puppeteer爬虫的工作原理是什么
发布时间:2020-12-07 14:37:41
来源:亿速云
阅读:756
作者:小新
栏目: web开发
小编给大家分享一下puppeteer爬虫的工作原理是什么,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
爬虫(puppeteer)是什么?
爬虫又称网络机器人。每天或许你都会使用搜索引擎,爬虫便是搜索引擎重要的组成部分,爬取内容做索引。现如今大数据,数据分析很火,那数据哪里来呢,可以通过网络爬虫爬取啊。那我萌就来探讨一下网络爬虫吧。
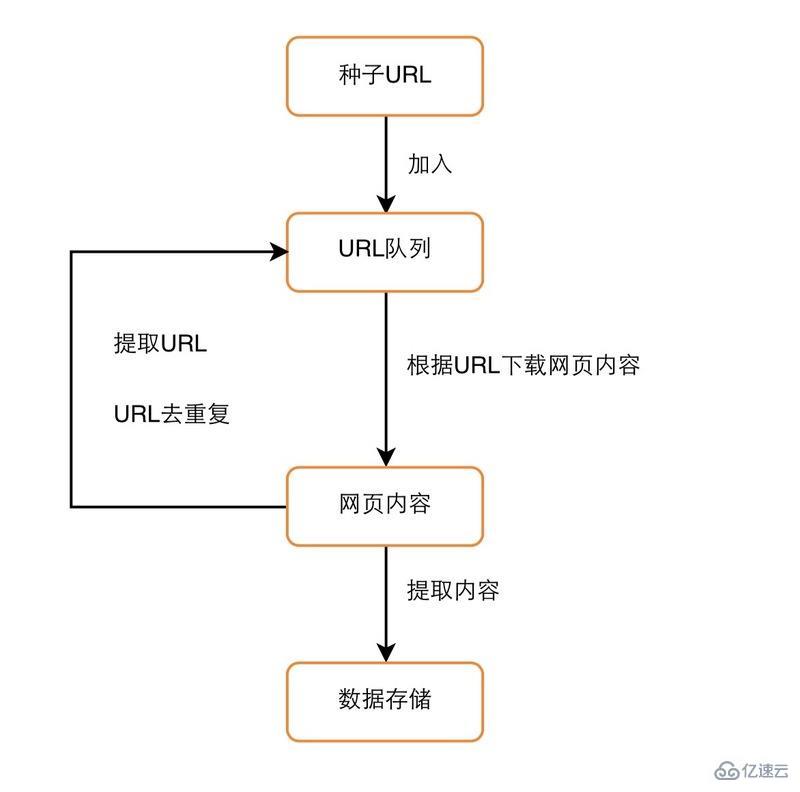
爬虫的工作原理
如图所示,这是爬虫的流程图,可以看到通过一个种子URL开启爬虫的爬取之旅,通过下载网页,解析网页中内容存储,同时解析中网页中的URL 去除重复后加入到等待爬取的队列。然后从队列中取到下一个等待爬取的URL重复以上步骤,是不是很简单呢?
广度(BFS)还是深度(DFS)优先策略
上面也提到在爬取完一个网页后从等待爬取的队列中选取一个URL去爬去,那如何选择呢?是选择当前爬取网页中的URL 还是继续选取当前URL中同级URL呢?这里的同级URL是指来自同一个网页的URL,这就是爬取策略之分。
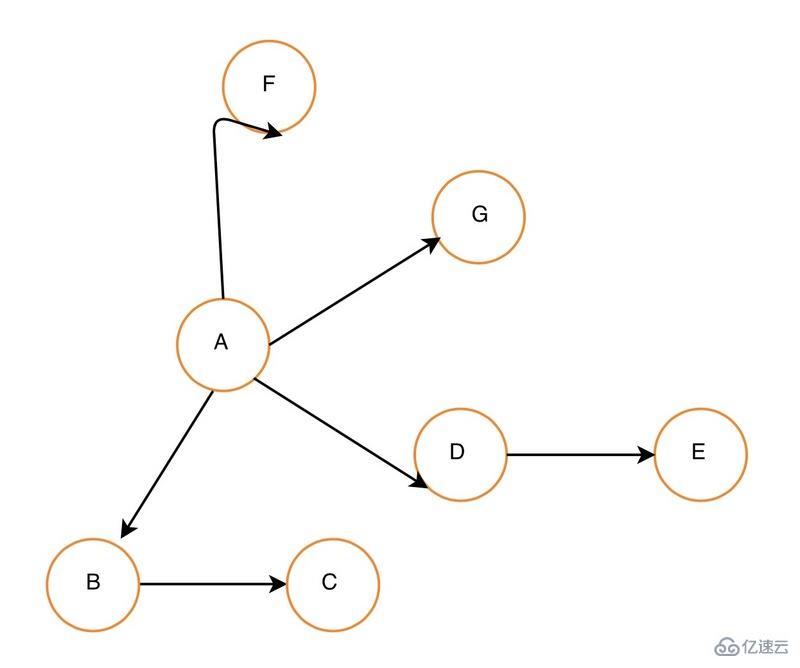
广度优先策略(BFS)
广度优先策略便是将当前某个网页中URL先爬取完全,再去爬取从当前网页中的URL爬取的URL,这就是BFS,如果上图的关系图表示网页的关系,那么BFS的爬取策略将会是:(A->(B,D,F,G)->(C,F));
深度优先策略(DFS)
深度优先策略爬取某个网页,然后继续去爬取从网页中解析出的URL,直到爬取完。
(A->B->C->D->E->F->G)
下载网页
下载网页看起来很简单,就像在浏览器中输入链接一样,下载完后浏览器便能显示出来。当然结果是并不是这样的简单。
模拟登录
对于一些网页来说需要登录才能看到网页中内容,那爬虫怎么登录呢?其实登录的过程就是获取访问的凭证(cookie,token...)
let cookie = '';
let j = request.jar()
async function login() {
if (cookie) {
return await Promise.resolve(cookie);
}
return await new Promise((resolve, reject) => {
request.post({
url: 'url',
form: {
m: 'username',
p: 'password',
},
jar: j
}, function(err, res, body) {
if (err) {
reject(err);
return;
}
cookie = j.getCookieString('url');
resolve(cookie);
})
})
}这里是个简单的栗子,登录获取cookie, 然后每次请求都带上cookie.
获取网页内容
有的网页内容是服务端渲染的,没有CGI能够获得数据,只能从html中解析内容,但是有的网站的内容并不是简单的便能获取内容,像linkedin这样的网站并不是简单的能够获得网页内容,网页需要通过浏览器执行后才能获得最终的html结构,那怎么解决呢?前面我萌提到浏览器执行,那么我萌有没有可编程的浏览器呢?puppeteer,谷歌chrome团队开源的无头浏览器项目,利用无头浏览器便能模拟用户访问,便能获取最重网页的内容,抓取内容。
利用puppeteer 模拟登录
async function login(username, password) {
const browser = await puppeteer.launch();
page = await browser.newPage();
await page.setViewport({
width: 1400,
height: 1000
})
await page.goto('https://example.cn/login');
console.log(page.url())
await page.focus('input[type=text]');
await page.type(username, { delay: 100 });
await page.focus('input[type=password]');
await page.type(password, { delay: 100 });
await page.$eval("input[type=submit]", el => el.click());
await page.waitForNavigation();
return page;
}执行login()后便能像在浏览器中登录后,便能像浏览器中登录后便能获取html中的内容,当让w哦萌也可以直接请求CGI
async function crawlData(index, data) {
let dataUrl = `https://example.cn/company/contacts?count=20&page=${index}&query=&dist=0&cid=${cinfo.cid}&company=${cinfo.encodename}&forcomp=1&searchTokens=&highlight=false&school=&me=&webcname=&webcid=&jsononly=1`;
await page.goto(dataUrl);
// ...
}像有的网站,拉钩,每次爬取的cookie都一样,也能利用无头浏览器取爬取,这样每次就不用每次爬取的时候担心cookie.
写在最后
当然爬虫不仅仅这些,更多的是对网站进行分析,找到合适的爬虫策略。对后关于puppeteer,不仅仅可以用来做爬虫,因为可以编程,无头浏览器,可以用来自动化测试等等。
以上是“puppeteer爬虫的工作原理是什么”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!





