Python爬虫——入门爬取网页数据
目录
前言
一、Python爬虫入门
二、使用代理IP
三、反爬虫技术
1. 间隔时间
2. 随机UA
3. 使用Cookies
四、总结
前言
本文介绍Python爬虫入门教程,主要讲解如何使用Python爬取网页数据,包括基本的网页数据抓取、使用代理IP和反爬虫技术。

一、Python爬虫入门
Python是一门非常适合爬虫的编程语言。它具有简单易学、代码可读性高等优点,而且Python爬虫库非常丰富,使用Python进行爬虫开发非常方便。
我们先来看一个简单的Python爬虫程序,爬取一个网页的标题:
import requests
from bs4 import BeautifulSoup# 发送HTTP请求
url = 'http://www.baidu.com/'
response = requests.get(url)# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title# 输出结果
print('网页标题:', title.string)在这个程序中,我们使用了requests库来发送HTTP请求,并使用BeautifulSoup库来解析HTML文档。通过这两个库,我们可以轻松地获取网页数据,进而进行数据分析和处理。
二、使用代理IP
有些网站可能会封禁某个IP地址,这时我们需要使用代理IP来隐藏真实IP地址。使用代理IP的方法很简单,只需向requests库的get()或post()方法传递proxies参数即可。
下面是一个使用代理IP的Python爬虫程序,爬取一个网站的代理IP:
import requests
from bs4 import BeautifulSoup# 设置代理IP
proxies = {'http': 'http://127.0.0.1:8080','https': 'http://127.0.0.1:8080'
}# 发送HTTP请求
url = 'http://www.zdaye.cn/freeproxy.html'
response = requests.get(url, proxies=proxies)# 解析HTML文档
soup = BeautifulSoup(response.text, 'html.parser')
trs = soup.select('.table tbody tr')# 输出结果
for tr in trs:tds = tr.select('td')ip = tds[0].stringport = tds[1].stringprint('{}:{}'.format(ip, port))在这个程序中,我们设置了一个代理IP,然后使用requests库发送HTTP请求,传递了proxies参数。接着我们解析HTML文档,使用BeautifulSoup库找到了代理IP,并输出了结果。
三、反爬虫技术
有些网站为了防止被爬虫抓取,会采取一些反爬虫技术,如设置限流、验证码等。为了绕过这些反爬虫技术,我们需要使用一些技巧。
1. 间隔时间
我们可以通过设置间隔时间来减小对目标网站的压力,缓解反爬虫措施带来的影响。代码实现如下:
import requests
import time# 发送HTTP请求
url = 'http://www.baidu.com/'
while True:response = requests.get(url)print(response.text)time.sleep(5) # 每隔10秒钟发送一次请求在这段代码中,我们使用了time库来让程序等待5秒钟,然后再继续发送HTTP请求。
2. 随机UA
有些网站会根据User-Agent来判断是否是爬虫程序,我们可以通过随机User-Agent的方法,来让我们的爬虫程序更难被发现。代码实现如下:
import requests
from fake_useragent import UserAgent# 获取随机User-Agent
ua = UserAgent()
headers = {'User-Agent': ua.random
}# 发送HTTP请求
url = 'http://www.baidu.com/'
response = requests.get(url, headers=headers)
print(response.text)在这段代码中,我们使用了fake_useragent库来生成随机的User-Agent,然后将其设置到HTTP请求的headers中。
3. 使用Cookies
有些网站会根据用户的Cookies来判断是否是爬虫程序,我们可以通过获取网站的Cookies,然后将其设置到我们的爬虫程序中,来伪装成正常用户。代码实现如下:
import requests# 发送HTTP请求
url = 'http://www.baidu.com/'
response = requests.get(url)# 获取Cookies
cookies = response.cookies# 设置Cookies
headers = {'Cookies': cookies
}# 发送HTTP请求
url = 'http://www.baidu.com/'
response = requests.get(url, headers=headers)
print(response.text)在这段代码中,我们先发送HTTP请求获取了网站的Cookies,然后将其设置到HTTP请求的headers中。
四、总结
本文介绍了Python爬虫入门教程,主要讲解了如何使用Python爬取网页数据,使用代理IP和反爬虫技术等技巧。通过学习本文,您可以轻松地掌握Python爬虫开发的基本技巧,从而更加高效地进行数据采集和处理。
相关文章

班级新闻管理系统asp.net+sqlserver

企业年会/年终活动如何邀请媒体记者报道?

9 mysql调优
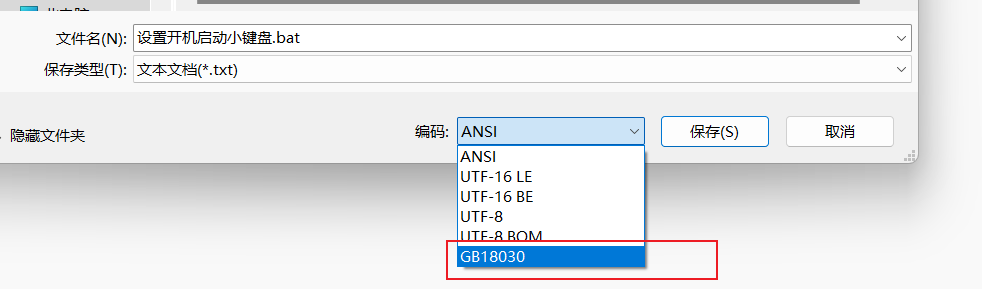
开机自启动笔记本的小键盘
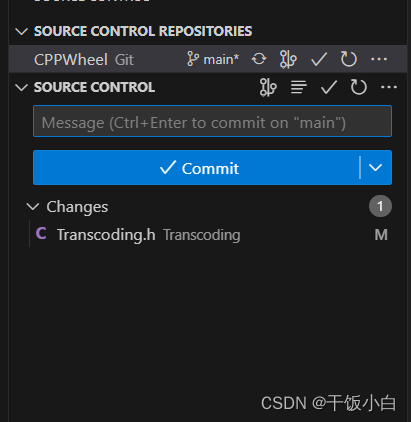
No source control providers registered

Exploration by random network distillation论文笔记
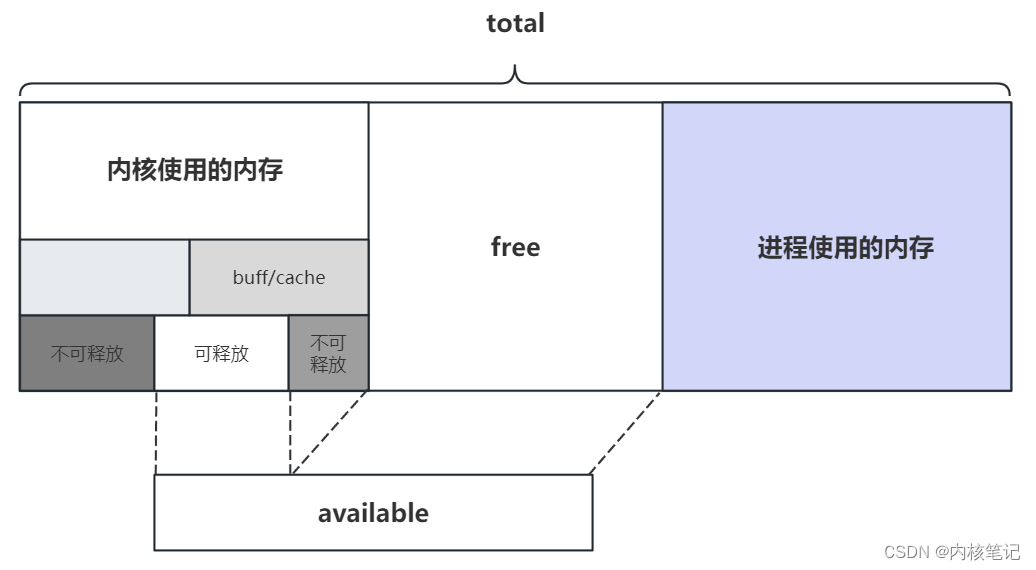
RK3399平台开发系列讲解(内存篇)free 命令查看内存占用情况介绍
【算法】算法题-20231111
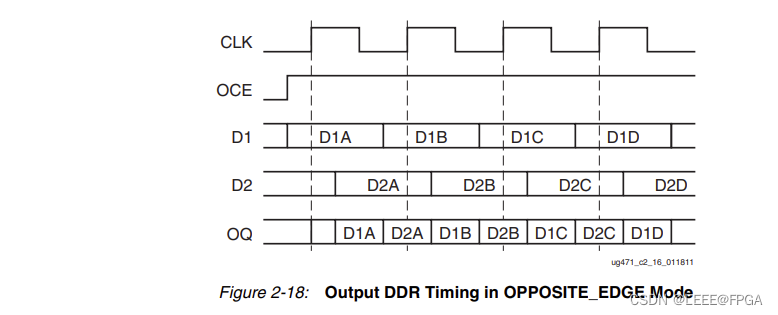
FPGA UDP RGMII 千兆以太网(3)ODDR

赛宁网安入选国家工业信息安全漏洞库(CICSVD)2023年度技术组成员单
Angular 由一个bug说起之一:List / Grid的性能问题

Wix使用velo添加Google ads tag并在form表单提交时向谷歌发送事件
uniapp+vue3+ts+vite+echarts开发图表类小程序,将echarts导入项目使用的详细步骤,耗时一天终于弄好了

【蓝桥杯选拔赛真题17】C++时间换算 第十二届蓝桥杯青少年创意编程大赛C++编程选拔赛真题解析

【广州华锐互动】太空探索VR模拟仿真教学系统
跨时钟域(Clock Domain Crossing,CDC)
原型制作神器ProtoPie的使用Unity与网页跨端交互
竞赛选题 深度学习疲劳检测 驾驶行为检测 - python opencv cnn

学者观察 | 数字经济中长期发展中的区块链影响力——清华大学柴跃廷
LeetCode(6)轮转数组【数组/字符串】【中等】
- Sourcetree安装教程及使用
- js 如何封装一个iframe通讯的sdk
- 一文读懂 javascript 函数返回值
- 脑机接口:是现代医学的外挂,更是瘫痪病人的豪赌
- 赶紧收藏!2024 年最常见 20道 Redis面试题(五)
- python mp3转mp4工具
- 《心理学报》文本分析技术最新进展总结盘点
- C++ Primer Chapter 3 Strings, Vectors, and Arrays
- webpack5_相关知识点
- Java学习52-迭代器 iterator
- Python怎么实现动态的方法调用?比如Ruby就有元编程
- 离大模型落地应用最近的工程化技术(RAG)
- 【计网】广播域和冲突域
- 操作系统真象还原:完善MBR
- 【文末附gpt升级方案】GPT-4级别的AI系统安全性探讨与未来展望
- CSS:浮动
- 营销短信XML接口对接发送示例
- 赎金信-力扣