自然语言处理综述》-最新版及AI必读10本经典分享

学习资料千万不要求多,把一本啃透了就足够了,比如如果是我,我就推荐李航老师的统计学习。
在入门阶段,三个准则你要时刻记在心里:1. 不要自己用代码去实现各种机器学习算法,太浪费时间,直接学习sklearn。2.作为入门选手,不要试图把所有机器学习算法全部学一遍,学不过来,会绝望。3. 重点的机器学习算法,必须能够手推公式。
我拿统计机器学习这本书来说,这本书一共是分为了11章,你只需要去看其中的六章内容,分别是:1,2,4,5,6,8
我带大家看一下这本书目录:
第一章是统计学习概论;这章是在学习整个机器学习的一些基础概念,比如说什么是回归问题,什么是分类问题;什么是正则化,什么是交叉验证,什么是过拟合等等基础概念;必须掌握,没有商量的余地;
第二章是感知机,是最简单机器学习模型,也和后面的神经网络有关系,必须掌握
第三章是K近邻算法,这个你现在不需要看,跳过它;
第四章是朴素贝叶斯算法,这个非常重要,里面的概念比如说后验概率,极大似然估计之类的,必须掌握
第五章是决策树:这很简单,就是如何特征选择,两个决策树算法;也要掌握
第六章是逻辑回归和最大熵;要看
第七章支持向量机,我说一下我的观念哈,我认为这章不需要看;为什们呢?首先在我自己的工作中,几乎没用过支持向量机;而且现在,在今天,如果你在面试深度学习岗位的时候,有的面试官还在让你手推SVM公式的话,我认为这个面试官是不合格的,这个公司可能未必是你很好的一个选择;
第八章提升树,必看,这个提升树算法非常重要;
第九章第十章第十一章,都不需要看;对于隐马尔科夫和条件随机场,之后你如果想深入学NLP,再来看;对于EM算法,入门之后你碰到的时候再去看;
我刚才谈到,对于重点算法必须能够手推公式,哪几个重要呢?不多,逻辑回归,朴素贝叶斯,以及提升树里的xgboost算法;别的算法,你能够自己复述一遍讲出来,就够了;
在看的过程中,如果有不懂的怎么办?就是我刚才推荐一个刘建平老师的博客;
这个博客很好,有对应理论介绍,也有使用sklearn实现代码;
我刚才还谈到一个准则,是不要去从零造论文实现算法,因为sklearn可以很好的帮助你;
在这个过程中,你要去搞清楚这个算法输入数据,输出数据,每个参数的含义是什么;可以自己自己调一下参数,看看不同参数下最终效果有什么不同;但是在这里不要花费太大精力在调参上,因为你现在代码实现的是一个demo,数据量很小,调参没什么意义;什么调参呢?我一会会讲到;
整个机器学习理论部分,如果你真的认真去学习,三周时间,你肯定能搞定;你想啊,总共看6章,每章你看四天,这四天,你期中三天看理论部分,一天用代码跑一遍熟悉一下感觉;
其实代码这块要跑起来,很快,都不需要一天,两三个小时就可以;四天搞定一章,三周看完一点问题没有;
————————————————————
我根据自己的入门和工作经验,用八千字,总结了一份超详细的保姆级深度学习从零入门路线图,分享给大家;
整个思维导图的路线图分为六个部分:
- 基础知识;
- 机器学习理论入门;
- 机器学习竞赛实战;
- 深度学习理论入门;
- 深度学习竞赛实战;
- 深度学习面试题汇总;
整个路线图的思维导图如下,我把对应的视频和github链接全部放在了思维导图备注里面;
也可以搭配着视频观看:
获取思维导图的方式大家可以看这里:
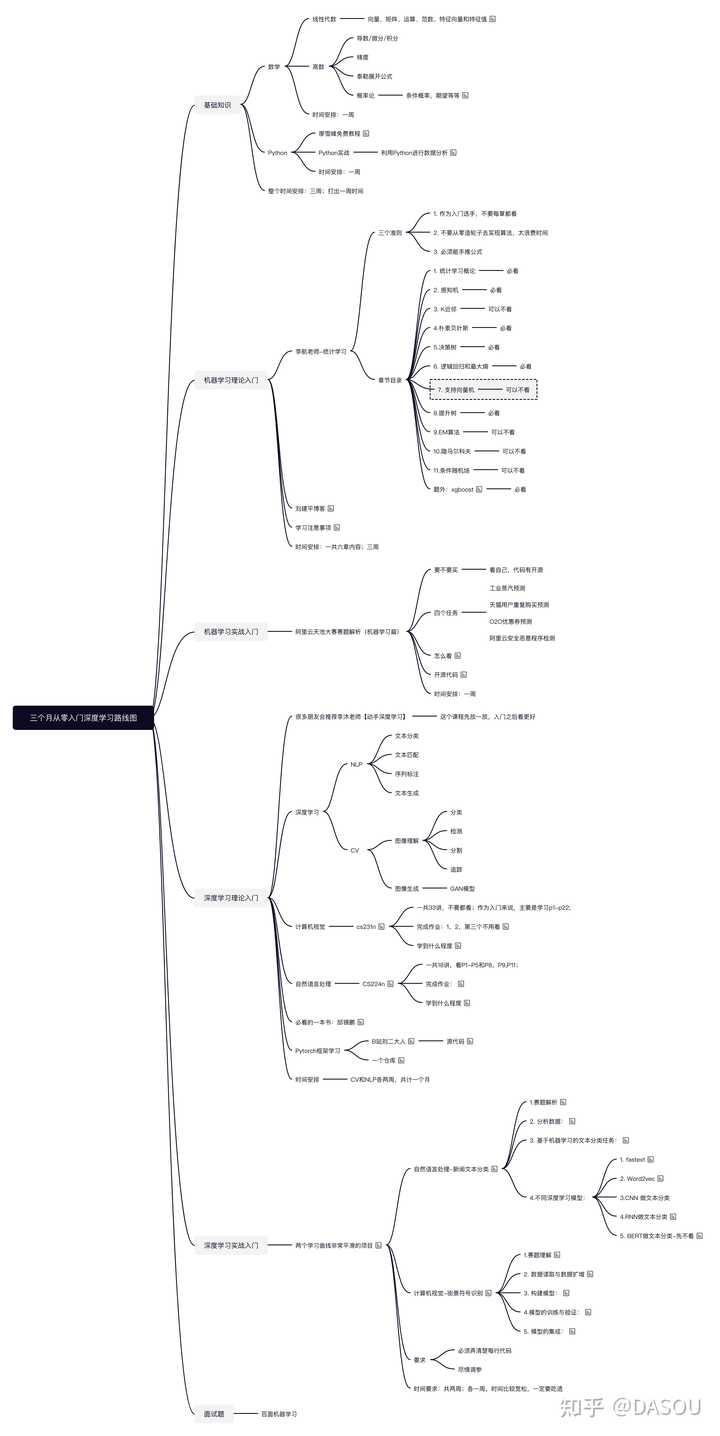

针对这六个部分,我们一个个的来看:
1.基础知识学习
首先,我们来看基础知识部分;
你需要掌握两个方面;第一个是数学,第二个是Python面向对象编程的基础;
首先对于数学来讲,我想很多搜索入门路线图的朋友,都会被推荐很多数学方面的大部头的书籍和视频和科目,比如说:微积分、线性代数、概率论、复变函数、数值计算等等;
我觉得如果当前的任务是入门,而不是做一些开创性的研究,这些并不全是没有必要;
从的建议来说,首先掌握线性代数里面的:向量、矩阵、运算、范数、特征向量和特征值;
我这里推荐一个中文视频,【两个小时快速复习线性代数】;链接看我思维导图思维导图的对应位置;
在复习的时候,不需要你完全记住,但是需要你用笔记画一个大致脉络图出来,把各个细节写上去,在以后需要用到的这个时候,像查字典一样能够查到就可以;
其次对于高数来说,需要掌握的主要就是4个:导数,梯度,泰勒公式,和概率论;概率论快速的过一遍就可以,了解一些基本概念,比如说条件概率,最大似然估计等等,我这里推荐一个视频,【1个小时快速复习概率论】;链接看我思维导图思维导图的对应位置;
有了这些数据基础,对于入门深度学习就够了;之后,如果遇到不懂的,在这个之外,我们再去学来得及;
第二个基础知识是Python;
Python是一种编程语言,是我们后面机器学习和深度学习中数据处理,实现模型的主力语言;
对于Python而言,不需要你很精通,只需要有一定的Python 面向对象编程的的基础就可以;
在这里,理论方面,我推荐廖雪峰的Python课程,这个课程没有必要都看,地址在思维导图备注
这个视频里面的目录,并不是都去学习,我们只需要从第一个简介开始,学习到常用的第三方模块;之后,有了一定的Python基础,就可以不用学习了;
之后需要提升的你的实战能力,我给你大家推荐一本书,学起来也很快,叫做【用Python做数据分析】;
这本书的中文翻译版链接在这里:见思维导图备注
这本书,不用全都看,看重点章节就可以;当然全看了,也很快,因为这本书本身学习起来就很简单;
我为什么推荐这本书呢?首先第一点,这本书确实看起来很简单,入门门槛极低,第二,这本书的内容,在我们往后的机器学习和深度学习关系很密切,因为我们在构建模型之前,需要很多操作去处理数据,用到这本书介绍的这两个api包;
看完廖雪峰的教程和这本书,你会掌握两个东西,一个python基础知识,一个是究竟怎么用Python实战去处理数据;
2.机器学习理论入门
第二个部分,我来重点介绍机器学习理论入门路线图;
对于机器学习理论算法,我推荐一本书籍和一个博客和一个Python包
书籍是:李航的统计学习,主要,不是全都看,我一会会告诉你看哪几个章节;
博客是刘建平老师的博客,Python包是sklearn;
我们先来看这个统计学习,我谈三个准则:
三个准则是:
第一,作为入门选手,不要每章都去看;
第二,不要用python从零去造轮子去实现这本书里面的算法,千万不要这样做,太浪费时间;
第三个,对于重点章节算法必须能做到手推公式,重点算法其实不多,一会说;
这本书一共是分为了11章,你只需要去看其中的六章内容,分别是:1,2,4,5,6,8
我带大家看一下这本书目录:
第一章是统计学习概论;这章是在学习整个机器学习的一些基础概念,比如说什么是回归问题,什么是分类问题;什么是正则化,什么是交叉验证,什么是过拟合等等基础概念;必须掌握,没有商量的余地;
第二章是感知机,是最简单机器学习模型,也和后面的神经网络有关系,必须掌握
第三章是K近邻算法,这个你现在不需要看,跳过它;
第四章是朴素贝叶斯算法,这个非常重要,里面的概念比如说后验概率,极大似然估计之类的,必须掌握
第五章是决策树:这很简单,就是如何特征选择,两个决策树算法;也要掌握
第六章是逻辑回归和最大熵;要看
第七章支持向量机,我说一下我的观念哈,我认为这章不需要看;为什们呢?首先在我自己的工作中,几乎没用过支持向量机;而且现在,在今天,如果你在面试深度学习岗位的时候,有的面试官还在让你手推SVM公式的话,我认为这个面试官是不合格的,这个公司可能未必是你很好的一个选择;
第八章提升树,必看,这个提升树算法非常重要;
第九章第十章第十一章,都不需要看;对于隐马尔科夫和条件随机场,之后你如果想深入学NLP,再来看;对于EM算法,入门之后你碰到的时候再去看;
我刚才谈到,对于重点算法必须能够手推公式,哪几个重要呢?不多,逻辑回归,朴素贝叶斯,以及提升树里的xgboost算法;别的算法,你能够自己复述一遍讲出来,就够了;
在看的过程中,如果有不懂的怎么办?就是我刚才推荐一个刘建平老师的博客;
在这里:见思维导图备注
这个博客很好,有对应理论介绍,也有使用sklearn实现代码;
我刚才还谈到一个准则,是不要去从零造论文实现算法,因为sklearn可以很好的帮助你;
在这个过程中,你要去搞清楚这个算法输入数据,输出数据,每个参数的含义是什么;可以自己自己调一下参数,看看不同参数下最终效果有什么不同;但是在这里不要花费太大精力在调参上,因为你现在代码实现的是一个demo,数据量很小,调参没什么意义;什么调参呢?我一会会讲到;
整个机器学习理论部分,如果你真的认真去学习,三周时间,你肯定能搞定;你想啊,总共看6章,每章你看四天,这四天,你期中三天看理论部分,一天用代码跑一遍熟悉一下感觉;
其实代码这块要跑起来,很快,都不需要一天,两三个小时就可以;四天搞定一章,三周看完一点问题没有;
3.机器学习竞赛实战
然后重点来了,理论部分看完了,也用sklearn做简单的代码实践了,接下来做什么呢?要把这些算法用到实践中去;
也就是我要谈的机器学习竞赛代码实战:在这里,我只推荐一本书,叫做:
阿里云天池大赛赛题解析——机器学习篇;
记住啊,是机器学习篇,不是深度学习篇;
我先说这本书要不要买:首先我自己是买了这本书,但是我发现书很厚,但是有大量的代码占据了很大篇幅;后来发现代码在天池上已经开源了,所以买完之后有一点点后悔;不过就全当为知识付费了;
拿你们要不要买呢?我觉得没啥必要,反正代码是开源的,一会我告诉链接;不过要想支持一下书的作者的话,可以买一本支持一下;就不要下次一定了;
天池是一个竞赛平台,这本书里面它包含了四个实战型的任务:
工业蒸汽预测
天猫用户重复购买预测
O2O优惠券预测
阿里云安全恶意程序检测
我来告诉大家怎么看这本书:
有四个任务是吧,你挑其中的一个或者两个,不需要都看,没必要;
怎么确定把这一个或者两个任务吃透呢?
七个步骤:赛题理解、数据探索、特征工程、模型训练、模型验证、特征优化、模型融合7个步骤
开源代码的链接我放在了思维导图的备注;
就像我说的,四个任务中挑一个或者两个,在一周,七天,三天看一个,七天看两个,或者七天你就看一个,比如第一个,把它吃透就够了;
看完之后,你会对之前学习的统计学习书籍里面机器学习算法有一个非常清楚的认识;
所以整个机器学习的理论和代码时间,花费时间为1个月;
4.深度学习理论学习
我把深度学习的入门仿照机器学习,也分为两个部分,先学理论,再实战打比赛;
其实说心里话,深度学习入门比机器学习入门要简单的多;
在网上很多朋友在推荐深度学习入门路线的时候,会谈到李沐老师【动手深度学习】;我自己也在跟着学习这个课程,我也学到了很多;
但是讲心里话,如果是带入一个初学者的角度去看这门课程,可能会有听不懂的情况;所以这门课程可以先放一放,我给大家推荐两个视频和一本书;
我们都知道深度这块主要就是分为NLP和CV;
NLP任务上大概可以分为四种:文本分类 文本匹配 序列标注 文本生成,
CV任务大致也可以分为图像理解和生成:理解这块大致可以分为:分类、检测、分割、追踪; 生成这块基本就是GAN模型
对于入门来说,我们不用学这么多,我们只需要学籍基础的神经网络,然后通过文本分类和图片分类任务去熟悉掌握整个徐娜林和预测流程,比如数据处理,模型搭建等呢吧;
所以我推荐的这两门课程也是很出名的:
就是大家常说的cs231n 和CS224n;
我来告诉大家怎么看这两个视频,同样不是全部都看;
- 推荐的视频cs231n;
B站视频链接见思维导图;
整个视频在B站是分为了33讲,作为入门来说,主要是学习p1-p22;
也就是从第一讲课程介绍-计算机视觉概述到循环神经网络;
我们来打开看一眼:
然后这个视频不是让你一直看,看完一部分之后,去完成对应作业;
它的作业有三个,我把实现代码链接放在这里:见思维导图备注
你去做前两个,实现图像分类任务,实现卷积神经网络:bn,dropout,cnn 都要看一下;
第三个作业比较复杂,大家不用去看,只需要做前两个;
注意,不需要自己从零去做这个作业,直接看给的代码仓库,去看人家怎么实现的,当然你如果有自信而且想要锻炼自己,没问题,可以从零去实现。但是对于大部分人,你去对照着代码一行行的看,去理解为什么这儿写,输出输入是什么;
在这个过程,就会涉及到一点,就是框架的学习,我推荐大家使用Pytorch;
框架框架学习,我这里我后面会讲到,我先在这里插一句,就是大家可以去看B站刘二大人,地址在这里:见思维导图备注
它这个pytorch学习曲线比较平滑,大家在在看计算机视觉视频之后,完成代码的部分,如果有不懂的地方,穿插着去看这个刘二大人的视频;
因为刘二大人这个视频会涉及到CNN和RNN,所以如果你一开始就看,可能会有点费劲;
我举个例子吧,比如说你看完CNN网络,然后你去完成第二个作业,突然你发现里面有些不懂,不知道为什么这么弄,然后你去看刘二大人对应的视频讲CNN代码的;是这么个顺序啊;
整个计算机市局视频和代码学习完之后,你必须要掌握到什么程度呢?
必须要把下面这些完全掌握:
反向传播梯度回传,损失函数,优化算法,多层感知机,卷积神经网络,普通的循环神经网络,以及一些dropout和BN掌握住;
2. 自然语言处理:
推荐一个视频,非常经典的 CS224n:
链接:见思维导图备注
这个课程不是需要都看,要有选择的看:
在B站的官方主页,它包含了18讲的内容;在入门阶段,你只需要看P1-P5和P8,P9,P11;
通过看这个视频你要能够达到什么地步呢?
其实这个视频和cs231n在基础部分是重叠的,对于基础部分,大家可以都看,两者兼学会更好
必须熟悉的掌握:反向传播,词向量,RNN,GRU,Lstm,Seq2Seq以及attention机制;初步了解卷积神经网络;
有作业,一定要认真做,自己写不出来,仿照着别人的写:见思维导图备注
作业也不是都写:重点看a1,a2,a4,a5;其实a5这个不做的话,也没问题,把前面给的这个三个一定自己走一遍;
作业涉及到词向量和机器翻译;
有的朋友常常会和我反应,不知道att这种细节是如何实现的,其实这些都是最基础的东西,一定要从零看代码,有余力的话,可以自己实现一遍,非常有帮助;
在学习这两个视频的过程中,视频是英文的,而且涉及到的一些经典概念,不太容易理解,那么必须要看这本书:
邱锡鹏
代码的学习过程中,不用去过度的关注调参之类的,而是关注代码是怎么写的;因为调参这块tricks后面我会有专门的部分提升;
3.Pytorch框架学习
pytorch框架的学习:其实这个pytorch学习应该是融合在上面这个计算机视觉学习中的;可以在看完视频只有,写作业之前,先刷一遍这个Pytorch教学视频;
B站的刘二大人:《PyTorch深度学习实践》完结合集 https://www.bilibili.com/video/BV1Y7411d7Ys?from=search&seid=1631997590037031874&spm_id_from=333.337.0.0
但是它好像没有源代码,评论区有小伙伴手敲了代码,地址在这: https://blog.csdn.net/bit452/category_10569531.html
5.深度学习竞赛实战:
重点来了,上面谈到的这些深度学习的东西,都是在给你打基础;
但是要记住,我们学习深度学习是为了实战:我给大家准备了两个学习曲线非常平滑的实战项目;
一个是新闻分类项目,一个是街景字符识别,也就是图片分类项目,有的人可能会认为这两个项目非常简单,但是我认为千万不要小瞧这两个项目,扎扎实实做完这两个项目,对你的帮助绝对比你想象的要大;
先说NLP的新闻文本分类任务;地址在这里:见思维导图备注
就像我所说的,这个任务是一个NLP中一个基础任务-文本分类任务;这也是绝大部分从业的业务型NLP工程师日常工作最常见的工作需求;所以掌握好这个任务非常关键;
那么怎么掌握呢?在天池上,有开源的赛题解析,我挑选几个我认为很好的notebook给到大家;
task1:赛题理解:
jupyter notebook 链接,见思维导图备注
就是仿照你工作的时候,运营人员怎么给你提的需求,你听完需求要去分析它是什么问题,是个分类问题,回归问题,NLP问题,CV问题,多模态问题?
task2:分析数据:去看字符分布,最大长度,链接思维导图备注
task3:基于机器学习的文本分类任务:先做一个baseline出来,不是先搞大模型复杂东西出来;
链接见思维导图备注
task4:不同深度学习模型:
fastext:它是一种词向量,也是一种文本分类模型:对应的论文链接在这里:对应的我的博客解读,在这里,链接见思维导图备注
w2C:在视频有介绍对应的论文链接对应的我的博客解读在这里
textcnn:也就是用CNN模型来做,链接见思维导图备注
textrnn:使用RNN做,链接见思维导图备注
之前深度学习视频学了,CNN,RNN等基础网络,这里你就去实战这些模型;
bert;这个可以先不看,等你入了深度学习的门,认为自己想搞NLP这个方向了,你再去看相关的论文;我把链接放在这里吧: https://tianchi.aliyun.com/notebook-ai/detail?spm=5176.12586969.1002.24.6406111aE3Lglg&postId=118259
第二个任务是CV任务:图片分类任务: 街景字符编码识别
链接:见思维导图备注
task1 赛题理解
链接见思维导图备注
task数据读取与数据扩增
链接见思维导图备注
task3构建
链接思维导图备注
task4模型的训练,链接思维导图备注
task4模型的集成:
链接见思维导图备注
做完这个任务,你会对在CV领域,如果加载自己的图片数据集,如何构建CV模型,增强数据,模型验证都有一个很清晰的了解;
在这两个任务实施的时候,大家可以尽情的调参,尝试各种各样的tricks提升自己的成绩;
整个深度学习
面试题:
百面机器学习;视频最后面我会提供给大家 这本书非常好,真的非常好;

安利一套口碑上佳的中文深度学习书,名叫《神经网络与深度学习》,复旦大学老师邱锡鹏出品。
它面向深度学习小白,从人工智能的基本概念开始讲起,可以说很友好了。
此外,各种附加资料一站式配齐:从教材、讲解PPT、示例代码到课后练习,全方位无死角学习。

书里都有啥?
这本书目前已经更新完,共有16章,从机器学习概论开始,涵盖多种基础神经网络模型的基础知识。
课程目录如下:
- 绪论
- 机器学习概述
- 线性模型
- 前馈神经网络
- 卷积神经网络
- 循环神经网络
- 网络优化与正则化
- 注意力机制与外部记忆
- 无监督学习
- 模型独立的学习方式
- 概率图模型
- 深度信念网络
- 深度生成模型
- 深度强化学习
- 序列生成模型
- 数学基础
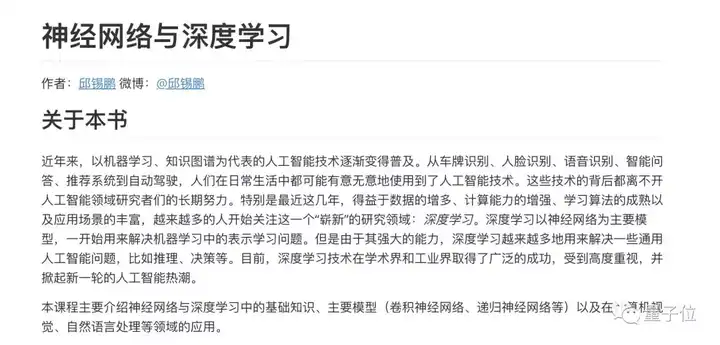
判断是一门课好不好学,图多是一个重要的因素,一是能帮助理解,二是还能减轻心理负担。邱老师的这套课,就是图很丰富的那种。
比如在书中一开始《如何开发一个人工智能系统》章节,有这样的结构图分清神经网络、机器学习与概率图模型的关系:
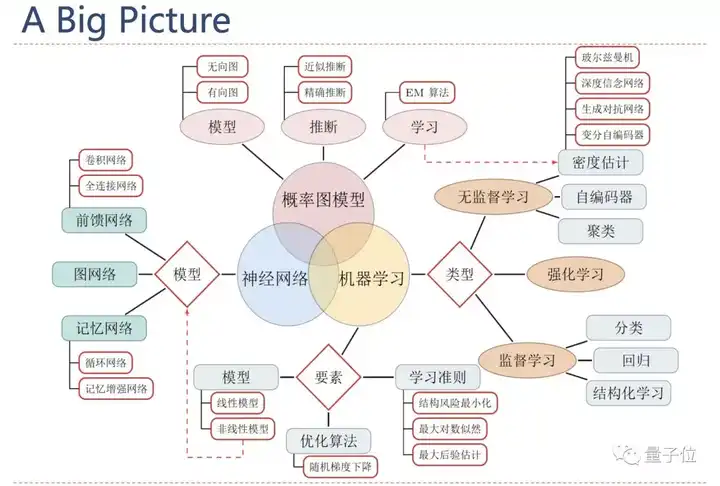

还有这样的对比图讲解“过拟合”的知识点:

还有一些已经整理好的对比图表,将这套教程作为工具书使用也是极好的:


是不是比书本上的长篇大论好理解多了。
数学小白必入
可以看出,这套书还是以普及深度学习相关概念为主,如果高数基础不好,还可以借助第16章节数学基础的38页PDF,将所需的理论知识一次性补全。
在这一部分,邱老师介绍了一些深度学习涉及到的基础数学知识,包括线性代数、微积分、数值优化、概率论和信息论等。
介绍方式简洁明了,针对深度学习任务进行了筛选。比如在线性代数这一小节,邱老师主要介绍了向量的概念:


以及必须要学的矩阵基础知识:


再也不用为划重点发愁,因为邱老师早已经整理好了~
理解神经网络所用的数学知识,有这么几页就能看懂大部分了。
作者其人
这本书的作者邱锡鹏老师,目前是复旦大学计算机科学技术学院的博士生导师、自然语言处理与深度学习组的副教授。


从本科读书、博士研究再到毕业后工作,邱老师都是在复旦大学工作,《神经网络与深度学习》也是邱老师带的研究生要学的课程。
目前,邱老师主要研究统计机器学习、自然语言处理以及对话系统/自动问答系统,此前还开源过一个全新的自然语言处理工具FastNLP:
https://github.com/FudanNLP/fnlp
传送门
GitHub地址:
https://nndl.github.io/
PDF讲义:
https://nndl.github.io/nndl-book.pdf
3小时课程概要PDF:
https://nndl.github.io/ppt/%E7%A5%9E%E7%BB%8F%E7%BD%91%E7%BB%9C%E4%B8%8E%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0-3%E5%B0%8F%E6%97%B6.pdf
示例代码:
https://github.com/nndl/nndl-codes
课后练习:
https://github.com/nndl/exercise
抱走这套资源吧。

彷徨疑惑,机器学习该看什么书?云栖社区&异步社区机器学习好书籍推荐
机器学习作为近期人工智能领域的热点话题一直被广大知乎讨论,小编也一直收到很多私信咨询有哪些好的书籍适合自己进行阅读学习。本周: 阿里云云栖社区机构号 联合机器学习专业出版社: 异步社区,为大家带来十本经典机器学习相关书籍,分别适合入门、进阶到精深的三个不同阶段同学阅读,并且每本书籍都由 异步社区机器学习相关编辑同学标注了适合阅读人群(文末有彩蛋不看后悔哦):
(异步社区,是人民邮电出版社旗下IT专业图书旗舰社区,也是国内领先的IT专业图书社区,致力于优质学习内容的出版和分享,实现了纸书电子书的同步上架,于2015年8月上线运营。)
Python高性能编程Python高性能编程-图书 - 异步社区本书适合初级和中级Python程序员、有一定Python语言基础想要得到进阶和提高的读者阅读。 本书共有12章,围绕如何进行代码优化和加快实际应用的运行速度进行详细讲解。本书主要包含以下主题:计算机内部结构的背景知识、列表和元组、字典和集合、迭代器和生成器、矩阵和矢量计算、并发、集群和工作队列等。最后,通过一系列真实案例展现了在应用场景中需要注意的问题。
NLTK基础教程——用NLTK和Python库构建机器学习应用
NLTK基础教程--用NLTK和Python库构建机器学习应用-图书 - 异步社区 本书适合 NLP 和机器学习领域的爱好者、对文本处理感兴趣的读者、想要快速学习NLTK的资深Python程序员以及机器学习领域的研究人员阅读。 NLTK 库是当前自然语言处理(NLP)领域最为流行、使用最为广泛的库之一, 同时Python语言也已逐渐成为主流的编程语言之一。本书主要介绍如何通过NLTK库与一些Python库的结合从而实现复杂的NLP任务和机器学习应用。全书共分为10章。第1章对NLP进行了简单介绍。第2章、第3章和第4章主要介绍一些通用的预处理技术、专属于NLP领域的预处理技术以及命名实体识别技术等。第5章之后的内容侧重于介绍如何构建一些NLP应用,涉及文本分类、数据科学和数据处理、社交媒体挖掘和大规模文本挖掘等方面。
机器学习与数据科学(基于R的统计学习方法)
机器学习与数据科学(基于R的统计学习方法)-图书 - 异步社区 本书适合数据科学家、数据分析师、软件开发者以及需要了解数据科学和机器学习方法的科研人员阅读参考。 本书试图指导读者掌握如何完成涉及机器学习的数据科学项目。本书将为数据科学家提供一些在统计学习领域会用到的工具和技巧,涉及数据连接、数据处理、探索性数据分析、监督机器学习、非监督机器学习和模型评估。本书选用的是R统计环境,书中所有代码示例都是用R语言编写的,涉及众多流行的R包和数据集。
实用机器学习
实用机器学习-图书 - 异步社区 本书适合需要应用机器学习算法解决实际问题的工程技术人员阅读,也可作为相关专业高年级本科生或研究生的入门教材或课外读物 大数据时代为机器学习的应用提供了广阔的空间,各行各业涉及数据分析的工作都需要使用机器学习算法。本书围绕实际数据分析的流程展开,着重介绍数据探索、数据预处理和常用的机器学习算法模型。本书从解决实际问题的角度出发,介绍回归算法、分类算法、推荐算法、排序算法和集成学习算法。在介绍每种机器学习算法模型时,书中不但阐述基本原理,而且讨论模型的评价与选择。为方便读者学习各种算法,本书介绍了R语言中相应的软件包并给出了示例程序。本书的最大特色就是贴近工程实践。首先,本书仅侧重介绍当前工业界最常用的机器学习算法,而不追求知识内容的覆盖面;其次,本书在介绍每类机器学习算法时,力求通俗易懂地阐述算法思想,而不追求理论的深度,让读者借助代码获得直观的体验。
Python机器学习实践指南
Python机器学习实践指南-图书 - 异步社区 本书适合Python 程序员、数据分析人员、对算法感兴趣的读者、机器学习领域的从业人员及科研人员阅读。 机器学习是近年来渐趋热门的一个领域,同时Python 语言经过一段时间的发展也已逐渐成为主流的编程语言之一。本书结合了机器学习和Python 语言两个热门的领域,通过利用两种核心的机器学习算法来将Python 语言在数据分析方面的优势发挥到极致。全书共有10 章。第1 章讲解了Python 机器学习的生态系统,剩余9 章介绍了众多与机器学习相关的算法,包括各类分类算法、数据可视化技术、推荐引擎等,主要包括机器学习在公寓、机票、IPO 市场、新闻源、内容推广、股票市场、图像、聊天机器人和推荐引擎等方面的应用。
贝叶斯方法:概率编程与贝叶斯推断
贝叶斯方法:概率编程与贝叶斯推断-图书 - 异步社区 本书适用于机器学习、贝叶斯推断、概率编程等相关领域的从业者和爱好者,也适合普通开发人员了解贝叶斯统计而使用。 本书基于PyMC语言以及一系列常用的Python数据分析框架,如NumPy、SciPy和Matplotlib,通过概率编程的方式,讲解了贝叶斯推断的原理和实现方法。该方法常常可以在避免引入大量数学分析的前提下,有效地解决问题。书中使用的案例往往是工作中遇到的实际问题,有趣并且实用。作者的阐述也尽量避免冗长的数学分析,而让读者可以动手解决一个个的具体问题。通过对本书的学习,读者可以对贝叶斯思维、概率编程有较为深入的了解,为将来从事机器学习、数据分析相关的工作打下基础。
TensorFlow技术解析与实战
TensorFlow技术解析与实战-图书 - 异步社区 本书深入浅出,理论联系实际,实战案例新颖,基于最新的TensorFlow 1.1版本,涵盖TensorFlow的新特性,非常适合对深度学习和TensorFlow感兴趣的读者阅读。 TensorFlow 是谷歌公司开发的深度学习框架,也是目前深度学习的主流框架之一。本书从深度学习的基础讲起,深入TensorFlow框架原理、模型构建、源代码分析和网络实现等各个方面。全书分为基础篇、实战篇和提高篇三部分。基础篇讲解人工智能的入门知识,深度学习的方法,TensorFlow的基础原理、系统架构、设计理念、编程模型、常用API、批标准化、模型的存储与加载、队列与线程,实现一个自定义操作,并进行TensorFlow源代码解析,介绍卷积神经网络(CNN)和循环神经网络(RNN)的演化发展及其TensorFlow实现、TensorFlow的高级框架等知识;实战篇讲解如何用TensorFlow写一个神经网络程序并介绍TensorFlow实现各种网络(CNN、RNN和自编码网络等),并对MINIST数据集进行训练,讲解TensorFlow在人脸识别、自然语言处理、图像和语音的结合、生成式对抗网络等方面的应用;提高篇讲解TensorFlow的分布式原理、架构、模式、API,还会介绍TensorFlow XLA、TensorFlow Debugger、TensorFlow和Kubernetes结合、TensorFlowOnSpark、TensorFlow移动端应用,以及TensorFlow Serving、TensorFlow Fold和TensorFlow计算加速等其他特性。最后,附录中列出一些可供参考的公开数据集,并结合作者的项目经验介绍项目管理的一些建议。
概率编程实战
概率编程实战-图书 - 异步社区 本书既可以作为概率编程的入门读物,也可以帮助已经有一定基础的读者熟悉Figaro这一概率编程利器。 ★ 人工智能领域的先驱、美国加州大学伯克利分校教授Stuart Russell作序推荐!一本不可思议的Scala概率编程实战书籍!概率推理是不确定性条件下做出决策的重要方法,在许多领域都已经得到了广泛的应用。概率编程充分结合了概率推理模型和现代计算机编程语言,使这一方法的实施更加简便,现已在许多领域(包括炙手可热的机器学习)中崭露头角,各种概率编程系统也如雨后春笋般出现。本书的作者Avi Pfeffer正是主流概率编程系统Figaro的首席开发者,他以详尽的实例、清晰易懂的解说引领读者进入这一过去令人望而生畏的领域。通读本书,可以发现概率编程并非“疯狂科学家”们的专利,无需艰深的数学知识,就可以构思出解决许多实际问题的概率模型,进而利用现代概率编程系统的强大功能解题。
Python机器学习——预测分析核心算法
Python机器学习--预测分析核心算法-图书 - 异步社区 本书主要针对想提高机器学习技能的Python 开发人员,帮助他们解决某一特定的项目或是提升相关的技能。 在学习和研究机器学习的时候,面临令人眼花缭乱的算法,机器学习新手往往会不知所措。本书从算法和Python 语言实现的角度,帮助读者认识机器学习。 书专注于两类核心的“算法族”,即惩罚线性回归和集成方法,并通过代码实例来展示所讨论的算法的使用原则。全书共分为7 章,详细讨论了预测模型的两类核心算法、预测模型的构建、惩罚线性回归和集成方法的具体应用和实现。
机器学习项目开发实战
机器学习项目开发实战-图书 - 异步社区 本书适合对机器学习感兴趣的.NET开发人员阅读,也适合其他读者作为机器学习的入门参考书。 本书通过一系列有趣的实例,由浅入深地介绍了机器学习这一炙手可热的新领域,并且详细介绍了适合机器学习开发的Microsoft F#语言和函数式编程,引领读者深入了解机器学习的基本概念、核心思想和常用算法。书中的例子既通俗易懂,同时又十分实用,可以作为许多开发问题的起点。通过对本书的阅读,读者无须接触枯燥的数学知识,便可快速上手,为日后的开发工作打下坚实的基础。
这里是彩蛋:
本次人民邮电出版社的同学也特意拿出10本书作为福利赠送给社区小伙伴们。
拿书规则:
1、关注阿里云云栖社区;
2、点击到原文: 彷徨疑惑,机器学习该看什么书?云栖社区&异步社区机器学习好书籍推荐 - 知乎专栏,评论回复以上10本中你最想看的一本书籍名称。请不要在本回答中回复
我们将在6月20日,从关注社区且在评论中回复了想阅读书籍名称的用户中,抽取10名幸运小伙伴免费赠送以上正版书籍一本哦。

我们组里的Seminar:
机器学习入门:西瓜书
CV入门:CS231N(完成作业)
机器学习进阶:Foundations of Machine Learning
坚持带同学们开seminar将近三年了,尽量在学习之余给大家补充些算法本质的理解和当下的趋势。去年开始,前两个终于不用我操心了!
今年带大家看FML效果出奇得还不错,两个大四的学弟基本花了一年跟下来三个讨论班,基础都打得很不错了。后面他们就可以开始好好锻炼工程能力开心炼丹啦!
看书还是个长期的事情,不要拘泥于一本两本,学个五遍六遍,也能有新的理解啦

入门书:
1、《机器学习图解》


Manning家的图解系列,可以说是入门书的首选。特别对于数学基础相对薄弱的读者来说,更是非常友好。本书使用Python构建有趣的项目,不谈深奥的术语,只通过基本代数知识(高中数学)提供清晰的解释,就能理解和应用强大的机器学习技术。摘录书中一段就可以得见:
“在大多数机器学习书籍中,算法以公式、导数等数学形式呈现。尽管在实践中对方法进行精确描述的效果良好,但公式本身可能比其说明的问题更令人困惑。然而,就像乐谱一样,复杂公式背后可能隐藏着一段优美的旋律。例如,让我们看看这个公式 \sum_{i=1}^{4}{i} 。这个公式乍一看很难懂,但其实它代表的是一个非常简单的总和,即1+2+3+4。那么, \sum_{i=1}^{n}{w_{i}} 呢?这代表n个数字的总和。但当想到多个数字的总和时,我宁愿想象3+2+4+27,而不是 \sum_{i=1}^{n}{w_{i}} 。”
2、《细说机器学习从理论到实践》


这是一本超级详细的机器学习入门书,还是一本边学边练的动手书。每个知识点配合大量练习,全书设计200多个编程实例,展示机器学习算法与框架的实际应用。从统计学、线性代数与概率论等机器学习的基础知识谈起,逐步介绍机器学习的基本概念,常用算法与编程实现,以及高级知识、框架实践与项目案例,兼顾理论与应用,详尽易懂。书中涵盖了机器学习中常用的模块和流行框架包括NumPy、Pandas、Matplotlib.Scikit-Learn、TensorFlow和PyTorch等,特别注重介绍基于深度学习的TensorFlow和PyTorch框架的概念、原理以及实际应用;还详细介绍了机器学习中的特征工程、模型评估、降维方法等必备基础知识,并针对K-Means聚类算法、K最近邻算法、回归算法、朴素贝叶斯算法、决策树与随机森林算法、支持向量机、神经网络、集成学习、卷积网络以及激活函数等进行了深入阐述,涵盖了当前机器学习的热点内容。
3、《Python机器学习实战》


本书作者在前言中写到:“通过这本书,我们做了一次非常谦卑的尝试,为绝对零基础的初学者写一本以机器学习为主题的分步骤指南。本书的每一章都包含对概念的解释、代码示例、对代码示例的解释以及代码输出截图。”
本书分为三个部分。第一部分介绍使用 Python 的数字运算和数据分析工具,并深入解释环境配置、数据加载、数值处理、数据分析和可视化。第二部分涵盖机器学习基础知识和 Scikit-learn 库。它还通过理论和实践课程以简单的方式解释了监督学习、无监督学习、回归算法的实现和分类以及集成学习方法。第三部分解释了复杂的神经网络架构,并详细介绍了卷积神经网络的内部工作和实现。最后一章包含 Pytorch 中神经网络的详细端到端解决方案。本书可以帮助读者实现机器学习和神经网络解决方案。
4、《艾博士:深入浅出人工智能》


由清华大学计算机系长聘教授,中国人工智能学会副监事长马少平教授编著,以博学的艾博士和好学的小明师徒二人对话的方式,一步步由浅入深地讲解人工智能的基本原理和方法,就像线下课堂一样亲切真实。
这本书不局限于机器学习,是针对初学者介绍人工智能基础知识的书籍。本书采用通俗易懂的语言讲了解人工智能的基本概念、发展历程和主要方法。内容涵盖人工智能的核心方法 ,包括什么是人工智能、神经网络 ( 深度学习 ) 是如何实现的、计算机是如何学会下棋的、计算机是如何找到最优路径的、如何用随机算法求解组合优化 问题、统计机器学习方法是如何实现分类与聚类的、专家系统是如何实现的等每种方法都配有例题并给出详细的求解过程 ,以帮助读者理解和掌握算法实质 ,提高读者解决实际问题的能力。
进阶书:
1、《机器学习中的统计思维》(Python实现)


作为一名统计学博士,作者曾以李航博士的《统计学习方法》为蓝本,在视频平台上分享统计学知识收获众多拥趸。如今董平博士将自己的所学所得凝练成册,以统计思维的视角,揭示监督学习中回归和分类模型的核心思想,帮助读者构建理论体系。具体模型包括线性回归模型、K近邻模型、贝叶斯推断、逻辑回归模型、决策树模型、感知机模型、支持向量机、EM算法和提升方法。
为满足不同年龄和不同专业读者的需求,作者为大家贴心地准备了主体书与小册子。主体书以机器学习模型为主,每一章都清晰透彻地解析了模型原理,书中的每一页都设计了留白,方便读者批注;小册子用于查阅碎片化的知识点,便于读者随时复习需要的数学概念。书中不仅有机器学习的理论知识,还有故事和案例,希望各位读者在阅读本书的过程中能够感受到机器学习中统计思维的魅力,获得科学思维方法的启迪并具有独立的创新思辨能力。
2、《机器学习系统设计和实现》


填补空白之作:衔接机器学习与计算机系统
本书由麦络,爱丁堡大学信息学院助理教授,博士生导师和董豪,北京大学计算机学院助理教授,博士生导师合著,图书在github上开源,同时收到了来自学界和产业界的各位优秀教授、研究者、和从业者的诸多写作建议。全书分成基础篇、进阶篇和拓展篇3个部分。
基础篇覆盖机器学习框架使用者所需要了解的核心系统知识和相关编程案例;进阶篇覆盖了机器学习框架开发着所需要理解的核心知识和相关实践案例;拓展篇详细讨论了多种类的机器学习系统,从而为广大机器学习从业者提供解密底层系统所需的基础知识。
图书开源地址:
提升篇:
1、《机器学习方法》


李航博士《统计学习方法》的升级版,2012年《统计学习方法 (第 1版)》出版,内容涵盖监督学习的主要方法, 2019年第 2版出版,增加了无监督学习的主要方法,都属于传统机器学习。《机器学习方法》在《统计学习方法》的基础上增加了深度学习的内容,全面系统地介绍了机器学习的主要方法,系统阐述其理论、模型、策略和算法,从具体例子入手,由浅入深,帮助读者直观地理解基本思路,同时从理论角度出发,给出严格的数学推导,严谨详实,让读者更好地掌握基本原理和概念。
《机器学习方法》全面系统地介绍了机器学习的主要方法,共分三篇。第一篇介绍监督学习的主要方法,包括感知机、k近邻法、朴素贝叶斯法、决策树、逻辑斯谛回归与z大熵模型、支持向量机、Boosting、EM算法、隐马尔可夫模型、条件随机场等;第二篇介绍无监督学习的主要方法,包括聚类、奇异值分解、主成分分析、潜在语义分析、概率潜在语义分析、马尔可夫链蒙特卡罗法、潜在狄利克雷分配、PageRank算法等。第三篇介绍深度学习的主要方法,包括前馈神经网络、卷积神经网络、循环神经网络、序列到序列模型、预训练语言模型、生成对抗网络等。
本书的机器学习算法清晰简练,公式推导详细又简洁,全书用逻辑和公式说话,没有啰嗦冗余,妥妥是一本“干货书”,让人又爱又恨呀~
2、《统计学习要素》


三位统计学家高屋建瓴之作,复旦张军平教授亲译。这是一本面向非统计专业的读者介绍重要的统计学概念的书,非纯数学理论,借助于一个通用概念框架,描述多个学科的重要思想,比如医学、生物学、金融学和营销。
全书共18 章,主题包括监督学习、回归的线性方法、分类的线性方法、基展开和正则化、核光滑方法、模型评估和选择、模型推断和平均、加性模型、树和相关方法、Boosting 和加性树、神经网络、支持向量机和柔性判断、原型方法和最近邻、非监督学习、随机森林、集成学习、无向图模型和高维问题等。本书将机器学习技术在统计和数值优化的意义上重新阐释,让读者理解本质和内在联系,掌握这类问题的基本思路,为希望在科研道路上发展的读者打下了坚实的基础。
传播先进文化、推动社会进步,蒙您欢喜,不要忘记点赞、分享、关注 @清华大学出版社 IT专栏
哦~


机器学习是计算机科学与人工智能的重要分支领域。周志华老师的《机器学习》这本书作为该领域的入门教材,在内容上涵盖机器学习基础知识的很多方面。全书共 16 章,大致分为 3 个部分:第 1 部分(第 1~3 章)介绍机器学习的基础知识;第 2 部分(第 4~10 章)讨论一些经典而常用的机器学习方法(决策树、神经网络、支持向量机、贝叶斯分类器、集成学习、聚类、降维与度量学习);第 3 部分(第 11~16 章)为进阶知识,内容涉及特征选择与稀疏学习、计算学习理论、半监督学习、概率图模型、规则学习以及强化学习等。
《统计学习方法(第二版)》全面系统地介绍了统计学习的主要方法,共分两篇。第一篇系统介绍监督学习的各种重要方法,包括决策树、感知机、支持向量机、很大熵模型与逻辑斯谛回归、推进法、多类分类法、EM算法、隐马尔科夫模型和条件随机场等;第二篇介绍无监督学习,包括聚类、奇异值、主成分分析、潜在语义分析等。
在学机器学习或者深度学习的时候,实战一直是一个重要的环节。《机器学习实战:基于Scikit-Learn和TensorFlow》本书作者 Aurélien Géron 曾经是谷歌工程师,在 2013 年至 2016 年,主导了YouTube的视频分类工程,拥有丰富的机器学习项目经验。作者的写作初衷是希望从实践出发,手把手地帮助开发者从零开始搭建起一个神经网络。这也正构成了本书区别于其他机器学习教程的最重要的特质—不再偏向于原理研究的角度,而是从开发者的实践角度出发,在动手写代码的过程中,循序渐进地了解机器学习的理论知识和工具的实践技巧。对于想要快速上手机器学习的开发者来说,本书是一个非常值得尝试的起点项目。
《机器学习实战》主要介绍机器学习基础,以及如何利用算法进行分类,并逐步介绍了多种经典的监督学习算法,如k近邻算法、朴素贝叶斯算法、Logistic 回归算法、支持向量机、AdaBoost 集成方法、基于树的回归算法和分类回归树(CART)算法等。第三部分则重点介绍无监督学习及其一些主要算法:k均值聚类算法、Apriori 算法、FP-Growth 算法。第四部分介绍了机器学习算法的一些附属工具。本书通过精心编排的实例,切入日常工作任务,摒弃学术化语言,利用高效的可复用Python代码来阐释如何处理统计数据,进行数据分析及可视化。通过各种实例,读者可从中学会机器学习的核心算法,并能将其运用于一些策略性任务中,如分类、预测、推荐。另外,还可用它们来实现一些更高级的功能,如汇总和简化等。
《深度学习》这本书的作者是 Ian Goodfellow、Yoshua Bengio 和 Aaron Courville 三位大牛。这本书的中文版于 2017 年 7 月 22 号上市。该书由众多译者协力完成。《深度学习》这本书从浅入深介绍了基础数学知识、机器学习经验以及现阶段深度学习的理论和发展,不管是人工智能技术爱好者,还是相关从业人员使用这本书都是非常有好处的。另外,读者如果想熟悉一些数学知识,本书也做了一些介绍,包括矩阵,导数等基本内容。读者可以从头读到尾。
《深度学习》这本书的一大特点是介绍深度学习算法的本质,脱离具体代码实现给出算法背后的逻辑,不写代码的人也完全可以看。为了方便读者阅读,作者特别绘制了本书的内容组织结构图,指出了全书20章内容之间的相关关系。读者可以根据自己的背景或需要,随意挑选阅读。
除此之外,还有一本书《动手学深度学习》。本书旨在向读者交付有关深度学习的交互式学习体验。书中不仅阐述深度学习的算法原理,还演示它们的实现和运行。与传统图书不同,本书的每一节都是一个可以下载并运行的 Jupyter 记事本,它将文字、公式、图像、代码和运行结果结合在了一起。此外,读者还可以访问并参与书中内容的讨论。
全书的内容分为 3 个部分:第一部分介绍深度学习的背景,提供预备知识,并包括深度学习基础的概念和技术;第二部分描述深度学习计算的重要组成部分,还解释近年来令深度学习在多个领域大获成功的卷积神经网络和循环神经网络;第三部分评价优化算法,检验影响深度学习计算性能的重要因素,并分别列举深度学习在计算机视觉和自然语言处理中的重要应用。
本书同时覆盖深度学习的方法和实践,主要面向在校大学生、技术人员和研究人员。阅读本书需要读者了解基本的Python编程或附录中描述的线性代数、微分和概率基础。
如果觉得数学知识不太够,可以看这一本《深度学习的数学》。本书基于丰富的图示和具体示例,通俗易懂地介绍了深度学习相关的数学知识。第1章介绍神经网络的概况;第 2 章介绍理解神经网络所需的数学基础知识;第 3 章介绍神经网络的优化;第 4 章介绍神经网络和误差反向传播法;第 5 章介绍深度学习和卷积神经网络。书中使用 Excel 进行理论验证,帮助读者直观地体验深度学习的原理。
如果想复习一些数学课程,可以读一些数学方面的基础课,例如微积分,线性代数,概率论等课程。程序员直接阅读数学书可能会比较枯燥,但是有人贴心地针对程序员撰写了相应的数学书籍。
《程序员的数学 第2版》面向程序员介绍了编程中常用的数学知识,借以培养初级程序员的数学思维。读者无须精通编程,也无须精通数学,只要具备四则运算和乘方等基础知识,即可阅读本书。本书讲解了二进制计数法、逻辑、余数、排列组合、递归、指数爆炸、不可解问题等许多与编程密切相关的数学方法,分析了哥尼斯堡七桥问题、高斯求和、汉诺塔、斐波那契数列等经典问题和算法。引导读者深入理解编程中的数学方法和思路。
《程序员的数学2:概率统计》涉及随机变量、贝叶斯公式、离散值和连续值的概率分布、协方差矩阵、多元正态分布、估计与检验理论、伪随机数以及概率论的各类应用,适合程序设计人员与数学爱好者阅读,也可作为高中或大学非数学专业学生的概率论入门读物。
《程序员的数学3:线性代数》本书用通俗的语言和具象的图表深入讲解了编程中所需的线性代数知识。内容包括向量、矩阵、行列式、秩、逆矩阵、线性方程、LU分解、特征值、对角化、Jordan标准型、特征值算法等。
通常来说,学习机器学习的时候,精读一本书即可,其他书用于辅助和查缺补漏,然后就可以根据科研的方向和导师的要求来阅读论文和搞科研了。如果想要学习数学系的一些课程的话,可以先阅读一些工科方面的数学书,有时间的话再选择一些数学的专业书籍进行阅读。

机器学习入门书:
动手学机器学习


本书每一章都由一个Python Notebook 组成, Notebook 中包括机器学习相关概念定义、理 论分析、算法过程和可运行代码。读者可以根据自己的需求自行选择感兴趣的部分阅读。例如, 只想学习各个算法的整体思想而不关注具体实现细节的读者,可以只阅读除代码以外的文字部 分;已经了解算法原理,只想要动手进行代码实践的读者,可以只关注代码的具体实现部分。
本书面向的读者主要是对机器学习感兴趣的高校学生(不论是本科生还是研究生)、教师、 企业研究员及工程师。在阅读本书之前,读者需要掌握一些基本的数学概念和数理统计基础知 识(如矩阵运算、概率分布和数值分析方法等)。
本书包含4个部分。第一部分为机器学习基础,主要讲解机器学习的基本概念以及两个最 基础的机器学习算法,即KNN 和线性回归,并基于这两个算法讨论机器学习的基本思想和实 验原则。这一部分涵盖了机器学习最基础、最主要的原理和实践内容,完成此部分学习后就能 在大部分机器学习实践场景中上手解决问题。第二部分为参数化模型,主要讨论监督学习任务 的参数化模型,包括线性模型、双线性模型和神经网络。这类方法主要基于数据的损失函数对 模型参数求梯度,进而更新模型,在代码实现方面具有共通性。第三部分为非参数化模型,主 要关注监督学习的非参数化模型,包括支持向量机、树模型和梯度提升树等。把非参数化模型 单独作为一个部分来讨论,能更好地帮助读者从原理和代码方面体会参数化模型和非参数化模型之间的区别和优劣。第四部分为无监督模型,涉及聚类、 PCA 降维、概率图模型、 EM 算法 和自编码器,旨在从不同任务、不同技术的角度讨论无监督学习,让读者体会无监督学习和监 督学习之间的区别。本书的4个部分皆为机器学习的主干知识,希望系统掌握机器学习基本知 识的读者都应该学习这些内容。
本书为机器学习的入门读物,也可以作为高校机器学习课程教学中的教材或者辅助材料。本书提供的代码都是基于Python3编写的,读者需要具有一定的Python编程基础。
机器学习的数学


本书的目标是帮助读者全面、系统地学习机器学习所必须的数学知识。全书由8章组成,力求精准、最小地覆盖机器学习的数学知识。包括微积分,线性代数与矩阵论,**化方法,概率论,信息论,随机过程,以及图论。本书从机器学习的角度讲授这些数学知识,对它们在该领域的应用举例说明,使读者对某些抽象的数学知识和理论的实际应用有直观、具体的认识。 本书内容紧凑,结构清晰,深入浅出,讲解详细。可用作计算机、人工智能、电子工程、自动化、数学等相关专业的教材与教学参考书。对人工智能领域的工程技术人员与产品研发人员,本书也有很强的参考价值。对于广大数学与应用的数学爱好者,本书亦为适合自学的读本。
机器学习精讲


本书用简短的篇幅、精炼的语言,讲授机器学习领域必备的知识和技能。全书共11章和一个术语表,依次介绍了机器学习的基本概念、符号和定义、算法、基本实践方法、神经网络和深度学习、问题与解决方案、进阶操作、非监督学习以及其他学习方式等,涵盖了监督学习和非监督学习、支持向量机、神经网络、集成学习、梯度下降、聚类分析、维度降低、自编码器、迁移学习、强化学习、特征工程、超参数调试等众多核心概念和方法。全书最后给出了一个较为详尽的术语表。
本书能够帮助读者了解机器学习是如何工作的,为进一步理解该领域的复杂问题和进行深入研究打好基础。本书适合想要学习和掌握机器学习的软件从业人员、想要运用机器学习技术的数据科学家阅读,也适合想要了解机器学习的一般读者参考。
机器学习进阶书


机器学习入门教程,机器学习精讲姊妹篇,侧重于机器学习应用贺工程实践,探讨多种实际应用场景,深挖AI技术实战,谷歌科学主管作序推荐。
本书是人工智能和机器学习领域专业多年实践的结晶,深入浅出讲解机器学习应用和工程实践,是对机器学习工程实践和设计模式的系统回顾。全书分别从项目前的准备,数据收集和准备,特征工程,监督模型训练,模型评估,模型服务、监测和维护等方面讲解,由浅入深剖析机器学习实践过程中遇到的问题,帮助读者快速掌握机器学习工程实践和设计模式的基本原理与方法。
本书内容安排合理,架构清晰,理论与实践相结合,适合想要从事机器学习项目的数据分析师、机器学习工程师以及机器学习相关专业的学生阅读,也可供需要处理模型的软件架构师参考。

先说入门阶段,推荐两本经典的毒物《机器学习》、《统计学习方法》
《机器学习》的作者为南京大学计算机系主任、人工智能学院院长周志华,简单介绍了机器学习的基础知识、各种流派的学习算法,通读本书可对机器学习的原理、内容、功能、流派,应用有一个整体的认识
注意,这是一本“教科书”,书本身没有很厚,看起来不至于压力很大。毕竟是“教科书”,每一章只有短短的几十页,结合课程用来教学是不错,但自学只看这本书估计有点不太够,可以结合coursera上Andrew Ng和林轩田的课来使用。


《统计学习方法》同样也是中文机器学习教材中的经典之一,文中介绍了很多算法模型和统计方法,比如朴素贝叶斯法、决策树、逻辑斯谛回归与熵模型等
除第1章概论和最后一章总结外,每章介绍一种方法,适用于高等院校文本数据挖掘、信息检索及自然语言处理等专业的大学生、研究生,也可供从事计算机应用相关专业的研发人员参考


进阶阶段
这个阶段同样也推荐两本——《机器学习实战》、《深度学习-AI圣经》
《机器学习施展》的作者是google前工程师Aurélien Géron,他在google时主导Youtube的视频分类工程,在机器学习方面具有丰富的实践经验,这些经验在该书中得到了很好的体现
本书看下来最大的特点就是以成熟可运行的机器学习库为基础,描述如何使用各种机器学习算法在数据上进行训练、优化,得到可用模型,然后介绍算法背后的理论基础,这样可以使读者先有算法感性认识,再到理性认识,能更好理解掌握机器学习方法。比起有些只讲理论、数学公式一大堆的书籍,本书要易读很多


《深度学习》由全球知名的三位专家IanGoodfellow、YoshuaBengio和AaronCourville撰写,是深度学习领域奠基性的经典教材。
全书的内容包括3个部分:第1部分介绍基本的数学工具和机器学习的概念,它们是深度学习的预备知识;第2部分系统深入地讲解现今已成熟的深度学习方法和技术;第3部分讨论某些具有前瞻性的方向和想法,它们被公认为是深度学习未来的研究重点。


实战阶段
上面推荐的四本书都是基于理论知识的,在这一阶段推荐一门结合实战的教科书——《Tensorflow实战google深度学习框架》
TensorFlow是谷歌2015年开源的主流深度学习框架,掌握深度学习需要较强的理论功底,用好TensorFlow又需要足够的实践和解析。这本书里以TensorFlow为实战学习,拥有非常丰富的库,省略了烦琐的数学模型推导,从实际应用问题出发,通过具体的TensorFlow示例介绍如何使用深度学习解决实际问题,是走进这个前沿、热门的人工智能领域的优选参考书。


最后分享一些相关资料:

现在无论是计算机专业还是其他的实体行业(机械、制造等等)对于人工智能的需求都还是蛮大的。所以现在也有很多人想入门人工智能,或者转行人工智能。其实人工智能是一个很大的方向,现在提到的人工智能基本上都默认以深度学习为主导的方法,但其实人工智能和深度学习的关系是:深度学习是机器学习的一个子集,机器学习是人工智能的一个子集。
那么现在深度学习这么火,答主就简单的出深度学习的角度来回答一下这个问题。
其实对于深度学习这个日新月异,每年爆发式更新模型的方向来说,学习路线的最尽头肯定是阅读你这个方向最新的论文,无论是科研人员还是已经走上工作岗位打算转行的打工人。阅读论文的来源一般是各种顶会(CVPR、ECCV、ICCV)、顶刊(TPAMI)。如果你嫌麻烦可以直接去谷歌学术或者 arXiv 上搜索你关注的内容,在搜索的时候最好把时间设定在最近几年。
说完学习路线的尽头,我们来看看入门的一些要求。对于入门深学习而言,你是必须掌握 Python 这门语言的,主要的原因是很多模型开源的代码都是基于 Python 实现的,而且目前针对深度学习的两个主流框架 pytorch 和 TensorFlow 都是支持 Python 开发的,也就是说深度学习的生态很大一部分是依赖 Python 的。所以说学习和掌握 Python 是入门深度学习必须的步骤,如果你不会也不用担心,入门 Python 还是非常简单的,目前知乎推出了一个基于 Python 的数据开发课程,如果你感兴趣的话可以购买学习一下,现在也不是很贵才一毛钱,以后可能就不好说了,所以直接买就完事了,也算是薅羊毛了。
好当你掌握了 Python,那么下一步就是去学习一些基础的数学知识了,因为如果一点数学知识都不知道的话后面论文中的公式你可能都看不懂,更不用提推导复现模型了。但你也没必要害怕,主要的就是基本的线性代数知识,也就是本科大一下学期学的,以及一些高等数学中的微积分知识。因为深度学习说的通俗一点就是大量的线代中矩阵运算和微积分中偏微分用于梯度下降。


当你掌握 Python 编程和基本的线代知识以及微积分以后,你现在就可以去看看最基本的深度学习网络模型了。虽然说现在深度学习日新月异,但是目前的很多新模型都是基于这些基础模型上进一步创新和跨领域应用的。这些基本的模型不仅能带你理解深度学习,也能帮你打下坚实的基础,这对于你后面去理解新模型和创新是非常重要的
下面就从计算机视觉(二维图片处理、三维点云数据处理)、自然语言处理列举几个最基本的模型。
深度学习网络基础知识:正向传播、梯度下降、反向传播、常见的几个 LOSS 函数(损失函数)
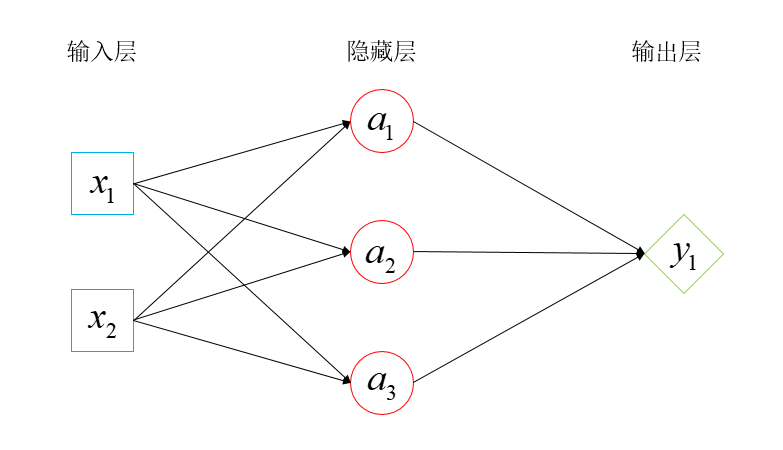
开山鼻祖:FCN 网络(全连接神经网络)
计算机视觉(2D 图片任务):
1.CNN(这个就不过多介绍了,已经是如雷贯耳了)
2.FCN(膨胀卷积,是分割任务中祖师爷般的存在)
3.RCNN 系列(目标检测任务霸主,现在很多下游任务还是会把 faster rcnn 当做骨干网络)
计算机视觉(3D 视觉点云或者体素任务):
1.PointNet/PointNet++(在三维视觉中基于点数据流派的开山之作)
2.VoteNet(何凯明在三维目标检测的力作)
自然语言处理方向:
- RNN(这个模型年纪虽然可能比你都大(1982 年)但这并不影响他在 NLP 领域的影响力)
- LSTM(1997 年,是对 RNN 的一个改进版本)
- transform(这个不多说,现在真的是 transform 及其子孙模型大行其道的时代,光在自然语言领域卷还不够,现在都跑到计算机视觉领域来卷了)
当你读完上面论文,你就可以去专门的看你自己方向的论文了,希望这篇回答对你有所帮助。
原文作者:数学建模钉子户

这是我一篇老的回答,相信贴在这个答案下也对大家有帮助。
研究生课程阶段,我曾上过学校开的《机器学习理论与应用》的课程,当时我们用的教材是周志华老师的西瓜书。那老师开课第一天告诉我们的第一句话是:“这个课程的基础知识很少,我不用半个学期就可以讲完。之后的东西要全凭你们选定一个领域后深度探索,前提是你们掌握足够的编码能力。”
那个学期老师只是前面几节课讲了些基本概念,又讲了些Dropout、BatchNorm方面的内容。什么LSTM、什么Transformer、什么注意力机制,不存在的,从来不讲。
我心里暗自骂,什么老师,什么课程,水的一批,我来上这个课的目的就是系统地学习一下这个课,就这?
然而随着后面慢慢入门,我发现“系统学习机器学习”,确实不是一件易事。它并不像我们学习C++,我们先通过《C++ Primer》了解大概,接下来进阶可以看看《Effective C++》,《STL 源码剖析》等等。它并没有这样的学习路线。
大家往往都是先看一些书进行了解之后,在一项一项业务中去实践和探索,应用,没有什么硬性规定好的东西,有效果的框架就是有效果,前几年LSTM好用,后来Transformer来了,到现在自监督非常火,说不准又会有什么新奇的框架出来,替代之前的框架,这和负责的具体业务场景有非常大的关系。
所以我那堂机器学习课程后面的任务是,不同学院的人,选择一个自己感兴趣的领域,定期做论文分享,最后的大作业是复现3篇论文的内容,并进行Presentation。现在我觉得,这才是机器学习从业者最需要掌握的技能。
现在想想,当时我们老师说的那句话居然和吴恩达老师的三个步骤如出一辙:
- 1.掌握足够的编码能力
- 2.学习机器学习和深度学习
- 3.专注于一个角色
接下来我推荐的学习资料都将围绕这三个点展开,除了书籍,还有一些课程和链接
掌握足够的编码能力
学习机器学习最方便的语言是python,因此可以先从python开始,如果已经接触过一点python,那么强烈推荐这本鱼书《深度学习入门》,一个日本作家写的,这本书非常薄,但是他已经足够教你从最基本的一个layer开始搭建起一个神经网络。


对于入门而言,python是足够的,但是机器学习的模型一定是需要被部署到移动端或者服务器端的,因此C++也非常重要。因此还必须得推荐一下这本基础书籍《C++ primer》


学习机器学习和深度学习
《统计学习方法》一定是机器学习者的必看书籍,说实话,一开始看《统计学习方法》的时候,我感到非常吃力,看了B站的一个带读视频才让我慢慢把这本书看下来,这里也把视频链接推荐给大家。
带读 李航 《统计学习方法 第二版》 第五章 决策树 跟我一起学习成长为大神_哔哩哔哩_bilibili
西瓜书、花书、以及吴恩达老师的机器学习课程已经是非常优质的机器学习课程了。这里我推荐一个李沐老师 @李沐 出的深度学习课程。李沐老师是绝对的机器学习领域的大牛了。亚马逊首席科学家,著有 IT 畅销书《动手学深度学习》,在b站和知乎上都出了很多课程。
值得一提的是,这个课程应该可以算是比较系统也比较友好的了,因为它是从基础的数学知识开始讲的!从基础的数学知识出发,到常用的优化方法,然后过渡到机器学习领域。主要内容涵盖了卷积神经网络、循环神经网络的常用结构,包括LSTM、Transformer等等。

对于前面的内容,主要以理论讲解为主,到后期涉及具体的模型时,会有手把手的关键代码讲解,因此比起纯讲理论的课程要友好很多。对于已经具有一定基础的同学,也可以把这个课程当作一个字典,用于查缺补漏。
专注于一个角色
由于我所接触的领域是自动驾驶的感知算法领域,因此这里我只推荐一些对应的网课和书籍。
首先计算机视觉中的各种论文、框架、pytorch实现等等可以参考这位up主的视频,真的讲的非常详细,无论是老的各种RCNN结构和Yolo结构,还是新出的一些各式各样的的卷积方式:转置卷积、膨胀卷积、以及目标分割领域的论文解读。可以这么说,我秋招的基础知识就是跟这个大佬的课程学的,这里也放上它的链接: 霹雳吧啦Wz的个人空间_
除了深度学习方面的内容,传统的图像领域在知识仍然不可少,所以计算机视觉这本书还是得看的,常看常新。