一种面向GitHub大规模开源代码的快速代码文件溯源方法和装置与流程
本发明涉及开源软件源代码溯源领域,尤其涉及一种面向github大规模开源代码的快速代码文件溯源方法和装置。
背景技术:
开源软件在生产生活中得到了广泛地应用。在软件开发中,复用已有的开源软件或其中的构件是一种非常普遍的做法。为了降低代码的维护成本,降低开源许可证冲突的风险,很多开发团队有对其软件项目使用的开源代码进行溯源的需求。
代码溯源的基本方法是收集大规模开源代码并在这些开源代码中通过代码克隆检测技术搜索源头代码及其所属的软件项目。代码克隆检测是指给定两个代码文件或代码片段,判定他们是否相似。
目前最为主流的代码检测方法是日本学者toshihirokamiya提出ccfinder,该方法基于代码token序列比对,寻找代码克隆的片段。近来,也有一些学者提出了基于机器学习的方法,利用大规模的代码克隆数据训练判断代码克隆的分类器。
然而,上述方法存在两点不足:
一是收集大规模开源代码的网络传输、存储空间和处理时间等开销非常巨大,互联网上的开源代码仓库多达数百万个,网络传输和存储开销在数十tb以上。此外,互联网上每天都有大量新的仓库产生,即便仅考虑github这样具有代表性的平台,也几乎不可能完整收集上面的开源代码;
二是上述代码克隆检测算法的复杂度较高,执行效率低。
综上,一种能够降低代码溯源的成本和处理时间方法有待提出。
技术实现要素:
本发明所要解决的技术问题是实现低成本的代码溯源。
本发明的技术解决方案:
本发明的一种面向github大规模开源代码的快速代码文件溯源方法,包括以下步骤:
(1)读取需要溯源的文件,构造符合github代码搜索api标准的初始查询;
(2)执行查询并获取github返回的查询结果;
(3)提取各条查询结果中的文件路径及所在的代码仓库;
(4)通过github的代码仓库api获取代码仓库的属性;
(5)根据代码仓库的属性对代码仓库排序,将排序后的代码仓库和步骤(3)得到的文件路径作为代码文件溯源结果。
进一步地,还包括步骤(6):对步骤(5)得到的代码文件溯源结果进行人工验证,如果人工验证后认为准确性不符合要求,可重新构造代码搜索查询,并进入步骤(2)。
进一步地,所述初始查询包括:
a.文件名称:需要溯源的文件的包括后缀的完整文件名称;
b.文件大小(byte)范围:需要溯源的文件的大小的70%为下边界,需要溯源的文件的大小的130%为上边界;
c.代码语句:从需要溯源的文件尾部开始,以空格分隔,向前取10个字符串。
进一步地,步骤(1)根据文件名称、大小、编程语言和文件中的代码语句,构造符合github代码搜索api标准的初始查询。
进一步地,所述代码仓库的属性,包括创建时间、fork数量、star数量。
进一步地,步骤(6)中,相对于上一次查询,首先变化代码部分:
从上一次最后取一个字符串开始,以空格分隔,向前取10个字符串;
如果上一次查询后剩余代码不足10个字符串,则变更文件大小范围,变更为原文件的50%-70%和130%-150%,代码部分从代码文件尾部重新开始;
如果在该范围内,上一次查询后剩余代码不足10个字符串,则停止查询,即该文件通过本方法无法溯源。
基于同一发明构思,本发明还提供一种面向github大规模开源代码的快速代码文件溯源装置,其包括:
初始查询构造模块,负责读取需要溯源的文件,构造符合github代码搜索api标准的初始查询;
查询执行模块,负责执行查询并获取github返回的查询结果;
查询结果提取模块,负责提取各条查询结果中的文件路径及所在的代码仓库;
代码仓库属性获取模块,负责通过github的代码仓库api获取代码仓库的属性;
排序模块,负责根据代码仓库的属性对代码仓库排序,将排序后的代码仓库和查询结果提取模块得到的文件路径作为代码文件溯源结果。
进一步地,还包括迭代查询模块,负责对排序后的结果进行人工验证,如果人工验证后认为准确性不符合要求,则重新构造符合github代码搜索api标准的查询语句,并依次调用初始查询构造模块、查询执行模块、查询结果提取模块、代码仓库属性获取模块、排序模块进行迭代溯源。
基于同一发明构思,本发明还提供一种计算机,其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
本发明的有益效果是:该方法的网络传输和存储代价以mb计算,相对于已有方法,几乎可以忽略不计。由于利用了github提供的服务,因此计算开销也十分微小。本方法迭代式的查询虽然增加了一些复杂度,但是可以提高查询结果的召回率,确保方法的实用性。
附图说明
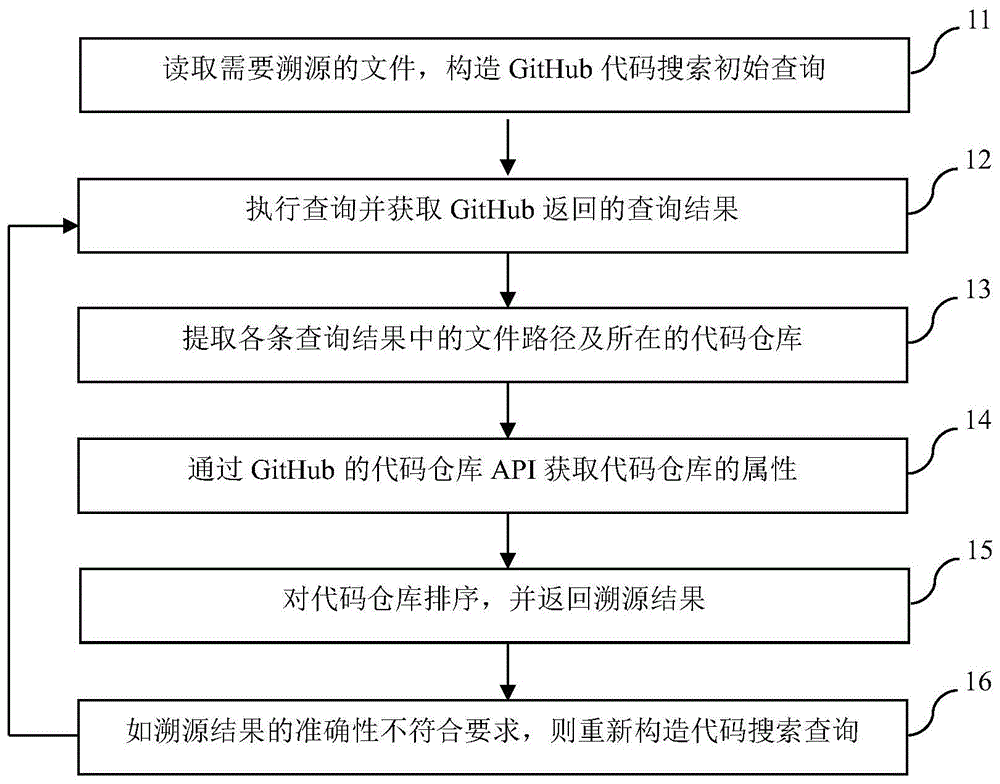
图1为本发明的一种面向github大规模开源代码的快速代码文件溯源方法实施例的步骤流程图。
具体实施方式
为使本发明的上述目的、特征和优点能够更加明显易懂,下面结合附图和具体实施方式对本发明作进一步详细的说明。
本发明的核心思想在于源头文件与当前文件的关键特征一致或相似,以及github的代码搜索引擎能够快速返回查询结果。
如图1所示,本发明一种面向github大规模开源代码的快速代码文件溯源方法实施例的步骤流程图,可以包括以下步骤:
步骤11,读取需要溯源的文件,构造github代码搜索初始查询。
根据文件名称、大小、编程语言和文件中的代码语句,构造符合github代码搜索api标准的初始查询。查询中的以下特殊字符需要过滤:
".",",",":",";","/","\\","`","'",'"',"=","*","!","?","#","$","&","+","^","|","~","<",">","(",")","{","}","[","]"
本实施例以开源跨平台项目异步io项目libuv的核心文件uv-common.c为例,该文件大小为17,738byte,编程语言为c,文件中的代码尾部如下:
构造的查询为:
q=uv__freeloop+default_loop+loop+if+0+err+assert+warnings+compiler+squelch+filename:uv-common.c+language:c+size:12417…23059
github的代码搜素api为:
https://api.github.com/search/code
步骤12,执行查询并获取github返回的查询结果。
github返回的查询结果为json格式,包括一系列items,每个item包括如下主要内容:
name:代码文件的文件名称。
path:代码文件在代码仓库中的路径。
repository:其中包括:
full_name:代码仓库的完整名称
步骤13,提取各条查询结果中的文件路径及所在的代码仓库。
将文件路径和所在的代码仓库需建立对应关系。
步骤14,通过github的代码仓库api获取代码仓库的属性。
github返回的查询结果为json格式,获取的属性包括:
created_at:创建时间
forks_count:fork数量。其中fork是指github上的一种克隆的代码仓库(https://help.github.com/en/articles/about-forks)。
stargazers_count:star数量。其中star是指github上的对代码仓库的收藏(https://help.github.com/en/articles/saving-repositories-with-stars)。
步骤15,对代码仓库排序,并返回排序后代码仓库和步骤13得到的代码仓库中文件的路径,即为代码文件溯源结果。
排序时,fork数量为主关键字,逆序;star数量为次关键字,逆序;创建时间为最后考虑的关键字,正序。进行排序的目的在于将最可能是源头的代码仓库和代码文件排在靠前的位置。
步骤16,如步骤15返回的代码文件溯源结果准确性不符合要求,则重新构造代码搜索查询。
查询结果的准确性需要人工进行浏览检查,如果结果不符合要求,则重新构造代码搜索查询;
相对于上一次查询,首先变化代码部分:
在本实施例中,第二轮再次构造的查询为:
q=err+void+uv_loop_closeloop+err+default_loop_ptr+default_loop+err+int+default_loop+uv_loop_t+filename:uv-common.c+language:c+size:12417…23059
如果上一次查询后剩余代码不足10个字符串,则变更文件大小范围,代码部分从代码文件尾部重新开始;
在本实施例中,这样的查询为:
q=uv__freeloop+default_loop+loop+if+0+err+assert+warnings+compiler+squelch+filename:uv-common.c+language:c+size:8869…12417
和
q=uv__freeloop+default_loop+loop+if+0+err+assert+warnings+compiler+squelch+filename:uv-common.c+language:c+size:23059…26607
基于同一发明构思,本发明的另一个实施例提供一种面向github大规模开源代码的快速代码文件溯源装置,其特征在于,包括:
初始查询构造模块,负责读取需要溯源的文件,构造符合github代码搜索api标准的初始查询;
查询执行模块,负责执行查询并获取github返回的查询结果;
查询结果提取模块,负责提取各条查询结果中的文件路径及所在的代码仓库;
代码仓库属性获取模块,负责通过github的代码仓库api获取代码仓库的属性;
排序模块,负责根据代码仓库的属性对代码仓库排序,并将排序后的代码仓库和查询结果提取模块得到的文件路径作为代码文件溯源结果;
迭代查询模块,负责对排序后的结果进行人工验证,如果人工验证后认为准确性不符合要求,则重新构造符合github代码搜索api标准的查询语句,并依次调用初始查询构造模块、查询执行模块、查询结果提取模块、代码仓库属性获取模块、排序模块进行迭代溯源。
基于同一发明构思,本发明的另一个实施例提供一种计算机/服务器,其包括存储器和处理器,所述存储器存储计算机程序,所述计算机程序被配置为由所述处理器执行,所述计算机程序包括用于执行本发明方法中各步骤的指令。
基于同一发明构思,本发明的另一个实施例提供一种计算机可读存储介质(如rom/ram、磁盘、光盘),所述计算机可读存储介质存储计算机程序,所述计算机程序被计算机执行时,实现本发明方法的各个步骤。
以上实施例仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的原理和范围,本发明的保护范围应以权利要求书所述为准。
- 应用处理方法和装置与流程
- 应用程序发布方法及装置与流程
- 数据加工方法、装置、工作节点...
- 资源分配参数的配置方法、装置...
- 用于生成多任务模型的方法、装...
- 部署流水线引擎系统的方法、持...
- 多平台软件版本管理及更新系统...
- 一种面向嵌入式高安全软件的持...
- 基于Guacamole的堡垒...
- 一种电网移动应用软件页面在线...
- 还没有人留言评论。精彩留言会获得点赞!