一种利用视频外表及动作上的渐进式优化注意力网络机制解决视频问答的方法与流程
本发明涉及视频问答答案生成,尤其涉及一种利用视频外表及动作上的渐进式优化注意力网络来生成与视频相关的问题的答案的方法。
背景技术:
视频问答问题是视频信息检索领域中的一个重要问题,该问题的目标是针对于相关的视频及对应的问题,自动生成答案。
现有的技术主要是针对于静态图像生成相关问题的答案,虽然目前的技术针对于静态图像问答,可以取得很好的表现结果。但是由于视频中信息的复杂性与多样性的特点,简单地把针对于图片的问答技术拓展到视频问答任务中不是十分恰当的。
本发明将使用一种原创的注意力机制来挖掘视频中的外表及动作信息。更为准确地说,本发明提出了一种端对端的模型,该模型可以在问题作为指导的前提下,逐渐利用视频中的外表及动作特征来改善其注意力网络。问题被逐词进行处理直到模型生成了最终的优化注意力模型。最终,视频的权重表达及其他的上下文信息被用来生成最后的答案。
本方法将先利用vgg网络与c3d网络分别提取视频的外表及动作信息。之后逐词分析问题,并且逐渐优化这些特征上的注意力值。在问题的最后一个单词被处理过之后,模型针对于视频形成了最终的优化注意力模型,该模型的注意力值设定对于回答该特定问题是最相关的。之后该模型利用该注意力机制混合外表及动作特征并且提取出视频的最终表达。之后利用该视频的最终表达结合如问题信息及注意力机制历史信息形成最终的答案。
技术实现要素:
本发明的目的在于解决现有技术中的问题,为了克服现有技术中缺少对于视频信息的复杂性与多样性的问题,且针对于视频中经常包含对象物品的外表及其移动信息,本发明提供一种利用视频外表及动作上的渐进式优化注意力网络来生成与视频相关的问题的答案的方法。本发明所采用的具体技术方案是:
利用视频外表及动作上的渐进式优化注意力网络来解决开放式视频问答问题,包含如下步骤:
1、针对于一组视频、问题、答案训练集,通过vgg网络提取视频帧级别的外表特征,通过c3d网络提取视频片段级别的动作特征,通过词嵌入的方法逐词处理问题,将问题的单词转化为对应的语义映射。
2、将问题的单词的语义映射输入到lstm网络中,之后将lstm网络的输出及问题单词的语义映射输入到注意力记忆单元(amu)中来形成并调整视频外表及动作特征上的注意力值,并最终生成视频优化后的表达。
3、利用学习得到的视频表达,获取针对于视频所问问题的答案。
上述步骤可具体采用如下实现方式:
1、对于所给视频,使用预训练的vgg网络获取视频的帧级别的外表特征
2、将问题单词所得到的单词映射xt输入到lstmq这个网络中,认为lstmq这个网络的隐藏层中记录了已经处理的问题部分的历史信息。之后将单词映射xt与lstmq网络的隐藏层状态值
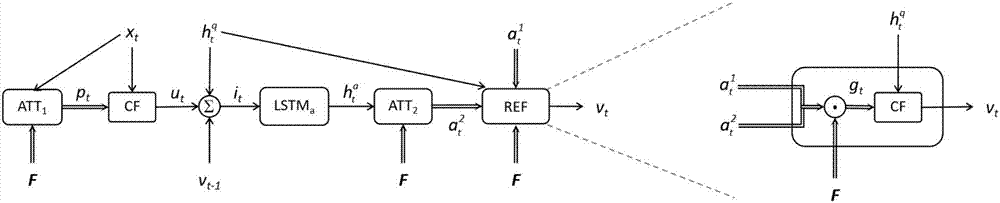
3、对于amu网络,其使用当前单词的映射值,lstmq网络的隐藏层中存储的问题信息及视频的外表及动作特征作为输入,之后执行一定的步骤来优化视频特征的注意力网络。在amu网络中主要有4个操作模块,分别为注意力模块att,频道混合模块cf,记忆模块lstma,优化模块ref。这四个模块与一些转化操作一起,构成了本发明提出的模型的逐渐优化注意力网络机制。下面对于本发明中amu网络的注意力优化机制进行概述。
首先att1模块以当前问题单词的单词映射xt为基础,对于视频的帧级别的外表特征fa与视频的片段级别的动作特征fm构成的视频的特征f初始化其注意力值
下面对于amu网络中各模块的工作原理进行详述。
4、对于注意力模块att,输入问题单词的单词映射表达xt,视频的帧级别的外表特征
ei=tanh(wffi+bf)ttanh(wxxt+bx)
其中,wf与wx为权重矩阵,用来将单词映射及视频特征转化到相同大小的潜在映射空间中;fi代指视频帧级别的外表特征或是视频片段级别的动作特征值,bf与bx为偏置向量。ai为最终求出的权重值,反映了当前单词与第i帧之间的相关程度。且将att1与att2所得到的所有ai构成及集合分别记为
其中,pt包含结合了问题单词信息的视频外表特征
5、对于频道混合模块cf,原理如下。对于得到的特征pt,包含了结合了问题单词信息的视频外表特征
其中,wm为权重矩阵,bm为偏置矩阵,用于将输入的xt转化为二维的向量,分别分配两个维度值给
6、对于记忆模块lstma,首先将lstmq网络的隐藏层状态值
7、对于优化模块ref,利用att1模块的输出
此处的fi代指视频的帧级别的外表特征
通过上述步骤,模型使用了精确处理的单词信息及粗糙处理的问题信息来逐步优化视频的外表及动作特征上的注意力值,待amu网络处理所有问题的单词之后,对于问题的所求答案的最相关及重要的视频的优化表达被形成。
8、得到视频在amu处理过所有问题单词后的混合表达vt后,结合lstmq网络中存储的问题记忆向量
第一种方法为:预先准备一个已经预定义好的答案集合,答案生成器为一个简单的softmax分类器,答案按如下方式生成:
其中,wc与wg为权重矩阵,用于改变输出向量的维度。
第二种方法为:利用lstmq网络中存储的问题记忆向量
附图说明
图1是本发明所使用的利用视频外表及动作上的渐进式优化注意力网络的整体示意图。图2是本发明所使用的amu网络的操作示意图,及本发明使用的amu网络中的优化模块ref的示意图。
具体实施方式
下面结合附图和具体实施方式对本发明做进一步阐述和说明。
如图1所示,本发明利用视频外表及动作上的渐进式优化注意力网络机制来解决视频问答的方法包括如下步骤:
1)对于输入的视频及问题,训练出视频外表及动作上的渐进式优化注意力网络来获取问题相关的联合视频表达;
2)对于步骤1)所得到的问题相关的联合视频表达,利用神经网络获得视频相关问题答案,再与真实的答案进行比较,更新整个注意力网络的参数,得到最终的视频外表及动作上的渐进式优化注意力网络;
3)对于要预测答案的视频和问题,根据生成的视频外表及动作上的渐进式优化注意力网络,得到所预测的答案。
所述的步骤1)采用视频外表及动作上的渐进式优化注意力网络来提取视频及问题的综合表达,其具体步骤为:
1.1)采用卷积神经网络提取视频的帧级别的外表特征及片段级别的动作特征,采用单词映射的方法利用嵌入层将问题单词映射到相应表达;
1.2)利用步骤1.1)找出的问题单词的映射表达,输入到lstmq网络中,得到其隐藏层状态值
1.3)利用步骤1.1)找出的视频的帧级别的外表特征及片段级别的动作特征,问题单词的映射表达,与步骤1.2)找出的lstmq网络的隐藏层状态值
所述的步骤1.1)具体为:
对于所给视频,使用预训练的vgg网络获取视频的帧级别的外表特征
所述的步骤1.3)具体为:
amu网络中主要有4个操作模块,分别为注意力模块att,频道混合模块cf,记忆模块lstma,优化模块ref。利用这4个模块逐渐优化视频的表达。具体步骤如下:
1.3.1)对于注意力模块att,输入问题单词的单词映射表达xt,视频的帧级别的外表特征
ei=tanh(wffi+bf)ttanh(wxxt+bx)
其中,wf与wx为权重矩阵,用来将单词映射及视频特征转化到相同大小的潜在映射空间中;fi代指视频帧级别的外表特征或是视频片段级别的动作特征值,bf与bx为偏置向量;ai为最终求出的权重值,反映了当前单词与第i帧之间的相关程度;且将att1与att2所得到的所有ai构成及集合分别记为
其中,pt包含结合了问题单词信息的视频外表特征
1.3.2)对于频道混合模块cf,原理如下,对于得到的特征pt,包含了结合了问题单词信息的视频外表特征
其中,wm为权重矩阵,bm为偏置矩阵,用于将输入的xt转化为二维的向量,分别分配两个维度值给
1.3.3)对于记忆模块lstma,首先将lstmq网络的隐藏层状态值
1.3.4)对于优化模块ref,利用att1模块的输出
此处的fi代指视频的帧级别的外表特征
则经过t个问题单词的处理之后,视频最终的混合表达为vt。
所述的步骤2)具体为:
对于步骤1.3.4)获得的视频最终的混合表达为vt,结合lstmq网络中存储的问题记忆向量
第一种方法为:预先准备一个已经预定义好的答案集合,答案生成器为一个简单的softmax分类器,答案按如下方式生成:
其中,wc与wg为权重矩阵,用于改变输出向量的维度;
第二种方法为:利用lstmq网络中存储的问题记忆向量
随后将生成的答案与训练数据中真实答案在相同位置的单词做比较,根据比较的差值更新注意力网络。
下面将上述方法应用于下列实施例中,以体现本发明的技术效果,实施例中具体步骤不再赘述。
实施例
本发明一共构建了两份数据集,分别为msvd-qa数据集和msrvtt-qa数据集,其中msvd-qa数据集包含1970条视频片段及50505个问答对,msrvtt-qa数据集包含10k条视频片段及243k个问答对。随后本发明对于构建的视频问答数据集进行如下预处理:
1)对于msvd-qa数据集和msrvtt-qa数据集中的每一个视频取20个平均均匀分布的帧和片段,随后对于提取的帧和片段利用预训练好的vggnet与预训练好的c3dnet处理,其最后一个全链接层的激活函数输出作为相应提取出来的特征,在每一个频道中的特征数为20,每一个特征的维数为4096。
2)对于问题的单词使用嵌入层进行转换,本发明利用预处理号的300维的glove网络来将问题单词映射为所需的单词映射,本发明中令lstmq的大小为300来匹配上单词映射的维度。
3)对于amu模块,本发明选择256作为其公共维度大小,视频的特征与单词的映射均要匹配到这一潜在公共空间之中,并且本发明中令lstma的大小为256。
4)本发明使用预定义的1000答案分类的softmax选择来生成视频问题的对应答案。
5)本发明从训练数据集中选择最常见的单词作为单词表,msvd-qa数据集选择了4000个单词,msrvtt-qa数据集选择了8000个单词。
6)本发明使用mini-batch的随机梯度下降方法优化模型,并且使用了学习率为默认值0.001的adam优化器,所有的模型均被训练最多30个循环,使用了早期停止技术,为了更有效地操作不同长度的问题,本发明将问题按照问题长度分为不同的组,msvd-qa数据集中共4组,msrvtt-qa数据集中共5组,在每一组中,问题均要转换为该组中的最长问题的长度。所有模型的loss函数为:
其中,n为批数据集的大小,m为可能的答案数目,yi,j为二维指示器用来指出答案j是否为例子i的正确答案,pi,j为本发明将答案j被指定给例子i的概率大小,第二项为l2正则项,wk代表模型权重,λ1为控制正则项重要性的超参数。
7)为了更有效地训练本发明中的模型,本发明在6)中的loss函数的基础上添加一项来鼓励模型从不同的频道运用特征:
其中,n代表批数据集大小,
为了客观地评价本发明的算法的性能,本发明在所选出的测试集中,使用了accuracy来对于本发明的效果进行评价,且分别对于数据集中不同种类的问题进行结果的求取。按照具体实施方式中描述的步骤,所得的实验结果如表1-表2所示:
表1本发明针对于msvd-qa数据集不同种类问题的测试结果
表2本发明针对于msrvtt-qa数据集不同种类问题的测试结果。
- 一种基于向量空间模型的中文虚...
- 一种管理系统平台化入口的方法...
- 一种基于iframe的页面加...
- 一种访问数据库记录的方法和系...
- 电子病历检索方法及装置、电子...
- 题目搜索方法、装置及设备与流...
- MySQL分区自动管理方法、...
- 基于标签库的营销客户筛选方法...
- 一种智能问答方法及其系统与流...
- 页面展示方法、装置、计算机设...
- 还没有人留言评论。精彩留言会获得点赞!