一种文本相似度检测方法与流程
本发明涉及一种文本相似度检测方法,属于自然语言处理技术领域。
背景技术:
当前,很多学习资料存储在大规模数据中心。然而,在数据中心充斥着大量重复或相似的文件,这对数据中心的存储空间和搜索引擎的数据检索都造成了一定的影响。
simhash是目前主流的近似文本检测算法,但是使用simhash进行文本相似度检测仍存在很多问题,比如对短文本检测的准确性很差,而且simhash在生成指纹的过程中涉及多次降维,可能会使一些有效信息丢失。
技术实现要素:
本发明提供了一种文本相似度检测方法,以用于解决simhash算法对短文本的支持性差、生成指纹过程中有效信息丢失等现象,增加文本相似度检测的准确性与可靠性。
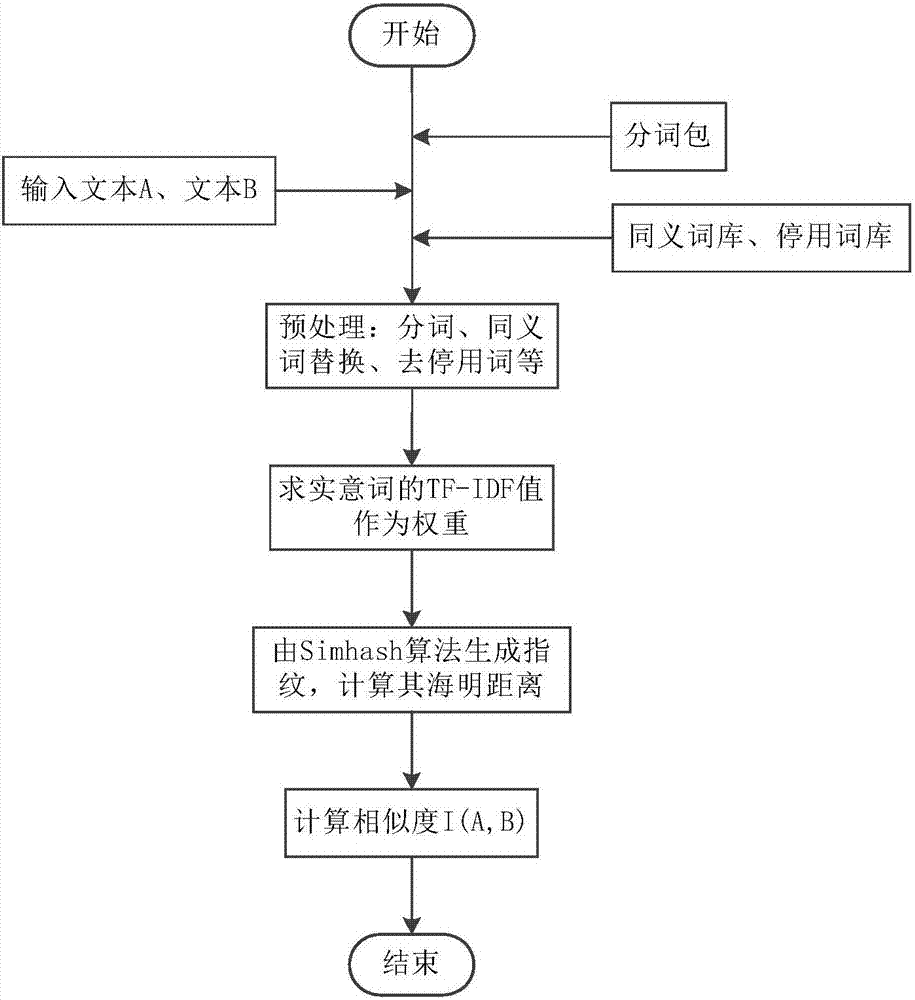
本发明的技术方案是:一种文本相似度检测方法,所述方法的具体步骤如下:
step1、输入文本a和文本b;
step2、对文本a和文本b进行预处理,得其实意词;对文本a和文本b的实意词分别求其tf-idf值作为该实意词的权重;根据权重由simhash算法分别对文本a和文本b的实意词生成其长度为l1的simhash指纹,并计算两者的海明距离h1;由海明距离h1及生成指纹的长度l1,计算出基于simhash算法的文本a和文本b的相似度i(a,b);
step3、对文本a和文本b进行预处理,得其实意词;运用n-gram语言模型,得出文本a和文本b的2-gram集合;对2-gram集合中每个组合词求其tf-idf值作为该组合词的权重;根据权重由simhash算法分别对文本a和文本b的2-gram集合生成其长度为l2的simhash指纹,并计算两者的海明距离h2;由海明距离h2及生成指纹的长度l2,计算出基于n-gram语言模型和simhash算法的文本a和文本b的相似度j(a,b);
step4、求文本a和文本b的最长公共子串;由最长公共子串的长度l3和文本a的长度la,以及文本b的长度lb,计算出基于最长公共子串的文本a和文本b的相似度z(a,b);
step5、设step2、step3、step4步骤所计算出的相似度对应权值分别为i、j、z,权值i、j、z满足i+j+z=1的要求,由相似度i(a,b)及权值i、相似度j(a,b)及权值j、相似度z(a,b)及权值z,计算文本a和文本b的最终相似度r(a,b)=i(a,b)×i+j(a,b)×j+z(a,b)×z。
所述步骤step1中,所述输入文本a和文本b为短文本。
所述步骤step2及步骤step3中对文本a和文本b进行预处理,预处理包括分词、同义词替换、去停用词;分别使用分词包、同义词库和停用词库进行分词、同义词替换、去停用词。
所述步骤step2中,计算文本a和文本b的相似度i(a,b)的公式为:
所述步骤step3中所述的计算文本a和文本b的相似度j(a,b)的公式为:
所述步骤step4中所述的计算文本a和文本b的相似度z(a,b)的公式为:
本发明的有益效果是:本发明引入n-gram语言模型和最长公共子串等对simhash算法进行改进。首先用常规的simhash算法对文本进行相似度计算;然后引入n-gram语言模型对文本关键词进行组合,使关键词具有上下文衔接关系,再次用simhash算法对文本进行相似度计算;其次,又引入最长公共子串作为评判相似的标准之一,对文本进行相似度计算;最后,给予以上计算所得的相似度相应的权值,进行最终相似度的叠加计算。本发明与现有技术相比,主要解决了simhash算法对短文本的支持性差、生成指纹过程中有效信息丢失等现象,增加文本相似度检测的准确性与可靠性。
附图说明
图1是本发明总流程图;
图2是本发明步骤step2详细流程图;
图3是本发明步骤step3详细流程图;
图4是本发明步骤step4详细流程图;
图5是本发明步骤step5详细流程图。
具体实施方式
实施例1:如图1-5所示,一种文本相似度检测方法,所述方法的具体步骤如下:
step1、输入文本a和文本b;
文本a的内容为“小明,你的小伙伴喊你去体育场打篮球,之后顺便一块儿吃晚饭!”,文本b的内容为“小明,你的小伙伴叫你去操场打橄榄球,之后再一起吃晚饭!”。
step2、对文本a和文本b进行预处理,得其实意词;对文本a和文本b的实意词分别求其tf-idf值作为该实意词的权重;根据权重由simhash算法分别对文本a和文本b的实意词生成其长度为l1的simhash指纹,并计算两者的海明距离h1;由海明距离h1及生成指纹的长度l1,计算出基于simhash算法的文本a和文本b的相似度
对文本进行预处理后,文本a的实意词为“小明/你/小伙伴/喊/你/去/操场/打篮球/之后/顺便/一起/吃晚饭/”,文本b的实意词为“小明/你/小伙伴/喊/你/去/操场/打/橄榄球/之后/再/一起/吃晚饭/”。
计算tf-idf值的一个步骤,要以文本集作为参考,具体的以本地100篇现代小说作为计算文本a、文本b的实意词的tf-idf值的文本集,由文本a、文本b的实意词的tf-idf值和128位simhash算法生成simhash指纹,文本a实意词所生成的simhash指纹为:
01011110111100111000010001111011011000100100111110111011000011010100100100110110000101001011100011010110100110010101100110111101
文本b实意词所生成的simhash指纹为:
01011010101000011100101110111010101010001101100111111111101011111100110001110111000111011000000011110100110101011110101000111110
得其海明距离h1=48,再由公式
step3、对文本a和文本b进行预处理,得其实意词;运用n-gram语言模型,得出文本a和文本b的2-gram集合;对2-gram集合中每个组合词求其tf-idf值作为该组合词的权重;根据权重由simhash算法分别对文本a和文本b的2-gram集合生成其长度为l2的simhash指纹,并计算两者的海明距离h2;由海明距离h2及生成指纹的长度l2,计算出基于n-gram语言模型和simhash算法的文本a和文本b的相似度
对预处理后的文本实意词运用n-gram语言模型,得出文本a和文本b的2-gram集合,分别为“小明你/你小伙伴/小伙伴喊/喊你/你去/去操场/操场打篮球/打篮球之后/之后顺便/顺便一起/一起吃晚饭/”和“小明你/你小伙伴/小伙伴喊/喊你/你去/去操场/操场打/打橄榄球/橄榄球之后/之后再/再一起/一起吃晚饭/”。
同样以本地100篇现代小说作为计算文本a、文本b的2-gram集合的tf-idf值的文本集,由文本a、文本b的2-gram集合的tf-idf值和128位simhash算法生成simhash指纹,文本a的2-gram集合所生成的simhash指纹为:
00101111011011010011110100010111110010100110010000110010011010110001001010110011111010100001010001001101110110011100000111101100
文本b的2-gram集合所生成的simhash指纹为:
10100111011010111001110100010111110000100110010001001011010001111101001010110011101111110101010011001101110010011100010111001100
得其海明距离h2=25,再由公式
step4、求文本a和文本b的最长公共子串;由最长公共子串的长度l3和文本a的长度la,以及文本b的长度lb,计算出基于最长公共子串的文本a和文本b的相似度z(a,b);具体的:
求文本a和文本b的最长公共子串,为“小明你小伙伴喊你去操场打”,由公式
step5、设step2、step3、step4步骤所计算出的相似度对应权值分别为i、j、z,权值i、j、z满足i+j+z=1的要求,由相似度i(a,b)及权值i、相似度j(a,b)及权值j、相似度z(a,b)及权值z,计算文本a和文本b的最终相似度r(a,b)=i(a,b)×i+j(a,b)×j+z(a,b)×z,具体的:
设相似度i(a,b)、j(a,b)、z(a,b)分别对应权值i=0.3、j=0.6、z=0.1,由公式r(a,b)=i(a,b)×i+j(a,b)×j+z(a,b)×z计算文本a和文本b的最终相似度:
r(a,b)=i(a,b)×i+j(a,b)×j+z(a,b)×z
=62.5%×0.3+80.47%×0.6+52.17%×0.1
=72.24%
由以上结果可以表明,最终计算所得相似度为72.24%,相对于常规simhash算法计算所得62.5%来讲,有一定程度上的提升,特别是针对短文本(小于200字)来讲。并且,因为计算tf-idf值的文本集与最终结果有很大关系,所以在实际应用中应尽可能使文本集中的内容丰富、类别广泛,以提高检测准确性。再者,关于相似度i(a,b)、j(a,b)、z(a,b)对应权值i、j、z的取值,应以不同类型文本多次检测、适当调整后合理取值。
上面结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 一种大数据处理系统的制作方法
- 一种舆情事件挖掘方法和系统与...
- 基于数据库的数据透视方法、装...
- 一种征信数据的采集方法及系统...
- 基于车载系统的搜索方法和装置...
- 信息推荐系统及方法与流程
- 用户意图自动识别方法及装置与...
- 一种客户端应用平台的统计方法...
- 一种地震应急和灾情信息获取分...
- 业务数据识别码生成系统的制作...
- 还没有人留言评论。精彩留言会获得点赞!
- 文本相似度的计算方法及系统、相似文本的查找方法及系统的制作方法
- 一种文本相似度检测方法
- 一种相似视频的确定方法及装置制造方法
- 路径相似度计算方法和装置制造方法
- 一种基于相似度计算方法的数据排列方法
- 一种确定文本视觉相似度的方法
- 一种网页相似度计算方法及装置制造方法
- 文本相似度、词义相似度计算方法和系统及应用系统的制作方法
- 一种基于万有引力的文本相似度计算方法
- 一种计算xml文档相似度的方法
- 改进的基于语义分析的文本相似度求解算法的制造方法与工艺
- 一种改进的文本相似度求解方法与制造工艺
- 一种改进的词汇语义相似度求解算法的制造方法与工艺
- 基于新统计的词汇语义相似度求解算法的制造方法与工艺
- 基于随机近邻嵌入的文本聚类方法
- 网页相似度计算方法及装置的制造方法
- 一种句子相似度的计算方法及系统的制作方法
- 一种基于lcs的自定义元素顺序优化方法
- 基于相似日聚类的微电网光伏出力空间预测方法
- 一种基于可读性指标的信息检索方法