一种基于TLSH特征表示的恶意软件聚类方法与流程
本发明涉及恶意软件分析技术领域,具体为一种基于TLSH特征表示的恶意软件聚类方法。
背景技术:
恶意软件是指在未明确提示用户或未经用户许可的情况下,在用户计算机或其他终端上安装运行,侵害用户合法权益的软件,是威胁信息安全的主要形式之一。近年来,恶意软件家族变种呈爆发式增长,据赛门铁克公司发布的《互联网安全威胁报告》统计,2014年恶意软件新增变种3.17亿,2015年则达到了4.31亿,同比增长约36%。显然,人工分类手段已经无法有效的应对这些海量数据,恶意软件的自动分类日益成为研究的热点。
针对恶意软件的研究主要包含以下四个方面:恶意软件的特征提取、特征表示、聚类算法的选择及优化、聚类效果评估。Yanfang等人通过静态分析方法提取样本指令序列及频度,集成tf-idf及k-medoids的聚类方法实现分类(Automatic malware categorization using cluster ensemble[A].ACM,2010.95-104.)。Cesare等人利用信息熵检测恶意软件是否加壳,并对加壳软件进行脱壳。然后从生成汇编代码中提取控制流程图作为样本特征,再通过近似图匹配算法实现恶意代码的分类(an effective and efficient classification system for packed and polymorphic malware[J].IEEE Transactions on Computers,2013,62(6):1193-1206.)。徐小琳等人实现了基于特征聚类的海量恶意代码在线自动分析模型,该模型主要由特征空间构建、自动特征提取及快速聚类分析3个部分组成,其中特征空间构建部分提出了基于统计和启发式的代码特征空间构建方法,自动特征提取部分提出了由API行为和代码片段构成的样本特征向量描述方法,快速聚类分析部分提出了基于位置敏感散列(LSH,locality-sensitive hashing)的快速近邻聚类算法(基于特征聚类的海量恶意代码在线自动分析模型[J].通信学报,2013,34(8):147-153.)。Ahmad Azab等人通过计算二进制文件的模糊哈希值,然后使用K-NN算法进行聚类。通过实验对比发现使用TLSH(The Trend Locality Sensitive Hash)生成的模糊哈希值有较好的效果(Mining Malware To Detect Variants.IEEE Computer Society[J],2014:44-53)。Guanghui Liang等人将程序活动行为分为:文件操作、进程行为、注册表行为、网络行为、服务行为以及获取系统信息等6种,使用6元祖(类型、名称、输入参数、输出参数、返回值、下一调用)来描述一个行为结点,最后建立起一个行为依赖链,通过计算jaccard距离,来计算相似度进行聚类(A Behavior-Based Malware Variant Classification Technique[C].International Journal of Information and Education Technology[J],2016,6(4):291-295)。
综合来看,这些方法存在以下缺陷:首先,特征的提取不够全面,没有结合动态和静态分析各自的优点进行提取。特征的表示要么过于依赖人力,要么就是通过统计进行了删减,同时由于维度过高,将导致聚类缓慢。其次,在聚类算法的选择上,使用K-MEANS这种基于划分的聚类无法识别噪音也无法进行任意形状的聚类,而K-NN算法则需要人工标记训练样本。最后,在聚类质量评估方面,单纯以正确率和纯度来评价聚类结果的好坏过于片面,聚类的结果应从聚类(簇)个数、簇内个体数量以及与实际样本的吻合度等方面综合考量。
技术实现要素:
针对上述问题,本发明的目的在于提供一种能够解决对大批量恶意变种样本自动分析并归类的问题,并能够提高对恶意软件家族自动化分析的基于TLSH特征表示的恶意软件聚类方法。技术方案如下:
一种基于TLSH特征表示的恶意软件聚类方法,包括以下步骤:
步骤1:利用Cuckoo Sandbox对样本进行分析,获取行为分析报告;
步骤2:从行为分析报告中获取样本静态特征,样本静态特征包括DLL信息、DLL信息的导入及导出函数信息,以及在分析过程中捕获到的字符串信息,并按照字典对上述信息进行排序,得到一个字符串;
步骤3:从行为分析报告中获取样本的资源访问记录,样本的资源访问记录包括以下信息:样文件/目录、注册表、服务、DLL、使用过的互斥量,将每个类别的信息按字典进行排序后合并为一个字符串;所述文件/目录和注册表信息先通过分隔符“\\”拆分成子项后再排序;
步骤4:从行为分析报告中获取样本动态API以及加载的DLL所调用的API,并按照字典对上述信息进行排序,得到一个字符串;
步骤5:分别计算步骤2、步骤3、步骤4中得到的字符串的TLSH值;
步骤6:采用TLSH距离计算公式求得两个TLSH值的TLSH距离,取最小的两个值的平均值作为两个样本的最终距离,采用OPTICS算法对样本进行聚类。
进一步的,所述步骤2中得到的字符串存在干扰项,对其进一步过滤处理,方法如下:
分别统计该字符串中代表各个信息的子字符串中字母出现的个数,由下式计算子字符串的信息熵:
其中,代表字母a-z,代表字母在子字符串中出现的概率,计算方法为的出现的个数除以子字符串长度;
保留信息熵在闭区间[2.188,3.91]内的子字符串。
更进一步的,所述TLSH值的算法如下:
1)用大小为5个字节的滑动窗口处理目标字符串S,一次向前滑动一个字节,设一个滑动窗口的内容为:ABCDE;则分别采用Pearson Hash映射并统计ABC、ABD、ABE、ACD、ACE、ADE这6个bucket的个数;
2)定义q1、q2、q3为:75%的bucket的个数>=q1,50%的bucket的个数>=q2,25%的bucket的个数>=q3;
3)构造TLSH哈希的头部,共三个字节:第一个字节是字符串的校验和;第二个字节是由公式(2)所描述的字符串S的长度的对数L表示,len为字符串S的长度;第三个字节由两个16位的数q1_ratio、q2_ratio组合而成,计算方法如公式(3)所示:
4)构造TLSH哈希的主体部分:Pearson Hash生成的128个映射中每个映射为一个键,其对应的值为该键出现的个数;遍历每个键,并按公式(4)生成相应的二进制位,最终得到大小为32字节的主体部分哈希值:
5)将步骤3)所求的数值和步骤4)所得的二进制串转换为70个十六进制数,得到最终的TLSH值。
更进一步的,所述步骤6中两个TLSH值X和Y之间的TLSH距离计算方法如下:
A)定义mod_diff(a,b,R)为一个在大小为R的循环队列中a到b的最小距离,即
mod_diff(a,b,R)=Min((a-b)modR,(b-a)modR) (5)
B)计算两个TLSH值X和Y头部之间的距离:
先由式(5)分别计算字符串S的长度的对数L及两个16位数q1_ratio和q2_ratio对应的距离:mod_diff(X.L,Y.L,256)、mod_diff(X.q1_ratio,Y.q1_ratio,256)和mod_diff(X.q2_ratio,Y.q2_ratio,256);
然后计算两个TLSH值X和Y的校验和的距离:如果X和Y校验和相等则校验和的距离为0,否则为1;
再将上述四个距离的值进一步优化:
其中,diff为各距离的原始值,diff′为对应的优化值;
则头部之间的距离为上述四个优化值的累加;
C)计算两个TLSH值X和Y主体间的距离:
将两个TLSH值X和Y主体所占的256个二进制位分别从左往右平分为128组,每组的二进制由b0b1表示;如果X与Y某组应用的二进制值不相等则按照公式(7)进行计算,否则该组的距离为0;
然后将X与Y每组对应的距离累加起来即为主体间的距离;
D)两个TLSH值X和Y头部间的距离与主体间的距离之和则为两个TLSH值X和Y之间的TLSH距离。
更进一步的,所述步骤6中采用OPTICS算法对样本进行聚类的方法如下:
算法的输入参数是样本集D,邻域半径r,以及一个点在r邻域内成为核心对象时,该r邻域所包含的点的最小个数MinPt,该r邻域所包含的点为该核心对象的直接密度可达对象;
a)创建有序队列和结果队列;
b)若样本集D中所有的点都处理完毕,则转入步骤g);否则从样本集D中选择一个未处理且为核心对象的点,将该核心对象放入结果队列,并将该核心对象的直接密度可达对象放入有序队列,这些直接密度可达点按可达距离升序排列;
c)若有序队列为空,则跳至步骤b),否则,从有序队列中取出一个样本点;
d)判断该样本点是否为核心对象,若不是,则返回步骤c);若是且该点不在结果队列中,则将其放入结果队列,执行下一步;
e)找到该核心对象的所有直接密度可达对象,遍历这些点,判断其是否已经存在于结果队列中,是则跳过并继续处理下一个点,否则执行下一步;
f)若该直接密度可达点已存在于有序队列,且此时新的可达距离小于旧的可达距离,则用新可达距离取代旧可达距离,对有序队列重新排序;
g)输出并保存结果队列中的有序样本点;
h)从结果队列中按顺序取出点,如果该点的可达距离不大于邻域半径r,则该点属于当前类别,否则进行下一步;
i)如果该点的核心距离大于邻域半径r,则该点被标记为噪声,否则该点属于新的类别。
本发明的有益效果是:
1)本发明的样本特征提取和分析过程是自动化进行的,采用无监督学习方法,不需要人工标记进行训练;
2)本发明采用OPTICS算法,不仅可以识别任意形状和任意个数的簇(cluster),且极大的降低了输入参数对聚类结果的影响,提高了聚类的效率和质量;
3)本发明能够通过可视化输出结果使用者更直观的了解聚类情况并及时做出相应调整;
4)本发明提取的特征采用TLSH进行压缩表示,在不损失特征的情况下,大大降低了数据维度,提高了聚类速度;同时,TLSH计算的距离值可达到1000以上,使得不同家族之间的区分度更为明显。
附图说明
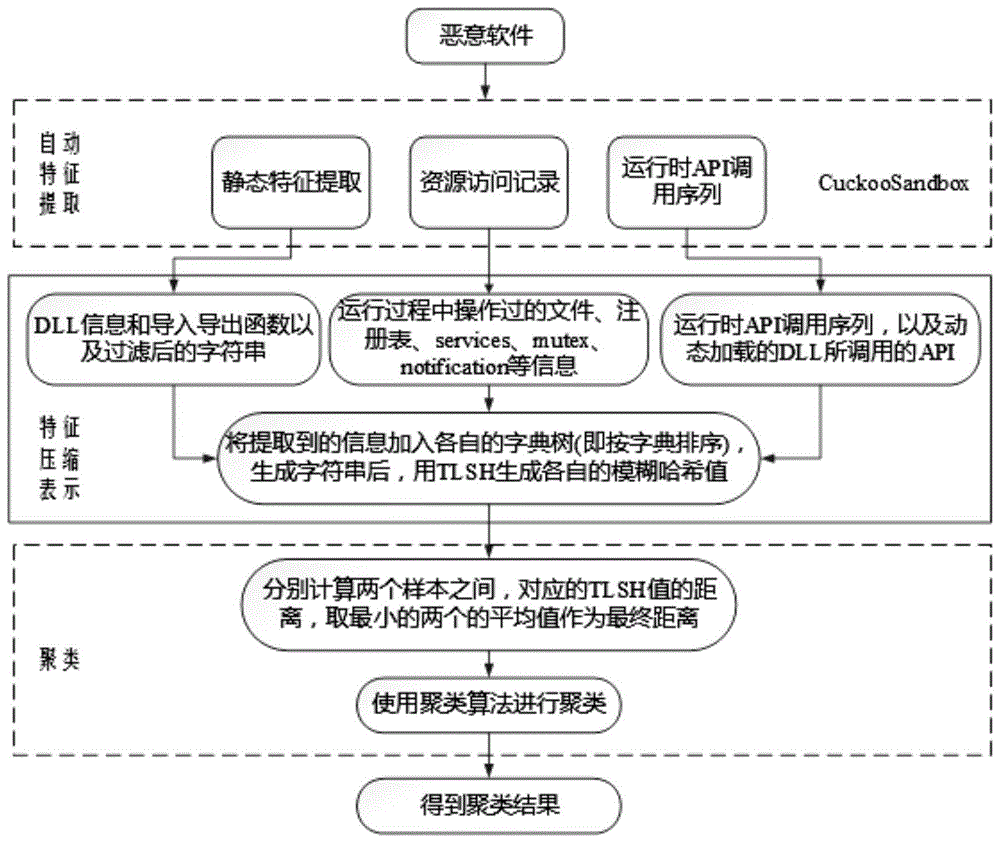
图1为基于TLSH特征表示的恶意软件聚类方法整体流程图。
图2为本发明采用的恶意软件样本家族分布。
图3为本方法与其他杀毒软件和聚类算法的输出结果对比
图4为本方法输出结果的可视化展示。
图5为本发明的环境部署结构图。
具体实施方式
以下结合附图及具体实施过程进一步详细说明本发明。
一种基于TLSH特征表示的恶意软件聚类方法,其特征是包括下述步骤:
步骤1,利用虚拟沙箱(Cuckoo Sandbox)对样本进行分析,获取行为分析报告。
步骤2,从行为分析报告中获取样本静态特征,包括DLL(Dynamic Link Library)信息和其导入、导出函数信息以及在分析过程中捕获到的字符串信息。将这些信息按字典进行排序(建立字典树)合并为一个字符串。
步骤3,从行为分析报告中获取样本在运行过程中的资源访问记录,这些记录可分为文件/目录、注册表、服务、DLL、使用过的互斥量以及其他资源信息等六个类别,将每个类别获取到的信息按字典进行排序后合并为一个字符串。其中,对于文件/目录和注册表两类信息,需先通过分隔符“\\”将其拆分成子项,再进行操作。
步骤4,从行为分析报告中获取样本动态API(Application Programming Interface)以及这些API加载DLL时所调用的API,将这些信息按照字典排序合并为一个字符串。
步骤5,分别计算在步骤2、步骤3、步骤4中得到的字符串的TLSH值。
步骤6,采用OPTICS(Ordering Points to identify the clustering structure)算法进行聚类,其中的距离度量方法采用TLSH距离计算公式,先求得两个样本中各个特征值的TLSH距离,然后取最小的两个值的平均值作为两个样本的最终距离。
上述步骤2中,由于提取出的字符串信息数量较多且存在干扰项,需做过滤处理。
字符串信息,指的是程序运行过程中,被捕获到的一些输出信息,诸如“执行成功”“运行失败”这些有实际意义的字符串和“*/*s231ddaaa”这些无实际意义的干扰项等等。需要将其过滤后排列组合在一起。方法描述如下:
分别统计该字符串中代表各个信息的子字符串中字母出现的个数,由下式计算子字符串的信息熵:
并保留信息熵在闭区间[2.188,3.91]内的子字符串。
其中,代表字母a-z,代表字母在子字符串中出现的概率,计算方法为的出现的个数除以子字符串长度。
所述步骤5中,TLSH值的计算方法描述如下:
1)用大小为5个字节的滑动窗口处理目标字符串S(一次向前滑动一个字节),设一个滑动窗口的内容为:ABCDE,则分别采用Pearson Hash映射并统计ABC、ABD、ABE、ACD、ACE、ADE这6个bucket的个数;
2)在统计完字符串S所有bucket的个数后,定义q1、q2、q3为:75%的bucket的个数大于等于q1,50%的bucket的个数大于等于q2,25%的bucket的个数大于等于q3。
3)构造TLSH哈希的头部,共三个字节:第一个字节是字符串的校验和(Checksum);第二个字节是由公式(2)所描述的字符串S的长度的对数L,设S的长度为len;第三个字节由两个16位的数q1_ratio、q2_ratio组合而成,计算方法如公式(3)所示。
4)构造TLSH哈希的主体部分,Pearson Hash会生成128个映射,每个映射为一个键(Key),其对应的值(Value)为该键出现的个数。遍历每个键,并按公式(4)生成相应的二进制位,最终得到大小为32字节的主体部分哈希值。
5)将步骤3)所求的数值和步骤4)所得的二进制串转换为70个十六进制数,至此得到最终的TLSH值。
所述步骤6中,两个TLSH值X和Y之间的TLSH距离计算方法描述如下:
A)先定义mod_diff(a,b,R)为一个在大小为R的循环队列中,a到b的最小距离,其由公式(5)求得。
mod_diff(a,b,R)=Min((a-b)modR,(b-a)modR) (5)
B)计算头部之间的距离,先分别计算L、q1_ratio、q2_ratio对应的距离mod_diff(X.L,Y.L,256)、mod_diff(X.q1_ratio,Y.q1_ratio,256)、mod_diff(X.q2_ratio,Y.q2_ratio,256)。然后计算X和Y的校验和的距离,如果X和Y校验和相等则距离为0,否则为1。再将上述四个距离的值进一步优化:
其中,diff为各距离的原始值,diff′为对应的优化值;
则头部之间的距离为上述四个优化值的累加。
C)计算主体之间的距离,将主体所占的256个二进制位从左往右平分为128组,每组的二进制由b0b1表示。如果X与Y的b0b1不相等则按照公式(6)进行计算,否则该组的距离为0。然后将X与Y每组对应的距离累加起来即为主体之间的距离。
D)X和Y之间的TLSH距离即为其头部之间的距离与主体之间的距离之和。
所述步骤6中的OPTICS算法描述如下:
算法的输入参数是样本集D,邻域半径r,以及一个点在r邻域内成为核心对象所包含的点的最小个数MinPts。
a)创建两个队列,有序队列和结果队列。其中,有序队列用来存储核心对象及该核心对象的直接密度可达对象(即在核心对象r邻域内的点),并按可达距离升序排列;结果队列用来存储样本点的输出以及处理次序。
b)如果样本集D中所有的点都处理完毕,则算法结束。否则从样本集D中选择一个未处理且为核心对象的点,将该核心点放入结果队列,并将该核心点的直接密度可达点放入有序队列,这些直接密度可达点按可达距离升序排列。
c)如果有序队列为空,则跳至步骤b),否则,从有序队列中取出第一个样本点(即可达距离最小的样本点)进行拓展。
d)首先判断该拓展点是否为核心对象,如果不是,则回到步骤c);如果是且该点不在结果队列中,则应先将其加入结果队列再执行下一步。
e)找到该核心点的所有直接密度可达点,遍历这些点,判断其是否已经存在于结果队列中,是则跳过并继续处理下一个点,否则执行下一步。
f)如果有序队列中已经存在该点,且此时新的可达距离小于旧的可达距离,则用新可达距离取代旧可达距离,有序队列重新排序。如果有序队列中不存在该直接密度可达样本点,则插入该点,并对有序队列重新排序。
g)样本处理完成,输出并保存结果队列中的有序样本点。
h)从结果队列中按顺序取出点,如果该点的可达距离不大于邻域半径r,即表示该点属于当前类别;若大于r则进行下一步。
i)如果该点的核心距离大于邻域半径r,则该点被标记为噪声;否则该点属于新的类别,并跳至步骤h),直至结果队列为空。
图1为本发明的总体流程,首先按照图5所示的环境部署图搭建测试环境,其中Cuckoohost为控制端,负责对虚拟机的管理以及分析任务的调度。而Guests可以采用VMware、Xen、VirtualBox等虚拟机管理软件生成测试环境。提交分析任务后,Cuckoohost会为该任务分配唯一的ID,然后在/storage/analysis/ID目录下生成报告,内容包括内存转储文件、TCP/UDP数据、软件运行时的行为记录以及屏幕截图、软件静态特征等信息。
在分析完成后,会生成一个Json格式的报告文件,对Json文件进行处理,提取主要特征(静态特征、资源访问记录、运行时API),对三组特征用TLSH压缩得到特征值。然后选用合适的聚类算法进行聚类,本发明采用的是OPTICS算法,图4是该方法输出的聚类结果,Y轴代表的是一个点的可达距离,图中看到的每一个波谷即可视为一个簇(家族),若Y值过高则代表该点可能是噪声。关于可达距离和核心距离的描述如下:
设x∈D,对于给定参数E和MinPts,称使得x成为核心点的最小邻域半径为x的核心距离cd(x),其数学定义为:
其中,d(x,y)表示x与y的距离;表示集合N∈(x)中与节点x第i邻近的节点;|N∈(x)|表示集合N∈(x)中的元素个数。
设x,y∈D,则y关于x的可达距离rd(y,x)的数学定义为:
在实验对比的参数中,正确率表示一个样本聚类后,被正确标记的概率;准确率和召回率分别表示聚类结果中,簇的凝聚程度以及与人工标记的整体吻合度,如公式(8)、(9)所示;F-Score代表准确率和召回率的调和平均值如公式(10)所示;熵值代表了聚类结果的混杂程度。
对设Lx为聚类结果中包含x的那个簇;Cx表示人工标记的结果中包含x的那个簇,则:
准确率:
召回率:
F-Score:
设聚类算法将数据集D划分为K个两两不相交的集合Di,人工标记中划分了M个集合Cj,则聚类结果的熵entropy(D)的计算方式如公式(11)所示。
其中,|Di|表示该簇的元素个数;Pi(Cj)表示在簇Di中属于类别Cj的元素所占的比例。
本发明采用的测试样本分布如图2所示,共有7919个样本,分为66个家族,经过加壳/混淆处理的样本占到了73.22%。对比实验采用最新版的(2016年7月)Kaspersky和360多查杀引擎进行对比,同时也加入了现有的几种经典聚类算法进行比较。实验结果如图3所示,可以看到Kaspersky的聚类结果优于360,而在聚类算法中,本发明采用的OPTICS算法效果最好,且在其他实验数据相差不大的情况下,其正确率和召回率同比Kaspersky分别提升了159%和39%。
- 一种温室异常温度诊断装置的制...
- 一种基于图像的重光照方法与流...
- 一种面向中文微博的情感倾向分...
- 对象分割方法和对象分割装置与...
- 用于曝光图像的图像处理方法及...
- 一种缓存数据刷盘方法及装置与...
- 智能设备的动作模拟交互方法和...
- 一种事件识别方法和设备与流程
- 一种煤矿低压供电系统自适应短...
- 一种文字显示方法及装置与流程
- 还没有人留言评论。精彩留言会获得点赞!