




MongoDB存储引擎数据持久化和索引原理
MongoDB基础概念
文档数据库
MongoDB是一种文档数据库,MongoDB 中的记录是一个文档,它是由字段和值对组成的数据结构。MongoDB 文档类似于 JSON对象。字段的值可能包括其他文档、数组和文档数组。
文档数据库的优点体现在以下几点:
1.文档(即bson对象)对应于许多编程语言中的原生数据类型,有利于在应用程序中对数据库数据直接存取。
2.内嵌的文档和数组减少了代价很高的join操作,提高了性能。
3.动态的数据模式支持灵活的数据形式(不像关系型数据库限定死了,每行数据拥有的属性都是一样,即便没有也要填空值)。
MongoDB把文档存储在集合中(collections),集合类似于关系数据库中的表,而文档类似于关系型数据库中的一行数据。
MongoDB的关键特性
1.高性能
MongoDB 提供高性能的数据持久化。特别是,
对内嵌的文档数据模型的支持减少了数据库系统上的磁盘 I/O 次数。
索引支持更快的查询,并且可以支持丰富的查询语句和索引类型,包括全文索引和地理位置索引查询;
2.高可用性
MongoDB的复制工具,也称为副本集,即一组MongoDB服务器维护一样的数据集来提供数据冗余和自动故障转移以增加数据高可用性。
3.水平可扩展性
MongoDB 提供水平可扩展性作为其核心功能的一部分,支持基于shard key创建数据区域,分片(sharding)技术将数据分布在一个集群的不同机器上。在一个稳定的集群中,MongoDB可以做到直接从包含数据分片(shard)的数据区域(服务器)读写数据。
存储引擎概念和数据结构
存储引擎是数据库中负责管理数据在内存和磁盘上的存储方式的组件,通俗点说就是——存储引擎要做的事情是将磁盘上的数据读到内存并返回给应用,或者将应用修改的数据由内存写到磁盘上。MongoDB使用插件式存储引擎,实现了Server层和存储引擎层的解耦,可以支持多种存储引擎,目前MongoDB默认使用的存储引擎是WiredTiger存储引擎。WiredTiger存储引擎默认使用B-Tree(确切地说是B+ Tree)数据结构来组织存储。
B-Tree
B-Tree是一种多叉平衡搜索树数据结构,它维护已排序的数据并允许在对数时间内进行搜索、顺序访问、插入和删除。B 树非常适合读写相对较大的数据块的存储系统,例如磁盘。它通常用于数据库和文件系统。
B-Tree的定义如下,一个 m 阶的B树是一个有以下属性的树:
每一个节点最多有 m 个子节点
每一个非叶子节点(除根节点)最少有 ⌈m/2⌉ 个子节点
如果根节点不是叶子节点,那么它至少有两个子节点
有 k 个子节点的非叶子节点拥有 k − 1 个键
所有的叶子节点都在同一层
B-Tree是为磁盘或其它辅助存储设备而设计的一种数据结构,目的是为了在查找数据的过程中减少磁盘I/O的次数,一个典型的B-Tree结构如下图所示: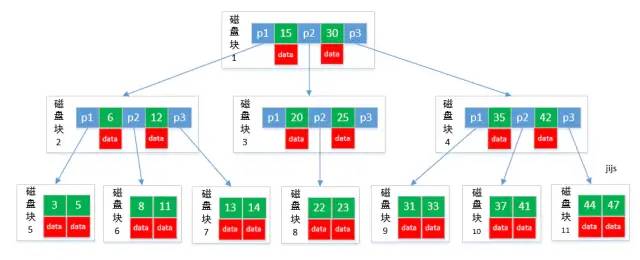
从B树定义和图1可以看出,B-Tree结构有三种节点,根节点,内部节点,叶子节点,根节点和内部节点一样,除了没有key数量最低限制,叶子节点没有执行子节点的指针域,内部节点有k个指针域和k-1个{key, data}数据域。
B树专门为磁盘存储而设计,但还有地方可以优化,减少IO次数的关键是降低B-Tree的层数,B树种非叶子节点也存储数据会导致B-Tree层数很高,而且B树不支持快速遍历。因此实际大部分数据库或文件系统中,会使用B树的一个变种——B+树作为存储数据结构。
B+ Tree
B+树与B树的区别在:
B+树的根节点和内部节点不存储数据,只存储子节点指针,所有数据全部存储在叶子节点,这样可以大大降低B-Tree的高度,减少IO次数,以4K块大小,8字节指针为例,一个节点可以存储512个子节点指针,第一层可以存储512个指针,第二层可以存储512*512个指针,第三层就可以存储512*512*4k = 1G的数据,最多4层一般就够用了,并且这个存储引擎使用的块(页)大小是可配的,一般大于4KB;
B+树的叶子节点之间,加了一个向右的指针(或者双向指针),组成叶子节点之间的一个链表,便于范围遍历;应用一般都有获取一个区间的需求,因此叶子节点连接成链表,能大大提高范围访问的效率;
WiredTiger存储引擎
查看当前MongoDB使用的存储引擎

图2: MongoDB使用的存储引擎
登录mongo客户端,连接上mongo服务器,执行db.serverStatus()["storageEngine"]可以看出MongoDB服务器默认使用的就是wiredTiger存储引擎;
索引使用的探究
索引检索的效果
为了实际体验索引对于查询的优化效果,我实际建立一个MongoDB数据和collection并插入数据来对比,不建索引和建索引的效果。
use db ldl_test_db;
for (var i = 1; i <= 1000000; i++) { db.ldl_collection.insert( { x : i , name: "liudinglong"+i, class:"class"+i, sex:"man"} ) }
for (var i = 1; i <= 1000000; i++) { db.ldl_collection_with_index.insert( { x : i , name: "liudinglong"+i, class:"class"+i, sex:"man"} ) }
# 创建x属性上升序的索引
db.ldl_collection_with_index.createIndex({"x":1})
我创建了两个集合,分别插入一样的数据,插入的文档数量有100,0000条(插入100,0000条数据是很耗时的操作,我大概花了10分钟),每个文档都有x,name,class,sex属性,一个集合不建索引,一个集合在x属性上建索引,然后分别在两个集合进行检索,对照一下效果。
两个集合分别执行db.ldl_collection.find({"x" : 678912}).explain("executionStats")["executionStats"]查看查询执行详情:
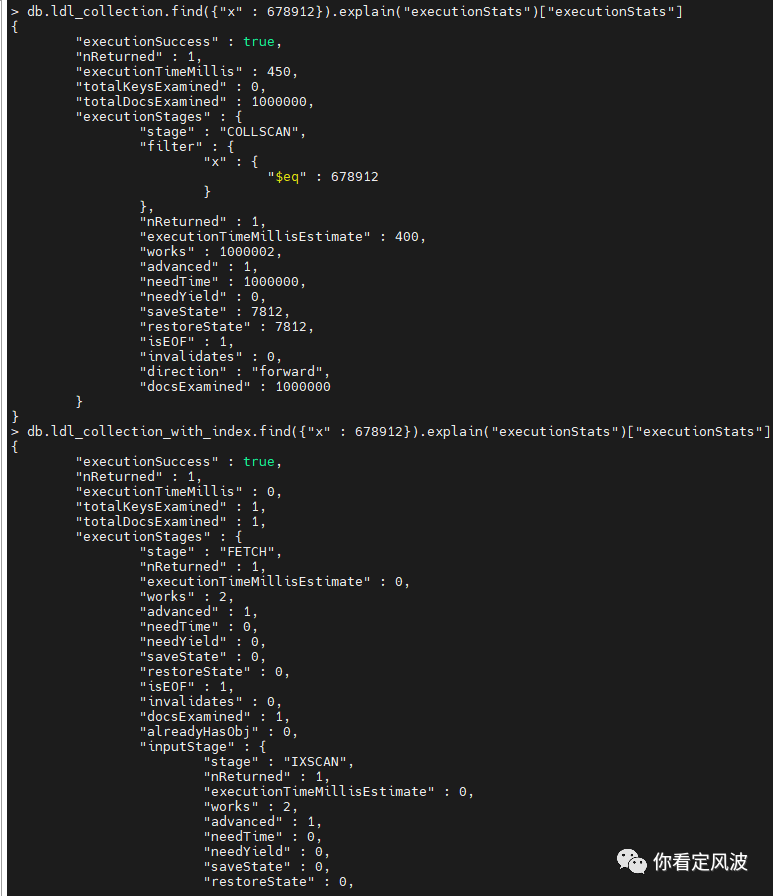
在查询计划中出现了很多 stage,下面列举的经常出现的 stage 以及它的含义:
COLLSCAN:全表扫描
IXSCAN:索引扫描
FETCH:根据前面扫描到的位置抓取完整文档
IDHACK:针对_id 进行查询
从图3查询结果可总结出以下关键信息:
无索引的集合查询耗时450ms;有索引的集合查询耗时0ms(不足1ms)
无索引的集合查询的"totalKeysExamined"为0,代表没有用到索引;有索引的集合查询的"totalKeysExamined"为1,扫描了一次索引;
无索引的集合查询的"totalDocsExamined"为100,0000,代表索引文档都扫描了一遍;有索引的集合查询的"totalKeysExamined"为1,只扫描了一个文档;
无索引的集合查询使用的是全表扫描,然后通过条件过滤;有索引的字段的查询直接通过索引扫描取数据。
有索引的查询效率比无索引的查询效率,高了成千上万倍,甚至百万倍;如果数据量再大点,这个差距更难以想象,一个文档的查询就可能要几秒甚至几十秒。所以在经常用于查询的属性上建立索引是非常必要的。
范围查询的效果
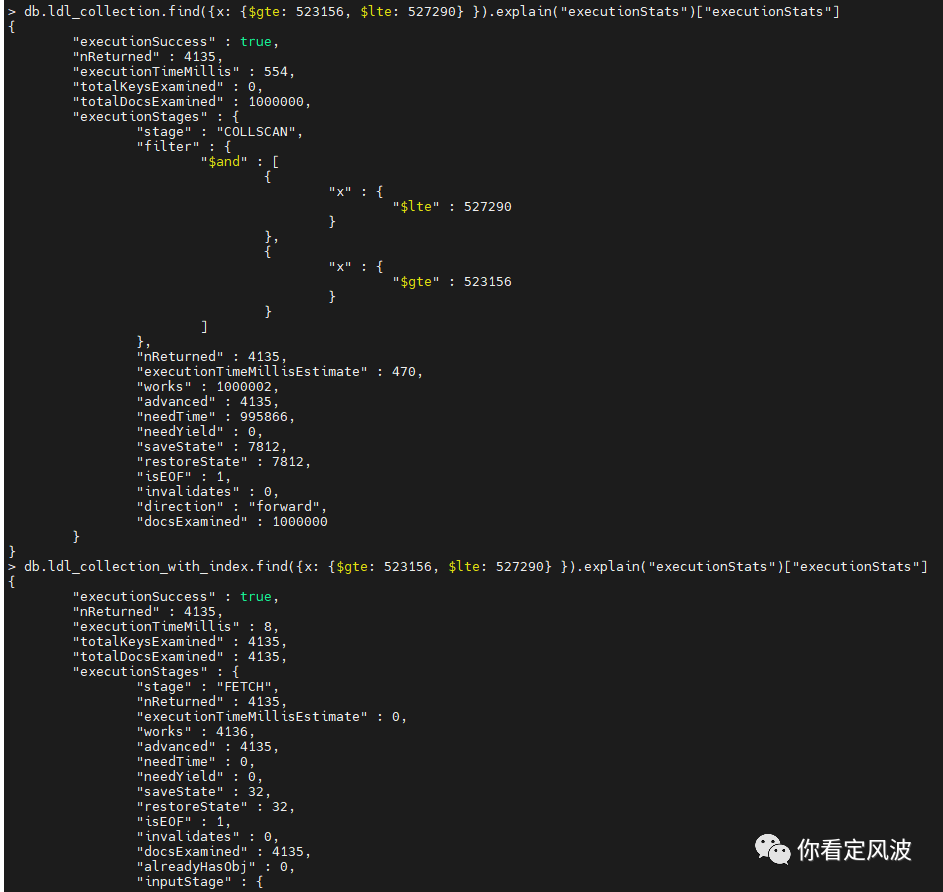
从上图可以看出,两个范围查询返回结果都是一样的——4135条文档,无索引的集合的查询进行全部扫描然后根据条件过滤,耗时554ms,有索引的集合利用索引扫描只耗时8ms,还是有明显的速度优势。
插入数据的性能对比
我们知道增加索引会提高查询效率,但是对于插入,删除,修改数据可能会有副作用,因为要维护对应索引的更新。我们测试一下插入10000条文档的速度对比:
在两个集合上分别执行以下语句
begintime = new Date()
var BASE= 1000000
for (var i = BASE + 1; i <= BASE+ 10000; i++) { db.ldl_collection_with_index.insert( { x : i , name: "liudinglong"+i, class:"class"+i, sex:"man"} ) }
endtime = new Date()
endtime - begintime
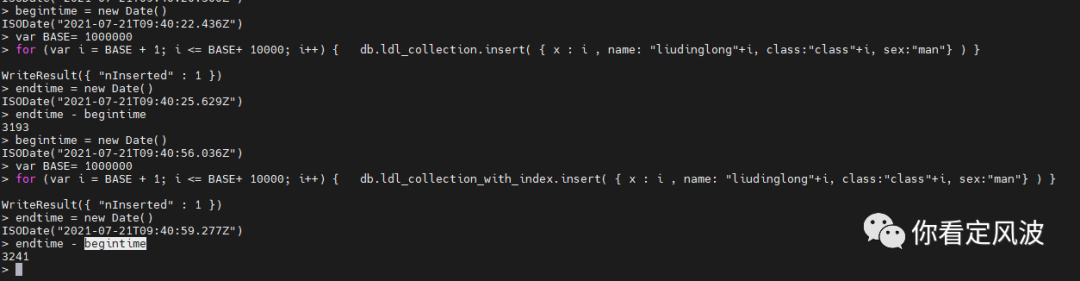
从上图可以看出无索引的集合插入10000条文档耗时3193ms,有索引的集合插入10000条文档耗时3241ms。这个差距微乎其微,相比于查询带来的巨大性能提升几乎可以忽略不计。可以想象更新和删除数据也类似,而且如果是在有索引的字段更新,有索引的集合更新应该还要快于没索引的更新,因为更新是先查找再更新。
wiredTiger存储引擎底层数据文件
WiredTiger启动时,会生成数据文件、索引文件、存储checkpoint等信息的元文件、实现数据持久化和数据库恢复的事务日志文件以及用于诊断分析的数据库运行日志文件。
下面先看下磁盘mongodb数据目录下生成的文件,如下图所示:
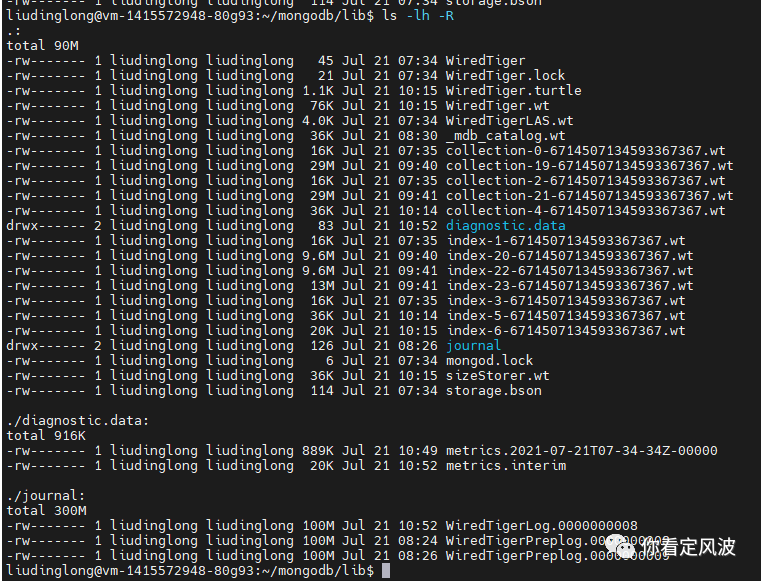
collection-xxx.wt和index-xxx.wt类文件
这是数据库中集合所对应的数据文件和索引文件。
可以通过如下命令查看集合在磁盘上对应的索引文件和数据文件:
> db.ldl_collection.stats({"indexDetails":true})["wiredTiger"]["uri"]
statistics:table:collection-19-6714507134593367367
# _id_是索引名称,如果有多个索引,indexDetails会有多个索引的信息
> db.ldl_collection.stats({"indexDetails":true})["indexDetails"]["_id_"]["uri"]
statistics:table:index-20-6714507134593367367
从上图可以看出我两个表分别插入了101万条数据,collection-XXX.wt数据文件都是29M,主键索引都是9.6M,另外我在其中一个表的x属性上建了索引,是13M。另外MongoDB的索引与数据文件完全分开,可以推断出MongoDB使用的非聚簇索引,即主键索引的叶子节点存储的是文档位置的指针,而非实际数据。
另外查看数据表状态
db.ldl_collection.stats()
{
"ns" : "ldl_test_db.ldl_collection",
"size" : 97767805, # 约93M
"count" : 1010000,
"avgObjSize" : 96,
"storageSize" : 30138368, # 约29M
}
可以看出1010000条数据,实际大小有93M,但在磁盘存储大小只占29M,证明wt文件格式是经过压缩的,而且压缩比例很可观,有3.24倍。
WiredTiger.lock文件:
这是WiredTiger运行实例的锁文件,防止多个进程同时连接同一个Wiredtiger实例。
mongod.lock文件:
这是MongoDB启动后在磁盘上创建的一个与守护进程mongod相关的锁文件,这个文件会记录mongod在运行过程中的一些状态信息,当正常关闭mongod时,会清除mongod.lock文件里面的内容;如果mongod.lock文件内容没有被清除,则说明mongod非正常的关闭;
sizeStorer.wt文件:
存储所有集合的容量信息,如集合中包含的文档数、总数据大小。
_mdb_catalog.wt文件:
存储的是集合表名与磁盘上数据文件和索引文件间的对应关系。这个映射关系也可以通过前面介绍的集合命令:db.ldl_collection.stats({“indexDetails”:true})获得。
WiredTigerLAS.wt文件:
存储的是内存里面lookaside table的持久化的数据。当对一个page进行reconcile时,如果系统中还有之前的读操作正在访问此page上的修改数据,则会将这些数据保存到lookaside table;当page再被读时,可以利用此lookaside table中的数据重新构建内存page。
WiredTiger.wt文件:
存储的是所有集合(包含系统自带的集合)相关数据文件和索引文件的checkpoint信息。
WiredTiger文件:
存储的是WiredTiger存储引擎的版本号,编译时间等信息。
WiredTiger.turtle文件:
存储的是WiredTiger.wt这个文件的checkpoint数据信息。相当于对保存有所有集合checkpoints信息的文件WiredTiger.wt又进行了一次checkpoint。
diagnostic.data文件夹:
存放的是MongoDB启动运行时的诊断数据。
journal文件夹:
开启Jouranl日志功能后,存放的是Write ahead log事务日志,当数据库意外crash时,可通过log来恢复数据。
Page的生命周期
WiredTiger存储引擎里面,磁盘里集合数据和索引都是通过B+ Tree来组织的,但是提供给应用读写的数据都是发生在内存里的,WiredTiger会按需将磁盘的数据以page为单位加载到内存,同时在内存会构造相应的B+ Tree来存储这些数据。应用都是在内存中对Page进行增删改,内存中的Page会利用一些数据结构来记录应用的修改,然后经过reconcile(调和)生成新的Page(基于原Page修改后的Page),然后等待evict线程将生成的新的Page写到磁盘,并丢弃旧的Page。
Page的典型生命周期如下图所示:
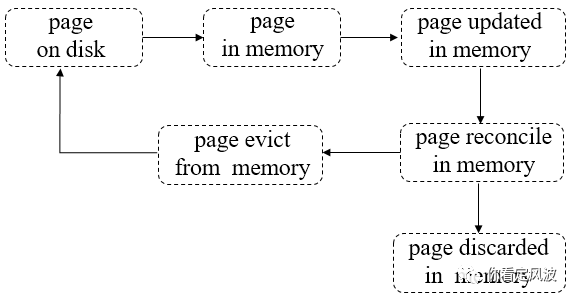
第一步:pages从磁盘读到内存;
第二步:pages在内存中被修改;
第三步:被修改的脏pages在内存被reconcile,完成后将discard这些pages。
第四步:pages被选中,加入淘汰队列,等待被evict线程淘汰出内存;
第五步:evict线程会将“干净“的pages直接从内存丢弃(因为相对于磁盘page来说没做任何修改),将经过reconcile处理后的磁盘映像写到磁盘再丢弃“脏的”pages。
WiredTiger数据持久化
前面了解了WiredTiger的索引数据结构和索引效果,以及MongoDB数据目录底层文件的简单作用,
并且介绍了MongoDB中Page的生命周期,其中有两个很重要的概念checkpoint和journal日志。
Checkpoint
checkpoint 中文名为检查点,顾名思义,是检查某一时刻内存和磁盘中的数据状态,即从上一次检查点到现在哪些Page被删除,哪些Page被新建等,可以说是记录了数据库中内存数据相对于上一次检查点的一个快照。当向Disk写入数据时,WiredTiger将Snapshot中的所有数据以一致性方式写入到数据文件(Disk Files)中。一旦Checkpoint创建成功,WiredTiger保证数据文件和内存数据是一致性的,因此,Checkpoint担当的是还原点(Recovery Point),一旦发生系统故障,可以根据检查点恢复出最新一次检查点的状态,然后通过回放从检查点之后的journal日志恢复出断电前的数据。
总的来说,Checkpoint主要有两个目的:
一是将内存里面发生修改的数据写到数据文件进行持久化保存,确保数据一致性;
二是实现数据库在某个时刻意外发生故障,再次启动时,缩短数据库的恢复时间。
checkpoint数据结构
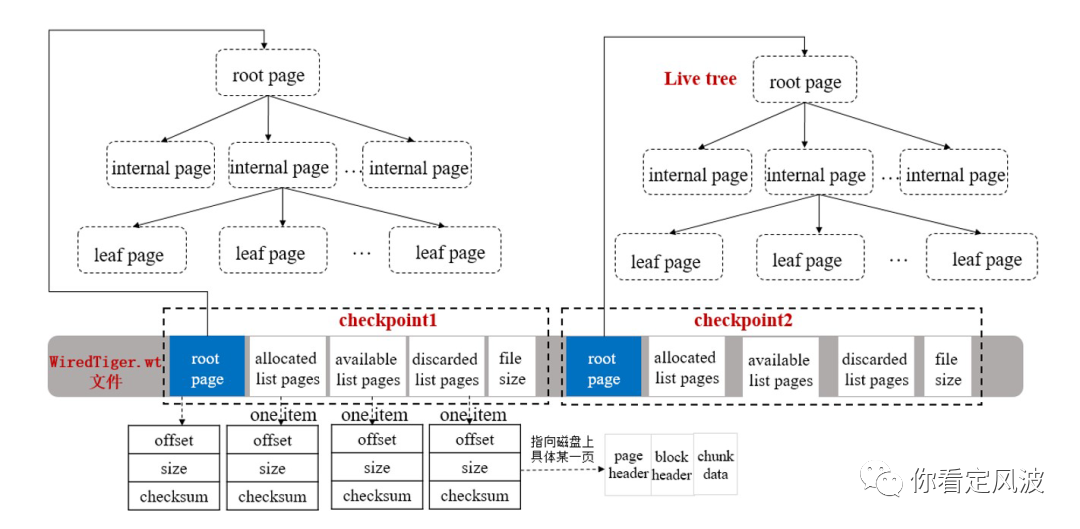
每个checkpoint包含一个root page、三个指向磁盘具体位置上pages的列表以及磁盘上文件的大小。
详细字段信息描述如下:
root page:
包含rootpage的大小(size),在文件中的位置(offset),校验和(checksum),创建一个checkpoint时,会生成一个新root page。
allocated list pages:
用于记录最后一次checkpoint之后,在这次checkpoint执行时,由WiredTiger块管理器新分配的pages,会记录每个新分配page的size,offset和checksum。这个部分的Pages会随checkpoint刷新到磁盘数据文件。
discarded list pages:
用于记录最后一次checkpoint之后,在这次checkpoint执行时,丢弃的不在使用的pages,会记录每个丢弃page的size,offset和checksum。
available list pages:
在这次checkpoint执行时,所有由WiredTiger块管理器分配但还没有被使用的pages;当删除一个之前创建的checkpoint时,它所附带的可用pages将合并到最新的这个checkpoint的可用列表上,也会记录每个可用page的size,offset和checksum。
file size:
在这次checkpoint执行后,磁盘上数据文件的大小。
checkpoint执行流程

流程描述如下:
查询集合数据时,会打开集合对应的数据文件并读取其最新checkpoint数据;
集合文件会按checkponit信息指定的大小(file size)被truncate掉,所以系统发生意外故障,恢复时可能会丢失checkponit之后的数据(如果没有开启Journal);
在内存构造一棵包含root page的live tree,表示这是当前可以修改的checkpoint结构,用来跟踪后面写操作引起的文件变化;其它历史的checkpoint信息只能读,可以被删除;
内存里面的page随着增删改查被修改后,写入并需分配新的磁盘page时,将会从livetree中的available列表中选取可用的page供其使用。随后,这个新的page被加入到checkpoint的allocated列表中;
如果一个checkpoint被删除时,它所包含的allocated和discarded两个列表信息将被合并到最新checkpoint的对应列表上;任何不再需要的磁盘pages,也会将其引用添加到live tree的available列表中;
当新的checkpoint生成时,会重新刷新其allocated、available、discard三个列表中的信息,并计算此时集合文件的大小以及rootpage的位置、大小、checksum等信息,将这些信息作checkpoint元信息写入文件;
生成的checkpoint默认名称为WiredTigerCheckpoint,如果不明确指定其它名称,则新check point将自动取代上一次生成的checkpoint。
Checkpoint执行的触发时机
触发checkpoint执行,通常有如下几种情况:
按一定时间周期:默认60s,执行一次checkpoint;
按一定日志文件大小:当Journal日志文件大小达到2GB(如果已开启),执行一次checkpoint;
任何打开的数据文件被修改,关闭时将自动执行一次checkpoint。
Checkpoint总结
Checkpoint技术通过在内存中维护一定的数据结构(B+ Tree),记录应用对数据的改动,即从上次checkpoint到现在的内存页的改动,和要删除的页等,然后通过定时刷新等触发方式,将内存中的Checkpoint 的B+ Tree刷新到磁盘。一旦checkpoint完成,磁盘中数据就和内存数据同步了,checkpoint可以生成新的live Tress来继续记录应用新的改动。
验证Checkpoint工作原理
为了探究checkpoint是怎么工作的,我们来实验一把:
插入一些文档
首先执行下面语句再插入1000个文档(当前时间约为Jul 22 08:25)
var BASE= 1010000
for (var i = BASE + 1; i <= BASE+ 1000; i++) { db.ldl_collection_with_index.insert( { x : i , name: "liudinglong"+i, class:"class"+i, sex:"man"} ) }
一分钟后杀掉mongod进程,查看MongoDB数据目录
过一分钟左右,停掉mongod进程,查看MongoDB数据目录;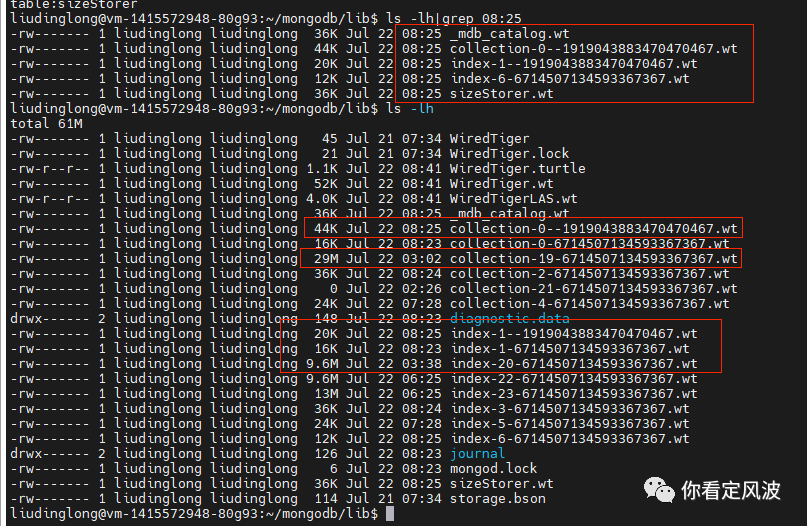
从图8可以看出,我插入1000条数据后,集合数据文件和索引文件都没有更新(从更新时间可以看出)。现在mongod进程也被杀了,内存里没有数据了,那刚刚插入的1000条数据岂不是丢了?MongoDB显然不会允许这样的事情发生,细心一点可以发现,目录下有几个新更新的文件(更新时间为08:25:02)。
分别是:_mdb_catalog.wt(前面介绍了这个文件记录了集合表名与磁盘上数据文件和索引文件间的对应关系,所以插入数据生成了新的checkpoint文件会影响对应关系)
collection-0--1919043883470470467.wt (这个文件记录了我刚刚的插入数据,下次MongoDB启动或下一次checkpoint时可以根据这个文件恢复数据)
index-1--1919043883470470467.wt (这个文件记录了新插入数据更新的索引,同样在MongoDB恢复启动或下一次checkpoint时,可以根据这个文件恢复索引)
sizeStorer.wt(存储所有集合的容量信息,自然在每次checkoutpoint都会更新)。
重新开启MongoDB数据库(当前时间约为Jul 22 09:09)
再次观察MongoDB数据目录文件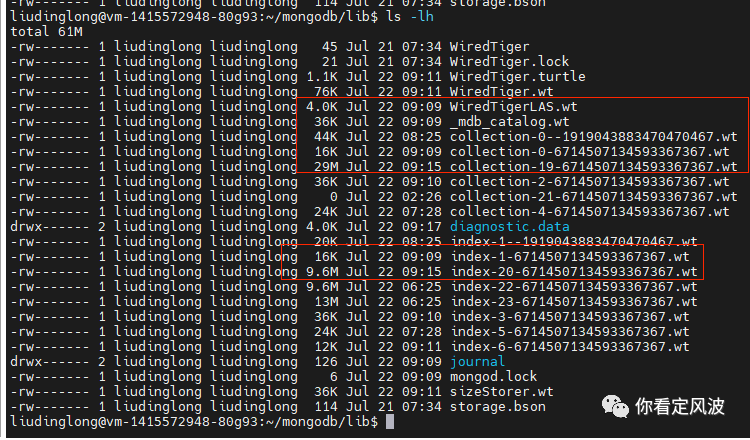
可以看出,collection-19-xxx.wt和index-20-xxx.wt这两个真正存储数据和索引的文件并没有立即更新,而是在大约6分钟后,才进行更新。说明checkpoint机制有自己的时间周期来做同步,并且同步完成后,最近一次checkpoint文件还会被保留。
journal日志
checkpoint保证了每个检查点之间,内存数据同步到磁盘。但是两个checkpoint时间间隔内的数据也需要保证持久化,这个就要靠journal日志来实现了。
journal 是顺序写入的二进制日志文件,用于记录上一个Checkpoint之后发生的数据更新,能够将数据库从系统异常终止事件中还原到一个有效的状态。journal日志文件是预分配的,从图6: MongoDB数据目录文件可以看出,journal目录下的文件都是100MB,是预分配好的,可以提高性能。WiredTiger 为每个客户端发起的写操作创建一个日志记录。日志记录包括由初始写入引起的任何内部写入操作。例如,对集合中文档的更新可能会导致对索引的修改;WiredTiger 创建单个日志记录,其中包括文档更新操作及其关联的索引修改。每条日志记录都有一个唯一的标识符,
WiredTiger 的最小日志记录大小为 128 字节。MongoDB 将 WiredTiger 配置为使用内存缓冲来存储日志记录。线程协调分配并复制到它们的缓冲区部分,缓冲最大 128 kB 的所有日志记录。当满足以下条件时,journal会被刷入到磁盘中:
每100ms
写操作时加了选项
{j:true}当 WiredTiger 创建一个新的日志文件时。由于 MongoDB 使用 100 MB 的日志文件大小限制,WiredTiger 大约每 100 MB 数据创建一个新日志文件。
使用Journal日志文件还原的过程
WiredTiger创建Checkpoint,能够将MongoDB数据库还原到上一个CheckPoint创建时的一致性状态,如果MongoDB在上一个Checkpoint之后异常终止,必须使用Journal日志文件,重做从上一个Checkpoint之后发生的数据更新操作,将数据还原到Journal记录的一致性状态,使用Journal日志还原的过程是:
1 获取上一个Checkpoint创建的标识值:从数据文件(Data Files)中查找上一个Checkpoint发生的标识值(Identifier);
2 根据标识值匹配日志记录:从Journal Files 中搜索日志记录(Record),查找匹配上一个Checkpoint的标识值的日志记录;
3 重做日志记录:重做从上一个Checkpoint之后,记录在Journal Files中的所有日志记录;
总结
至此我们了解了MongoDB 索引的原理和作用,并且探究了MongoDB数据目录文件的结构和每个文件的作用。然后了解了MongoDB 数据组织的结构和数据页(Page)的生命周期,并且了解了MongoDB实现数据一致性和持久化的执行——Checkpoint和journal。
简单总结,MongoDB通过B+ Tree数据结构来组织数据和索引。使用索引对于数据查询的效果非常显著,因此在经常查询的字段建立索引是非常必要的。MongoDB在内存中也维护一个Page和磁盘中的数据块对应,所有的增删改操作都在内存中完成,并且保存到checkpoint 的live tree的数据结构中。checkpoint机制每隔一分钟(默认值)刷新到磁盘,完成一次内存数据页到磁盘数据的同步,checkpoint完成那一刻,磁盘和内存数据是一致的。在两个checkpoint之间,MongoDB通过journal日志来记录数据的修改。journal日志不仅记录应用对数据的修改,也记录由此引发的内部的修改,比如对索引的修改。journall日志先记录到日志缓冲区,每100ms(默认值)刷新到磁盘journal日志文件,因此对于突然的服务器故障,MongoDB可以通过checkpoint和journal日志恢复出故障前100ms内的内容,可以满足绝大多数应用了。
参考文档
[1] WiredTiger存储引擎系列
[2] MongoDB-3.6手册
[3] WiredTiger Reference Guide
