
爬虫技术是做什么的?
简单来讲, 爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,从这个链接跳到那个链接,查查数据,或者把看到的信息传输回去。就像一只蜘蛛在互联网这张大网上不知疲倦的爬来爬去。
你每天使用的百度,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。
抢票软件,就相当于撒出去无数个分身,每一个分身都帮助你不断刷新 12306 网站的火车余票。一旦发现有票,就马上拍下来,然后对你喊:土豪快来付款。
这些都可以使用爬虫来实现,爬虫其实可以代替人类完成一些重复无聊的工作,例如:你想将小明的网站博客搬到自己网站,但是你又不想一篇一篇的复制,于是你用爬虫批量采集,完成这项工作可能需要人工3天左右的时间,而使用爬虫只需要1-2分钟左右,大大节省了人力。
当然大部分爬虫技术还是用来采集数据的,之后对数据进行清洗,符合项目要求。
爬虫采集数据的主要步骤
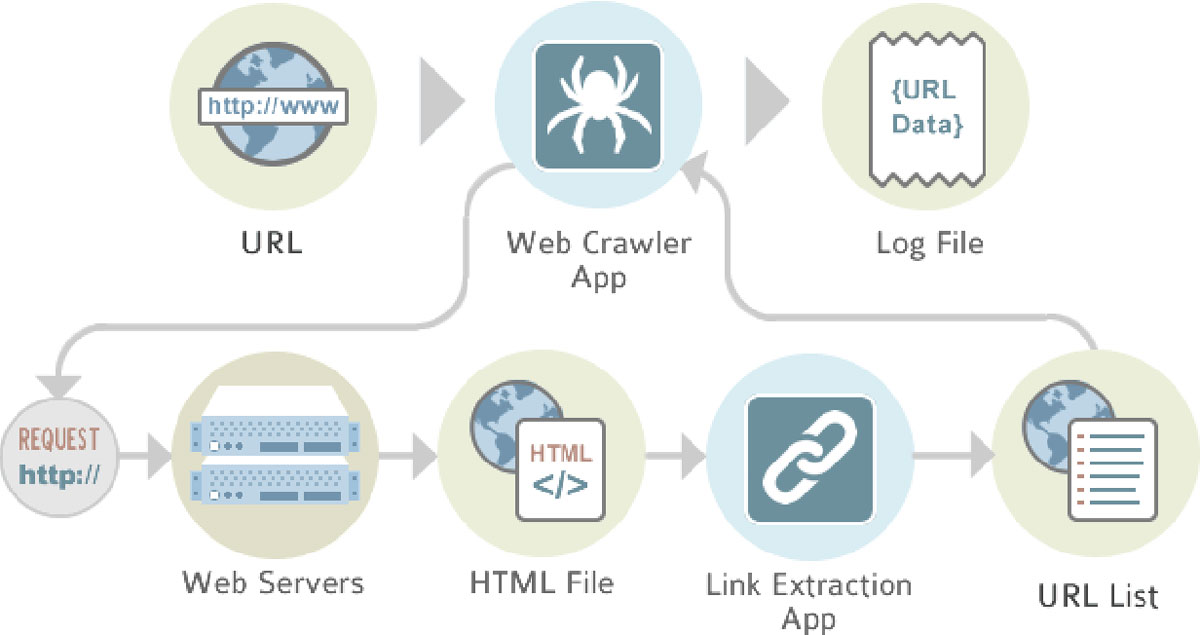
- 获取网页
获取网页可以简单理解为向网页的服务器发送网络请求,然后服务器返回给我们网页的源代码,其中通信的底层原理较为复杂,而Python给我们封装好了urllib库和requests库等,这些库可以让我们非常简单的发送各种形式的请求。
- 提取信息
获取到的网页源码内包含了很多信息,想要进提取到我们需要的信息,则需要对源码还要做进一步筛选。可以选用python中的re库即通过正则匹配的形式去提取信息,也可以采用BeautifulSoup库(bs4)等解析源代码,除了有自动编码的优势之外,bs4库还可以结构化输出源代码信息,更易于理解与使用。
- 保存数据
提取到我们需要的有用信息后,需要在Python中把它们保存下来。可以使用通过内置函数open保存为文本数据,也可以用第三方库保存为其它形式的数据,例如可以通过pandas库保存为常见的xlsx数据,如果有图片等非结构化数据还可以通过pymongo库保存至非结构化数据库中。
- 让爬虫自动运行
从获取网页,到提取信息,然后保存数据之后,我们就可以把这些爬虫代码整合成一个有效的爬虫自动程序,当我们需要类似的数据时,随时可以获取。
-
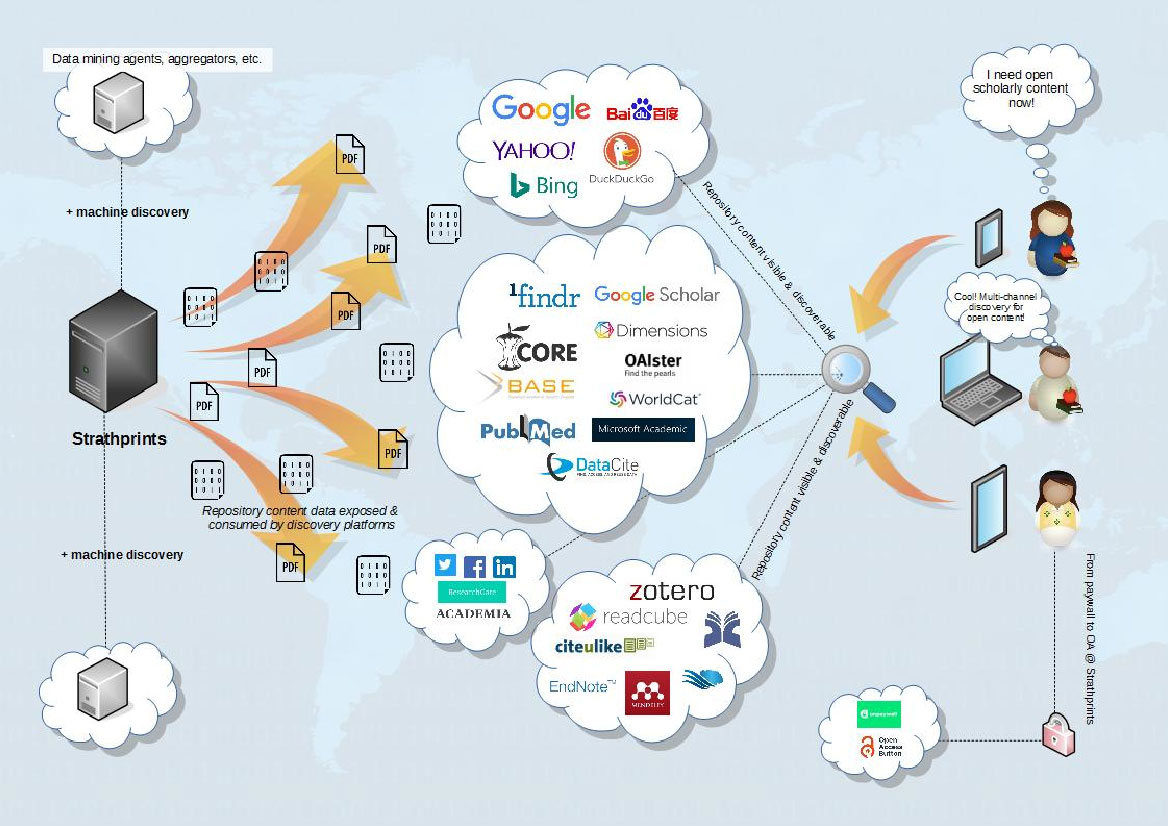
搜索引擎与爬虫
爬虫数据采集
-
搜索引擎与爬虫
爬虫常说的君子协议是什么
-
![望着远方的小狗]()
网站管理
网站进入测试阶段
-
![望着远方的小狗]()
网站管理
ICP备案和公安网备案通过
-
![望着远方的小狗]()
网站管理
爬虫识别支持 IPv6 地址访问
-
![IPv4 地址耗尽,为什么 IPv6 没有广泛将其取代?]()
IP 与 AS
IPv4 地址耗尽,为什么 IPv6 没有广泛将其取代?



