






长按二维码关注
大数据领域必关注的公众号

By大数据研习社
概要:Hive中使用数据压缩,可以减少存储磁盘空间,降低单节点的磁盘IO。由于压缩后的数据占用的带宽更少,因此可以加快数据在Hadoop集群流动的速度。
关键词:Hive、数据压缩、Snappy、Lzo
减少存储磁盘空间,降低单节点的磁盘IO。由于压缩后的数据占用的带宽更少,因此可以加快数据在Hadoop集群流动的速度。
Hive做大数据分析运行过程中,需要花费额外的时间/CPU做压缩和解压缩计算。
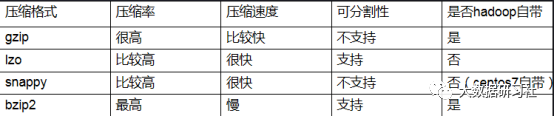
几种压缩方案总结:
1)lzo和snappy的压缩率和压缩速度相对比较均衡。
2)压缩文件是否能分割的也比较重要,MapReduce 需要将大文件分割成多个分片,每个map处理一个分片数据,从而并行进行处理。
3)虽然GZip与Snappy文件不可分,但也有替代的方案。可以控制输出文件个数和大小。
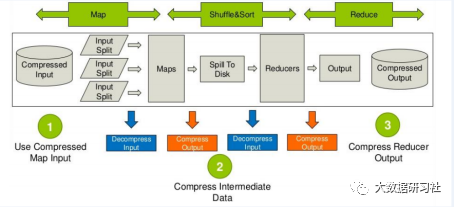
1.查看集群支持的压缩算法
使用以下命令,可以查看是否有相应压缩算法的库;如果显示为false,则需要额外安装。
bin/hadoop checknative -a
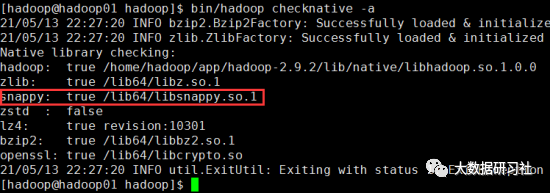
PS:Hadoop 2.X版本已经集成了snappy、lz4、bzip2等压缩算法的编/解码器,会自动调用对应的本地库,而CentOS 7中自带snappy依赖库,故无需安装安装snappy依赖
如果报错:
openssl: false Cannot load libcrypto.so
原因:
提示不能正确加载 libcrypto.so,因为缺少 ssl lib包
解决:
sudo yum -y install openssl-devel
2.开启map节点输出压缩
Hive中开启Map阶段输出压缩,可以减少在Hive中MR Job的Mapper和Reducer之间的网络I/O。
1)开启Hive中MR中间文件压缩:
hive> set hive.exec.compress.intermediate=true;
2)开启Hadoop的MapReduce任务中Map输出压缩功能:
hive> set mapreduce.map.output.
compress=true;
3)设置Hadoop的MapReduce任务中Map阶段压缩算法(对应的编/解码器):
hive> set mapreduce.map.output.compress.
codec=org.apache.hadoop.io.compress.SnappyCodec;
常用编码/解码器:
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.DeflateCodec,
org.apache.hadoop.io.compress.SnappyCodec,
com.hadoop.compression.lzo.LzoCodec
4)案例
统计查询每个气象站的平均气温
select id , sum(temperature)/count(*) from temperature group by id limit 10;
备注:通过运行结果可以看到,使用的中间压缩,不影响hive查询
3.开启Reduce阶段输出压缩
当Hive将查询内容写入到表中(local/hdfs)时,输出内容同样可以进行压缩。
1)开启Hive最终查询结果输出文件压缩功能:
hive> set hive.exec.compress.output=true;
2)开启Hadoop中的MR任务的最终输出文件压缩:
hive> set mapreduce.output.fileoutputformat.compress=true;
3)设置Hadoop中MR任务的最终输出文件压缩算法(对应的编/解码器):
hive> set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
4)设置Hadoop中MR任务序列化文件的压缩类型,默认为RECORD即按照记录RECORD级别压缩(建议设置成BLOCK):
hive> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
5)案例
统计查询每个气象站的平均气温,然后将统计结果写入result表
create table result as select id , sum(temperature)/count(*) from tempera-
ture group by id;
从hdfs上查看result结果文件数据格式为snappy

查询result表,看是否能正常查询数据
select * from result limit 10;
4.另一种数据压缩配置方式
通过设置hive-site.xml文件设置启用中间数据压缩,配置文件如下:
<!-- 开启map输出压缩 -->
<property>
<name>hive.exec.compress.intermediate</name>
<value>true</value>
</property>
<!-- 开启reduce输出压缩 -->
<property>
<name>hive.exec.compress.output</name>
<value>true</value>
</property>
<!-- map输出压缩 -->
<property>
<name>mapreduce.map.output.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.map.output.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
<!-- reduce输出压缩 -->
<property>
<name>mapreduce.output.fileoutputformat.compress</name>
<value>true</value>
</property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codec</name>
<value>org.apache.hadoop.io.compress.SnappyCodec</value>
</property>
完
Apache Flink 在快手的过去、现在和未来
大数据基础运维:HDFS参数调优
大数据无处不在,向左还是向右

