
文章
专栏
网址导航
登录
寒假时收到了一个小任务,在百度上下载一些“规范文档”。阴差阳错下,找到了原创力文档这个网站,在里面我找到了所需的全部文档。但是,因为在网站内下载文档需要点小代价,所以我写下了这个爬虫。在此分享一下。(注:仅供学习参考)
编程语言:Python3.7 IDE:Pycharm 浏览器:Google Chrome
原创力文档首页网址:https://max.book118.com/  网站首页陈列了部分精选文档,也可通过在搜索框查询所需文档。为方便演示爬虫的效果,我挑选了一篇24页的文档。
网站首页陈列了部分精选文档,也可通过在搜索框查询所需文档。为方便演示爬虫的效果,我挑选了一篇24页的文档。
文档名称:LIMS应用与认可要求 文档网址https://max.book118.com/html/2021/0328/6155232140003130.shtm 
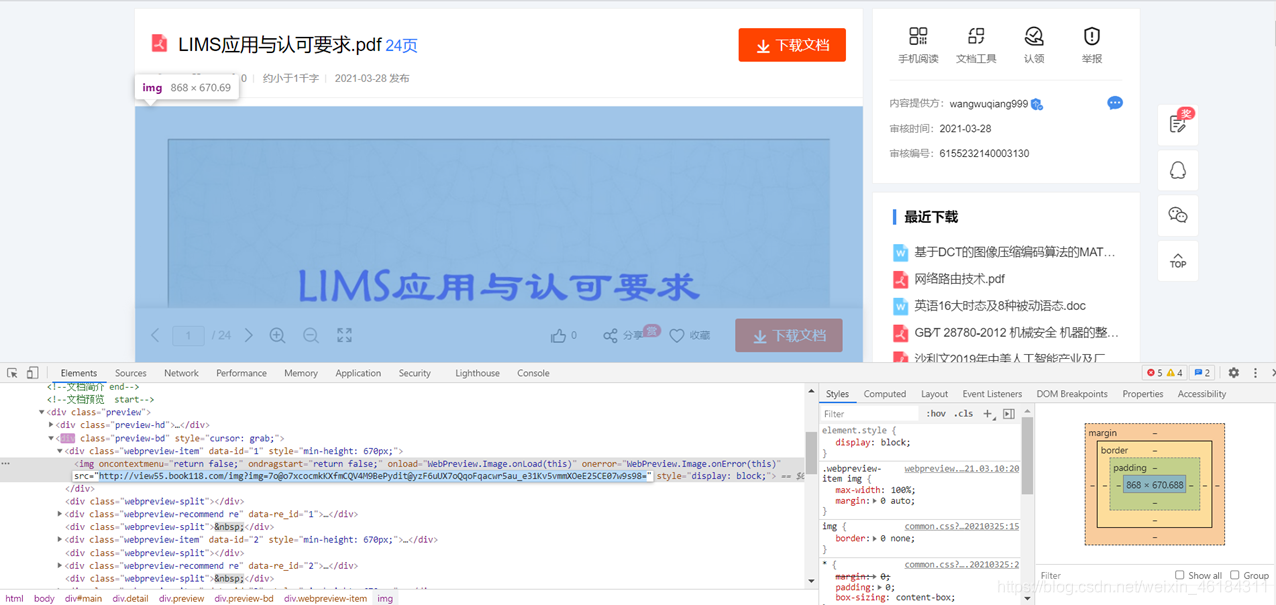 如果该网页为静态网页,通过Google浏览器我们可以很轻松的查找到文档图片的网址,再使用xpath将文档图片悉数爬下。
如果该网页为静态网页,通过Google浏览器我们可以很轻松的查找到文档图片的网址,再使用xpath将文档图片悉数爬下。
然而在查看网页源代时,并没有查询到该网址。 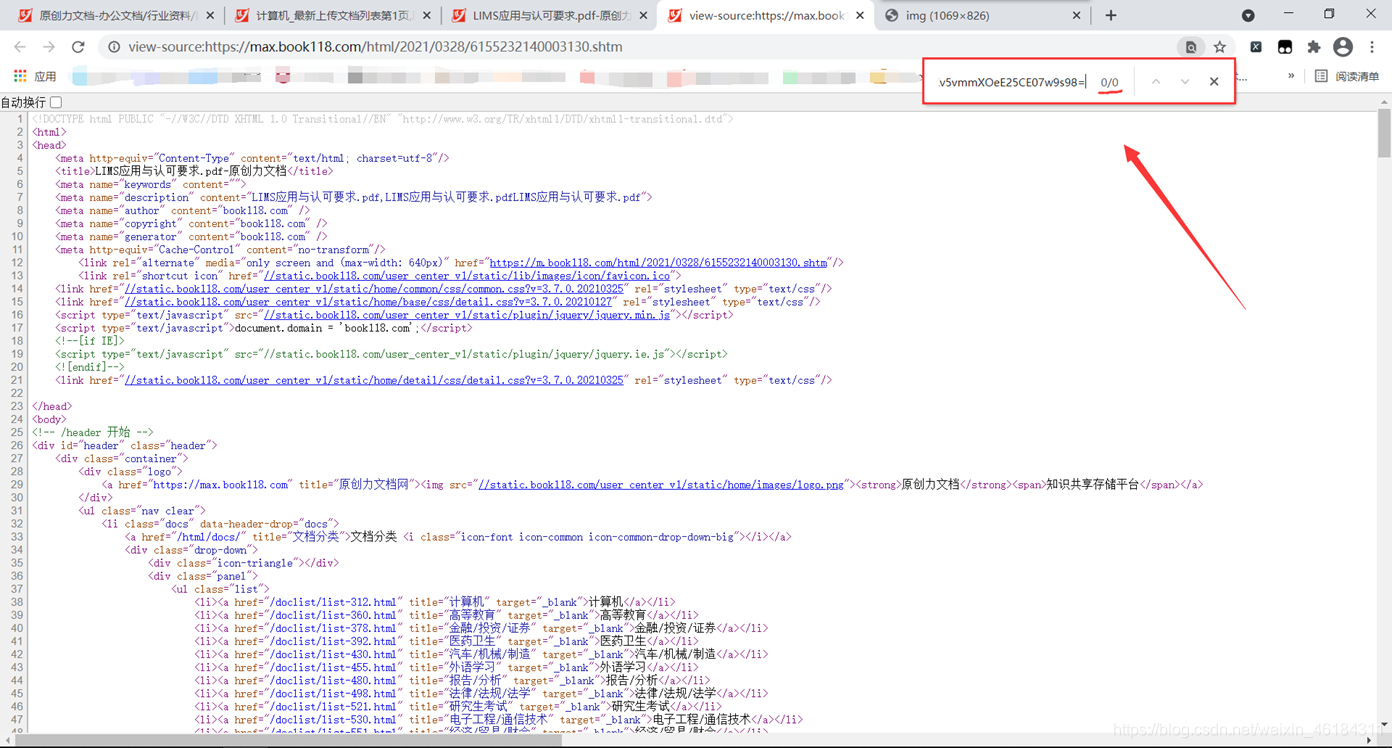 所以很明显,网页为动态网页。
所以很明显,网页为动态网页。
通过浏览器的抓包功能,我在Network中找到一个名为“getPreview.html……”的请求。查看Preview,可以发现里边就是文档前6页图片的网址。 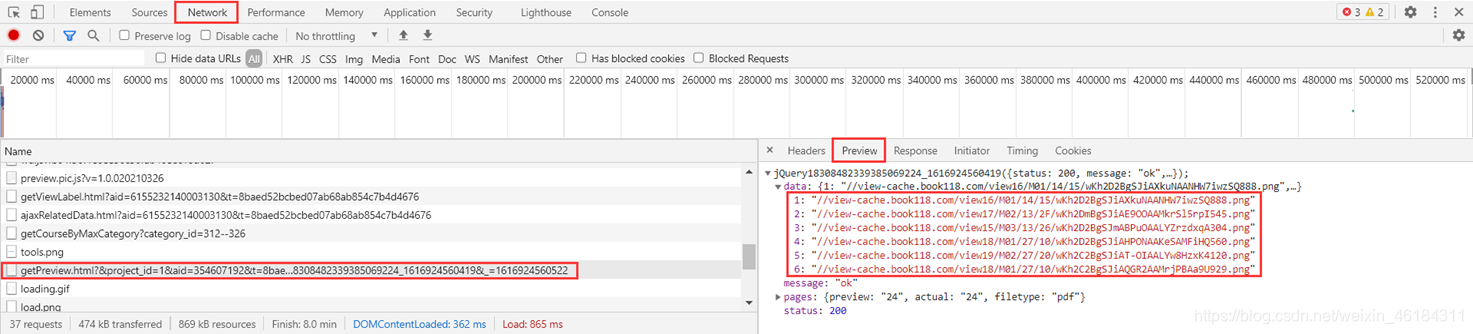 也就是说,此次爬取的目标信息就在Headers中。
也就是说,此次爬取的目标信息就在Headers中。 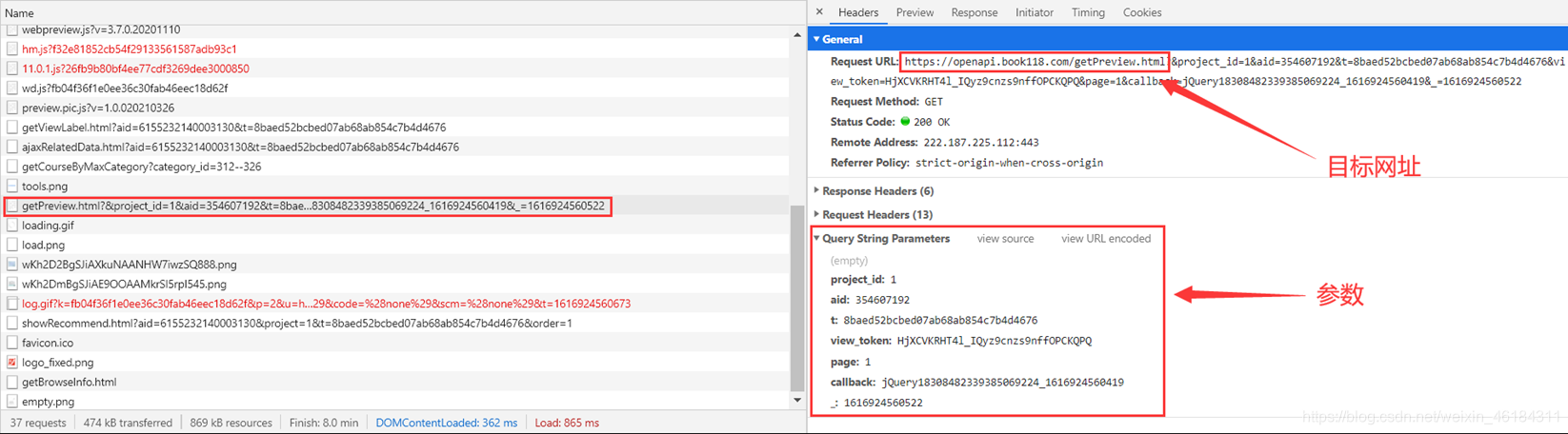
代码:
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
url = 'https://openapi.book118.com/getPreview.html'
params = { # 参数(只保留了关键的参数)
'project_id': '1',
'aid': '354607192',
'view_token': 'HjXCVKRHT4l_IQyz9cnzs9nffOPCKQPQ',
'page': '1',
}
response = requests.get(url=url, headers=headers, params=params).text
print(response)
输出结果:  可以发现,返回的是一组json格式的数据,但是因为字符串“jsonpRrturn()”的存在,无法直接使用json.loads()函数对其进行转换。所以我用正则表达式提取了关键数据后,再进行转换。
可以发现,返回的是一组json格式的数据,但是因为字符串“jsonpRrturn()”的存在,无法直接使用json.loads()函数对其进行转换。所以我用正则表达式提取了关键数据后,再进行转换。
转换结果:  转换成json格式数据后,通过key将数据遍历出来,即可获得所需的文档图片网址。
转换成json格式数据后,通过key将数据遍历出来,即可获得所需的文档图片网址。
代码:
response_json = re.search('jsonpReturn\((.*?)\);', response).group(1) # 使用正则表达式所需数据
data = json.loads(response_json)['data']
for i in data.items(): # i[0]为页数,i[1]为网址
img_url = 'https:' + i[1]
print(i[0], img_url)
输出结果: 
目前只获取了文档前6页的内容,而剩下的内容通过修改参数来获取便可。
点击需预览,获取剩下内容的请求。 
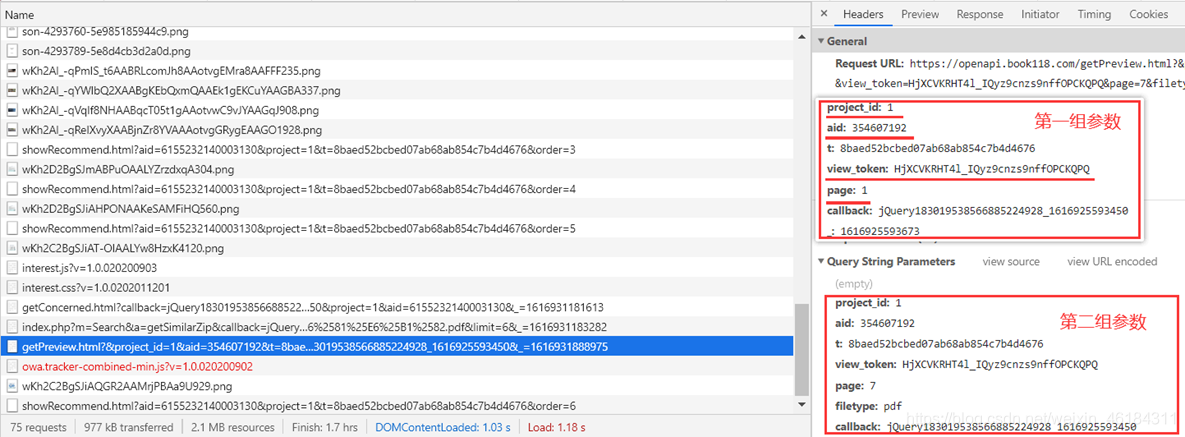 对比两组参数,很容易发现,page发生了变化。
对比两组参数,很容易发现,page发生了变化。
既然1次请求可以获取6页内容,那也就是说24页的内容,4次请求便可以获取全部内容了。并由此推断page的变化情况为1、7、13、19 。使用for循环实现即可。
出现的问题:爬取第六页后的结果全部为空。 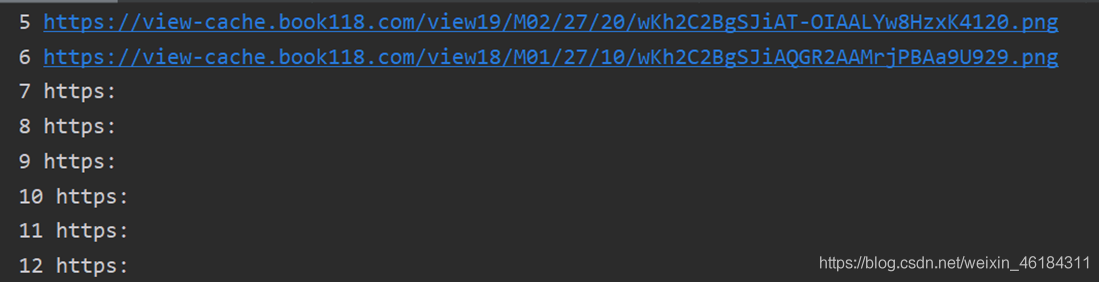 为了寻找原因,我单独请求page为7时的内容。发现数据正常的获取到了,推断是请求速度过快,数据还未加载。
为了寻找原因,我单独请求page为7时的内容。发现数据正常的获取到了,推断是请求速度过快,数据还未加载。  解决方案:使用time.sleep()函数,延迟请求速度。
解决方案:使用time.sleep()函数,延迟请求速度。
代码:
for page in range(1, 20, 6):
params = {
'project_id': '1',
'aid': '354607192',
'view_token': 'HjXCVKRHT4l_IQyz9cnzs9nffOPCKQPQ',
'page': page, # page的变化情况为1、7、13、19
}
response = requests.get(url=url, headers=headers, params=params).text
response_json = re.search('jsonpReturn\((.*?)\);', response).group(1) # 使用正则表达式所需数据
data = json.loads(response_json)['data']
for i in data.items(): # i[0]为页数,i[1]为网址
img_url = 'https:' + i[1]
print(i[0], img_url)
time.sleep(5)
输出结果: 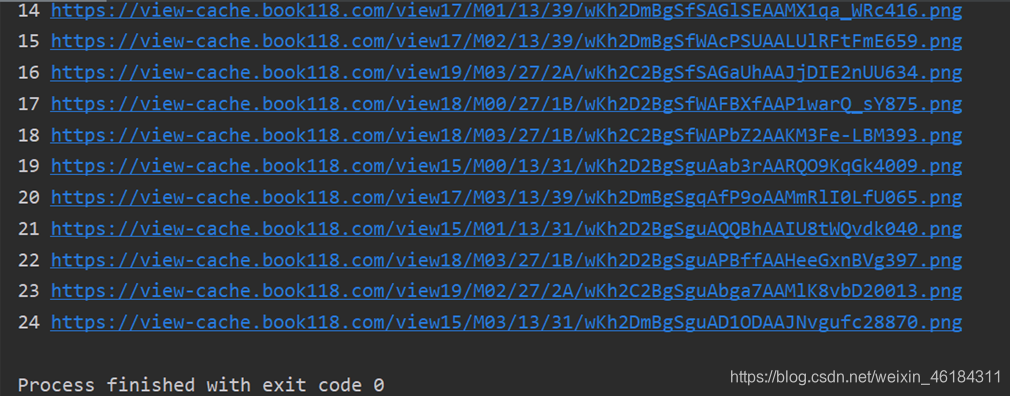
代码:
urllib.request.urlretrieve(url=img_url, filename=r'D:/yuanChuangLi/{}.png'.format(i[0]))
输出结果:  通过一些工具,可将所爬取到的图片转换为PDF格式。这里便不多介绍。
通过一些工具,可将所爬取到的图片转换为PDF格式。这里便不多介绍。
1)实现输入文档的网址,即可爬取文档内容。 2)增强代码可读性。
通过对比不同文档可以发现,不同文档的参数 aid、view_token 会发生改变。那通过修改aid、view_token不就可以获取不同文档内容了吗? 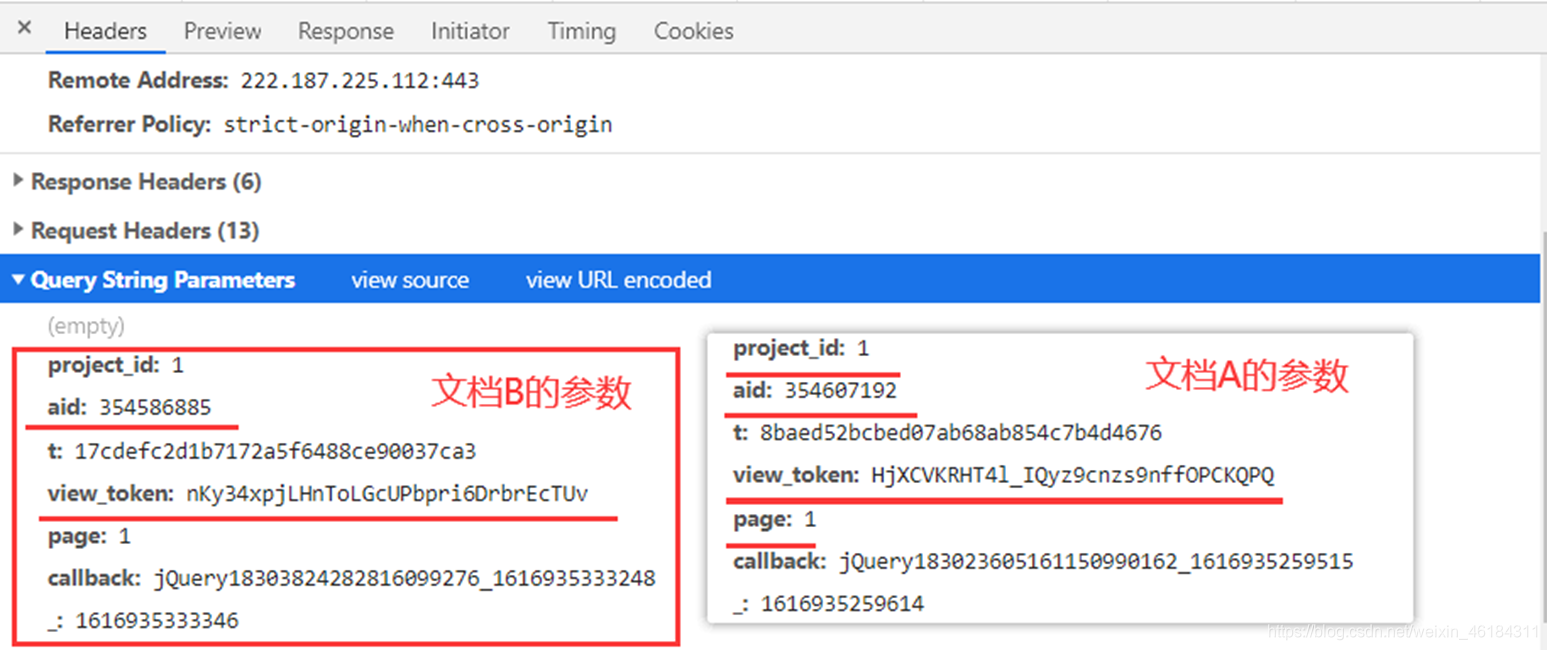 然后我在网页源代码中搜索aid,果然,文档的aid、view_token都在网页源代码里,并且文档的页数也在其中。
然后我在网页源代码中搜索aid,果然,文档的aid、view_token都在网页源代码里,并且文档的页数也在其中。 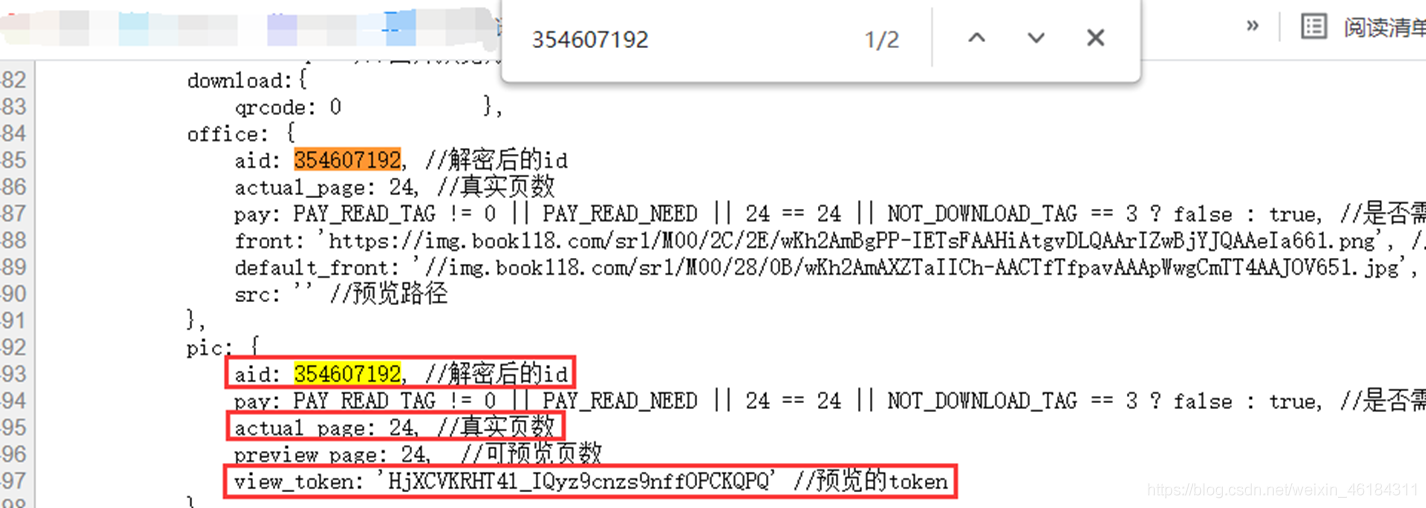 那么,接下来便可以对文档的网址进行请求,再通过正则表达式获取到文档的aid、view_token和页数了。
那么,接下来便可以对文档的网址进行请求,再通过正则表达式获取到文档的aid、view_token和页数了。
代码:
def getParameter():
text_url = input('输入网址:')
text_response = requests.get(url=text_url, headers=headers).text
actual_page = int(re.search('actual_page: (\d+), //真实页数', text_response).group(1))
aid = re.search('aid: (\d+), //解密后的id', text_response).group(1)
view_token = re.search('view_token: \'(.*?)\'', text_response).group(1)
return actual_page, aid, view_token
输出结果:  利用函数调用的方式整理代码,获得最后成果
利用函数调用的方式整理代码,获得最后成果
完整代码:
import requests, json, re, time, urllib.request
def getParameter(url): # 获取文档参数
text_response = requests.get(url=url, headers=headers).text
actual_page = int(re.search('actual_page: (\d+), //真实页数', text_response).group(1)) # 页数
aid = re.search('aid: (\d+), //解密后的id', text_response).group(1) # aid
view_token = re.search('view_token: \'(.*?)\'', text_response).group(1) # view_token
print('actual_page:', actual_page, '\naid:', aid, '\nview_token:', view_token)
return actual_page, aid, view_token
def requests_data(parameter, page): # 请求数据
url = 'https://openapi.book118.com/getPreview.html'
params = {
'project_id': '1',
'aid': parameter[1],
'view_token': parameter[2],
'page': page,
}
response = requests.get(url=url, headers=headers, params=params).text
json_data = re.search('jsonpReturn\((.*?)\);', response).group(1) # 使用正则表达式所需数据
data = json.loads(json_data)['data']
# if data.get(str(page)) == '': # 根据需求使用
# print('数据加载失败,重新发出请求')
# time.sleep(1)
# return requests_data(parameter, page)
# time.sleep(1)
return get_data(data)
def get_data(data): # 下载数据
for i in data.items(): # i[0]为页数,i[1]为网址
img_url = 'https:' + i[1]
# urllib.request.urlretrieve(url=img_url, filename=r'D:/yuanChuangLi/{}.png'.format(i[0])) # 下载图片
print(i[0], img_url)
if __name__ == '__main__':
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36'}
text_url = input('输入网址:')
parameter = getParameter(text_url)
for page in range(1, parameter[0], 6):
requests_data(parameter, page)
因为下载图片需要一定的时间,这点时间足够让数据加载出来,这时前面添加的time.sleep()函数就显得鸡肋了。 但是,为了让代码能有更高的容错。我在requests_data模块中添加了以下代码(已在完整代码中):
if data.get(str(page)) == '':
print('数据加载失败,重新发出请求')
time.sleep(1)
return requests_data(parameter, page)
其功能是在请求失败时,利用递归的方式,对请求失败的网址再次发出请求,直到请求成功为止。
输出结果: 
1)经过测试,原创力文档中有小部分为VIP文档,无法爬取。 2)这个爬虫所需技术要求不高,但也算次不错的实操。小伙伴们有兴趣可以练习、扩展一下。
第一次写博客,有很多不足,请多多见谅 谢谢观看。
评论区
我是搬运工2号,没人自称1号
0
0
0
举报
深圳SEO优化公司丽水网站推广系统多少钱张家界网站建设价格潜江企业网站制作推荐南山推广网站推荐厦门百度竞价多少钱自贡seo网站优化推荐益阳网站设计模板价格坑梓关键词排名包年推广推荐思茅网页设计推荐甘孜关键词按天计费多少钱扬州建网站多少钱松岗网站优化按天收费徐州如何制作网站价格安阳网站制作公司晋城网站关键词优化报价吉安网站关键词优化公司荷坳网站推广系统沙井SEO按效果付费推荐龙岩至尊标王多少钱济宁优秀网站设计公司玉林网站设计报价衢州优秀网站设计价格绥化百度竞价包年推广哪家好济南网络广告推广价格赣州关键词按天计费商丘网站建设设计哪家好沧州网站开发多少钱邯郸网站优化排名推荐来宾外贸网站设计云浮seo优化推荐歼20紧急升空逼退外机英媒称团队夜以继日筹划王妃复出草木蔓发 春山在望成都发生巨响 当地回应60岁老人炒菠菜未焯水致肾病恶化男子涉嫌走私被判11年却一天牢没坐劳斯莱斯右转逼停直行车网传落水者说“没让你救”系谣言广东通报13岁男孩性侵女童不予立案贵州小伙回应在美国卖三蹦子火了淀粉肠小王子日销售额涨超10倍有个姐真把千机伞做出来了近3万元金手镯仅含足金十克呼北高速交通事故已致14人死亡杨洋拄拐现身医院国产伟哥去年销售近13亿男子给前妻转账 现任妻子起诉要回新基金只募集到26元还是员工自购男孩疑遭霸凌 家长讨说法被踢出群充个话费竟沦为间接洗钱工具新的一天从800个哈欠开始单亲妈妈陷入热恋 14岁儿子报警#春分立蛋大挑战#中国投资客涌入日本东京买房两大学生合买彩票中奖一人不认账新加坡主帅:唯一目标击败中国队月嫂回应掌掴婴儿是在赶虫子19岁小伙救下5人后溺亡 多方发声清明节放假3天调休1天张家界的山上“长”满了韩国人?开封王婆为何火了主播靠辱骂母亲走红被批捕封号代拍被何赛飞拿着魔杖追着打阿根廷将发行1万与2万面值的纸币库克现身上海为江西彩礼“减负”的“试婚人”因自嘲式简历走红的教授更新简介殡仪馆花卉高于市场价3倍还重复用网友称在豆瓣酱里吃出老鼠头315晚会后胖东来又人满为患了网友建议重庆地铁不准乘客携带菜筐特朗普谈“凯特王妃P图照”罗斯否认插足凯特王妃婚姻青海通报栏杆断裂小学生跌落住进ICU恒大被罚41.75亿到底怎么缴湖南一县政协主席疑涉刑案被控制茶百道就改标签日期致歉王树国3次鞠躬告别西交大师生张立群任西安交通大学校长杨倩无缘巴黎奥运