
LZ77压缩算法原理剖析
共 4919字,需浏览 10分钟
· 2021-08-18
点击上方“君子黎”,选择“置顶/星标公众号”
干货福利,第一时间送达!
1. 数据压缩
数据压缩(Data Compression),简称为压缩,通常也被称为编码(coding)。它是信息论的一个分支,其主要目的是使要传输的数据量尽量最小化。从根本上讲,它在保证能够包含原有相同信息的前提下,使用比原始表示更少的位来对信息进行重新编码。它通过对数据进行编码、重组或修改以减少其大小的一个过程。
数据压缩在数据存储和数据传输领域有着重要的应用。尤其是在Internet高速发展的今天,文件大小和网络传输速度之间的微妙关系变得更加明显。越来越多的企业和应用需要存储大量的数据文件,同时网络交互、通信传输的数据报文也愈加频繁。更大的数据和带宽意味着需要更高的成本与代价,这无疑与人们追求更高利益化的理念相违背。而通过压缩要存储或传输的数据可以极大地降低存储或通讯成本。对将要发送的数据压缩后,体积变小了,随之而来的是增加了通信信道的容量;而在数据变小之后,相同容量的存储介质间接地可以存储更多的数据量。同时,更小的数据,通过利用 存储层次结构 规则,可以将其放在计层次更高、速度更快的存储层级,从而减少系统I/O通道的负载与压力。
2. 压缩算法
尽管压缩算法类型十分繁多,但是从本质上而言,可以归纳为两大类,分别是:无损压缩(Lossless Compression)和有损压缩(Lossy Compression)。无损压缩算法可以反转以恢复到原始数据,所以它是精确的;而有损算法在反转时候会丢失部分细节或引入一些小错误,所以它不是精确的。
2.1 无损压缩
无损压缩算法的基本原理是,对于任何一个非随机文件都将包含重复的信息,而这些信息是可以使用统计建模技术进行压缩,从而确定字符或短语出现的概念进行压缩。然后这些统计模型可用于根据特定字符或短语出现的概率生成代码,并将最短的代码分配给最常见的数据,从而使大量文本中大量冗余的数据被移除。这些技术包括熵编码、游标编码和字典进行压缩。
常用的无损压缩算法程序有:Zip(使用于Windows系统上)、gzip(工作于类UNIX系统上)等。
2.2 有损压缩
有损压缩算法通常通过删除需要大量数据以完全保真度的小细节来减少文件大小。由于该算法删除了许多必要的数据,所以是不能恢复到原始文件的,显然,它实现了非常高的压缩比。最常用于有损压缩算法的场景是图像和音视频数据。
3. LZ算法
LZ算法是由Abraham Lempel和Jacob Ziv于1977年发明的算法,因此,该LZ算法也称为LZ77算法(或LZ1)。此算法是第一个使用字典压缩数据的算法。更具体点地说,LZ77算法使用了一个动态字典(Dynamic Dictionary),通常也称为“滑动窗口(Sliding Window)。” 在第二年中,即1978年, Abraham Lempel和Jacob Ziv在基于LZ77算法的基础上,发布了LZ78算法(也称为LZ2),该算法同样使用了字典,但是与LZ77不同的是,LZ78算法取消了动态字典生成;反之,它是根据解析输入数据而生成静态字典。
LZ算法是一种无损压缩算法。在LZ77和LZ78的基础上,衍生出了许多的无损压缩算法,然而许多算法自面世以来,没隔多久时间就消失了,只有少数的算法得到一直延续到今天且在广泛使用。如下图所示,该图详细地描述了无损压缩算法的层次结构,以及分别在LZ77和LZ78算法版本上所衍生出来的其他算法版本。

从图中可以看到基于LZ77的算法变体远多于LZ78。这是因为从LZ78上变体出来的LZW算法申请了专利,并开始起诉提供该算法的软件服务商,基于专利保护的缘故,导致该算法的衍生版本不如LZ77多。
3.1 LZ算法的原理
当使用LZ算法来对一个符号序列进行压缩时候,它采用如下的示意结构。
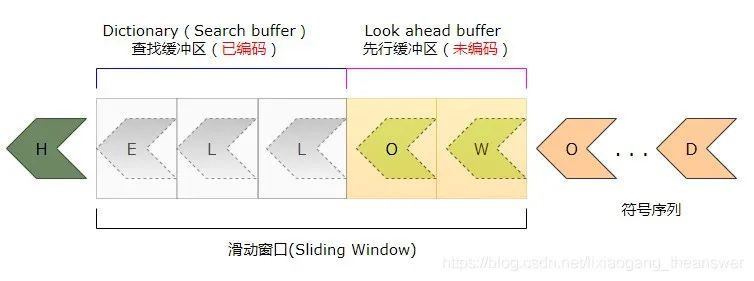
该结构共包含了2个部分,分别是:查找缓冲区(Search buffer),也称字典(所谓字典,就是已编码好的部分)。先行缓冲区(Look ahead buffer),包括即将进行编码序列的一部分。这两个部分组成了这个所谓的“滑动窗口(Sliding Window)。”
由于缓冲区具有固定的长度,所以,当算法(编码器)在运行时候,它看起来像在文件中“滑动”,所以这个缓冲区被称为“滑动窗口”。而该技术也被称为“滑动窗口技术”。
查找缓冲区和先行缓冲区都有自己的固定大小,比如上图中,其查找缓冲区大小是3字节,而先行缓冲区是2字节。当然,实际中肯定比这个大许多,这里只是为了方便举例说明。对于LZ算法,滑动窗口的典型大小是4096字节。PostgreSQL数据库中的TOAST技术,也采用了LZ无损压缩算法,其窗口大小也是4096字节。
//滑动窗口的固定大小 4096字节
#define PGLZ_HISTORY_SIZE 4096
3.2 LZ编码过程
LZ压缩算法使用一个三元组<o, l, c>来对字符串序列进行编码。其中o是offset(偏移量)的缩写,l是length(长度)的缩写,而c则是代表先行缓冲区中位于匹配项之后的字符(character)。也有的文献资料称之为码字(Code Word)。
现在来详细说明一个三元组<o, l, c>中这几个数字对应的实际含义。这里待编码的字符串序列是“HELLOWORLD”。假定LZ窗口大小是5字节,其中查找缓冲区是3字节,而先行缓冲区为2字节。由于窗口大小是固定的,所以同一时刻(当然,一开始时候,查找缓冲区没有字符),查找缓冲区中最多有3个字节数据,先行缓冲区最多容纳2字节数据。
假如现在已经对字符‘H’、'E'、'L'、'L'、'O'、'W'这6字符编码完成,其中'L'、'O'、'W'字符位于查找缓冲区中,而先行缓冲区中的字符是'O'、'R'。如下图所示:
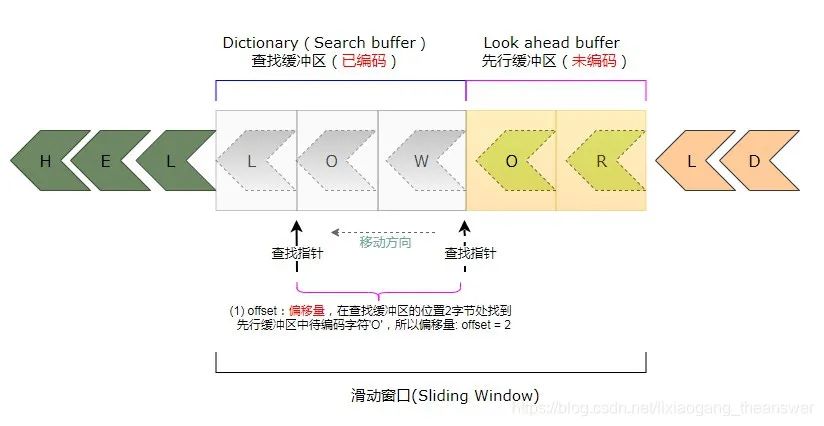
编码器将会通过“查找指针”在查找缓冲区中不断移动(移动方向如上图黑色箭头所示),来判断是否有字符和先行缓冲区中的(第一个)待编码字符相同。这里先行缓冲区中的待编码字符是‘O’。通过判断可知,在查找缓冲区中的第2个位置处有一个字符‘O’和先行缓冲区中的第一个符号相同,该(查找)指针与先行缓冲区的距离称为“偏移量(offset)”,这里偏移量是2。
此时,LZ编码器会继续查看并判断查找缓冲区中该“查找指针”位置之后的字符,是否与先行缓冲区中第一个字符之后的字符连续相匹配。在查找缓冲区中与先行缓冲区中连续相匹配的字符的数量,我们称之为“匹配长度”。从上图可以看到位于查找缓冲区中的查找指针后面的一个字符是‘W’,而先行缓冲区中第一个待编码字符之后的字符是‘R’,不相匹配。所以这里的匹配长度length等于1。
先行缓冲区中匹配字符之后的第一个字符是‘R’,所以可以得到一个三元组:<2, 1, C(R)>。待字符‘O’编码好之后,滑动窗口移动一个字符(字节)。此时的查找缓冲区与先行缓冲区中的内容如下图所示:

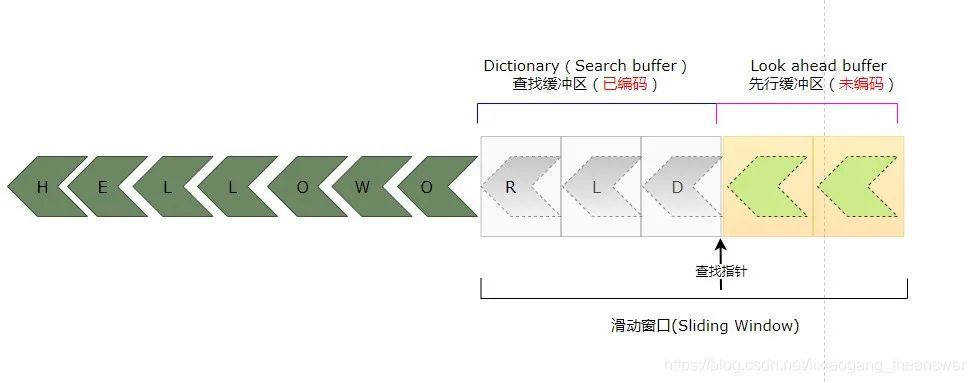
LZ编码器继续对先行缓冲区中的字符‘R’进行编码,重复上面的逻辑判断过程。首先在查找缓冲区(Search Buffer)中通过移动查找指针,判断是否有字符和先行缓冲区中的第一个字符(待编码)相等,若有,则继续判断是否有连续的字符和先行缓冲区的字符相匹配,通过上图可以看到,查找缓冲区中没有与字符‘R’相等的符号。所以偏移量为0,其长度也为0,字符编码是‘R’。所以得出其三元组为:<0, 0, C(L)>。得到如下图所示的编码。

最后,还剩下字符‘D’未编码,通过前面的步骤可知,查找缓冲区中没有与之匹配的字符,所以该三元组是<0, 0, C(D)>。最终完成对序列字符“HELLOWORLD”的编码操作,如下图所示:
 对于LZ编码,其整个压缩过程可以划分为以下三个步骤:
对于LZ编码,其整个压缩过程可以划分为以下三个步骤:
(1) 用搜索缓冲区中可用的模式查找从当前位置开始的字符串的最长匹配。
(2) 输出一个三元组<o, l, c>;
o:偏移量,表示为了找到匹配字符串的开始,我们需要向后移动的位置数。
l:表示匹配的长度。
c:字符,表示匹配后找到的字符。
(3) 向右移动查找指针 + 1。
3.3 LZ编码过程中的三种可能性
通过上面对LZ编码过程的描述,可以看出,编码器使用LZ算法对一个符号序列进行压缩时候,可能会遇到以下几种情形。
(1) 查找缓冲区里存在与先行缓冲区中待编码的字符(即存在匹配项)。
(2) 查找缓冲区里没有与先行缓冲区中待编码字符匹配的字符。
(3) 查找缓冲区中有匹配字符串,且该字符串在先行缓冲区字符串中延伸。
前面(1)和(2)两种情形好理解,即找到与未找到问题。对于第(3)项的理解,需要记住这样一个事实。即对于LZ算法,仅要求匹配项的字符位置起点(即查找与先行缓冲区中的待编码字符)位于查找缓冲区中,但是若匹配到先行缓冲区中的多个字符,则其终点可以延续到先行缓冲区中。借助这段话,再来理解情形(3),就相对容易许多。
3.4 LZ解码过程
由于LZ算法是无损压缩算法,这意味着我们能够完全恢复原始的数据,因此,我们不能从随机的LZ三元组开始解压缩。相反,我们必须得从初始的三元组开始解压缩,因为LZ编码的三元组是基于搜索缓冲区的。
假设我们已经完成对字符‘H’、‘E’、‘L’、‘L’、‘O’、‘W’的编码,如下图所示。
注意,编码与解码过程中 其窗口(查找缓冲区,先行缓冲区)大小是固定的,否则,其解压缩过程将会以失败而告终。
现在依次对上面的三元组:<2, 1, C(R)>、<0, 0, C(L)>和<0, 0, C(D)>进行解码。
(1) 解码<2, 1, C(R)>
由于其偏移量(offset)等于2,所以我们将查找指针(向左)移动两位;而字符匹配的长度(length)是1,所以我们将查找指针所指向的字符复制一个。其解码过程如下图所示:
该三元组解析完成之后,得到的窗口图如下: (2) 解码<0, 0, C(L)>
(2) 解码<0, 0, C(L)>
由于偏移量(offset)等于0,且匹配字符长度为0,则表明在查找缓冲区中没有与之匹配的内容,且下一个字符是‘L’。所以则在已解码的字符串后面增加一个字符‘L’,并将窗口移动一个字符。如下图所示:
(3) 解码<0, 0, C(D)>
和解码<0, 0, C(L)>一样,由于其偏移量和匹配长度都为0,所以其下一个字符是‘D’。则最终解码(压缩)得到的完整字符串是:HELLOWORLD。如下图所示:

3.5 LZ算法实现
在github上有一份 LZ算法 的源码实现。该算法中使用了二叉树来作为编码过程中的偏移量和长度等索引,以加快编码、解码的速度。针对这个LZ算法的源码,后期将专门写一篇文章来进行分析、学习。
4. 数据压缩优缺点
没有任何一件事物是完美的,数据压缩亦是如此。既然有优点,肯定也有它的缺点所在。下面分别对数据压缩的优缺点进行一个简单的概述。
4.1 优点
(1) 同一个数据文件,需要更少的磁盘空间。这意味着可以存储更多的数据文件;
(2) 文件传输、读写速度更快。
4.2 缺点
(1) 增加了CPU的负载,对于一些较为复杂的压缩算法,尤其如此。
(2) 增加了复杂性;
(3) 提高了传输误差影响。
往期推荐
SQL中GROUP BY的这些使用诀窍,你都学“废”了吗?
C/C++中extern关键字,它还得这么用
为什么空类的大小不为0
基类析构函数总是应该为virtual吗?
PostgreSQL数据库体系架构
🧐分享、点赞、在看,给个3连击呗!👇
手机扫一扫分享
手机扫一扫分享