Spark参数自适应优化方法及系统与流程
本发明属于时空大数据计算
技术领域:
,具体涉及一种spark参数自适应优化方法及系统。
背景技术:
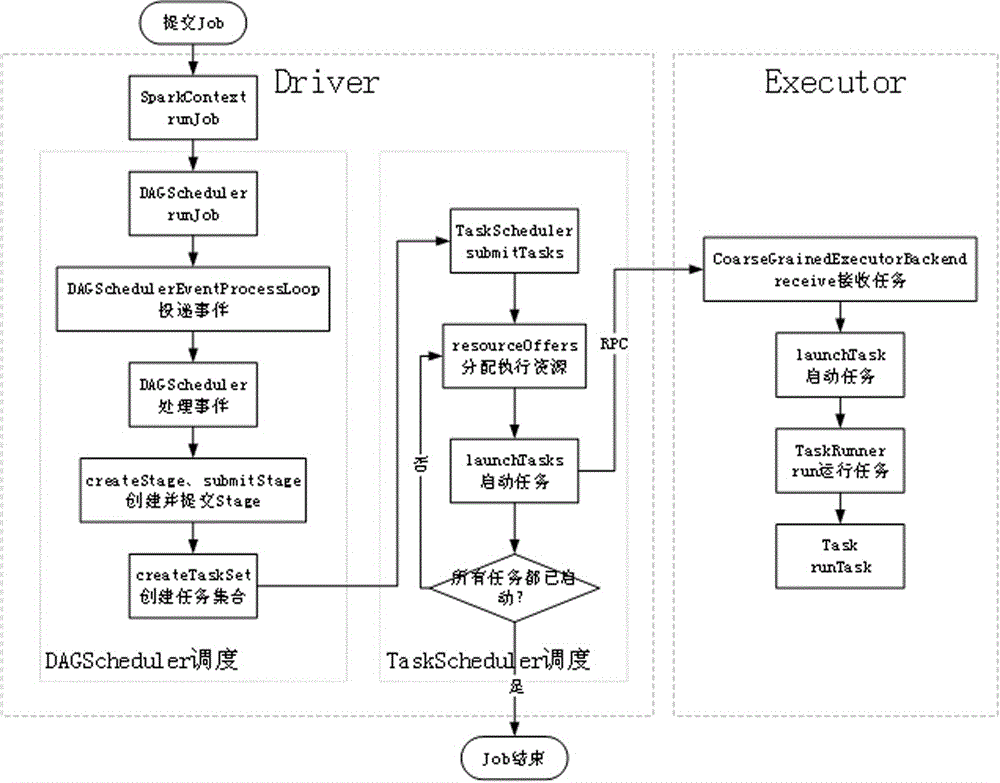
:过去几年里我们进入了大数据时代,海量数据的增长对存储管理和计算分析提出了新的需求,推动着大数据技术的发展。主流的计算框架也由基于mapreduce的hadoop发展为基于内存计算的spark。spark作为一个复杂的通用型分布式计算框架,提供了大量可配置的参数以适应不同应用场景下使用spark的各种需求,并最大化spark的计算性能。但过多的参数以及复杂的参数设置也给程序开发人员优化spark应用程序带来了很大的挑战。技术实现要素:本发明的目的是提供spark参数自适应优化方法及系统,以缓解spark参数调优较复杂的问题。本发明提供的spark参数自适应优化方法,包括:步骤1,构建spark任务执行时间的预测模型,利用样本数据训练该预测模型;本步骤进一步包括:步骤101,接收需优化的spark参数及其取值空间,取值空间基于spark集群环境确定;步骤102,在取值空间内选取不同的参数组合分别提交并执行spark应用,利用spark提供的sparklistener接口采集各spark应用执行的任务度量数据;所述任务度量数据至少包括需优化的spark参数和各spark应用执行时的任务执行时间;步骤103,将采集的任务度量数据构建神经网络模型,并对所构建的神经网络模型进行训练,得任务执行时间预测模型;步骤2,按照spark执行机制将待执行的spark应用依次分解为作业、阶段、任务,每一任务分配给每一executor节点的各core,利用任务执行时间预测模型预测每次任务执行时间,基于任务执行时间模拟spark阶段任务调度过程,推算出不同参数组合下阶段的执行时间;步骤3,根据不同参数组合下预测出的阶段执行时间,确定最终优化的参数组合。步骤101中,所述spark参数包括rdd分区数、以及executor的内存与核数。步骤102具体为:利用spark提供的sparklistener接口采集spark应用执行的任务度量数据,将任务度量数据输出到hadoop的container日志,并将日志聚合到hdfs上,通过从hdfs上解析日志文件即可提取任务度量数据。所述预测模型利用tensorflow工具中的回归模型构建模型。步骤2中推算阶段时间的具体实施过程如下:一core对应一时间线,所有时间线的起始时间相同,均设为0;按时间顺序分配任务,即每一任务分配到当前时间最早的时间线所对应的core上,利用任务执行时间预测模型预测该任务执行时间,将所预测时间加到相应时间线上;待阶段中所有任务分配完成,取所有时间线的终止时间,取其中最晚时间,即该阶段的总执行时间。步骤3中,以阶段执行时间最短所对应的参数组合作为优化的参数组合。本发明提供的spark参数自适应优化系统,包括:构建模型模块,用来构建spark任务执行时间的预测模型,利用样本数据训练该预测模型;所述构建模型模块进一步包括子模块:接收子模块,用来接收需优化的spark参数及其取值空间,取值空间基于spark集群环境确定;样本采集子模块,用来在取值空间内选取不同的参数组合分别提交并执行spark应用,利用spark提供的sparklistener接口采集各spark应用执行的任务度量数据;所述任务度量数据至少包括需优化的spark参数和各spark应用执行时的任务执行时间;构建模型子模块,用来将采集的任务度量数据构建神经网络模型,并对所构建的神经网络模型进行训练,得任务执行时间预测模型;阶段执行时间推算模块,用来按照spark执行机制将待执行的spark应用依次分解为作业、阶段、任务,每一任务分配给每一executor节点的各core,利用任务执行时间预测模型预测每次任务执行时间,基于任务执行时间模拟spark阶段任务调度过程,推算出不同参数组合下阶段的执行时间;优化参数组合确定模块,用来根据不同参数组合下预测出的阶段执行时间,确定最终优化的参数组合。本发明首先利用机器学习的方法预测特定的参数组合下,spark完成特定的计算模型需要花费的时间,获得执行时间;接着,比较不同参数组合下spark应用的执行时间,根据比较结果推荐最优的参数组合,从而实现参数的自适应优化。本发明通过预测方式避免了实际试验每种参数组合对应所需的执行时间,从而实现了一种可行的参数自适应优化方法。附图说明图1为spark作业提交流程的内部机制;图2为spark作业执行过程中单个任务的生命周期;图3为本发明方法的流程框图。具体实施方式为了更清楚地说明本发明的技术方案和技术效果,下面将对照附图对本发明的具体实施方式进行详细说明。显而易见地,下面描述仅仅是本发明的实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,并获得其他的实施方式。应当理解,此处所描述的具体实施例仅仅用以解释本发明,并不用于限定本发明。此外,下面所描述的本发明各个实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互组合。本发明通过机器学习的方法构建并训练spark应用执行时间的预测模型,利用该预测模型可在不实际执行的情况下,预测每种参数组合对应所需的大致执行时间,基于预测的时间对各种参数组合进行比较与评价,给出最合适的一种参数组合。对于spark应用执行时间的预测,本发明主要分析spark作业的底层执行机制,把spark应用分解为多个作业(job),每个作业可以分成多个阶段(stage),每个stage包含多个task,因此最终确定对task的执行时间进行预测,再来推算整个应用的执行时间。spark的核心是rdd(resilientdistributeddataset,弹性分布式数据集),并在rdd的基础上提供一系列操作api,api分为转换(transformation)和行动(action)两类,转换api构建rdd之间的依赖关系,不会实际执行;行动api则通过提交spark作业来实际计算相关rdd的内容。根据spark应用包含的行动api的个数,一个spark应用可以划分为同等数量的作业。每个spark作业执行过程的源码分析如图1所示,图中,job指spark作业;sparkcontext为一类行动api;dagscheduler模块用来分析提交的job,并根据计算任务的依赖关系建立dag,且将dag划分为不同的stage,每个stage可并发执行一组任务task;dagscheduler将划分完成的task提交到taskscheduler。首先,sparkcontext调用runjob函数,然后是作业的调度执行过程。作业调度分为dagscheduler和taskscheduler两部分。rdd之间的依赖关系形成一张有向无环图(directedacyclicgraph,dag),dagscheduler分析该依赖图dag,判断rdd之间的依赖关系是否为宽依赖,将宽依赖的rdd划分至不同的stage中,并根据rdd包含的分区数,分别对每个stage创建任务集(taskset),每个taskset包含与分区数相等的任务个数。宽依赖是spark中已有概念,spark的核心数据结构是rdd,rdd之间存在依赖关系,该依赖关系又分为宽依赖和窄依赖。窄依赖指一个父rdd只对应一个子rdd,子rdd可以依赖一个或多个父rdd,宽依赖则指一个父rdd对应多个子rdd。spark任务的调度过程由taskscheduler完成,详细的调度过程如图2所示,图1和图2均为已有的spark计算机理。taskscheduler通过调度将序列化后的task发送至相关的executor节点上,executor对task进行反序列化,并执行task中包含的相关操作。本发明利用spark提供的度量接口,采集了任务相关的度量数据,综合考虑度量数据与任务执行时间之间的相关性以及模型预测时的可行性,选取了executor的内存与核数、rdd的分区大小与分区数、任务处理数据量、单位内存处理的数据大小等用作神经网络模型的输入特征。具体实施时,可利用计算机程序来实现spark参数自适应优化的自动运行,实施例所提供方法的实现流程可参见图3,步骤如下:步骤1,构建spark任务执行时间的预测模型,利用样本数据训练该预测模型,具体可利用tensorflow构建模型。实施例中,预测模型构建的具体包括:步骤1.1,基于spark集群环境,确定需优化的spark参数及其取值空间。选取一个spark集群,基于当前的集群环境,确定spark参数的取值空间。本发明中主要考虑几个常用的spark参数,如rdd分区数、executor的内存与核数等,因此当前步骤主要根据集群中各个节点包含的总内存与总核数来确定单个spark应用可以使用的executor内存与核数的取值空间。需要说明的是,spark参数取值空间的确定需考虑集群的硬件条件,并结合操作者的经验来确定,并且还可根据实际运行结果来调整取值空间。下面将提供一种具体的取值空间确定方法,实际应用中,只要能确定出合理的参数取值空间的方法均是可行的。本实施例中,executor的内存和核数的取值空间,其上限一般设置为服务器的可用内存和核数的一定比例,该比例一般取为60%~80%。同时考虑到进行机器学习模型训练时,模型训练使用的参数范围应和模型预测时使用的参数范围一致,这样才能保证预测精度。因此后面的具体案例中,将executor的核数和内存的上限分别设为6核和6gb。rdd分区数的范围确定需要通过实验反复验证来获取合适的取值空间。通过多次实验发现,在其他spark参数相同的情况下,分区数增加对应用执行时间的影响是一个先减少后增加的过程,因此理论上能确定一个最优分区数。而分区数取值空间的确定则是先在实验中不断增加分区数,当发现分区数连续三次增加时,统计的spark应用执行时间都没有再减少,最后的分区数就作为分区数参数空间的上限。步骤1.2,在确定的取值空间内选取不同的参数组合分别提交并执行spark应用,利用spark提供的sparklistener接口采集各spark应用执行的任务度量数据。通过实现spark提供的sparklistener接口采集spark应用执行的任务度量数据,包括executor的内存与核数、rdd的分区大小和分区数、任务处理数据量、单位内存处理的数据大小、任务(task)执行时间等,将任务度量信息输出到hadoop的container日志,通过日志聚合将日志聚合到hdfs上,后续通过从hdfs上解析日志文件来提取任务度量数据。任务执行时间采用如下法确定:当一个任务从tasksetmanager中出队之后,会向sparklistener投递一个任务开始事件,记录任务的起始执行时间,当任务执行结束后,tasksetmanager在处理任务成功执行完成的消息时,会向sparklistener投递一个任务结束事件,记录任务的完成时间。这两个时间点之间的时间就是一个任务的执行时间。步骤1.3,将采集到的任务度量数据通过tensorflow工具来构建神经网络模型,具体模型采用了keras的sequential模型,经训练得spark任务执行时间的预测模型。本发明中主要利用tensorflow工具来对任务执行时间进行回归拟合,即可采用回归模型来构建神经网络模型,将采集的任务度量数据输入到keras的sequential模型中进行训练,即得spark任务执行时间的预测模型。在训练sequential模型预测模型时,可进行多次训练,每次训练后利用损失函数和测试数据集来评价模型的拟合结果和泛化能力,直至模型的预测偏差低于预设偏差值。步骤2,使用预测模型来预测任务的执行时间,并基于任务执行时间模拟spark阶段任务调度过程,推算出阶段的执行时间。前文已述spark作业的执行机制为:将spark应用分解为多个作业job,每个作业分成多个阶段stage,每个stage包含多个任务task,执行时将一个个任务分配到每一个executor的各core上执行。本发明中则是利用模拟调度来模拟spark的执行过程,当任务分配到各core时,利用预测模型预测各任务的执行时间,从而推算整个spark应用的执行时间。该模拟调度中,只会进行时间预测,不会实际执行其他计算。具体实施时,一core对应一条时间线,即产生多条分别与core对应的并行时间线,各时间线起始时间相同,可以均设为0。按时间顺序分配任务,每一个任务分配到时间最早的时间线所对应的core上。当把任务分配到某core上后,该core对应时间线的最新时间为当前时间加上该任务的预测执行时间。这样直至所有任务分配完成,取所有时间线的终止时间,取其中的最晚时间,即阶段的总执行时间。实施例中,步骤2进一步包括:步骤2.1,使用步骤1.1确定的参数取值空间,分别选取参数组合输入到模型中进行预测,得到任务的执行时间。需要说明的是,步骤1.2中的参数组合起到构建预测模型的样本数据的作用,用于模型的训练阶段;本步骤中所确定的参数组合用于预测阶段,即将该参数输入已训练模型中预测各参数组合下的任务执行时间。步骤1.2和本步骤中的参数组合所其作用不同,可以相同或不同,但应属于相同的参数取值空间。步骤2.2,模拟spark中任务调度过程,根据任务执行时间推算出阶段的执行时间。sparkstage中具体的任务调度方式有fifo和fair两种,本发明主要模拟fifo调度模式,即先进先出调度模式。具体模拟时,按照任务的先后顺序分别预测出任务的执行时间,结合spark应用的并行度,将任务的时间按照节点的先后空闲顺序分别累加到各个节点的总执行时间上,所有任务累加完成后,花费时间最长的节点的执行时间作为模拟的stage执行时间。具体实施时,考虑到rdd数据分区的方式未知,每个分区包含的数据量大小未知,对应的每个任务所处理的数据量也未知。在实际预测时,只能根据处理的总数据量和分区数计算一个平均分区数据大小,使用该平均值输入到模型中进行预测。这会对预测结果的准确性造成一定的偏差,但这种偏差属于系统性偏差,对于不同的参数组合的影响,大致上是相同的,能够确保最终推荐的参数组合的相对优势。步骤3,对不同参数组合下预测出的执行时间进行评价,确定最终推荐的参数组合。实施例中,步骤3中依据参数组合的评价结果推荐合适的参数组合具备以下特征:评价指标可以选择应用的执行时间,也可以选择综合考虑应用的执行时间与资源利用率等设计一个加权指标。具体实施时,本发明选取了执行时间作为评价指标,认为执行时间更少的参数组合更加具有优势。实施例本案例为,以四台可用核数14核、可用内存44gb的服务器构建spark集群,以轨迹数据点与路网数据进行空间相交计算为应用模型。步骤1,采集实验数据进行模型训练。见表1所示,分别在相应的参数取值空间下提交spark应用,本实施例共采集140746条任务执行的度量信息,其中,数据量的范围为从5千万开始,以5千万的数据量增长,直到当前参数配置能够处理的数据量上限为止。将采集的任务度量数据加工处理后输入到神经网络模型进行训练,模型的参数见表2。并使用测试数据集对模型进行评价,得到单个任务执行时间的平均预测偏差在18%左右,即预测时间与真实时间的差值与真实任务执行时间的比的平均值约18%。需要说明的是,表1中内存和核数指executor的内存与核数,数据量中n表示当前spark集群配置能处理的数据量上限值,该值通过试验确定,非精确值。表2中神经网络拓扑结构所对应的参数取值空间{64,64,8,8,1}分别指每层神经网络所包含的节点数。表1spark参数及参数取值空间spark参数参数取值空间executor个数4分区数{200,400,600}内存(单位:gb){2,4,6}核数{2,4,6}数据量[1,n]*5千万表2神经网络模型参数及参数取值空间参数参数取值空间模型kerassequential模型神经网络拓扑结构{64,64,8,8,1}优化器rmsproplossmsemetricsmae学习率0.0003epoch300步骤2,使用训练好的模型进行预测,从而选出合适的参数组合作为推荐参数。首先确定参数的取值范围,executor个数的取值范围为[1,4],核数为[1,6],内存为[1gb,6gb],对于分区数的取值范围,通过实验发现分区数对spark应用执行时间的影响呈现出先减少后增加的趋势,理论上存在一个最佳的分区数,因此分区数的范围为从100开始,以100的间隔递增,直到连续4次分区数增加而预测的应用执行时间没有减少为止。确定参数范围后,分别以不同的间隔在各自的参数范围内对不同的参数进行取值,对5亿条轨迹数据与1000多条道路数据空间相交计算模型进行预测,一共对1450种参数组合进行预测,得到每一种参数组合下的任务执行时间,并结合各自参数组合,如分区数、核数等,由任务的执行时间推算出整个stage的执行时间。步骤3,对不同参数组合进行比较,选出最合适的参数组合。通常比较合适的评价方式则是使用资源越少、执行时间越短的参数组合较优,本发明则主要根据stage的执行时间来评价,时间越短的参数组合较优。表3列出了预测执行时间最短的几个参数组合的基本信息。表3预测执行时间最短的参数组合executor内存核数分区数预测stage时间预测任务执行时间46gb6500209622ms9982ms45gb6600224850ms8994ms46gb5500248175ms9927ms45gb5500256250ms10250ms在预测任务执行时间时需要提供每个任务处理的数据量大小,考虑到数据空间分布对数据空间分区的影响(不同数据分布情况,在数据分区时,每个分区的数据量大小不是完全相等的),且每个分区处理的数据量只有在任务实际执行后才能获取到,因此在模型输入时每个分区所处理的数据量只能通过平均值(数据总量与分区数的比值)来代替,这对stage执行时间的预测精度会产生较大影响。但数据的空间分布情况对预测时间的影响对于不同的参数组合来说都是存在的,可以将其视为系统性偏差,而参数优化主要是比较不同参数组合之间的相对优劣,因此在存在偏差的情况下,还是可以从中选取较优的参数组合作为最后的推荐参数。表4是选取了表3中的最佳组合,并通过分别修改参数组合中的某个参数值得到其它比较参数组合,对这些参数组合实际提交spark应用后采集到的执行数据。比较发现之前预测的最佳参数组合{4executor,6核,6gb内存,500分区},预测时间是210秒,实际执行时间为363秒,预测偏差较大,但与其他组合比较,它的执行时间是有优势的,因此推荐该参数组合也是合理的。表4中有两个组合的执行时间比预测的最优组合时间更短,主要是因为这两个组合的内存为8gb或者核数是8核,没有在预测的参数组合范围内。表4预测执行时间最短的参数组合idexecutor内存核数分区数执行时间1466500363s2466300447s3466700420s4446500450s5486500351s6464500419s7468500346s此外,对事后提交的spark应用的任务数据进行了采集,包括获取到每个任务处理的实际数据量大小,将其输入到预测模型,预测出来的任务执行时间的相对偏差约为18%。因此,如果能够获取到每个任务的实际处理数据量大小,包括让数据分区更加均匀以接近平均分区大小,或者通过其他方法预先获取到每个分区的数据量大小,则stage的执行时间预测精度应该会有较大的提升。为了探究该方法的可行性,本发明的研究案例中只考虑了针对单个stage执行时间的参数优化,因此每个任务的计算流程都是相似的,只是数据上有差别。在实际使用时,要针对spark应用进行参数优化,则还需要考虑每个任务的计算内容对任务执行时间的影响。这一点可以通过判断每个stage包含的rdd类型和数量来考虑,将每种计算类型也作为任务执行时间预测模型的一个输入特征来考虑。当前第1页1 2 3
完整全部详细技术资料下载
当前第1页 1 2 3
相关技术
- 一种内存使用管理方法、装置及...
- 一种实现资源高效利用的集群极...
- 信息处理方法及装置、计算机存...
- 面向微服务的纳秒级电力资源分...
- 一种基于演化博弈论的分布式资...
- 电子系统和操作电子系统的方法...
- 基于区块链的去中心化金融数据...
- 人工智能芯片以及用于人工智能...
- 敏捷单星多约束任务优化调度方...
- 一种通用的分布式系统设计及其...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
自适应优化算法相关技术
- 面元修正与网格预先自适应计算方法
- 自适应式微网储能系统能量优化管理方法
- 一种基于绕环自适应相机路径优化的视频防抖方法
- 自适应差分进化算法优化的广义率相关p-i迟滞建模方法
- 一种水泥烧成分解炉全工况自适应温度优化控制方法
- 用于自适应放射治疗的优化方法及系统的制作方法
- 使用跨层优化自适应地传送fec奇偶校验数据的方法
- 自适应优化的比较-交换操作的制作方法
- 自适应查询优化的制作方法
- 大规模并行计算系统中的网络传输自适应优化方法及系统的制作方法
响应式和自适应相关技术
- 一种自适应调节响应速度的静止式动态无功补偿装置的制造方法
- 接收器分集的自适应使用
- 频段自适应的无线通信的制作方法
- 一种快速响应多轨道适应的卫星温控方法
- 自适应式耳机的制作方法
- 自适应式扶手箱的制作方法
- 具有自适应功能的传动装置的制造方法
- 自适应式管箱的制作方法
- 具有自适应空中接口的网关的制作方法
- 用于响应于网络拥塞进行速率自适应的方法和装置的制作方法
自适应粒子群优化算法相关技术
- 一种具有自适应功能的优化数据帧聚合的方法
- 基于自适应差分的粒子群定位算法
- 一种基于粒子群算法的自适应脊柱ct图像分割方法
- 一种融合梯度特征和自适应模板的粒子滤波红外跟踪方法
- 用于优化性能的自适应动力总成控制的制作方法
- 一种车载自适应优化供电装置的制造方法
- 交通控制子区优化与自适应调整方法
- 自适应式微网储能系统能量优化管理方法
- 一种基于绕环自适应相机路径优化的视频防抖方法
- 一种基于粒子群优化的心电信号自适应非局部均值降噪方法