一种深度学习中识别并处理标签噪声的方法与流程
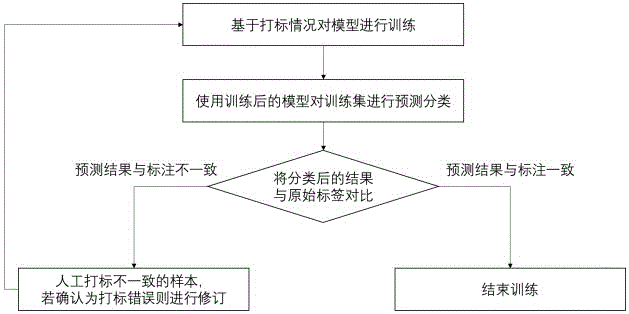
本发明属于深度学习
技术领域:
,具体属于一种深度学习中识别并处理标签噪声的方法。
背景技术:
:金融科技是指通过利用各类科技手段创新传统金融行业所提供的产品和服务,提升效率并有效降低运营成本,金融市场以及金融服务业务供给产生重大影响的新兴业务模式、新技术应用、新产品服务等。随着互联网金融的发展,金融欺诈问题的不断涌现,如何解决互联网金融欺诈问题、提高金融交易安全性,成为当前形势下亟待解决的问题。金融交易中欺诈者通过耳机指挥借贷者进行欺诈的场景,欺诈客户中有较大比例会戴耳机接收中介/骗子的实时指导,因此市场需要开发一个自动化模型来快速识别戴耳机的客户,并导向专门的风险筛查流程,以此节约人力资源与成本,同时降低行内资产的欺诈风险。但由于人工打标签成本高、质量低,本例模型训练集中样本严重不平衡,戴耳机的样本量约为不戴耳机样本量的1/100。且在进行模型训练时,必须面对标签噪声的影响,我们拿到的每一个带标签数据集都含有一定程度的噪声,即0标签数据集中含有少量的1标签,这部分1标签会严重影响训练模型的效果。由于样本量很大,对于每一个带标签数据集,我们不可能人工逐个检查并校正标签。现有技术中常用的标签噪声处理方法主要有:改变损失函数,通过改变损失函数使得模型在噪声数据集上训练后的性能与在干净的噪声数据集上的性能相当,但在实际操作过程中,改变的损失函数往往会降低模型的性能;使用鲁棒性的架构,但这类方法往往难以训练而且效果并不好;正则化,比如权重衰减、dropout、batchnormalization等方法,这类方法足以抵抗少量的噪声数据,但在面对稍多的噪声时,效果不太好;调整损失函数,在更新参数前调整所有训练样本对损失值的影响,从而来影响最终的损失值,但此类方法训练难度大,效果也并不是很好;丢弃疑似噪声的样本,但选择什么样的规则来丢弃疑似噪声样本会增大训练难度且不可避免地会丢弃一些标注正确的样本;半监督学习,从少量的干净数据集上训练多个小型的网络,然后将这些网络在噪音集上的预测结果进行集成,从而筛选出可能的标签噪音数据。深度学习模型往往需要大量标记正确的数据,而实际数据集中有8%-38.5%的数据是被污染的,故很多深度学习模型很容易对存在噪声的数据集过拟合,从而使得模型在测试集上的表现较差,而常用的处理标签噪声的方法并不能很好地解决这一问题。技术实现要素:针对现有技术中样本量大,人工无法逐个对标签数据进行检查,无法找出是噪音样本的的问题,本发明提供一种深度学习中识别并处理标签噪声的方法,其目的在于:通过对含有标签噪声的数据集进行迭代训练,从而筛选出潜在的标签噪声数据进行修正。本发明采用的技术方案如下:一种深度学习中识别并处理标签噪声的方法,包括以下步骤:步骤a:构建大规模的带有标签噪声的真实条件下的初始人脸图像数据集;步骤b:在imagenet图像数据集上使用resnet框架训练带有标签噪声的通用数据集得到通用图片分类模型,该通用图片分类模型使用了51层的cnn模型进行训练,目标为1000类图片标签(包含车,船,飞机,花,鸟,猫,狗等等,但不包含本发明示例的下游任务预测目标/标签),模型的中间层充分学习了各种物体的纹理特征,泛化/迁移学习能力良好;步骤c:将通用图片分类模型在初始人脸图像数据集上进行有监督迁移学习,得到标签分类模型;步骤d:将标签分类模型应用于初始人脸图像数据集上并进行标签预测,完成人脸图像数据集的分类和标签标注,得到预测后的人脸图像数据集;步骤e:将初始人脸图像数据集与预测后的人脸图像数据集进行对比,若标签一致,则结束训练;若标签不一致,输出预测后的人脸图像数据集与初始人脸图像数据集中不一致的标签样本,将不一致的标签样本进行人工检验,若不一致的标签样本标注错误则校正,得到校正后的人脸图像数据集。优选的,还包括步骤f:重复步骤c至e,将初始人脸图像数据集替换为校正后的人脸图像数据集。优选的,所述步骤a中还包括对初始人脸图像数据集进行预处理:用opencv和dlib对初始人脸图像数据集中的每一人脸进行检测,对人脸进行关键点定位并旋转对齐,之后依据眼睛和嘴唇的特征点裁剪人脸,再使用高斯噪声、对比度增强、调整亮度和几何变换增强的方式依次增强噪声标签样本。优选的,所述步骤c中具体包括:将初始人脸图像数据集随机切分为训练集、验证集和测试集,三者的数据量比例为2:1:1,将通用图片分类模型在训练集上训练最小化损失函数得到初始标签分类模型,将初始标签分类模型在验证集进行评估,评估后得到评估初始标签分类模型,再将评估初始标签分类模型依次在训练集上训练、验证集上评估,经过数次训练评估后,得到准标签分类模型,再将准标签分类模型在测试集进行评估,评估后得到标签分类模型。综上所述,由于采用了上述技术方案,本发明的有益效果是:1.本发明对标签噪声的数据进行训练,之后用训练得到的模型在训练集上进行预测,从而筛选出可能的标签噪声数据进行修正并迭代模型更可能筛选出标签噪声数据;本发明适用于含有标签噪声的数据,解决数据存在严重不平衡、打标错误的问题;本发明通过对含有标签噪声的数据集进行迭代训练,从而筛选出潜在的标签噪声数据进行修正,其不需要预先对数据进行清洗,训练难度低且人工成本低,效率高,具有重要现实意义。2.本发明将初始人脸图像数据集分为训练集、验证集和测试集,三者的数据量比例为2:1:1;其中,训练集用于模型在单轮(单个epoch)训练中最小化损失函数(此处学习任务为分类任务,所以损失函数定义为交叉熵损失函数,最小化损失函数即为最小化交叉熵损失crossentrophyloss,公式如上,其中l为交叉熵损失,y为真实标签,y_hat为模型预测值,该损失用于评估预测值与真实标签之间的差异,预测差异越大,交叉熵损失越大,最小化交叉熵损失即为最小化预测误差),验证集用于评估本轮训练的模型效果(泛化能力,避免过拟合),经过若干轮训练后,模型的验证集评估效果不再有显著提升,此时在测试集(独立于训练与验证样本)上评估模型的样本外表现,避免出现严重的过拟合,得到泛化能力强且稳定的模型。附图说明图1是本发明的一种具体实施方式的流程示意图。图2是本发明的一种具体实施方式的人脸示意图。具体实施方式本说明书中公开的所有特征,或公开的所有方法或过程中的步骤,除了互相排斥的特征和/或步骤以外,均可以以任何方式组合。下面结合图1对本发明作详细说明。本发明适用的条件:统计打标客户绝对数量与相对占比,如果打标数量充足,进入本发明所述的标签噪声处理与模型训练流程;如果打标数量不足,则需要考虑加入相似分布的外部标签样本参与训练,并进入本发明所述的标签噪声处理与模型训练流程;抽样评估打标质量,如果打标质量较差(漏标与误标情况较多),则直接进入本发明所述的标签噪声处理与模型训练流程;一种深度学习中识别并处理标签噪声的方法,包括以下步骤:步骤a:构建大规模的带有标签噪声的真实条件下的初始人脸图像数据集;人脸图像均为真实人脸,且数据集中含有标签噪声,初始人脸图像数据集具有如下特点:真实人脸图像从手机等拍摄工具获取或从互联网中爬取;少量标签为1的样本被误标为0,即标签为0的数据集中存在标签噪声;步骤b:在imagenet图像数据集上使用resnet框架训练带有标签噪声的通用数据集得到通用图片分类模型;步骤c:将通用图片分类模型在初始人脸图像数据集上进行有监督迁移学习,得到标签分类模型;其中有监督代表训练过程中使用的初始人脸图像数据集带有标签(虽然含有标签噪声,标签准确度不高),无监督则代表训练数据不含显式的标签;迁移学习则表示该模型训练的初始化权重来自于不同的学习任务a(即步骤b中的通用图片分类模型),与本学习任务b没有直接关联;即通用图片分类模型通过解析训练数据,学习到一个可以将数据映射到标签的函数,可以将不同标签的样本分类。步骤d:将标签分类模型应用于初始人脸图像数据集上并进行标签预测,完成人脸图像数据集的分类和标签标注,得到预测后的人脸图像数据集;即将训练好的标签分类模型重新应用于初始人脸图像数据集上并进行标签预测,即不展示样本的分类标签,让模型通过步骤b和c学习到的将数据映射到标签的函数,对初始人脸图像数据集上的样本进行分类并标注标签。步骤e:将初始人脸图像数据集与预测后的人脸图像数据集进行对比,若标签一致,则结束训练;若标签不一致,输出预测后的人脸图像数据集与初始人脸图像数据集中不一致的标签样本,将不一致的标签样本进行人工检验,若不一致的标签样本标注错误则校正,得到校正后的人脸图像数据集。即输出与预测标签与原始标签不一致的人脸图像,人工校对预测结果是否正确,将确实标注错误的样本从原数据集中删除,并将这些样本加入到正确的数据集中;还包括步骤f:重复步骤c至e,将初始人脸图像数据集替换为校正后的人脸图像数据集。所述步骤a中还包括对初始人脸图像数据集进行预处理:用opencv和dlib对初始人脸图像数据集中的每一人脸进行检测,对人脸进行关键点定位并旋转对齐,之后依据眼睛和嘴唇的特征点裁剪人脸,再使用高斯噪声、对比度增强、调整亮度和几何变换增强的方式依次增强噪声标签样本。所述步骤c中具体包括:将初始人脸图像数据集分为训练集、验证集和测试集,三者的数据量比例为2:1:1,将通用图片分类模型在训练集上训练最小化损失函数得到初始标签分类模型,将初始标签分类模型在验证集进行评估,评估后得到评估初始标签分类模型,再将评估初始标签分类模型依次在训练集上训练、验证集上评估,经过数次训练评估后,得到准标签分类模型,再将准标签分类模型在测试集进行评估,评估后得到标签分类模型。即将初始人脸图像数据集分为训练集、验证集和测试集,三者的数据量比例为2:1:1,其中,训练集用于模型在单轮(单个epoch)训练中最小化损失函数(crossentrophyloss),验证集用于评估本轮训练的模型效果(泛化能力,避免过拟合),经过若干轮训练后,模型的验证集评估效果不再有显著提升,此时在测试集(独立于训练与验证样本)上评估模型的样本外表现,避免出现严重的过拟合,得到泛化能力强且稳定的模型。具体实施例:前置条件数据集标签记为0标签与1标签,数据集样本严重不平衡,0标签远远多于1标签。0标签数据含有标签噪声,即部分1标签数据被误划分为0标签数据。模型训练阶段在含有标签噪声的数据集上,搭建神经网络,确定损失函数,使用梯度下降技术对参数进行训练,得到一组能使损失函数相对较小的模型参数,完成模型的初步训练。用初次训练好的模型对含标签噪声的训练集重新进行预测分类。将模型预测出的1标签与实际1标签比对,人工筛选出标签噪声数据并重新打标。模型迭代阶段在重新打标之后的数据集上训练模型,不断重复模型训练阶段,直至模型预测结果与实际数据基本吻合。1.构建大规模的深度学习初始人脸识别图像数据集,该数据集的特点为:图像均为真实场景下的人脸自拍;戴耳机的人脸图像数据标签为1,不戴耳机的人脸图像数据标签为0;不戴耳机(0标签)数据集存在标签噪声,即有一些戴耳机的数据混在里面,且这部分数据标签为0;戴耳机(1标签)数据集干净,即不存在不戴耳机的数据;不戴耳机的数据集规模远远大于戴耳机数据集规模;初始人脸识别图像数据集被随机分为训练集、验证集和测试集,其中训练集的规模要远大于验证集和测试集;2.对初始人脸图像数据进行数据预处理,具体方法为:使用face_recognition检测人脸的关键点并返回68个特征点,face_recognition是一个强大、简单、易上手的人脸识别开源项目,可以提取、识别、操作人脸;将人脸图像对齐,即计算左右眼中心坐标连线与水平方向的夹角θ,以左右两眼整体中心坐标为基点,将图片旋转θ度以使得左右眼中心连线与水平方向对齐(夹角θ为正时顺时针旋转,θ为负时逆时针旋转);基于眼睛和嘴唇的特征点对人脸图像进行裁剪,首先将两眼坐标中心到嘴唇坐标中心的像素距离定义为裁剪标定距离,再进行上下等距裁剪使得该裁剪标定距离占垂直方向的35%;裁剪标定距离的具体说明参见后文图2的人脸示意图;3.利用数据增强方法处理样本不平衡问题,具体方法为:使用几何变换(水平翻转)对图像进行数据增强;使用随机调整亮度(增加亮度或降低亮度)对图像进行增强;使用随机调整对比度对图像进行增强;利用程序给图像添加高斯噪声;4.利用resnet34训练模型。(1)resnet又叫深度残差网络,是卷积神经网络(cnn)中的一种,将resnet与其它神经网络在image数据集上的分类效果进行对比,发现resnet较其它神经网络准确率有比较大的提升。因此选择resnet作为最终模型。(2)resnet有很多不同结构,如resnet34、resnet18、resnet50等,将不同resnet分类效果在验证集上对比,结果如下表所示,发现resnet34在验证集上表现效果更好。表1不同模型框架训练效果对比表因此本案例使用resnet34作为训练模型。(3)resnet34训练模型的大致流程为:a.模型输入。resnet34是一种图像处理的方法,模型输入即为数值矩阵,通常的图像有红蓝绿3色通道,因此模型输入为3×m×n。其中m×n是图像的分辨率。b.模型结构。基本的cnn主要包含4个元素,分别为卷积层、池化层、激活函数、全连接层。卷积层的目的是提取图像特征,前向传播公式为:其中i和j为矩阵坐标,l为第l层,l-1为第l-1层(即前一层),为第l层第j列的偏移系数,为第l-1层第i行的取值,为第l层权重矩阵第i行第j列的取值;池化层简单来说是一种下采样,它可以大大降低数据维度。卷积层和池化层之后会有全连接层,然后加上一个损失函数就能输出我们想要的结果,比如二分类问题,我们常用logistic函数,其形式如下:其中f(x)输出的模型预测概率p,x为模型输出绝对值(未转化为概率),e为对数函数。resnet网络为解决传统cnn面临的随着层数增加,模型拟合效果下降的问题而提出,主要思想是一种恒等映射,具体公式为:模型只需要学习f(x)即可,如此便可解决模型的退化问题。5.batch_size设置为64,训练方法使用随机梯度下降算法(sgd),训练结果如下表所示:表2模型训练结果表数据集戴耳机数不戴耳机数精确率召回率f1验证集4644240.884610.9388测试集11298880.82570.80360.8145用训练好的resnet34分类模型重新应用于原训练集上并进行标签预测,对训练集上的样本进行分类并标注标签。预测的具体方法为使用softmax函数就可以将多分类的输出值转换为范围在[0,1]和为1的概率分布。具体公式如下:其中为第i个节点的输出值,c为输出节点的个数,即分类类别个数。与softmax相对应的是hardmax,后者只选出其中一个最大的值,即非黑即白。但是往往在实际中这种方式是不合情理的,比如对于图片分类来说,一张图片可能同时包含多种图片类别,我们更期望得到图片对于每个可能的物体类别的概率值(置信度),可以简单理解成属于对应类别的可信度。所以此时用到了soft的概念,softmax的含义就在于不再唯一的确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。6.将分类后的标签结果与原始标签进行对比,若不一致,输出与原始标签不一致的样本进行人工检验,若的确标注错误,则将标注错误的样本标签校正。若一致,则结束训练。7.结束训练后得到最终模型和一个没有标签噪声的干净数据集合。以上所述实施例仅表达了本申请的具体实施方式,其描述较为具体和详细,但并不能因此而理解为对本申请保护范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本申请技术方案构思的前提下,还可以做出若干变形和改进,这些都属于本申请的保护范围。当前第1页12
完整全部详细技术资料下载
当前第1页 1 2
相关技术
- 动作矫正模型的训练方法、动作...
- 一种多人姿态识别方法和装置与...
- 耕地变化检测方法、装置、电子...
- 多视角图像共存文字检测方法、...
- 标题列表的识别方法、系统、电...
- 目标物体检测模型、训练方法、...
- 灭点提取方法、装置、电子设备...
- 模型训练方法、图像生成方法、...
- 一种基于地形点分类的静脉图像...
- 基于神经网络模型的图像处理方...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1