即时战略游戏(比如 WAR3)的 AI 是怎样实现的?
49 个回答

国内真正做过游戏AI的很少,说概念的人很多,所以看了半天离实际编码还是很远,不知道该怎么入手,因为国内游戏主要以MMO和卡牌为主,RTS比较少,体育竞技类游戏更少,没几个真正写过强AI代码的。而从AI的难度上来看,是:MMO < FPS < RTS < 体育竞技。作为实际开发过AI的人,拿一份五年前的代码,以最难的体育竞技类游戏为例,来科普一下,什么叫做游戏团队策略,什么叫做分层状态机?具体该如何落地到代码?如果你能实现体育竞技的AI,那即时战略只是小事一桩。
硬派游戏AI,不是虚无缥缈的神经网络,用神经网络其实是一个黑洞,把问题一脚踢给计算机,认为我只要训练它,它就能解决一切问题的懒人想法。更不是遗传算法和模糊逻辑,你想想以前8位机,16位机上就能有比较激烈对抗的足球游戏、篮球游戏,那么差的处理器能做这些计算么?
硬派游戏AI,就是状态机和行为树。状态机是基本功,行为树可选(早年AI没行为树这东西,大家都是hard code的)。大部分人说到这里也就没了,各位读完还是无法写代码。因为没有把最核心的三个问题讲清楚,即:分层状态机、决策支持系统、以及团队角色分配。下面分类介绍:
何为分层状态机?
每个人物身上,有三层状态机:基础层状态机、行为层状态机、角色层状态机。每一层状态机解决一个层次的复杂度,并对上层提供接口,上层状态机通过设置下层状态机的目标实现更复杂的逻辑。
- 基础状态机:直接控制角色动画、提供基础动作实现,为上层提供支持。
- 行为状态机:分解动作,躲避跑、直线移动、原地站立、要球、传球、射球、追球、打人、跳。
- 角色状态机:实现更复杂的逻辑,比如防射求、篮板等都是由N次直线运动+跳跃或者打人完成。
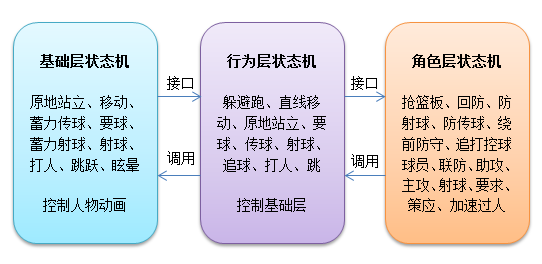

每一层状态机都是通过为下一层状态机设定目标来实现控制(目标设定后,下层状态机将自动工作,上层不用关心动画到底播到哪了,现在到底是跑是跳),从而为上层提供更加高级拟人化的行为,所有状态机固定频率更新(如每秒10次),用于判断状态变迁和检查底层目标完成情况。最高层的角色状态机的工作由团队AI来掌控,即角色分配的工作。而行为状态机以上的状态抉择,比如回防,到底是跑到哪一点,射球,到底在哪里起跳,路径是怎样的,则由决策支持系统提供支持。
何为决策支持系统?
状态机为角色的大脑,而决策支持系统是眼睛和耳朵,常见的工具有势力图(Influence Map)和白板(相当于不同角色间喊话),其中势力图比较常用,篮球游戏AI势力图可以用下面几张图表示:


势力图1:于防守篮板距离的map,每格分值为最远距离减去该格到篮板所在格子的距离


势力图2:进攻篮板距离的map,每个分值为最远距离减去该格到篮板距离,篮板后为0


势力图3:同敌人距离,每个敌人有影响范围,范围内,离敌人越近分越低,范围重叠选低的。


势力图4:同所有队友目标位置距离map,打分方法类似上图。


势力图5:与每个队友目标位置距离的map,标识单个队友目标位置距离的map。


势力图6:现实传球可行性的map,分数越高,越容易把球传到该格子上。


势力图7:容易把球传出的位置map,越容易直接传球给队友的区域分数越高。


势力图8:综合map,把以上map按一定加权求和。球员有合法目标区域,便于实现内线游走和外线游走。
每个球员性格不同,权值也不同,有保守的球员,有喜欢冒险的球员,权值不同而已。这些势力图都是为了给上面的三层状态机和团队状态机提供决策支持的。
何为团队角色分配?
每一层状态机为下一层设定一个目标,让下层自动工作,顶层角色层的目标则由最高层的团队ai进行战术指导。


团队状态机跟据当前的游戏情况确定当前首要目标(进攻或者防守),又根据当前的势力图等信息,确定进攻或者防守的具体战略(比如中路突破、盘路包抄、下底传中等),最终为当前己方的所有角色分配一个新的任务,即设定角色层状态机的新目标,确定他是做主攻还是做助攻,还是联防还是策应。具体该怎么联防,怎么策应,那就是角色层状态机的事情了。
话题总结
其实团队AI没那么玄乎,任何问题就是一个编程的建模问题,而最复杂的体育竞技类游戏的AI策略,上文已经给出模型,相信各位略加修改即可使用。写状态机是游戏AI的硬功夫,如果状态机逻辑经常改变或者项目规模大了以后可以考虑引入决策树来控制状态机,程序提供一系列接口,然后用可视化的编辑器进行更改,感兴趣的人可以参考决策树相关文章。
概率统计
如果上面这些逻辑都实现了,这时候才可以辅助与概率统计来让角色具备学习特性,比如统计某个策略对对手的成败情况,用来支撑下一次决策,这样能够逐步发现对手的弱点,还可以统计所有用户的大数据,来确定某种情况下,选择什么策略,能够对付60%的用户。
神经网络
在上面所有逻辑都实现了,你调试好了,玩着比较顺畅的时候,再在团队角色分配处尝试使用神经网络或者模糊逻辑,同样是学习大数据,来引入一些不可控的人性化的成分,让游戏更加有意思。(EA的 FIFA 20XX号称引入神经网络,Call of Duty的AI也号称引入了神经网络和学习机制)。确实能让游戏更有趣一点,但是仅仅有趣了一点而已。

War3的AI没有必要使用你提及的算法,或者说,根本无法使用。
有相关经验表明,游戏的AI如果采用神经网络等算法,会傻得出奇。
使用学院派算法的AI总会做出匪夷所思的动作,让人无法理解,游戏性尽失。
其主要原因在于遗传算法、模拟退火算法、神经网络算法、各种分类算法等等,都是高度概括化的,旨在找到局部最优解/或者找到全局关系。但是我们的AI实际不需要最优解和全局关系,一是你的电脑没那么叼,这么复杂的情况,如果真的高度概括出来了,其复杂程度是很高的,你的电脑也带不动,其次是算法在训练过程中收敛也会很慢,因为样本太过复杂,所以也许要花上很久(几年?猜的)来收敛,如果我们降低收敛精度要求来使速度加快,AI就会变得非常傻,做游戏明显不能这样。即使上述问题都被解决了,还有个问题就是,电脑得到了最优解和最优数学模型,你作为玩家就没有胜利的希望了,这游戏 给谁玩?
即使设计公司神经病般的决定如此设计,每当你的游戏有更新,兵种变化,数据变化,整个算法 就要重新训练,玩家需要重新下载AI的全部内容,对用户的体验和公司的工作效率都有损害。
战略类游戏的AI,还是有限状态机。
根据不同情况分类做不一样的事情,全都设计好,设计的尽量详细,就OK了。
关于其复杂度:
这类AI的程序体往往超乎想象的长,当然具体长度和游戏本身的设计也有一定关系,和游戏其它部分代码的设计优化程度也有关系,但是即使在较优环境中,其AI长度也是很长的。具体原因就在于其事无巨细的分类了所有情况,规定了AI在不同时间不同情况所做的不同事情,作为一个战略类游戏,尤其是即时战略类游戏,这是十分复杂的,情况十分多,因此程序本身也会相当的长。
但是他运行速度又快!又像人类在玩!又给了玩家胜利的可能!又容易设计和更改!
何乐而不为呢?

自己可以打开地图的jass脚本去看的,星际里也有script可以看。
War3时代,底层寻路是地图分Tile之后的A *寻路,上层逻辑估计就是FSM有限状态机,经过这些年发展,现在游戏里寻路还是基于导航网格(NavigationMesh)的A*,上层AI很多是Behavior Tree来实现的。
游戏和工程的AI目标完全不同的,游戏的AI是看起来聪明、表现多样;工程上我熟悉的多是为了解决组合爆炸问题,通过AI算法求解。但工程上的AI算法也有各种限制,例如遗传算法的过度收敛、收敛到局部解、神经网络的权重训练出来人不可理解、多少个神经节点能解决特定问题的没有定义,等等等等还有大量问题,这些对于游戏开发这种需要控制开发周期和确定性结果的工程设计都不利啊!所以游戏这种密集开发的软件工程,一是AI不需要这么复杂的算法就能实现,二是AI算法很多不稳定和难理解控制并不适合游戏快速迭代开发。
顺带一提,游戏中的AI系统底层A*是图算法,上层Behavior Tree只是个框架,方便逻辑书写的。当然这个世界上也有各种尝试把学院派AI应用在游戏的项目,例如
bwapi - An API for interacting with Starcraft: Broodwar (1.16.1),每年还有AI比赛
游戏界“深蓝” 伯克利的《星际争霸》AI“主宰”这是篇伯克利AI的报道,自己当年毕设就通过这平台搞了个星际微操的遗传神经网络玩了玩,满好玩的。
ps:个人感觉很多游戏里的操作集是有限的,游戏AI在工程意义上去拟真玩家是可解的,某种意义上游戏AI是可以率先通过工程手段通过图灵测试。
More human than human: AI game bots pass Turing Test
赞同楼上所有答案。
传统即时战略 [1] 的AI其实可以分为两个部分,一个是资源管理AI,一个是战争AI。
资源管理AI就是决定建筑、科技树、建兵的AI。
资源管理AI一般采用的是规则式AI。
规则式AI简单来说,就是一大堆if-else语句。
它有两个主要的部分,一个是工作记忆,另一个是规则记忆。[2]
工作记忆储存已知的游戏世界信息,这部分是动态的。
规则记忆储存设游戏计师设计的的规则。
正如
@五八所说,规则都是pre-scripted的。
而当工作记忆符合规则记忆的某一条规则时,相应的行动就会被触发。
这样做的好处是,游戏设计师拥有完全的掌控权。
而它的坏处也是十分明显的——因为是pre-scripted,所以整个规则是静止的。
但是毕竟在即时战略中,“正确合理”的发展方式就那么几套方案,所以规则式AI带来的好处多于坏处。
当然,规则式AI也有一些手段来动态学习。
例如给规则的触发条件并不是一些具体的“钱多少、兵多少”,而是权重。
每次分析时,根据上一次触发的结果的好坏来调整所有规则的权重,然后选出权重最高的规则,触发相应行为。[3]
然而动态有时会带来不确定性,所以采取与否,需要看游戏的设计来决定。
战争AI其实可以分为两层 [4],一层是将军AI,一层是士兵AI。
将军AI的工作是分析游戏世界,然后告诉所有士兵AI “去哪里,做什么”。
士兵AI的工作是分析自己附近的游戏世界,然后决定相应的行为。
在将军AI分析游戏世界时,有可能会采用Planner[8]、Utility-Based AI或者Neural Network[11]等能够带来不确定性的AI算法。
我对Planner不熟悉,就不多说了,大家可以看看[8]链接。
Utility-Based AI是指一套打分系统,根据游戏世界的信息对行为库[5]打分,然后选出或者组合出[6]一套行为[12]。
Neural Network是指几层神经元,例如经典的三层网络——输入层、隐藏层、输出层,世界信息通过输入层输入Neural Network系统,然后输出层输出一个结果[7]。
上面提到的这些算法有一个共同的好处,能够根据游戏世界的变化带来不确定性。
因为即时战略中的战争部分是最难预测的,玩家可以有无穷无尽的战术变化,所以将军AI需要更加动态来产生更加动态的战术。
然而,这些算法,特别是Nerual Network,它们产生的结果的过程是“黑箱的”——即使是我设计的将军AI,我也不知道它是怎么工作的...游戏设计师可以说失去了掌控权。
不过,有研究表明,神经质AI在即时战略中表现最好[9]....或许,这也是算是 “出其不意”吧...
相反地,士兵AI需要比将军AI更加静态。
如果你把士兵拉到敌人旁边,他却在那边Idle的话...
所以楼上都有提到的有限状态机、行为树等更加静态的算法[10]会更合适,因为游戏设计师可以设计好士兵的行动规则。
例如弓箭手在距离敌人大于XX米的情况下射箭,距离小于X米的时候肉搏,士气低于XX的时候走佬。
如果用Neural Network来实现这些设计的话就会哭笑不得...对的,我就用过Neural Network设计过士兵AI,是我们大学的神经网络的作业...
除了上面的提到的算法,还有另外一些提高游戏性的算法可以采用。
模糊逻辑,Fuzzy Logic,让游戏世界的信息模糊化,带来合理的不确定性。
势力图,Influence Map,让游戏世界的信息可视化或者是规范化,有助于将军AI分析。
随机,Randomization,在适当的时候做出适当的随机选择[13]。
注释或资料来源:
[1]我个人喜欢划分《星际》《红警》《帝国》等游戏为“传统即时战略”,通常都有资源管理和战争两部分组成。区别于塔防、即时战术等即时的策略游戏。
[2][3]资料来源:《游戏开发中的人工智能》第十一章,规则式AI。
[4]也可以是多层,视乎需求而定。
[5]行为库指的是一个很多单元行为的集合。一个例子就是行为树里面的“行为”。
[6]单元行为如果设计得好、相互没有依赖关系得话,它们之间可以相互组合。
[7]“结果”可以是一个行为的代号,也可以是一个权重。
[8]Planner资料来源:
http://intrinsicalgorithm.com/IAonAI/2012/11/ai-architectures-a-culinary-guide-gdmag-article/[9]资料来源:
Solidot | "神经质"AI在即时战略游戏中表现最突出[10]如
@Freelancer所说,称之为框架会更加合适。
[11]
Flanking Total War’s AI: 11 Tricks to Conquer for Your Game提到《全面战争》有用到Neural Network,但是我对文章的说的 “Neural Network用在士兵AI上” 表示怀疑,我猜测是用在将军AI上的。
[12]一个利用Utility-Based AI的成功例子
http://christophermpark.blogspot.sg/2009/06/designing-emergent-ai-part-1.html[13]感谢
@HARDCOREGAME提醒 :)

首先,状态机和行为树是最聪明的算法,因为设计师全权控制,设计师只要够聪明,AI就够强。但是设计师就算有那么聪明,他们往往也没有那么长的寿命去调试平衡。另一方面来讲,进化算法当然聪明。但正常人的硬件想必是带不起的,实践开发往往要寻找性能和聪明劲的平衡。
而且最重要的是游戏AI强到恰到好处就够了,游戏卖不卖得出去还是看PVP生态的。实际上大部分项目直接放弃了聪明劲儿。
从AI的难度上来看,是:MMO < FPS < RTS < 体育竞技
这些都或多或少以联机为主,或者我方与敌人实力相当不平衡,或者相当依赖于操作而非战术。我们考虑一下高自由度战棋、高自由度沙盒。如果用状态机和行为树,那么将会有无数个状态、无数个行动。所以游戏无非就两种情况:
- 说是AI,其实一眼就能看出不是人;但游戏很好玩。比如《文明》,比如GTA5。文明5就是Utility AI,文明6是行动树+Utility打分。而且对于文明,即便这样的AI每回合也会花费成吨时间。
- AI很聪明,很灵性;但游戏缺乏自由度。比如《星际2》,比如《F.E.A.R.》。
之所以要用Planner、Utility等方法:
- 是为了让AI有灵光乍现的能力,创造游戏变数。多用于真正的单机游戏,而不是联机游戏,因为这种游戏是真正的只有AI陪人在玩的。NPC的目标很可能就是“幸福地活下去”,随后NPC会意识到自己“不应该被绿”,“人若犯我我必犯人”,或者“惩奸除恶以保卫我大好河山”,又或者“好人没好报”等等事情。
- 对这种算法只需要输入整个世界状态,而不需要复杂的条件判定和各种状态。
- 所有机制都被解耦成了各种行动、任务,很容易改动、平衡,大大降低迭代难度。
《F.E.A.R.》就是用的GOAP,然而到了第二代《F.E.A.R. 2》,因为角色可用行动太多,每次环境改变就要搜索一遍,性能就跟不上了。从这里我们就可以看出,灵性和性能是不能兼得的。如果GTA5或者文明这样更自由的游戏去用GOAP,那么聪明是聪明了,可是万把块钱的电脑也带不动了。
GOAP从结果出发搜寻行动路径。HTN从复合任务出发,分解成子复合任务,直到分解到简单任务。由于设计师定义了所有的任务分解方式,所以几乎没有什么出人意料的行为。它比行为树好做,但又没有行为树那么精确。《KillZone》系列游戏都是用的HTN Planner. 聪明是聪明了,但不一定够强,也不是很像人类。
还有就是Utility AI。就是对行动、任务等等打分,这种方法经常和别的方法结合。如果一个AI单纯只采用Utility + 简单状态机,那么这个AI大概率极度短视,被高玩吊打。
至于你说的进化算法等AI算法:
- 性能跟不上,不能用在单机游戏中。
这个独立游戏作者做的是类XCOM的回合制战棋 https://www.youtube.com/watch?v=9jlLoAGvT_8 他尝试 Online Evolution 算法,结果是无论如何一回合也要超过10秒计算时间。最后他采用了选取不同行动,模拟采取该行动后整个游戏的走向,并对最终结果进行打分的方法。
很多算法不是不聪明,是内存跟不上或者需要太长计算时间。如果用未来硬件玩游戏,那当然很香。
最后,能不能用深度学习做游戏AI,训练个模型出来?其实是可以的,难点在于:
- 怎么教会AI有感情地、有目的的放水。虐玩家是赚不到钱的。
- 怎么精细平衡一个黑盒。玩家都在骂这个AI,设计师也都在骂这个AI,程序员摸摸脑袋说,这我没办法……
我记得微软有项目组说在MMO中使用,但“由于AI太强了,所以到底该怎么用还有待研究”。
我最近就看到了一个吕聘搞的 rct studio,至于靠不靠谱,那我就不知道了。

war3的AI我没写过,别的即时战略游戏的AI我倒是分析过。举个例子,神话时代、帝国时代3、国家的崛起的AI都差不多,前半截出农民分配矿工去不同资源上都是设定好的,几分几秒造哪种建筑出什么兵种都是设计好的。然后都是照方抓药,人类来什么兵AI就派某种兵来顶,发生什么状况就会触发什么预案,都是设计好的。所谓自我学习的AI也只不过是把某情况触发某预案的阈值变量变化了,不会出现特别复杂的“算”法,没什么可算的,都是条件触发罢了。国家的崛起的AI不过是一堆几kb的C++语言文件。至于微操方面的AI也是如此,一堆条件触发罢了。

泻药。
当然是状态机,楼上几位已经说得很好了。
我能补充的是:
1. 类似遗传算法这种AI算法都是计算量极大、需要等几小时、几天、几个月才能出结果的算法,而游戏的AI必须在一个tick内迅速作出决定;
2. 重量级的AI算法是解决不知道答案的问题用的。对于已知答案的问题,当然直接给答案就好;
3. 游戏中的AI有两个目标:更像人/更有趣。为了让他更像人,直接采用预定的策略就可以;为了更有趣,加入一些随机因素就成。

WAR3和帝国的AI顶层就2块:
- 固定的Build Order(建造顺序),电脑会按照给定的序列建造建筑(甚至单位),一般来说满足资源要求就可以造。关于这点,我曾观察过帝国4的AI,我灭掉电脑所有军队,把它围起来,他没有木材资源,但是其他资源是充足的,它会卡在那边(因为缺木材),不会利用多余的资源,因为它的前置BuildOrder没达成。这里会有一些细节,1)比如中途中间的BO建筑被拆了,要补。2)建筑选点的逻辑
- 军队一般就分2部分,一部分是进攻,一部分是防守。WAR3的WorldEdit中有文档说过,WAR3的AI有2个虚拟领主(进攻领主,防御领主)单位会被划分到这2个领主麾下,聚集在领主周围。当进攻领主聚集够特定的单位后(和BO一样是有一个清单的,但是越困难的电脑,这个清单越长。然后早期的清单和后期的清单不一样,这样可以让电脑更早发起第一轮攻势)就进攻玩家。防御领主带兵在家基地周围,防守进犯的敌军。
类似WAR3和帝国的游戏最顶层的策略基本是这样的。中间层还有一些逻辑,比如进攻领主选择从哪个方向进攻,选择进攻什么样的目标,这些有一些细节需要处理,但是没细研究过。
最底层当然还有寻路,等最基本的状态机,这块其他答主已经回答的比较详细了,我就不赘述了。


1 请从角色体验和游戏类型考虑AI的复杂度
2 有限状态机适应大多数系统
3 BT可以有效解决分支逻辑的体验表达
4 寻路和群组可能会涉及到A*的算法深入 但还是有替代方案
5 基于目标的AI是一个业界尝试的新思路
6 请制作让玩家觉得有趣“聪明的”AI 不是搞科研

游戏的AI只有一个目的,那就是让玩家玩的爽。
模拟退火,神经网络这些算法不能达成这唯一的要求,所以游戏中一般不会采用。
现在业界用的最多的是行为树,可以简单理解为加强版的状态机。
我来卖个萌 呵呵
有限状态机 几乎是2005年以前所有游戏的ai解决方案
但是即使是 有限状态机 ,在刻画复杂的游戏场景时,也会陷入冗长的代码链之中而丧失代码可读性
所以 behavior tree(行为树)出现了
本质上说,behavior tree的原理并不比 有限状态机 高明多少
但是behavior tree可以大大简化ai控制流程,使解决方案更加清晰
一个用有限状态机写的ai控制,用behavior tree大概只需要1/3的代码,并且可读性更强
要了解behavior tree,请查看cry engine 相关资料,
或者havok的行为树资料更加翔实
同时也有一个基于c#的实现,叫做tree sharp ,可以搜下

war3里是不可能使用类似“遗传,模拟退火”等学院派算法的,主要还是有限状态机,消息机制,控制行为,群状态控制等,具体到策略上的规则依然是人为设定好的。
黎清水推荐的书是游戏ai编程里最经典的教程,你可以去大概翻翻前几章便可以对游戏的ai设计有个基本大致的认识。

推荐一本书
游戏编程中的人工智能技术 (豆瓣),非常好的解释了题主的问题,而且有C++源码。其实上面说的都对,有限状态机,遗传算法,神经网络编程游戏AI,在这本书中都有提及。只不过实际应用中有限状态机应该是主流吧。

那种算法实际上性能很差。现在通常都用概率网络。

有人用强化学习来写星际AI,链接:
Berkeley Overmind