




概述:
最近在研究数据结构和算法,花了些时间对比较常用的算法做了一下简单的整理,并自我进行的测试。
经典10大排序汇总:
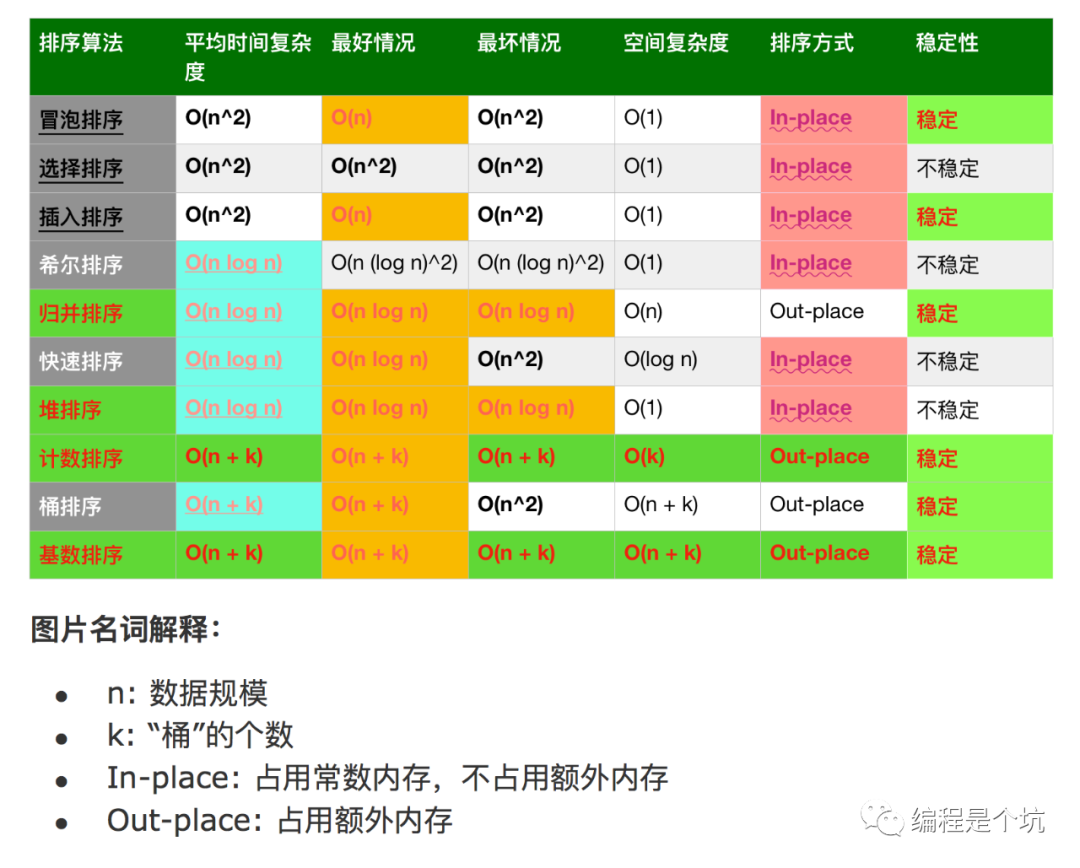
名词描述:1、稳定:如果原来 a 在 b前边,且 a = b;排序之后a仍然在b的前面。2、不稳定:与稳定相对应,排序之后 a 可能会在 b 后边。3、内排序(In-place):所有排序操作都在内存中完成。4、外排序(Out-place):由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行。5、时间复杂度:一个算法执行所耗费的时间。6、空间复杂度:运行完一个程序所需内存的大小。
算法实现
抽象ISor类,封装swap(数组中元素交换)、randomArrs(生产随机数组)
、display(方便打印输出数组)
package cn.jdk8.test.sorts;public class ISort {/*** 元素互换 swap* @param arr* @param i index 为i* @param j index 为j* @param <T>*/public static <T extends Comparable<T>> void swap(T[] arr, int i, int j) {T t = arr[i];arr[i] = arr[j];arr[j] = t;}/*** 生成有n个元素的随机数组,每个元素的随机范围为[rangeL, rangeR]* @param n* @param rangeL* @param rangeR* @return*/public static <T> T[] randomArrs(int n, int rangeL, int rangeR) {assert rangeL <= rangeR;T[] arr = (T[]) new Integer[n];for (int i = 0; i < n; i++)arr[i] = (T)new Integer((int)(Math.random() * (rangeR - rangeL + 1) + rangeL));return arr;}/*** 打印输出数组* @param arr* @param <T>*/public static <T> void display(T[] arr) {System.out.print("[");for (int i = 0; i < arr.length; i++) {T ts = arr[i];if (i == arr.length - 1) {System.out.println(ts + "]");break;}System.out.print(ts + ", ");}}}
一:冒泡排序 |
package cn.jdk8.test.sorts;/*** @author jaylee* @description: 冒泡排序:* 排序方式:In-place* @author: Mr.JayLee* @create: 2020-04-27 21:49*/public class _01_BubbleSort extends ISort {/*** 冒泡排序 优化版本** @param arr* @param <T>*/public static <T extends Comparable<T>> void sort(T[] arr) {assert arr != null;//标记是否已发生 元素交换boolean exchanged = true;int cycleNum = 0;for (int i = 0; i < arr.length - 1 && exchanged; i++) {exchanged = false;//todo 这里限制边界需要注意, 长度递减 -1, 防止数组越界cycleNum++;for (int j = 0; j < arr.length - 1 - i; j++) {if (arr[j].compareTo(arr[j + 1]) > 0) {swap(arr, j, j + 1);exchanged = true;// todo 前大后,交换}}}System.out.println("遍历 " + cycleNum + " 次");//遍历 89728 次}public static void main(String[] args) {int N = 90000;Integer[] arr = randomArrs(N, 1, 2000000000);long startTime = System.currentTimeMillis();sort(arr);long endTime = System.currentTimeMillis();System.out.println(" 冒泡排序(优化版)耗费时间 :" + (endTime - startTime) + " 毫秒");//33801 毫秒display(arr);}}
| 二:选择排序 |
package cn.jdk8.test.sorts;/*** @author jaylee* @description: 选择排序:* 排序方式:In-place* @author: Mr.JayLee* @create: 2020-04-30 22:54*/public class _02_SelectSort extends ISort {/*** 选择排序** @param arr* @param <T> 实现了Comparable的比较数据类型*/public static <T extends Comparable<T>> void sort(T[] arr) {assert arr != null;for (int i = 0; i < arr.length; i++) {int minIndex = i;for (int k = i + 1; k < arr.length; k++) {//todo 外层遍历一次,内部全部遍历找到minValue的index 赋值给 minIndexif (arr[k].compareTo(arr[minIndex]) < 0) {minIndex = k;}}swap(arr, i, minIndex);}}public static void main(String[] args) {int N = 90000;Integer[] arr = randomArrs(N, 1, 2000000000);long startTime = System.currentTimeMillis();sort(arr);long endTime = System.currentTimeMillis();System.out.println(" 选择排序耗费时间 :" + (endTime - startTime) + " 毫秒");//9369 毫秒 ,11007 毫秒,10168 毫秒display(arr);}}
| 三:插入排序 |
插入排序采用in-place在数组上实现。算法描述如下: |
package cn.jdk8.test.sorts;/*** @author jaylee* @description: 插入排序:* 排序方式:In-place* @author: Mr.JayLee* @create: 2020-04-30 23:25*/public class _03_InsertionSort extends ISort {/*** 插入排序** @param arr* @param <T>*/public static <T extends Comparable<T>> void sort1(T[] arr) {assert arr != null;//todo 从第2个元素开始for (int i = 1; i < arr.length; i++) {for (int j = i; j > 0 && arr[j - 1].compareTo(arr[j]) > 0; j--) {swap(arr, j, j - 1);}}}/*** 优化插入排序** @param arr* @param <T> 插入排序算法,优化版,在确定交换的元素后再进行交换位置,* 每次比较时先不交换,在最后确定最终交换位置时再执行交换.* <p>* 优化后,效率大大的提高了*/public static <T extends Comparable<T>> void sort(T[] arr) {assert arr != null;//todo 从第2个元素开始for (int i = 1; i < arr.length; i++) {T e = arr[i];//先记录要比较的元素,确定其交换的位置后再移动到对应位置int j;//记录j,最后交换时使用for (j = i; j > 0 && arr[j - 1].compareTo(e) > 0; j--) {arr[j] = arr[j - 1];}//arr[j] = e;//todo 此处可要可不要}}/*** 对 arr[l...r]区间 插入排序** @param arr* @param l* @param r* @param <T>*/public static <T extends Comparable<T>> void sort(T[] arr, int l, int r) {for (int i = l + 1; i <= r; i++) {T e = arr[i];int j = i;for (; j > l && arr[j - 1].compareTo(e) > 0; j--)arr[j] = arr[j - 1];arr[j] = e;}}public static void main(String[] args) {int N = 90000;Integer[] arr = randomArrs(N, 1, 2000000000);long startTime1 = System.currentTimeMillis();sort1(arr);long endTime1 = System.currentTimeMillis();System.out.println(" 插入排序耗费时间 :" + (endTime1 - startTime1) + " 毫秒");//15638 毫秒, 14764 毫秒 //todo 最理想状态(有序数组) 4 毫秒System.out.println("===============");long startTime = System.currentTimeMillis();sort(arr);long endTime = System.currentTimeMillis();System.out.println(" 插入排序(优化版)耗费时间 :" + (endTime - startTime) + " 毫秒");//15991 毫秒 //todo 最理想状态(有序数组) 4 毫秒display(arr);}}
| 四:希尔排序 |
package cn.jdk8.test.sorts;/*** @author jaylee* @description: 希尔排序:* 排序方式:In-place* @author: Mr.JayLee* @create: 2020-05-01 00:14*/public class _04_ShellSort extends ISort {/*** 希尔排序** @param arr* @param <T>*/public static <T extends Comparable<T>> void sort(T[] arr) {assert null != arr;int len = arr.length;T temp;int gap = len / 2;while (gap > 0) {for (int i = gap; i < len; i++) {temp = arr[i];int preIndex = i - gap;while (preIndex >= 0 && arr[preIndex].compareTo(temp) > 0) {arr[preIndex + gap] = arr[preIndex];preIndex -= gap;}arr[preIndex + gap] = temp;}gap /= 2;}}public static void main(String[] args) {int N = 90000;Integer[] arr = randomArrs(N, 1, 2000000000);long startTime = System.currentTimeMillis();sort(arr);long endTime = System.currentTimeMillis();System.out.println(" 希尔排序耗费时间 :" + (endTime - startTime) + " 毫秒");// 82 毫秒, 66 毫秒display(arr);}}
| 五:归并排序 |
package cn.jdk8.test.sorts;import java.lang.reflect.Array;/*** @author jaylee* @description: 归并排序:* 排序方式:Out-place* @author: Mr.JayLee* @create: 2020-05-01 00:30*/public class _05_00_MergeSort extends ISort {/*** 未优化版归并排序** @param array* @param <T>*/public static <T extends Comparable<T>> void sort(T[] array) {assert array != null;int n = array.length;mergeSort(array, 0, n - 1);}/*** 优化版归并排序** @param array* @param <T>*/public static <T extends Comparable<T>> void sortOptimize(T[] array) {assert array != null;int n = array.length;mergeSortOptimize(array, 0, n - 1);}/*** 归并排序算法优化版*/private static <T extends Comparable<T>> void mergeSortOptimize(T[] array, int l, int r) {// 优化: 对于小规模数组, 使用插入排序,在较小的数据范围内,数据近乎有序// 可能性非常,采用插入排序能提高效率if (r - l <= 15) {_03_InsertionSort.sort(array, l, r);return;}//计算分组间距int mid = l + (r - l) / 2;//递归分组mergeSort(array, l, mid);mergeSort(array, mid + 1, r);/*** 优化: 对于arr[mid] <= arr[mid+1]的情况,不进行merge* 对于近乎有序的数组非常有效,但是对于一般情况,有一定的性能损失*/if (array[mid].compareTo(array[mid + 1]) > 0) {//两边都分组完成即分组后数组元素只有一个后开始合并merge(array, l, mid, r);}}/*** 归并排序算法(未优化版)** @param array* @param l* @param r* @param <T>*/private static <T extends Comparable<T>> void mergeSort(T[] array, int l, int r) {//递归结束条件(分组后数组只有一个元素时不再分组)if (l >= r) {return;}//计算分组间距int mid = l + (r - l) / 2;//递归分组mergeSort(array, l, mid);mergeSort(array, mid + 1, r);//两边都分组完成即分组后数组元素只有一个后开始合并merge(array, l, mid, r);}/*** 合并函数** @param array* @param l* @param mid* @param r* @param <T>*/public static <T extends Comparable<T>> void merge(T[] array, int l, int mid, int r) {int len = r - l + 1;//创建临时数据辅助归并T[] temp = (T[]) Array.newInstance(array.getClass().getComponentType(), len);//把需要归并的元素全赋值给temp;for (int i = l; i <= r; i++) {temp[i - l] = array[i];}int i = l;int j = mid + 1;//执行归并操作(O(N)级别)for (int k = l; k <= r; k++) {if (i > mid) { //说明左边的元素已全部归并完成array[k] = temp[j - l];j++;} else if (j > r) { //说明右边的元素已全部归并完成array[k] = temp[i - l];i++;} else if (temp[i - l].compareTo(temp[j - l]) > 0) {//左边的元素大于右边array[k] = temp[j - l];j++;} else if (temp[i - l].compareTo(temp[j - l]) < 0) { //右边的元素大于左边array[k] = temp[i - l];i++;}}}public static void main(String[] args) {int N = 90000;Integer[] arr = randomArrs(N, 1, 2000000000);long startTime0 = System.currentTimeMillis();sort(arr);long endTime0 = System.currentTimeMillis();System.out.println(" 归并排序耗费时间 :" + (endTime0 - startTime0) + " 毫秒");//192 毫秒, 177 毫秒 //todo 最理想状态(有序数组) 48 毫秒System.out.println("===============");long startTime = System.currentTimeMillis();sortOptimize(arr);long endTime = System.currentTimeMillis();System.out.println(" 归并排序(优化版)耗费时间 :" + (endTime - startTime) + " 毫秒");//159 毫秒 //todo 最理想状态(有序数组) 42 毫秒, 28 毫秒display(arr);}}
| 六:快速排序 |
package cn.jdk8.test.sorts;/*** @author jaylee* @description: 快速排序方法:* 排序方式:In-place* @author: Mr.JayLee* @create: 2020-05-01 02:11*/public class _06_QuickSort extends ISort {/*** 未优化快速排序入口* @param arr* @param <T>*/public static <T extends Comparable<T>> void QuickSort(T[] arr) {assert arr != null;QuickSort(arr, 0, arr.length - 1);}/*** 快速排序方法** @param arr* @param start* @param end* @param <T>*/public static <T extends Comparable<T>> T[] QuickSort(T[] arr, int start, int end) {int length = arr.length;if (length < 1 || start < 0 || end >= length || start > end) return null;int smallIndex = partition(arr, start, end);if (smallIndex > start)QuickSort(arr, start, smallIndex - 1);if (smallIndex < end)QuickSort(arr, smallIndex + 1, end);return arr;}/*** 快速排序主入口** @param arr* @param <T>*/public static <T extends Comparable<T>> void sort(T[] arr) {assert arr != null;quickSort(arr, 0, arr.length - 1);}/*** 使用递归实现快速排序** @param arr* @param l* @param r* @param <T>*/public static <T extends Comparable<T>> void quickSort(T[] arr, int l, int r) {//如果排序的数组元素个数少于16直接使用插入排序即可(优化点)if (r - l < 16) {_03_InsertionSort.sort(arr, l, r);return;}//获取分区的基准点的数组下标pint p = partition(arr, l, r);//使用递归的方式继续进行分区quickSort(arr, l, p - 1); //处理左侧数组quickSort(arr, p + 1, r); //处理右侧数组}/*** 进行分区操作* 对arr[l...r]部分进行partition操作* 返回p, 使得arr[l...p-1] < arr[p] ; arr[p+1...r] > arr[p]*/private static <T extends Comparable<T>> int partition(T[] arr, int l, int r) {//随机在arr[l...r]的范围中, 选择一个数值作为标定点pivot//之所以要随机选择,是为了防止在出现大规模近乎有序的数据时若只取左边的值可能会//造成快速排序算法退化到O(N²)级别,与二叉树退化成链表是同样的道理.swap(arr, l, (int) (Math.random() * (r - l + 1)) + l);//确定分组元素T e = arr[l];// 进行分区操作,使用得 arr[l+1...j] < v < arr[j+1...i) i是当前正在判断的元素int j = l;//注意i需要从1+1起for (int i = l + 1; i <= r; i++) {//当前元素比基准点元素小,移动到e的左侧.//当前元素比基准点元素大,无需移动.if (arr[i].compareTo(e) < 0) {swap(arr, j + 1, i);j++;//j往后移动一位}}//最后将基准点移动到j的位置,形成arr[l...j-1] < arr[j] < arr[j+1...r]swap(arr, j, l);//返回基准点下标return j;}public static void main(String[] args) {int N = 90000;Integer[] arr = randomArrs(N, 1, 2000000000);long startTime0 = System.currentTimeMillis();QuickSort(arr);long endTime0 = System.currentTimeMillis();System.out.println(" 快速排序(_06_QuickSort)耗费时间 :" + (endTime0 - startTime0) + " 毫秒");//41 毫秒, 40 毫秒, 38 毫秒, 44 毫秒, 41 毫秒, 47 毫秒, 55 毫秒, 48 毫秒, 46 毫秒, 48 毫秒System.out.println("========================");long startTime = System.currentTimeMillis();sort(arr);long endTime = System.currentTimeMillis();System.out.println(" 快速排序(sort)耗费时间 :" + (endTime - startTime) + " 毫秒");//38 毫秒, 32 毫秒, 40 毫秒, 47 毫秒, 47 毫秒, 46 毫秒, 42 毫秒, 54 毫秒, 52 毫秒, 48 毫秒display(arr);}}
| 七:堆排序 |
package cn.jdk8.test.sorts;import java.util.stream.IntStream;/*** @author jaylee* @description: 堆排序算法 && topMaxN* 排序方式:In-place* @author: Mr.JayLee* @create: 2020-05-01 02:46*/public class _07_HeapSort extends ISort {//声明全局变量,用于记录数组array的长度;volatile static int len;/*** 堆排序算法** @param arr* @param <T>* @return*/public static <T extends Comparable<T>> T[] heapSort(T[] arr) {len = arr.length;if (len < 1) return arr;//1.构建一个最大堆buildMaxHeap(arr);//2.循环将堆首位(最大值)与末位交换,然后在重新调整最大堆while (len > 0) {swap(arr, 0, len - 1);len--;adjustHeap(arr, 0);}return arr;}/*** 建立最大堆** @param array* @param <T>*/public static <T extends Comparable<T>> void buildMaxHeap(T[] array) {//从最后一个非叶子节点开始向上构造最大堆for (int i = ((len >> 1) - 1); i >= 0; i--) {adjustHeap(array, i);}}/*** 调整使之成为最大堆** @param array* @param i* @param <T>*/public static <T extends Comparable<T>> void adjustHeap(T[] array, int i) {int maxIndex = i;//如果有左子树,且左子树大于父节点,则将最大指针指向左子树if ((i << 1) < len && array[(i << 1)].compareTo(array[maxIndex]) > 0)maxIndex = i << 1;//如果有右子树,且右子树大于父节点,则将最大指针指向右子树if ((i << 1) + 1 < len && array[(i << 1) + 1].compareTo(array[maxIndex]) > 0)maxIndex = (i << 1) + 1;//如果父节点不是最大值,则将父节点与最大值交换,并且递归调整与父节点交换的位置。if (maxIndex != i) {swap(array, maxIndex, i);adjustHeap(array, maxIndex);}}/*** 获取 topMaxN** @param arr 堆排序之后的数组* @param topMaxN 取最大值 多少个* @param <T> 数据类型* @return*/public static <T extends Comparable<T>> T[] topMaxN(T[] arr, int topMaxN) {//System.out.println("from [ max arr length : " + arr.length + " ] to topMaxN :" + topMaxN);T[] maxTops = (T[]) new Integer[topMaxN];IntStream.range(0, topMaxN).forEachOrdered(i -> {int arrTail = (arr.length - 1) - i;maxTops[i] = arr[arrTail];});return maxTops;}public static void main(String[] args) {//int N = 90000; //todo 9万个数中(topMax 1000 耗时(avg = 116 毫秒) : 117 毫秒, 116 毫秒, 114 毫秒, 117 毫秒, 116 毫秒 )int N = 100000; //todo 十万个数中(topMax 1000 耗时(avg = 122 毫秒) : 124 毫秒, 118 毫秒, 121 毫秒, 124 毫秒, 122 毫秒 )//int N = 1000000;//todo 百万个数中(topMax 1000 耗时(avg = 714 毫秒) : 703 毫秒, 719 毫秒,717 毫秒,712 毫秒,717 毫秒 )//int N = 10000000;//todo 千万个数中(topMax 1000 耗时(avg = 12094 毫秒) : 12327 毫秒,12174 毫秒, 12210 毫秒, 11874 毫秒, 11882 毫秒 )Integer[] arr = randomArrs(N, 1, 2000000000);//display(arr);long startTime = System.currentTimeMillis();Integer[] heapSort = heapSort(arr);long endTime = System.currentTimeMillis();System.out.println(" 堆排序耗费时间 :" + (endTime - startTime) + " 毫秒");//45 毫秒, 58 毫秒, 48 毫秒,45 毫秒, 53 毫秒, 48 毫秒//display(heapSort);/************* 堆排序完后, 取出 topMaxN ***************/int topMaxN = 1000;Integer[] topMaxNs = topMaxN(heapSort, topMaxN);//display(topMaxNs);long topMaxEndTime = System.currentTimeMillis();System.out.println(" [ arr.length : " + arr.length + " ], " +"堆排序后,取出 { topMaxN ::: " + topMaxN + " } 耗费时间 :" + (topMaxEndTime - startTime) + " 毫秒");//115 毫秒, 117 毫秒, 118 毫秒display(topMaxNs);}}
| 八:计数排序 |
package cn.jdk8.test.sorts;import java.util.Arrays;/*** @author jaylee* @description: 计数排序:* 排序方式:Out-place* @author: Mr.JayLee* @create: 2020-05-01 04:01*/public class _08_CountingSort extends ISort {/*** 计数排序** @param array* @return*/public static Integer[] countingSort(Integer[] array) {if (array.length == 0) return array;int bias, min = array[0], max = array[0];for (int i = 1; i < array.length; i++) {if (array[i] > max)max = array[i];if (array[i] < min)min = array[i];}bias = 0 - min;int[] bucket = new int[max - min + 1];/*** {@linkplain java.util.Arrays#fill(int[], int)}*/Arrays.fill(bucket, 0);for (int i = 0; i < array.length; i++) {bucket[array[i] + bias]++;}int index = 0, i = 0;while (index < array.length) {if (bucket[i] != 0) {array[index] = i - bias;bucket[i]--;index++;} elsei++;}return array;}public static void main(String[] args) {System.out.println(Integer.MAX_VALUE);// 2147483647 Integer.maxValue 21亿多int N2 = 900000; //816 毫秒, 899 毫秒, 836 毫秒, 867 毫秒, 869 毫秒int N = 90000; //746 毫秒, 756 毫秒, 712 毫秒, 710 毫秒, 704 毫秒, 785 毫秒Integer[] arr = randomArrs(N, 1, 200000000);//todo 计数排序 最大排 2亿数据display(arr);long startTime0 = System.currentTimeMillis();//todo 计数排序Integer[] countSorts = countingSort(arr);long endTime0 = System.currentTimeMillis();System.out.println(" [ N :" + N + " ], 计数排序 \n"+ " 计数排序耗费时间 :" + (endTime0 - startTime0) + " 毫秒");display(countSorts);}}
| 九:桶排序 |
package cn.jdk8.test.sorts;import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;import java.util.stream.Stream;/*** @author jaylee* @description: 桶排序:* 排序方式:Out-place* @author: Mr.JayLee* @create: 2020-05-01 04:32*/public class _09_BucketSort extends ISort {/*** 桶排序** @param arr 数组 arr* @param <T> 数组数据类型* @return*/public static <T extends Comparable<T>> T[] bucketSort(T[] arr) {List<T> toList = Stream.of(arr).collect(Collectors.toList());int bucketSize = 16;List<T> sortList = bucketSort(toList, bucketSize);T[] toArr = (T[]) sortList.stream().toArray(Integer[]::new);return toArr;}/*** 桶排序** @param array* @param bucketSize* @return*/public static <T extends Comparable<T>> List<T> bucketSort(List<T> array, int bucketSize) {assert array != null || array.size() >= 2;T max = array.get(0), min = array.get(0);// todo 找到最大值最小值for (int i = 0; i < array.size(); i++) {if (array.get(i).compareTo(max) > 0) max = array.get(i);if (array.get(i).compareTo(min) < 0) min = array.get(i);}int bucketCount = (Integer.parseInt(max.toString()) - Integer.parseInt(min.toString())) / bucketSize + 1;List<List<T>> bucketArr = new ArrayList<>(bucketCount);List<T> resultList = new ArrayList<>();for (int i = 0; i < bucketCount; i++) {bucketArr.add(new ArrayList<T>());}for (int i = 0; i < array.size(); i++) {bucketArr.get((Integer.parseInt(array.get(i).toString()) - Integer.parseInt(min.toString())) / bucketSize).add(array.get(i));}for (int i = 0; i < bucketCount; i++) {if (bucketSize == 1) { // 如果带排序数组中有重复数字时 感谢 @见风任然是风 朋友指出错误for (int j = 0; j < bucketArr.get(i).size(); j++)resultList.add(bucketArr.get(i).get(j));} else {if (bucketCount == 1)bucketSize--;List<T> temp = bucketSort(bucketArr.get(i), bucketSize);for (int j = 0; j < temp.size(); j++)resultList.add(temp.get(j));}}return resultList;}public static void main(String[] args) {int N = 90000; // 5386 毫秒, 5330 毫秒, 5319 毫秒,5686 毫秒Integer[] arr = randomArrs(N, 1, 200000000);//todo 桶排序 最大排 2亿数据,再大效率就gg了display(arr);long startTime0 = System.currentTimeMillis();//todo 桶排序Integer[] countSorts = bucketSort(arr);long endTime0 = System.currentTimeMillis();System.out.println(" [ N :" + N + " ], 桶排序 \n"+ " 桶排序耗费时间 :" + (endTime0 - startTime0) + " 毫秒");display(countSorts);}}
| 十:基数排序 |
package cn.jdk8.test.sorts;/*** @author jaylee* @description: 基数排序:* 排序方式:Out-place* @author: Mr.JayLee* @create: 2020-05-01 05:41*/import java.util.ArrayList;import java.util.List;/*** 算法描述* 取得数组中的最大数,并取得位数;* arr为原始数组,从最低位开始取每个位组成radix数组;* 对radix进行计数排序(利用计数排序适用于小范围数的特点);*/public class _10_RadixSort extends ISort {/* todo基数排序 vs 计数排序 vs 桶排序这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:1、todo 基数排序:根据键值的每位数字来分配桶2、todo 计数排序:每个桶只存储单一键值3、todo 桶排序:每个桶存储一定范围的数值*//*** 基数排序** @param arr* @return*/public static <T extends Integer> T[] radixSort(T[] arr) {if (arr == null || arr.length < 2)return arr;// 1.先算出最大数的位数;int max = arr[0];for (int i = 1; i < arr.length; i++) {max = Math.max(max, arr[i]);}int maxDigit = 0;while (max != 0) {max /= 10;maxDigit++;}int mod = 10, div = 1;List<List<T>> bucketList = new ArrayList<>();for (int i = 0; i < 10; i++)bucketList.add(new ArrayList<T>());for (int i = 0; i < maxDigit; i++, mod *= 10, div *= 10) {for (int j = 0; j < arr.length; j++) {int num = (Integer.parseInt(arr[j].toString()) % mod) / div;bucketList.get(num).add(arr[j]);}int index = 0;for (int j = 0; j < bucketList.size(); j++) {for (int k = 0; k < bucketList.get(j).size(); k++)arr[index++] = bucketList.get(j).get(k);bucketList.get(j).clear();}}return arr;}public static void main(String[] args) {int N = 90000; // 191 毫秒,205 毫秒,203 毫秒,208 毫秒, 209 毫秒Integer[] arr = randomArrs(N, 1, 2000000000);//todo 基数排序 最大排 20亿数据display(arr);long startTime0 = System.currentTimeMillis();//todo 基数排序Integer[] countSorts = radixSort(arr);long endTime0 = System.currentTimeMillis();System.out.println(" [ N :" + N + " ], 基数排序 \n"+ " 基数排序耗费时间 :" + (endTime0 - startTime0) + " 毫秒");display(countSorts);}}
java
文章转载自 编程是个坑,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
