MapReduce流程详解
发布时间:2020-06-30 15:55:17
来源:网络
阅读:1750
作者:bigdata_lzw
栏目: 大数据
MapReduce源于Google一篇论文,它充分借鉴了“分而治之”的思想,将一个数据处理过程拆分为主要的Map(映射)与Reduce(归约)两步。简单地说,MapReduce就是"任务的分解与结果的汇总"。
MapReduce (MR) 是一个基于磁盘运算的框架,贼慢,慢的主要原因:
1)MR是进程级别的,一个MR任务会创建多个进程(map task和reduce task都是进程),进程的创建和销毁等过程需要耗很多的时间。
2)磁盘I/O问题, MapReduce作业通常都是数据密集型作业,大量的中间结果需要写到磁盘上并通过网络进行传输,这耗去了大量的时间。
注:mapreduce 1.x架构有两个进程:
JobTracker :负责资源管理、作业调度、监控TaskTracker。
TaskTracker:任务的执行者。运行 map task 和 reduce task。
在2.x的时候由yarn取代他们的工作了。
MapReduce工作流程:
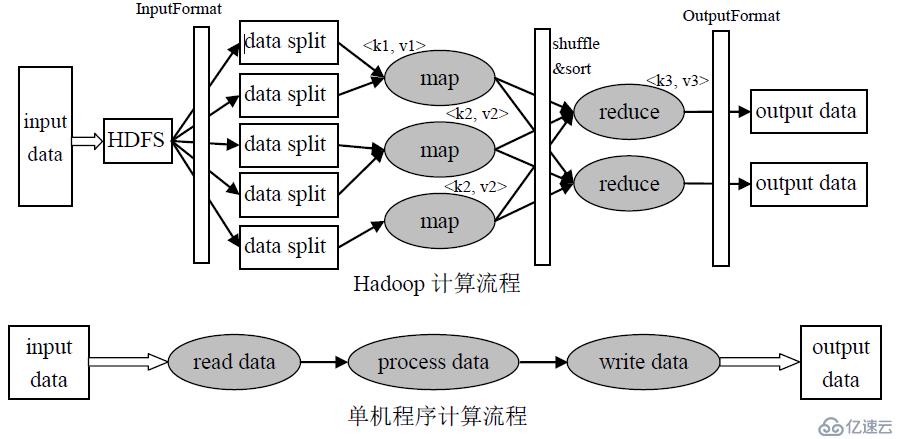
HDFS上的文件—>InputFormat—>Map阶段—>shuffle阶段(横跨Mapper和Reducer,在Mapper输出数据之前和Reducer接收数据之后都有进行)—>Reduce阶段 —>OutputFormat —>HDFS:output.txt
InputFormat接口:将输入数据进行分片(split),输入分片的大小一般和hdfs的blocksize相同(128M)。
Map阶段: Map会读取输入分片数据,一个输入分片(input split)针对一个map任务,进行map逻辑处理(用户自定义)
Reduce阶段:对已排序输出中的每个键调用reduce函数。reduce task 个数通过setNumReduceTasks设定,即mapreduce.job.reduces参数的默认值1。此阶段的输出直接写到输出文件系统,一般为hdfs。
MapReduce Shffle详解
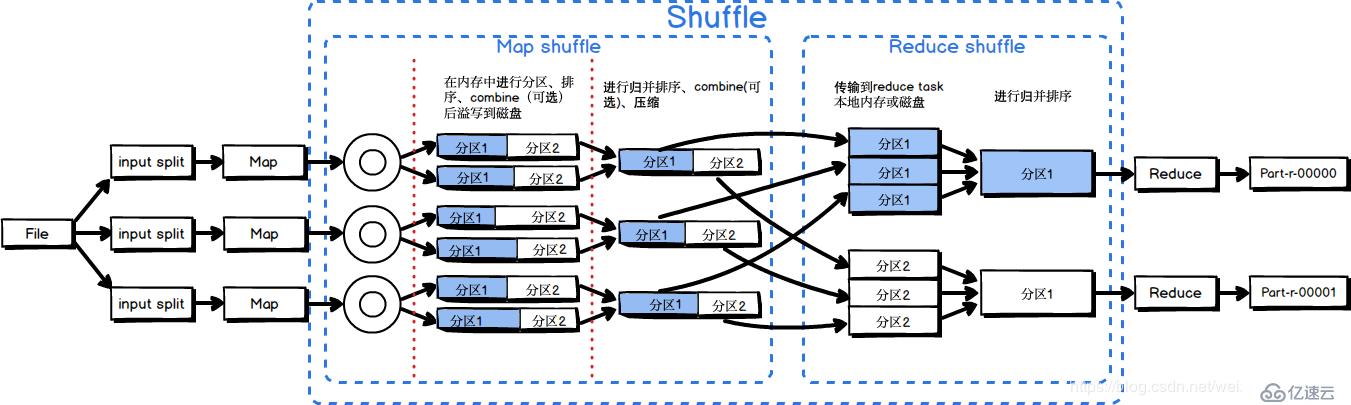
为了确保每个reducer的的输入都是按键排序的,系统执行排序的过程,即将map task的输出通过一定规则传给reduce task,这个过程成为shuffle。
Shuffle阶段一部分是在map task 中进行的, 这里称为Map shuffle , 还有一部分是在reduce task 中进行的, 这里称为Reduce shffle。
Map Shuffle阶段
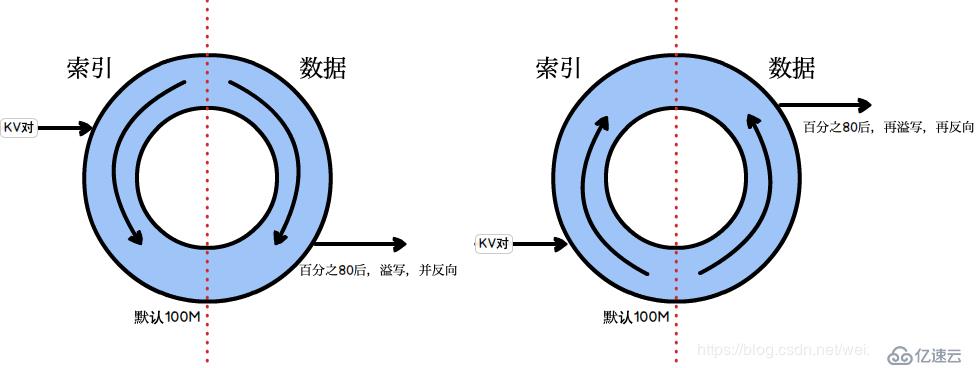
Map在做输出时候会在内存里开启一个环形缓冲区,默认大小是100M(参数:mapreduce.task.io.sort.mb),Map中的outputCollect会把输出的所有kv对收集起来,存到这个环形缓冲区中。
环形缓冲区:本质上是一个首尾相连的数组,这个数组会被一分为二,一边用来写索引,一边用来写数据。一旦这个环形缓冲区中的内容达到阈值(默认是0.8,参数:mapreduce.map.sort.spill.percent),一个后台线程就会把内容溢写(spill)到磁盘上,在这过程中,map输出并不会停止往缓冲区写入数据(反向写,到达阈值后,再反向,以此类推),但如果在此期间缓冲区被写满,map会被阻塞直到写磁盘过程完成。溢写过程按照轮询方式将缓冲区的内容写到mapred.local.dir指定的作业特定子目录中的目录中,map任务结束后删除。
相关概念了解:
Combiner: 本地的reducer,运行combiner使得map输出结果更紧凑,可以减少写到磁盘的数据和传递给reducer的数据。可通过编程自定义(没有定义默认没有)。适用场景:求和、次数等 (做 ‘’+‘’ 法的场景) 【如平均数等场景不适合用】。
Partitioner:分区,按照一定规则,把数据分成不同的区,Partitioner决定map task输出的数据交由哪个reduce task处理, 分区规则可通过编程自定义,一般自定义一个partition对应一个reduce task,默认是按照key的hashcode进行分区。注:默认reduce task 设置为1,所以不执行partition,执行partition操作时会先判断reduce task是否大于1 。
Spill:每次溢写会生成一个溢写文件(spill file),因此在map任务写完其最后一个输出记录之后,会有多个溢写文件。在Map 任务完成前,所有的spill file将会进行归并排序为一个分区且有序的文件。这是一个多路归并过程,最大归并路数由默认是10(参数:mapreduce.task.io.sort.factor)。如果有定义combiner,且至少存在3个(参数:mapreduce.map.combine.minspills )溢出文件时,则combiner就会在输出文件写到磁盘之前再次运行。当spill 文件归并完毕后,Map 将删除所有的临时spill 文件,通知appmaster, map task已经完成。
Map阶段压缩:在将压缩map输出写到磁盘的过程中对它进行压缩加快写磁盘的速度、更加节约时间、减少传给reducer的数据量。将mapreduce.map.output.compress设置为true(默认为false),就可以启用这个功能。使用的压缩库由参数mapreduce.map.output.compress.codec指定。注:此时建议优先使用效率比较高的压缩模式。
Reduce Shuffle阶段
Reducer是通过HTTP的方式得到输出文件的分区。使用netty进行数据传输(RPC协议),默认情况下netty的工作线程数是处理器数的2倍。一个reduce task 对应一个分区。
在reduce端获取所有的map输出之前,Reduce端的线程会周期性的询问appmaster 关于map的输出。App Master是知道map的输出和host之间的关系。在reduce端获取所有的map输出之前,Reduce端的线程会周期性的询问master 关于map的输出。Reduce并不会在获取到map输出之后就立即删除hosts,因为reduce有可能运行失败。相反,是等待appmaster的删除消息来决定删除host。
当map任务的完成数占总map任务的0.05(参数:mapreduce.job.reduce.slowstart.completedmaps),reduce任务就开始复制它的输出,复制阶段把Map输出复制到Reducer的内存或磁盘。复制线程的数量由mapreduce.reduce.shuffle.parallelcopies参数来决定,默认是 5。
如果map输出相当小,会被复制到reduce任务JVM的内存(缓冲区大小由mapreduce.reduce.shuffle.input.buffer.percent属性控制,指定用于此用途的堆空间的百分比,默认为0.7),如果缓冲区空间不足,map输出会被复制到磁盘。一旦内存缓冲区达到阈值(参数:mapreduce.reduce.shuffle.merge.percent,默认0.66)或达到map的输出阈值(参数:mapreduce.reduce.merge.inmem.threshold,默认1000)则合并后溢写到磁盘中。如果指定combiner,则在合并期间运行它已降低写入磁盘的数据量。随着磁盘上副本的增多,后台线程会将它们合并为更大的,排序好的文件。注:为了合并,压缩的map输出都必须在内存中解压缩。
复制完所有的map输出后,reduce任务进入归并排序阶段,这个阶段将合并map的输出,维持其顺序排序。这是循环进行的。目标是合并最小数据量的文件以便最后一趟刚好满足合并系数(参数:mapreduce.task.io.sort.factor,默认10)。
因此,如果有40个文件(包括磁盘和内存),不会在四趟中每趟合并10个文件而得到4个文件,再将4个文件合并到reduce。而是第一趟只合并4个文件,随后的三塘合并10个文件。最后一趟中,4个已经合并的文件和剩余的6个文件合计十个文件直接合并到reduce。
这并没有改变合并的次数,它只是一个优化措施,尽量减少写到磁盘的数据量。因为最后一趟总是直接合并到reduce,没有磁盘往返。
至此,Shuffle阶段结束。
Shuffle总结
1)map task收集map()方法输出的kv对,放到内存环形缓冲区中
2)从内存环形缓冲区不断将文件经过分区、排序、combine(可选)溢写(spill)到本地磁盘
3)多个溢出文件会归并排序成大的spill file
4)reduce task根据自己的分区号,去各个map task机器上取相应的结果分区数据
5)reduce task会取到同一个分区的来自不同maptask的结果文件,reduce task会将这些文件再进行归并排序
6)合并成大文件后,shuffle过程结束
MapReduce调优
输入阶段:处理小文件问题:
Map阶段:
1)减少溢写(spill)次数。
2)减少合并(merge)次数。
3)不影响业务逻辑前提下,设置combine。
4)启用压缩。
Reduce阶段:
1)合理设置map和reduce数。
2)合理设置map、reduce共存。
3)规避使用reduce:因为reduce在用于连接数据集的时候将会产生大量的网络消耗。
4)合理设置reduce端的buffer:默认情况下,数据达到一个阈值的时候,buffer中的数据就会写入磁盘,然后reduce会从磁盘中获得所有的数据。也就是说,buffer和reduce是没有直接关联的,中间多个一个写磁盘->读磁盘的过程,既然有这个弊端,那么就可以通过参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少IO开销。





