基于Spark的并行化随机标签子集多标签文本分类方法与流程
本发明涉及信息技术、云计算、数据挖掘、文本分类等领域,提供了一种基于Spark大数据平台的并行化随机标签子集多标签文本分类算法。
背景技术:
随着信息技术的发展,互联网数据规模呈海量增长,表现形式也不断丰富。文本作为重要的信息载体,其自动分类技术的发展能够提高对海量信息的处理效率,节约处理时间,方便用户的使用,近年来得到广泛的关注和快速的发展。传统有监督学习认为每个样本只具有一个标签,缺乏准确表述事物的复杂语义信息的能力。但是一个样本可能对应与之相关的多个标签,例如文本信息往往同时拥有多个语义,比如一个文本信息可能同时与计算机、机器学习、经济、社会效益等相关联。有效明确解释事物具有的多个语义的一个直接方法就是给一个事物标注多个标签,因此多标签学习(Multi-Label Learning)也应运而生。在多标签学习中,每个样本可能包含一个或多个标签,被多个标签标注的样本能够更好的表现事物语义信息的多样性,也能够使其分类更具现实意义。
随机标签子集多标签(ECC)算法是多标签分类算法的一种,其核心思想为将多标签学习问题转换为多个随机标签子集的学习过程。该算法考虑了标签之间的关联性并且加入了随机因素,在实际使用中分类效果很好。但由于训练阶段需要对于同一样本集进行多个随机标签子集进行多次训练,构建多个训练模型;预测阶段需要使用训练阶段构建的多个模型进行多次预测过程,因此时间复杂度和空间复杂度较高,随着数据量的增大,采用传统串行算法难以应对规模越来越大的数据集,出现运行时间过长,内存溢出等情况,不能满足工程需求。近几年来,大数据技术的发展为解决此类问题提供了理想的条件和思路。
Spark是一个基于内存的分布式计算系统,是由UC Berkeley AM P Lab实验室于2009年开发的开源数据分析集群计算框架。拥有MapReduce的所有优点,与MapReduce不同的是.Spark将计算的中间结果数据持久地存储在内存中,通过减少磁盘I/O,使后续的数据运算效率更高。Spark的这种架构设计尤其适合于机器学习、交互式数据分析等应用.这些应用都需要重复地利用计算的中间数据。在Spark和Hadoop的性能基准测试对比中,运行基于内存的logistic regression,在迭代次数相同的情况下,Spark的性能超出Hadoop MapReduce 100倍以上。两者之间在计算过程中也存在一些不同之处,比如MapReduce输出的中间结果需要读写HDFS,而Spark框架会把中间结果保存在内存中。这些不同之处使Spark在某些工作负载方面表现得更加优越,换句话说,Spark启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。而弹性分布式数据集(RDD,Resilient Distributed Datasets)是Spark框架的核心数据结构,它具备像MapReduce等数据流模型的容错特性,并且允许开发人员在大型集群上执行基于内存的计算。Spark将数据集运行的中间结果保存在内存中能够极大地提高性能,资源开销也极低,非常适合多次迭代的机器学习算法。
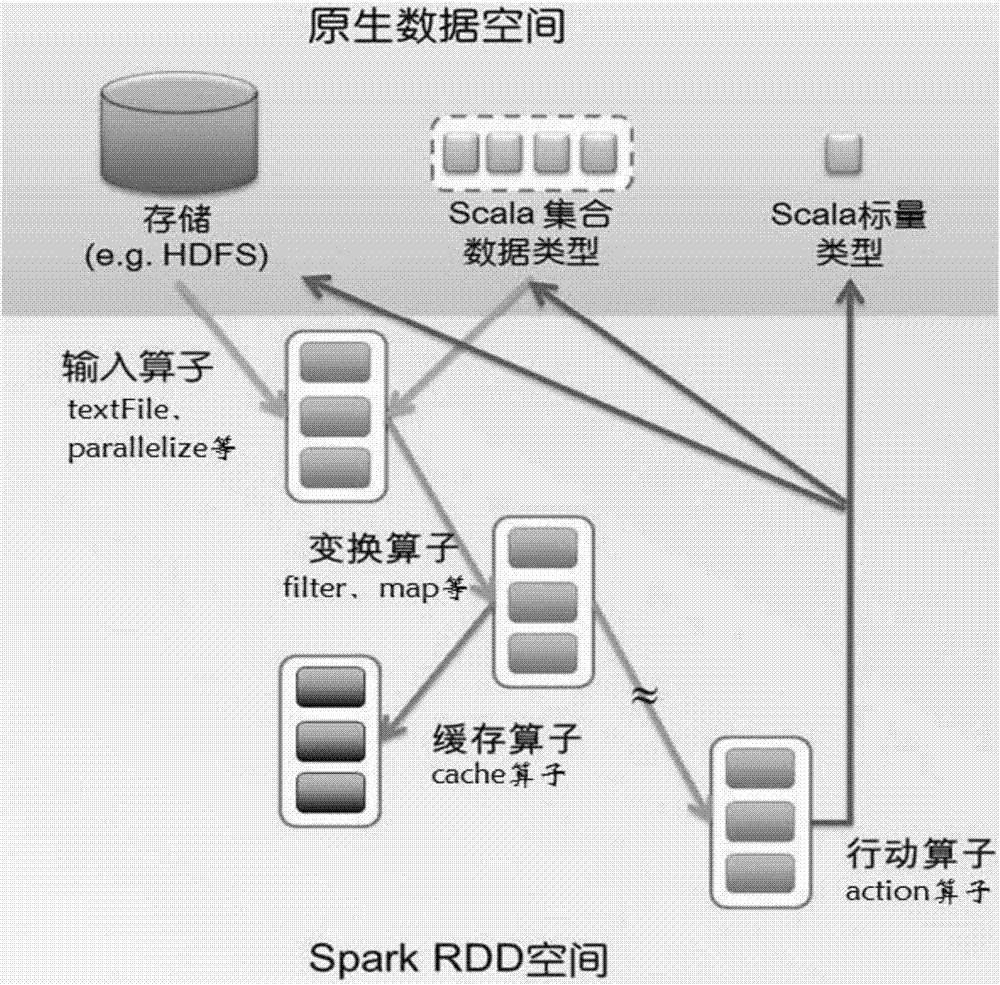
弹性分布式数据集(RDD)是Spark的核心数据结构。这个数据集的全部或部分可以缓存在内存中,在多次计算间重用。传统的MapReduce虽然具有自动容错、平衡负载和可拓展性的优点,但是其最大缺点是采用非循环式的数据流模型,使得在迭代计算式要进行大量的磁盘IO操作。RDD正是解决这一缺点的抽象方法。通过RDD,Spark可以基本一致的应用于不同的大数据处理场景,如MapReduce,实时流数据,SQL,Machine Learning和图计算等。RDD是一个容错的、并行的数据结构,可以显式的将数据存储在内存和磁盘中,并且能够控制数据的分区状态。RDD还提供了一系列操作接口,用户通过这组接口,可以方便的操作其中的数据。
RDD可以由包括本地文件系统,HDFS,HBase,Hive等任何被Hadoop支持的存储源创建,也可以通过Scala内存数据集合创建。在创建RDD后,用户可以设置RDD的存储级别,将RDD缓存在内存或磁盘中,下次重复使用时就不需重新计算,提高程序性能。RDD支持的操作可以分为转换操作和行动操作两种类型,其中转换操作从现有的RDD产生一个新的RDD,行动操作在RDD上执行某种计算返回一个结果值。随着Spark技术的产生与发展,为了适应大数据应用的要求,很多机器学习和数据挖掘领域的算法被设计应用于Spark平台,获得了成倍的性能提升。本发明通过将Spark大数据处理技术和随机标签子集多标签方法相结合,有效的解决了串行随机标签子集算法在大规模多标签文本分类应用中算法时空复杂度较高、内存溢出、难以在有效时间内得到结果等不足,提高了分类效率与精度。
经过对现有技术的文献检索发现,文章Zhu B,Mara A,Mozo A.CLUS:Parallel Subspace Clustering Algorithm on Spark[M]//New Trends in Databases and Information Systems.Springer International Publishing,2015:175-185.将子空间聚类算法基于Spark并行化实现,应用于大数据集获得了较大的速度提升。文章Jesus Maillo,Sergio Ramírez,Isaac Triguero,et al.kNN-IS:An Iterative Spark-based design of the k-Nearest Neighbors Classifier for Big Data[J].Knowledge-Based Systems(2016),doi:10.1016/j.knosys.2016.06.012提出了一种基于Spark的迭代精确K最近邻算法,该算法充分利用Spark内存计算的机制,性能比使用Hadoop MapReduce实现的相同算法提高了将近十倍。文章Kim H,Park J,Jang J,et al.DeepSpark:Spark-Based Deep Learning Supporting Asynchronous Updates and Caffe Compatibility[J].2016.结合深度学习技术、Spark大数据处理技术和GPU加速等技术,开发出一套运行于Spark上的深度学习框架。文章Duan M,Li K,Tang Z,et al.Selection and replacement algorithms for memory performance improvement in Spark[J].Concurrency&Computation Practice&Experience,2015.提出了一种在内存不足的情况下自动缓存合适的RDD的选择和替换算法,进一步提高了Spark程序的性能。
技术实现要素:
本发明针对现有多标签分类技术存在的从海量的文本构造的数据集进行分类时容易内存溢出、时间过长和无法运行宕机等缺点,结合Spark分布式技术,有效挖掘了待分类多标签文本样本标签之间的关联。提出了一种提高了分类的精度、能够大幅降低处理大规模多标签数据的学习时间方法。本发明的技术方案如下:
一种基于Spark的并行化随机标签子集多标签文本分类方法,其包括以下步骤:
首先,从HDFS上获取来自互联网的大规模文本数据集和配置信息文件,所述大规模文本数据集包括训练数据集和预测数据集,通过Spark API提供的textFile方法将训练数据集、预测数据集、配置信息文件转换成Spark平台的分布式数据集RDD,完成初始化操作;
其次,并行地随机生成规定数目的标签子集,由原始训练集为每一个标签子集生成一个新的训练集,该训练集特征为原始训练集的全部特征,新训练集中的标签仅保留对应标签子集中包含的标签;
再次,对于每一个新生成的训练集,将训练集的多个标签通过标签幂集法转换为单个标签,将新生成的训练集转化为一个单标签多类数据集,并行地为这些数据集训练一个基分类器;
然后,使用训练好的基分类器形成预测模型对测试集进行预测,将得到的单标签多类预测结果转化为多标签结果;
最后,将所有预测结果进行汇总投票,得到测试集最终的多标签预测结果,完成文本分类。
进一步的,所述转换成Spark平台的分布式数据集RDD的步骤包括:创建一个SparkContext对象,然后用它的textFile函数创建分布式数据集RDD,一旦创建完成,这个分布式数据集就可以被并行操作,算法最开始还需输入数据集的标签个数L、标签子集标签数n和和要生成的模型数m。
进一步的,所述并行地随机生成规定数目的标签子集,由原始训练集为每一个标签子集生成一个新的训练集,包括步骤:
(1)通过SparkContext对象的parallelize函数创建一个RDD,该RDD分区数为m,每个分区包含标签全集,通过RDD的map转化操作对每个分区的标签全集随机抽样,将标签全集转换为一个包含n个标签的随机标签子集,得到RDD1;
(2)通过collect行动操作将训练集RDD变为一个本地集合,对RDD1进行map操作,使该RDD的每个分区包含一个随机标签子集和训练集全集的二元组,得到RDD2;
(3)通过map操作对RDD2每个分区的训练集的标签进行过滤,只留下与之对应的标签子集中包含的标签,得到RDD3。
进一步的,所述对于每一个新生成的训练集,将训练集的多个标签通过标签幂集法转换为单个标签,该数据集转化为一个单标签多类数据集,并行地为这些数据集训练一个基分类器,包括以下步骤:
(1)通过mapPartitions操作,并行地对RDD3的每个分区的训练集执行标签幂集算法,对于训练集的多个标签进行变换,将这些标签转换为一个标签,原始训练集由多标签数据集转换为了单标签多类数据集,得到RDD4;
(2)对RDD4继续执行mapPartitions操作,在其每一个分区上初始化一个单标签基分类器,其中基分类器类型由配置文件指定,将分区上的单标签多类数据集输入基分类器中进行训练,生成预测模型,返回一个由随机标签子集和预测模型组成的二元组,得到RDD5;
(3)对RDD5执行cache操作,将其缓存在内存中。
进一步的,所述使用训练好的基分类器对测试集进行预测,将得到的单标签多类预测结果转化为多标签结果,包括以下步骤:
I.对于每个样本x,生成2个长度为L的double类型数组Sum、Votes,分别保存样本的预测标签集合以及所有的模型对每个标签的投票;
II.采用生成的多标签模型hi对每个样本分别进行预测,i=1,2,3...n,每个多标签模型对应一个随机标签子集,根据生成的随机标签子集对待预测样本进行预处理,随机地生成k个标签构造LabelSet对象,LabelSet和特征组合一起作为模型的输入;
Votesj←Votesj+1 (2)
III.根据公式(1)和公式(2)更新Sum和Votes,即当模型预测某个标签的输出为1时,标签索引对应的Sum数组元素的值加1,Votes不管模型输出为1还是0,标签索引对应的值都加1;
avgj=Sumj/Votesj (3)
IV.聚合所有的模型输出,保存每个样本的预测结果(id,confidence,predcitLabel),根据公式(3)算出每个样本的置信度,若置信度大于0.5,则样本属于该标签,否则样本不属于该标签。
本发明的优点及有益效果如下:
本发明结合了Spark大数据平台技术和多标签分类技术,一方面,有效挖掘了待分类多标签样本标签之间的关联,提高了分类的精度。另一方面,采用Spark分布式技术,又能够大幅降低处理大规模多标签数据的学习时间,有效解决大规模多标签数据集在机器学习和模式识别领域中的文本分类问题。
附图说明
图1是本发明提供优选实施例基于Spark大数据平台的并行化随机标签子集多标签文本分类方法示意图;
图2RDD操作示意图;
图3多标签分类算法总结。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、详细地描述。所描述的实施例仅仅是本发明的一部分实施例。
本发明解决上述技术问题的技术方案是:
本发明提供的基于spark大数据平台的并行化多标签文本分类方法-随机标签子集法,包括如下3个过程:
1.针对对随机标签子集算法的特点构建多标签数据集;
为了体现并行算法的高效性和随机标签子集方法的分类效果,分别从标签的数量和样本数量两个角度从mulan官网选取了文本数据集EUR-Lex(directory codes),该数据集的每个样本由5000维的词语描述,关于该数据集的详细刻画如表1所示;
①随机标签子集算法根据子集大小k随机地从标签空间中选取k个标签训练n个多标签幂集模型,模型的个数可以自定义,最大值为标签个数L和子集大小k的组合系数默认情况下为标签个数L的2倍。针对EUR-Lex(directory codes)数据集,本实施案例的算法参数k设为3,模型个数n取默认标签个数L的2倍162;
②根据上述的模型个数n和子集大小k,首先初始化一个spark上下文对象sc,利用sc对象的parallelize方法将一个包含1到162的自然数的本地集合变为弹性分布式数据集RDD,利用map等高阶方法把RDD的每个元素转换为一个个的标签子集元组(id,subset),id为模型的序号,subset为每次随机地选取的标签序号;
③每个worker节点在训练模型的时候需要训练集所有样本的特征和该模型需要的标签子集,因此需要在所有的计算节点上广播整个训练集,每个worker节点根据步骤1-②分配的标签子集进行预处理,即保留每个样本的所有特征,保留标签子集中包含的标签,过滤掉标签子集不需要的标签,经过预处理之后得到标签子集对应的数据集;
构造多标签数据集的子集元组需要保存下来,后续的样本预测时需要对测试集做同样的处理;
2.基于步骤1的多标签数据集,利用spark并行计算的优势,训练多个多标签幂集分类器;
步骤1结束之后每个分区里面缓存了标签子集对应的训练数据,利用mappartitions方法,在每个分区内初始化一个标签幂集分类器。标签幂集分类模型需要传入一个基分类器,这里所有的模型都选择J48分类器作为基分类器。在构造模型之前标签幂集算法需要整个数据集的标签集合,把步骤1的多标签数据集转换为标签幂集算法可处理的数据如下;
①首选根据数据集特征个数和子集大小k产生一个本地序列集合,结合本数据集产生的序列为labelindex={501,502,503};
②生成一个空的哈希表和保存每个样本标签子集的列表,哈希表存储的为LabelSet对象,列表的元素为(id,LabelSets),id为每个样本的编号,Labelsets为每个样本的标签集合对应的Labelset对象,对该分区的每个样本进行map操作,把样本的标签子集集合构造为labelset对象,并加入到哈希表中和标签子集列表中;
③把哈希表中的数据设置为该数据集对应的标签的枚举值,过滤掉所有样本的标签,此时每个样本的纬度为5000维;
④对步骤③的样本和步骤②的标签子集列表join操作,构成标签幂集所需的数据集,设置标签索引,即可用于构造多标签幂集算法的数据集;
3.获取多标签数据集预测结果;
①用测试集所有的样本构造元组(id,Instance);
②通过parallelise方法把上述集合变为RDD,然后对RDD的每个元素进行map操作,返回一个三元组(id,confidence,predcitLabel),id为样本的编号,predcitLabel为样本的预测标签集合,confidence为样本属于每一个标签的概率,predcitLabel,confidence均为长度为L的数组;该步骤的详细描述如下:
I.对于每个样本,生成2个长度为L的double类型数组sumVotes、lengthVotes,分别保存每个样本的标签集合以及所有的模型对每个标签的投票;
II.sumVotes和lengthVotes的区别在于:当模型预测某个标签的输出为1时,标签索引对应的sumVotes数组元素的值加1,lengthVotes不管模型输出为1还是0,标签索引对应的lengthVotes数组元素的值都加1;
③步骤2生成的n个多标签模型对每个样本分别进行预测,每个多标签模型都对应一个标签子集,根据步骤1-②产生的随机标签子集对待预测的样本进行预处理,随机地生成k个标签构造LabelSet对象,LabelSet和样本的特征组合一起作为模型的输入,每个模型都对样本产生一个输出;
聚合所有的模型输出,保存每个样本的预测结果(id,confidence,predcitLabel)。每个样本的sumVotes、lengthVotes对应位置的值相除作为样本的置信度,如置信度大于0.5,则样本属于该标签,否则样本不属于该标签。
表1
以上这些实施例应理解为仅用于说明本发明而不用于限制本发明的保护范围。在阅读了本发明的记载的内容之后,技术人员可以对本发明作各种改动或修改,这些等效变化和修饰同样落入本发明权利要求所限定的范围。
- 一种作文素材共享教学系统及其...
- 一种用于精确高效统计法兰接口...
- 一种基于索张力不确定性的平面...
- 一种可配置Portal框架的...
- 一种网页收藏的无效网页处理方...
- 一种M‑UCA估计M‑1个信...
- 一种稿件发布方法和装置与流程
- 一种拟人机器人客服方法与流程
- 一种合体裤样板个性化设计的方...
- 信息推送方法和装置与流程
- 还没有人留言评论。精彩留言会获得点赞!
- 一种基于快速分裂算法的节点迁移网络分块优化方法与流程
- 并行化二维流场多元数据动态可视化系统的制作方法与工艺
- 一种基于GN分裂算法的节点迁移网络分块优化方法与流程
- 基于FPGA的FP‑Growth算法的改进方法及装置与流程
- 基于Spark的并行化随机标签子集多标签文本分类方法与流程
- 一种含多VSC的多速率电磁暂态分网方法与流程
- 一种并行化的文本聚类方法与流程
- 一种基于MPI的ML‑KNN多标签中文文本分类方法与流程
- 一种Hog并行化设计方法及系统与流程
- 一种毛细力驱动的测试卡的制作方法与工艺
- 一种批量升级epon中onu的系统及其方法
- 用于吉比特无源光网络的分段重组方法
- 适合连续变量量子密钥分发的高速秘密协商方法
- SerDes中高速串行信号的并行化处理方法及装置制造方法
- 一种基于分布存储和并行计算的电网数据质量检测方法
- 一种并行化矩阵求逆硬件装置的实现方法
- 一种资源分配方法
- 基于系统级诊断信息的负载衡量方法
- 一种分布式环境中空间分析方法的计算代价编码方法
- 一种基于OpenCL的红黑树加速算法