一种基于BM25算法的文本语料库的搭建和优化方法与流程
本发明涉及计大数据技术领域,具体的说,是一种基于bm25算法的文本语料库的搭建和优化方法。
背景技术:
互联网技术的发展带来传统消费的改变,消费者乐于在各种电商平台购买产品,网络言论自由使得消费者更乐于发表意见,由此产生了大量的文本数据,这类数据大致包括传播评价类和意见建议信息。目前有关文本表示的研究主要集中于文本表示模型的选择和特征词选择算法的选取上。在对文本处理文本挖掘带有明显的机器学习色彩,依赖于数据信息抽取、分类、聚类等基础算法和技术。这些内容在数据挖掘领域已大有建树,甚至已发展出不同的算法流派。由于电商评论数据本身具有海量、交叉缠绕、变密度和高维的特点,现阶段文本处理受到分词词典词条有限的影响,分词结果并不理想,加之数据量大无法检验分词的有效性,只能抽样检测,而文本聚类因文本数据维度多对使得技术本身聚类算法得到的维度也有限,无法得到足够的类,这是现阶段文本处理不可避免的问题。
在算法的选取上,多采用相似度评估判断文本处理前后的相关性,本发明涉及的bm25算法便是其中一种,bm25算法是一种用来评价搜索词和文档之间相关性的算法,是检索领域里最基本的一个技术,由词在文档中相关度、词在查询关键字中的相关度以及词的权重三个核心概念组成。根据算法公式知总文档数n和文档长度dl/avgdl直接影响相关性结果分数的高低,足量的包含该词的文档n和合理的文档长度是现阶段文本处理的一个关键影响因素。现阶段算法使用总文档是有现成的文档库的,数量可选,加上算法本身无法对所使用的文档中文档长度dl进行预估判断。导致计算出来的相关性分数是大概率不具备代表性的,因为改动文档数和文档长度都会对结果产生直接影响,故无法准确判断分词效果。因此,现有技术下针对电商评论文本处理和聚类过程中都存在不可逾越的瓶颈。
技术实现要素:
本发明的目的在于提供一种基于bm25算法的文本语料库的搭建和优化方法,用于解决现有技术中针对电商评论文本处理和类聚过程导致的计算结果不具代表性,判断不够准确的问题。
本发明通过下述技术方案解决上述问题:
一种基于bm25算法的文本语料库的搭建和优化方法,所述方法包括如下步骤:
步骤1:由人工进行建立训练语料库,语料库组成来源可以是自写语料或数据库现有资源处理提取;
步骤2:获取一定时间内电商评论数据,进行数据预处理,整理出语料库基础文本;
步骤3:使用bm25算法计算评论语料库基础文本内容与语料库相似度,采用的算法公式为:
其中,q表示query,为断句前的文本;qi表示q解析之后的一个语素,为断句后的文本;d表示一个搜索结果文档,dl为文档d的长度,avgdl为所有文档的平均长度;k1,b为调节因子,k1=2,b=0.75;fi为qi在d中的出现频率;
步骤4:根据i分组相似数据与不关联或低关联数据,对相似数据做频率统计用以观察数据为业务作支持、新增或删减已有语料;对不关联或低关联部分数据使用均值聚类将不存在的语料增加到语料库,完成语料库的优化。
本方法,结合bm25算法,获取相关系数值i,通过先建立有产品及其他维度标识的文本语料库,与处理后的文本数据进行匹配分析,基于相关系数计算得到与语料库关联高和关联低的两部分数据,对相似数据做频率统计用以观察数据为业务作支持、新增或删减已有语料;对不关联或低关联部分数据使用均值聚类将不存在的语料增加到语料库,完成语料库的优化,很好的解决了现有技术中针对电商评论文本处理和类聚过程导致的计算结果不具代表性,判断不够准确的问题。
进一步地,所述步骤3中算法公式由下述公式变换所得:
其中,q表示query,为断句前的文本;qi表示q解析之后的一个语素,为断句后的文本;d表示一个搜索结果文档;wi表示语素qi的权重;r(qi,d)表示语素qi与文档d的相关性得分。
进一步地,所述公式中r(qi,d)的计算方式如下:
其中,k1,k2,b为调节因子,k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在query中的出现频率;dl为文档d的长度,avgdl为所有文档的平均长度;qfi=1,因此公式可以简化为:
进一步地,所述公式中wi表示语素qi的权重,其计算公式如下:
其中,n为索引中的全部文档数,n(qi)为包含了qi的文档数;当n(qi)超过一半的时,分子上的-n(qi)项不需要。
进一步地,当断句前的文本q为中文时,把对query的分词作为语素分析,每个词看成语素qi。
本发明与现有技术相比,具有以下优点及有益效果:
(1)本发明结合bm25算法,获取相关系数值i,通过先建立有产品及其他维度标识的文本语料库,与处理后的文本数据进行匹配分析,基于相关系数计算得到与语料库关联高和关联低的两部分数据。对关联高的部分可选择性添加代表性语料外,还可直接应用于数据分析和支持活动,如可判断评论数据中用户最关注的是哪些维度内容,为后期产品优化和做针对性运营计划提供决策支撑。对关联度低的部分可用于丰富语料和挖掘新的用户关注点。实现了文本数据的有效分析利用并可对业务活动进行支撑,提供了文本数据分类后与业务结合分析的参考。
附图说明
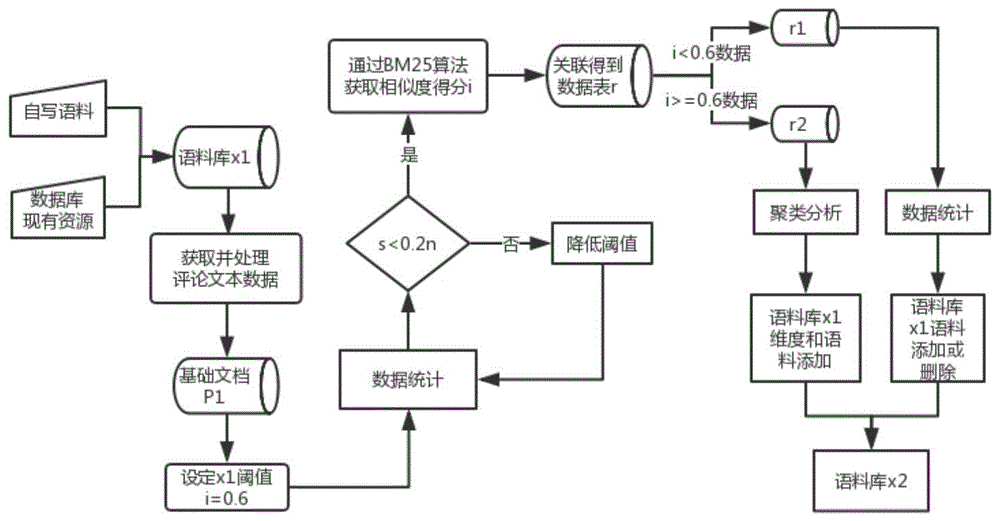
图1为本发明语料库的搭建和优化的方法流程示意图;
图2为本发明的语料库结构示意图。
具体实施方式
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
实施例1:
结合附图1所示,一种基于bm25算法的文本语料库的搭建和优化方法,包括如下步骤:
第一步,由人工进行建立训练语料库x1,语料库组成来源可以是自写语料、数据库现有数据库文本资源处理提取等。语料库包含传播评价类t、意见建议信息s两方面,分别记为tag.t='传播评价类'、tag.s='意见建议类',其中传播评价类主要围绕产品及体验的评价信息进行预料标记,意见建议类主要围绕产品的各个角度的意见建议,如产品外观、质量等以及其他方面如价格、渠道、促销、售前、售后等各方面的建议,针对每个小类按维度进行类别标记,语料的要求是语句尽量是短文本、每类语料维度足够多、不同维度语料含义不交叉,语料内容形式及标记方式如图1示;
第二步,获取一定时间内电商评论数据,进行数据常规预处理,处理脏数据,无效数据等等,使用正则表达式根据标点符号对评论数据断句,常用标点为逗号、空格、叹号、句号、制表符、分号等。由此整理出语料库基础文本p1,含主键、文本内容共2列;
第三步,对语料库x1设定相似度阈值,本发明中设置默认阈值i=0.6(若输出相似度i>=0.6的数量低于总记录数*20%,则根据实际情况降低阈值),设基础文档总记录数为n,相似度i>=0.6的数量为s,即若s<0.2n,进行降低阈值操作;
第四步,使用技术方案中设计的bm25算法的相关性得分公式:
计算基础文本p1中各文本与语料库文档x1中各语料的相似度得分i;
第五步,根据相关新匹配得到p1主键、p1文本内容、p1各文本内容与语料库文档x1关联的语料问呗内容、语料标记(如∈意见建议类产品维度即tag.t.s1)、关联度系数i共4列数据,存于成数据表r;
第六步,基于语料库中相似度设定的阈值,将数据表r中关联度系数i<0.6和i>=0.6的记录分词两个部分r1和r2;
第七步,对r1部分,根据语料标记的tag分组统计评论数据在每种维度中出现的频数进行由高到低的排序,进行数据统计,选择性的添加已有维度中有代表性的文本评论数据或删除已有维度的训练语句;
第八步,对于r2部分,使用k-means及tf-idf算法对文本聚类,基于r语言选择最优k个簇,得到r2部分聚类结果。根据聚类关键词将现语料库x1中不存在的维度加入到语料库x1中,并添加对应的语料语句,经过第七步和第八步形成新的语料库x2作为下一次使用的语料库。
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
- 一种创新需求挖掘方法、系统、...
- 一种基于事理图谱和多因子模型...
- 基于知识图谱的临床试验检索方...
- 生成验证问题组的方法、装置、...
- 一种实体画像的构建方法和装置...
- 文本情感分类方法与流程
- 文本识别方法、装置、电子设备...
- 一种数据处理方法、电子设备及...
- 一种语境集合与回复集合的匹配...
- 一种引入多路选择融合机制的多...
- 还没有人留言评论。精彩留言会获得点赞!
- 文本分类方法和装置的制造方法
- 一种多模型融合的短文本分类方法
- 基于网页链接分析和支持向量机的网页文本分类算法研究的制作方法
- 网页识别方法及网页识别装置的制造方法
- 一种文本分类方法及装置的制造方法
- 一种基于MapReduce的KNN文本分类方法
- 基于概率主题进行短文本分类的方法及系统的制作方法
- 一种文本消息检测算法和基于该算法的个性化网络消息发布监视方法
- 一种基于TF<sup>*</sup>IDF算法的统计学文本分类系统及方法
- 文本分类方法
- 一种基于TF<sup>*</sup>IDF算法的统计学文本分类系统及方法
- 一种用于海量文本快速相似搜索的方法
- 通过计算机实现的计算文本相似度和搜索处理方法及装置制造方法
- 确定短文本相似度的方法和装置制造方法
- 一种确定文本视觉相似度的方法
- 一种基于专家投票的文本相似网络构建方法
- 基于文本内容特征相似度和主题相关程度比较的内容过滤器的制作方法
- 一种用于短文本语义相似度计算的方法
- 一种相似文本检测装置和方法
- 一种基于海量文本数据的相似度衡量方法