 Linuxeden开源社区
Linuxeden开源社区IBM 开源 ModelMesh,使开发者能够大规模部署 AI 模型
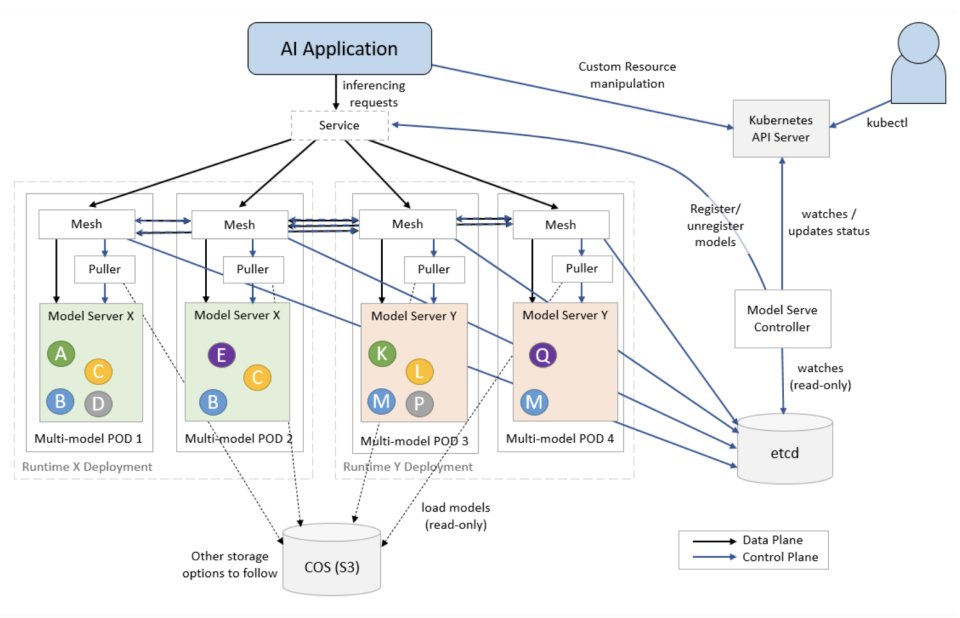
模型服务是人工智能领域的一个重要组成部分。它使用人工智能模型中提供的推理来响应用户的请求。那些接触过企业级机器学习应用的用户或开发者应该知道,它们通常不是由一个模型提供推理,实际上是由数百甚至数千个模型在串联运行。由于 AI 模型的计算成本很高,因为你不可能在每次要提供请求时都启动一个专用容器。
除此之外,因为存在一些限制,这对在 Kubernetes 集群上部署大量模型的开发者来说也是一个挑战:
- 计算资源限制
- 最大 pod 限制(Kubernetes 建议每个节点最多有 100 个 pods)
- 最大 IP 地址限制(一个拥有 4096 个 IP 的集群可以部署大约 1000 到 4000 个模型)
IBM 通过其专有的 ModelMesh 模型服务管理层为 Watson 产品(如 Watson Assistant、Watson Natural Language Understanding 和 Watson Discovery)解决了这个难题。由于这些模型已经在生产环境中运行了多年时间,ModelMesh 已经针对各种场景进行了全面测试。现在,IBM 将这一管理层与控制器组件以及模型服务运行时一起贡献给了开源社区。
ModelMesh 使开发者能够在 Kubernetes 之上以 “极大规模” 部署 AI 模型。它具有缓存管理的功能,也充当一个平衡推理请求的路由。模型被智能地放置在 pods 中,并且能够适应临时中断。开发者无需任何外部协调机制就可以轻松升级部署的 ModelMesh。它可以自动确保一个模型在路由新的请求之前已经完全更新和加载。
IBM 用一些统计数据解释了 ModelMesh 的可扩展性:
一个部署在单个工作节点 8vCPU x 64G 集群上的 ModelMesh 实例能够打包 2 万个简单字符串模型。除了密度测试之外,我们还通过发送数千个并发推理请求来对 ModelMesh 服务进行负载测试,以模拟高流量的假日场景,所有加载的模型都以个位数毫秒的延迟做出响应。我们的实验表明,单个工作节点支持 2 万个模型,每秒最多 1000 个查询,并以个位数毫秒的延迟响应推理任务。
ModelMesh 与 KServe 相结合,还将为部署在生产中的模型增加可信的人工智能指标,如可解释性与公平性。目前该项目已托管至 GitHub 平台,可点击链接进一步了解该项目。
来源:开源中国 作者:Alias_Travis
相关推荐
- 每日文章精选 2024 06 15
- 作为基于 GTK4 的 Evince 分叉,GNOME Papers 文档查看器正在取得进展
- 每日文章精选 2024 06 14
- KDE Gear 24.05.1 改进了 Elisa、Spectacle、KCalc 和其他 KDE 应用程序
- 每日文章精选 2024 06 13
- Ubuntu 谈 RISC-V 八核笔记本电脑
- FreeBSD 社区调查证实 ZFS 是他们最看重的服务器功能
- 每日文章精选 2024 06 12
最新评论
中国逻辑也开始出口了,同时也要加大国内生态文明建设[鲜花]
能在不用快捷指令和第三方app的前提下让他只在工作日叫醒我吗?
为什么你发的所有微博网页链接都打不开?内容只显示一点点,链接又打不开,那要看什么?看标题?
牛皮往大里吹的一个典型表现是没有具体联系负责人和一般人都感受不到这种牛逼文字背后的逻辑!
追求最先进的芯片制程工艺远远没有用好硬件,做扎实测试,建设完善的安全系统和构建有文化的软件工具链和生态来的重要!
使用 HTTP/3 时,处理特制的 QUIC 会话时,可能会导致工作进程崩溃、工作进程内存泄露(在MTU大于4096字节的系统上 在 MTU 大于 4096 字节的系统上可能导致工作进程内存泄露,或造
微博已支持音频服务,一起来#听见微博#发现你喜爱的音频作者吧~
intel现在是蒸蒸日下