一种基于本地化差分隐私的多维众包数据真值发现方法与流程
本发明涉及网络与信息安全
技术领域:
,尤其涉及一种基于本地化差分隐私的多维众包数据真值发现方法。
背景技术:
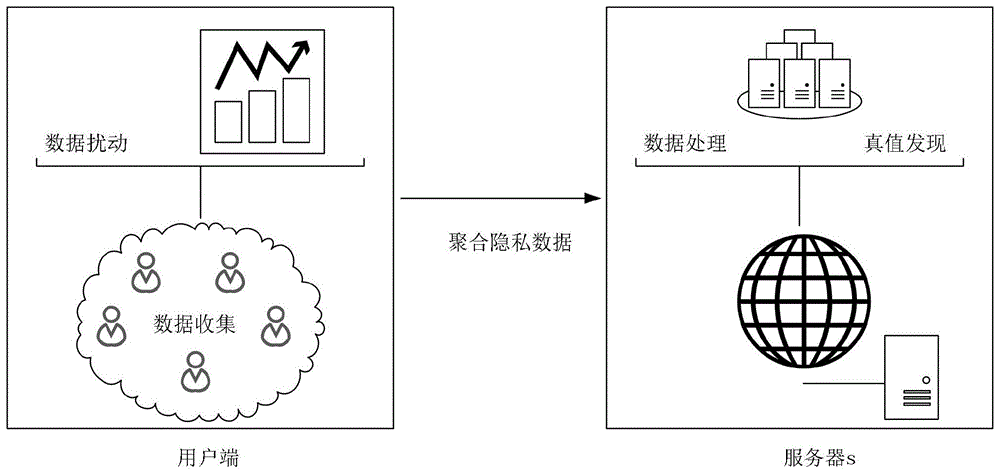
:随着互联网技术的飞速发展,众包形式已从线下模式发展为网络模式,即用户可以使用智能设备随时随地参与众包任务,企业使用该方式广泛聚集用户的数据并通过数据了解用户需求同时降低自身成本,众包已成为解决许多具有挑战性的任务的有效方案,然而,一方面,由于各种原因,受金融激励的影响、主观意识推断等,用户的回答任务的答案准确率存在不同,即用户提供的数据之间存在冲突性,这就需要考虑如何将嘈杂的候选答案从用户群体中聚合出来从而推理出准确的答案?另一方面,用户提供自己的数据时会有隐私问题:如网页相关性的数据可能会泄露用户的个人偏好等,就是由于这些隐私风险,用户可能会拒绝参与众包任务,这也需要考虑如何设置一个强隐私保护机制去保护用户的数据隐私?近几年,为了解决冲突性数据,许多研究都采用真值发现方法来获取项目的准确性回答,而对于既能保护用户隐私又能获得准确性答案的方法的研究中,文献[cloud-enabledprivacy-preservingtruthdiscoveryincrowdsensingsystems,2015]和文献[non-interactiveprivacy-preservingtruthdiscoveryincrowdsensingapplications,2018]等研究提出的框架是使用同态加密等加密方式和安全多方计算来保护用户数据同时进行真值发现获取准确性的数据,但是这些技术需要昂贵的计算资源以及用户之间的通信,用户规模大时会造成很大的开销。为了解决两大问题的同时能降低开销,采用一种强隐私保护机制--本地化差分隐私,本地化差分隐私的基本原理就是对于任意的两个输入值,通过该机制获得的输出值相等时的概率比趋近于eε,这样根据输出的结果无法判定输入的值是什么,则可以保证用户数据的隐私性。文献[anefficienttwo-layermechanismforprivacy-preservingtruthdiscovery,2018]首次将本地化差分隐私与真值发现进行结合,直接对扰动后的隐私数据进行真值发现,但该方案所考虑的众包数据为二元数据,当众包数据为多维时,该方案会造成误差较大,文献[truthinferenceonsparsecrowdsourcingdatawithlocaldifferentialprivacy,2018]也将本地化差分隐私与真值发现结合并使用mf方法应用于稀疏众包数据中,通过这些方法处理去获取众包数据的准确性结果,但该方案对于分类数据的处理存在误差。技术实现要素:本发明为克服现有技术存在的不足之处,提供一种基于本地化差分隐私的多维众包数据真值发现方法,以期能够解决具有任何背景知识的敌手去泄露用户敏感数据及无法从嘈杂的数据集中获取准确性回答的问题,同时让任何第三方能够在不知道用户敏感信息的情况下去估计原始数据分布,从而达到能够确保用户数据的隐私性的同时,能够有效的获得每一个众包项目中的准确结果的目的。本发明为达到上述发明目的,采用以下技术方案的:本发明一种基于本地化差分隐私的多维众包数据真值发现方法的特点是应用于服务器s与用户端所构成的众包平台中,且所述用户端包含n个用户u={u1,u2,…,ui,…,un},其中,ui表示第i个用户;将所述第i个用户ui对m个项目t={t1,t2,…,tj,…,tm}中任意第j个项目tj回答的众包数据记为dij,从而将第i个用户ui对m个项目回答的众包数据记为di={di1,di2,…,dij,…,dim},并将第i个用户ui对m个项目t的回答准确率记为wi,从而得到n个用户对m个项目t的回答准确率w={w1,w2,…,wi,…,wn};1≤i≤n;1≤j≤m;所述多维众包数据真值发现方法包括以下步骤:步骤s1、数据扰动阶段:在满足本地化差分隐私的条件下,所述用户端使用随机响应机制对第i个用户ui的众包数据di进行扰动处理,从而产生隐私数据并发送给服务器s以实现隐私保护:步骤s1.1、one-hot编码:将第j个项目tj的候选答案集合记为其中,表示第j个项目tj的第δj个候选答案;δj表示第j个项目tj的域值范围;将第i个用户ui对第j个项目tj的δj位二进制编码记为其中,表示第δj个二进制位;若第i个用户ui对第j个项目tj回答的众包数据dij为第v个候选答案hjv,则令δj位二进制编码中xij的第v个二进制位为“1”,其余二进制位为“0”;v=1,2,…,δj;步骤s1.2、使用满足本地化差分隐私条件的扰动机制来扰动数据:使用式(1)和式(2)所示的扰动机制对二进制编码中第v个二进制位进行扰动,得到扰动后的第v个隐私值为从而得到第i个用户ui对第j个项目tj的δj位二进制编码xij扰动后的隐私数据zij,进而得到第i个用户ui对m个项目扰动后的隐私数据zi={zi1,zi2,…,zij,…,zim}以及n个用户对m个项目扰动后的隐私数据z={z1,z2,…,zi,…,zn}:式(1)中,表示使第v个二进制位不变的扰动概率,ε表示隐私保护的程度;式(2)中,表示使第v个二进制位发生改变的扰动概率;步骤s2、隐私数据处理阶段:服务器s利用收集的隐私数据集z估计原始数据的分布,从而生成合成数据集步骤s2.1、利用式(3)获得第i个用户ui对第j个项目tj扰动后的隐私数据zij的期望值e(zij|xij):式(3)中,表示为δj维全为1的矢量;步骤s2.2、利用式(4)得到第j个项目tj的分布估计步骤s2.3、合成数据:对所述第j个项目tj的分布估计进行随机抽样,从而产生第i个用户ui对第j个项目tj的合成数据进而得到第i个用户ui对m个项目的合成数据以及n个用户对m个项目的合成数据步骤s3、真值发现阶段:服务器s对所述合成数据进行真值发现,得到m个项目的真值集truth以及n个用户对m个项目t的回答准确率集w:步骤s3.1、初始准备阶段:将m个项目中第j个项目tj的真值记为则有m个项目的真值集为令最大迭代次数为kmax次,当前迭代次数为k,则将第k次迭代的m个项目中第j个项目tj的真值表示为将第k次迭代的第i个用户ui对m个项目的回答准确率表示为初始化设置k=1;步骤s3.2、迭代更新阶段:步骤s3.2.1、初始化j=1;步骤s3.2.2、初始化i=1;步骤s3.2.3、利用式(5)得到第k次迭代的m个项目中第j个项目tj的真值式(5)中,hj表示第j个项目tj的候选答案集,表示第i个用户ui对m个项目中第j个项目tj的合成数据是否为候选答案中第v个候选答案hjv,若则表示合成数据为第v个候选答案hjv;若则表示合成数据不为第v个候选答案hjv;当k=1时,令第i个用户ui对m个项目的回答准确率步骤s3.2.4、将i+1赋值给i后,判断i>n是否成立,若成立,则执行步骤s3.2.5;否则,返回步骤s3.2.3;步骤s3.2.5、将j+1赋值给j后,判断j>m是否成立,若成立,则执行步骤s3.2.6;否则,返回步骤s3.2.2;步骤s3.2.6、初始化i=1;步骤s3.2.7、初始化j=1;步骤s3.2.8、利用式(6)得到第k次迭代的第i个用户ui对m个项目的回答准确率式(6)中,|t|是项目总数,表示第i个用户ui对m个项目中第j个项目tj的合成数据是否与第k次迭代的对m个项目中第j个项目tj的真值相同,若则表示两者相同,若则表示两者不同;步骤s3.2.9、将j+1赋值给j后,判断j>m是否成立,若成立,则执行步骤s3.2.10;否则,返回步骤s3.2.8;步骤s3.2.10、将i+1赋值给i后,判断i>n是否成立,若成立,则表示得到第k次迭代的m个项目的真值集truth以及n个用户对m个项目t的回答准确率集w;并执行步骤s3.3;否则,返回步骤s3.2.7;步骤s3.3、将k+1赋值给k后,判断k>kmax是否成立,若成立,则表示得到最终的第kmax次迭代中的m个项目的真值集truth和n个用户对m个项目t的回答准确率集w;否则,返回步骤s3.2执行。对众包多维数据进行真值发现方法的隐私保护方案中,本发明的有益效果体现在:1、本发明采用了强隐私保护机制-本地化差分隐私这一种新的隐私保护技术进行数据保护,防止了信息泄露,相对于安全多方计算以及同态加密等加密技术,由于其可以抵御具有任意背景知识的攻击者,同时也能够防止不可信第三方,包括服务器等的攻击,其具有强隐私保护特性,而且由于其直接对数据进行数据扰动,而不需要几方之间进行交流传递密钥等,降低了通信成本。2、本发明利用了满足本地化差分隐私的扰动机制,保证了无偏估计原始数据的分布情况,同时,在每个项目有多维数据的情况下降低直接使用隐私数据进行真值发现的误差,保证了总体数据分析的可用性。3、本发明采用了真值发现技术对每个项目的数据进行处理,解决了众包平台中由于各种原因导致的数据不一致问题以及用户质量不一致带来的结果不准确,使得能从冲突性数据中获取准确性的数据结果,保证真值更新的准确性,使得在众包平台中既能保证用户隐私又能保证数据的可用性。附图说明图1是本发明应用场景示意图;图2是本发明基于本地化差分隐私的多维众包数据真值发现方法的实施步骤流程图。具体实施方式为了保护参与到众包中的用户的回答数据不会被泄露,同时为了解决由于多用户之间可能存在的偏见等而产生冲突数据的问题以及用户质量不一致问题,本实施例的一种基于本地化差分隐私对多维众包数据进行真值发现方法,是应用于如图1所示的服务器s与用户端所构成的众包平台中,且用户端包含n个用户u={u1,u2,…,ui,…,un},其中,ui表示第i个用户;将第i个用户ui对m个项目t={t1,t2,…,tj,…,tm}中任意第j个项目tj回答的众包数据记为dij,从而将第i个用户ui对m个项目回答的众包数据记为di={di1,di2,…,dij,…,dim},并将第i个用户ui对m个项目t的回答准确率记为wi,从而得到n个用户对m个项目t的回答准确率w={w1,w2,…,wi,…,wn};1≤i≤n;1≤j≤m;如图2所示,该多维众包数据真值发现方法包括以下步骤:步骤s1、数据扰动阶段:用户进行回答后,在满足本地化差分隐私的条件下,用户端使用随机响应机制对第i个用户ui的众包数据di进行扰动处理,从而产生隐私数据并发送给服务器s以实现隐私保护:步骤s1.1、one-hot编码:将第j个项目tj的候选答案集合记为其中,表示第j个项目tj的第δj个候选答案;δj表示第j个项目tj的域值范围;将第i个用户ui对第j个项目tj的δj位二进制编码记为其中,表示第δj个二进制位;若第i个用户ui对第j个项目tj回答的众包数据dij为第v个候选答案hjv,则令δj位二进制编码中xij的第v个二进制位为“1”,其余二进制位为“0”;v=1,2,…,δj;假设的基于本地化差分隐私的多维众包数据真值发现方法应用于一某众包平台,参与到众包平台中的用户者回答的真实众包数据记录对于服务器s来说是未知,如表1所示,这里有5位用户u={u1,u2,u3,u4,u5}参与回答,项目t包含某地区大多数人的教育程度、人均收入水平、教育程度与收入水平是否有关,3个项目的候选答案分别为教育程度={高中,大学,硕士},人均收入水平={低,中,高},相关性={相关,无关},用户将对这三个项目进行回答,这里每条记录表示一个用户对这3个项目的回答情况及其编码;表1用户数据及其编码user教育程度人均收入水平相关性u1大学(100)中(010)无关(01)u2高中(010)低(100)相关(10)u3大学(100)中(010)无关(01)u4大学(100)高(001)相关(10)u5硕士(001)高(001)相关(10)步骤s1.2、使用满足本地化差分隐私条件的扰动机制来扰动数据:使用式(1)和式(2)所示的扰动机制对二进制编码中第v个二进制位进行扰动,得到扰动后的第v个隐私值为从而得到第i个用户ui对第j个项目tj的δj位二进制编码xij扰动后的隐私数据zij,进而得到第i个用户ui对m个项目扰动后的隐私数据zi={zi1,zi2,…,zij,…,zim}以及n个用户对m个项目扰动后的隐私数据z={z1,z2,…,zi,…,zn}:式(1)中,表示使第v个二进制位不变的扰动概率,ε表示隐私保护的程度;式(2)中,表示使第v个二进制位发生改变的扰动概率;这里ε的大小会影响数据的安全性,如式(1)与式(2)所示,使第v个二进制位不变的扰动概率与使第v个二进制位发生改变的扰动概率相加之和为1,则有若ε的值越小,使第v个二进制位不变的扰动概率就会变得越小,第v位的值改变的可能性会变大,当对某一数据编码后的所有的二进制位进行扰动的过程中使用的值ε越小时,其二进制位扰动概率较大,则隐私保护程度就会变强,安全性越好;步骤s2、隐私数据处理阶段:服务器s利用收集的隐私数据集z估计原始数据的分布,从而生成合成数据集步骤s2.1、利用式(3)获得第i个用户ui对第j个项目tj扰动后的隐私数据zij的期望值e(zij|xij):式(3)中,表示为δj维全为1的矢量;步骤s2.2、利用式(4)得到第j个项目tj的分布估计步骤s2.3、合成数据:对第j个项目tj的分布估计进行随机抽样,从而产生第i个用户ui对第j个项目tj的合成数据进而得到第i个用户ui对m个项目的合成数据以及n个用户对m个项目的合成数据步骤s3、真值发现阶段:服务器s对合成数据进行真值发现,得到m个项目的真值集truth以及n个用户对m个项目t的回答准确率集w:步骤s3.1、初始准备阶段:将m个项目中第j个项目tj的真值记为则有m个项目的真值集为令最大迭代次数为kmax次,当前迭代次数为k,则将第k次迭代的m个项目中第j个项目tj的真值表示为将第k次迭代的第i个用户ui对m个项目的回答准确率表示为初始化设置k=1;步骤s3.2、迭代更新阶段:步骤s3.2.1、初始化j=1;步骤s3.2.2、初始化i=1;步骤s3.2.3、利用式(5)得到第k次迭代的m个项目中第j个项目tj的真值式(5)中,hj表示第j个项目tj的候选答案集,表示第i个用户ui对m个项目中第j个项目tj的合成数据是否为候选答案中第v个候选答案hjv,若则表示合成数据为第v个候选答案hjv;若则表示合成数据不为第v个候选答案hjv;当k=1时,令第i个用户ui对m个项目的回答准确率式(5)所求的第k次迭代的第j个真值为第j个项目tj候选答案集中计算出来值最大的候选答案,故真值计算的过程与用户回答项目的准确率有关,若第k-1次第i个用户回答项目的准确率wi越高,那么第i个用户对第j个项目回答的候选答案的计算结果的影响就会增大,则该候选答案为真值的可能性变大,反之,若准确率wi越低,则影响就会降低,该候选答案为真值的可能性变小,这保证了能在嘈杂的数据集中选择出较准确的真值;步骤s3.2.4、将i+1赋值给i后,判断i>n是否成立,若成立,则执行步骤s3.2.5;否则,返回步骤s3.2.3;步骤s3.2.5、将j+1赋值给j后,判断j>m是否成立,若成立,则执行步骤s3.2.6;否则,返回步骤s3.2.2;步骤s3.2.6、初始化i=1;步骤s3.2.7、初始化j=1;步骤s3.2.8、利用式(6)得到第k次迭代的第i个用户ui对m个项目的回答准确率式(6)中,|t|是项目总数,表示第i个用户ui对m个项目中第j个项目tj的合成数据是否与第k次迭代的对m个项目中第j个项目tj的真值相同,若则表示两者相同,若则表示两者不同;式(6)所求的第k次迭代的第i个用户的回答准确率为第i个用户ui对m个项目回答后的数据与第k次迭代的m个项目的真值相同的比例,故若第i个用户对m个项目回答的数据与m个项目的真值相同越多,那么第i个用户的回答准确率越高,其对真值的影响也就越大,反之,若第i个用户的回答准确率越低,其对真值的影响越小。注意,由于真值发现阶段采用的是合成数据集,用户数据是随机抽样而获得的,非用户原始数据,对于用户的回答准确率来说,其与用户原始数据一致,对于服务器来说,都是未知的,保证了隐私安全。步骤s3.2.9、将j+1赋值给j后,判断j>m是否成立,若成立,则执行步骤s3.2.10;否则,返回步骤s3.2.8;步骤s3.2.10、将i+1赋值给i后,判断i>n是否成立,若成立,则表示得到第k次迭代的m个项目的真值集truth以及n个用户对m个项目t的回答准确率集w;并执行步骤s3.3;否则,返回步骤s3.2.7;步骤s3.3、将k+1赋值给k后,判断k>kmax是否成立,若成立,则表示得到最终的第kmax次迭代中的m个项目的真值集truth和n个用户对m个项目t的回答准确率集w;否则,返回步骤s3.2执行。当前第1页12
完整全部详细技术资料下载
当前第1页 1 2
相关技术
- 查看图像的方法、装置、设备及...
- 多图数据中频繁子图挖掘的差分...
- 一种支持信息检索的安全网络文...
- 一种可搜索加密方法、装置、设...
- 一种基于模式匹配算法的敏感信...
- 一种数据库数据安全管理方法及...
- 一种医疗安全以及医疗档案查询...
- 核电站的文件权限管理方法、装...
- 一种用电客户数据的脱敏系统及...
- 基于大数据平台的脱敏方法及系...
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1
众包相关技术
- 一种基于众包的验证信息的识别方法及系统与流程
- 汽车开放系统架构操作系统的任务分配方法及其装置与流程
- 任务分配方法及装置与流程
- 用部分同态加密方案构建的空间众包任务分配系统及方法与流程
- 众包系统中的异构任务执行序列优化方法与流程
- 基于效用优化的认知协作网络联合资源分配方法与流程
- 一种众包环境下物品概念空间的建模方法与流程
- 基于商品定制化的电商平台自动定价方法及系统与流程
- 用于实现对众包隐私的控制的方法和系统与制造工艺
- 基于放置策略的计算资源分配的制造方法与工艺
美团众包相关技术
- 空间众包网络节点位置隐私保护方法
- 一种基于众包指纹分簇和匹配的室内子区域定位方法
- 一种众包数据库下的双向k-匿名方法
- 基于基站历书质量的众包的制作方法
- 一种面向社交网络的基于信任的众包工人筛选方法
- 众包的路径地图的制作方法
- 一种基于众包的软件开发问题自动应答方法
- 用于推断关于实体的元数据的实时众包数据的累积的制作方法
- 使用小型小区众包通信网络中的信息的制作方法
- 一种面向智能服务引擎的任务众包方法