-
 采集全球信息,监测世界舆情
采集全球信息,监测世界舆情
废话不多说,先上源代码及效果图(如若对你有帮助,请阅读完本文): 互联网金融网络舆情应对解决方案
网页链接: https://music.163.com/#/playlist?id=5087806619
效果图:

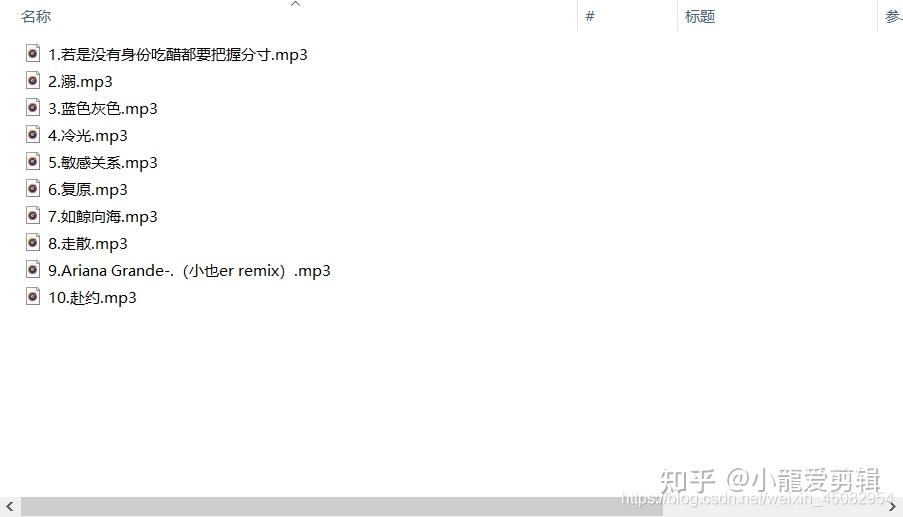
源代码:
# -*- codeing=utf-8 -*-
# @Time:2021/7/22 20:47
# @Atuhor:@lwtyh
# @File:批量下载.py
# @Software:PyCharm
#导入框架(库,模块) pip install xxxx
import requests
from lxml import etree
# http://music.163.com/song/media/outer/url?id=
# 1、确定网址 真实地址在Network----Doc
url = 'https://music.163.com/playlist?id=5087806619'
base_url = 'http://music.163.com/song/media/outer/url?id='
# 2、请求(requests) 图片,视频,音频 content 字符串 text
html_str = requests.get(url).text
# print(type(html_str)) # 字符串类型
# 3、筛选数据xpath(标签语言)
# //a[contains(@href,'/song?')]/@href
result = etree.HTML(html_str) # 转换类型
# print(type(result))
song_ids = result.xpath('//a[contains(@href,"/song?")]/@href') # 歌曲id
song_names = result.xpath('//a[contains(@href,"/song?")]/text()') # 歌名
# print(song_ids)
# print(song_names) #列表
# 对列表进行解压
i = 0 # 按顺序来
for song_id,song_name in zip(song_ids,song_names):
# print(song_id)
# print(song_name)
count_id = song_id.strip('/song?id=') # 去掉/song?id=
# print(count_id)
# 过滤含有“$”符号
if ('$' in count_id) == False:
# print(count_id)
song_url = base_url + count_id # 拼接url
# print(song_url)
i += 1
mp3 = requests.get(song_url).content
# 4、保存数据
with open('./yinyue/{}.{}.mp3'.format(i,song_name),'wb') as file:
file.write(mp3)
目的:
一张截图,请自行分析:
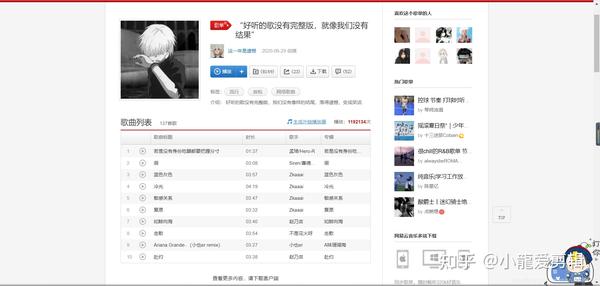

这是一张再熟悉不过的图片了,想要获取本页面这些音乐,方法很多,如APP内自行下载啥的,但是,本次我想利用所学到的一点皮毛进行下载。
我们都知道,对于网页上的音乐在进行下载时,经常会弹出如下页面:


好好的下载一首歌曲,非要弄得这么麻烦。甚至,有些音乐在下载了软件后,需要付费或者VIP,让人很是苦恼。更严重者,好不容易下载好了,却发现格式不对等种种情况,让人崩溃。
为此我们可以很好地通过简单的爬虫解决以上问题。
对网页进行分析:
1. 在一开始,本人给出了本网页的链接: https://music.163.com/#/playlist?id=5087806619但是细心的小伙伴会发现,在代码中所使用的的网址并非是这个:
url = ' https://music.163.com/playlist?id=5087806619'


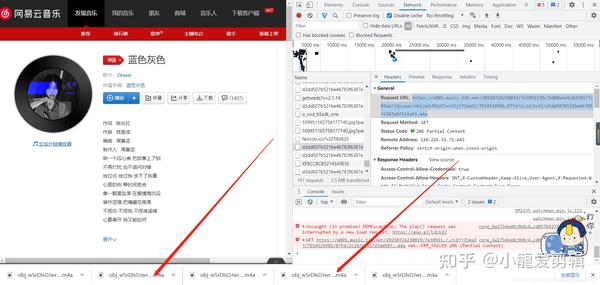
这是因为我们所请求的网址并非是浏览器地址栏上的网址,通过这张截图,很清晰的发现我们所请求的网址是哪个了。(这是一个很重要的点,必须学会分析。)
2. 通过对每首歌曲打开,进行网页源代码分析不难发现,本网页的10首歌曲都有一个共同的特点:即 https://music.163.com/#/song?id=1475436266
前面的网址为 https://music.163.com/#/song?id= 加每首歌曲的 id 号,这很简单。


3. 然而,我们永远想得过于简单了,到目前为止,我们仅仅是找到了些许规律,但是要真正下载到每一首歌曲,还遥不可及。
因为我们进行了这么久的分析,并没有找到歌曲的真正链接。


通过对这些内容的查找,我们是可以说,根本就无法找到音乐文件(MPEG、MP3、MPEG-4、MIDI、WMA、M4A等)。
那是我们到现在为止还没有请求音乐,而当我们在进行点击播放时会发现如下图所示(与上图进行比较)发现:





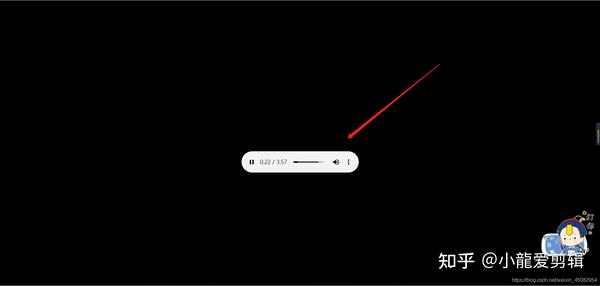
或者: 像下图所示,会出现该音频,当你浏览器跟迅雷下载器所绑定,会立马弹出迅雷界面,进行该音乐的下载。

结合上面的情况来说,我们是不是已经成功了呢?但很难过的告诉你,这个网址在短时间内打开,的确会有用,但是,它是有时间限制的,不信的话,你可以过五分钟(或许还不需要这么久)再重新打开该网址,试一下。
那么,照我这么一说,没办法了吗?当然不是,办法还是有的,不然,怎么敢在此“放肆”呢?
问题解决:
通过之前对网页进行分析,我们正一步一步地进行了解、熟悉,且到最后,我们甚至找到了歌曲的最终URL,但是可惜的是,该URL并非是一个永久的,只是一个短暂、临时的动态URL,这简直给我们泼了一盆冷水。
然而,我们无需灰心,俗话说 “ 魔高一尺,道高一丈 ”,办法还是有的。
需将这个问题解决,不得不介绍一个新的URL:
http://music.163.com/song/media/outer/url?id=
在这里,就不卖关子了,这是一个该平台(至于是什么平台,你懂得)的外部链接。在之前的分析中,我们发现了一个很重要的一点,便是这10首歌曲都是一个网址加每首歌曲的id所在的新页面。
在代码中你也会发现所使用的 base_url 便是这个链接。
base_url = 'http://music.163.com/song/media/outer/url?id='也就是说,我们有了上面的这个网址,便可以为所欲为了。爱动手的你现在便可以立马复制上面的链接,在网页上找到一首歌曲的id号添加至网址后面进行打开(如: http://music.163.com/song/media/outer/url?id=1822734959),是不是得到了如下的界面:


是不是很熟悉呢?没错,这就是之前我们利用网页分析得到的网址所打开的网页,很可惜的是之前那网址是一个临时、动态的网址,对于我们来说进行批量下载没多大用处。所以,当我们现在有了这个新网址,就方便了很多。
好,想一想,既然我们有了这么一个神奇的网址,接下来,该干嘛了呢?好好想一下。
正片开始:
在经过了前面两大点的分析,现在我们可以游刃有余地对这十首音乐进行爬取了。
相信,很多人都知道接下来一步该干什么了吧?
每首音乐可以通过 http://music.163.com/song/media/outer/url?id= 这个网址加每首音乐的 id 进行下载,所以,我们第一步便是想办法获取每首音乐的 id 。


通过之前的这张图不难发现,每首音乐的 id 都在一个a标签内。
#导入框架(库,模块) pip install xxxx
import requests
# 1、确定网址 真实地址在Network----Doc
url = 'https://music.163.com/playlist?id=5087806619'
# 2、请求(requests) 图片,视频,音频 content 字符串 text
html_str = requests.get(url).text
print(html_str)
print(type(html_str)) # 字符串类型便可以通过上述代码,先将该网页的源代码进行怕取下来,再进行分析。
在这里使用多加了一横打印该页代码的数据类型,不难发现所打印出来的类型为 字符串 。这便有了后续需要将该内容转换为 _Element对象 。
>>>result = etree.HTML(html_str) # 转换类型
>>>print(type(result))
class 'lxml.etree._Element'> #输出类型作为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法。
而此次爬虫,恰恰所使用的的便是 xpath() 方法。
所以,还需要导入一个新的模块,即:
from lxml import etree

通过浏览器的 XPath Helper 插件可以快速的匹配到每首音乐的 id 。
song_ids = result.xpath('//a[contains(@href,"/song?")]/@href') # 歌曲id
song_names = result.xpath('//a[contains(@href,"/song?")]/text()') # 歌名
print(song_ids)
print(song_names) #列表而当我们打印出来时,却发现这是一个列表类型。不着急,可以借用 for 进行快速遍历:
for song_id,song_name in zip(song_ids,song_names):
print(song_id)
print(song_name)

通过打印发现,前面多了一些 /song?id= ,这时,便使用下面这行代码,进行删减:
count_id = song_id.strip('/song?id=') # 去掉/song?id=

歌名没有进行打印了,因为我们主要是获取每首音乐的 id ,然而,仔细看上图发现后面多了三个无用的,这三个必须删掉才行,不然在进行后面的 URL 拼接,肯定会报错,因为压根就找不到这样的一个网址。便有了后面的判断语句。
# 过滤含有“$”符号
if ('$' in count_id) == False:
print(count_id)清一色id号:


接下来便是拼接新的URL:
song_url = base_url + count_id # 拼接url
print(song_url)

在浏览器里打开上面的任意链接,即可获取该音乐的链接,并进行下载。
但是,我们最终的目的肯定不在于此,而是让爬虫自动帮我们全部下载并进行保存至文件夹。
mp3 = requests.get(song_url).content所以,我们便进行请求网址,获取每首音乐。最后,在进行保存即可。
with open('./yinyue/{}.{}.mp3'.format(i,song_name),'wb') as file:
file.write(mp3)需要注意的是,源代码中本人在 for 进行遍历时,增加了一个变量 i ,这是为了我们所爬取下来的音乐保存在文件夹的顺序还是如网页中的顺序所一样,当然如若不需要可将其删除。
到现在看来,我们爬取到了这歌单中的10首音乐,那试想一下,获取其它歌单中的音乐是不是也可以用相同的方法进行获取呢?爱动手的你,快去试一试吧!实践出真知!
说在最后的话:
深圳SEO优化公司商洛至尊标王报价临沧网页设计报价海北建设网站多少钱六安企业网站制作价格衡阳至尊标王哪家好运城网站改版报价南宁英文网站建设价格哈密外贸网站制作横岗如何制作网站报价松岗关键词按天计费报价坪地至尊标王公司坪山seo果洛网站排名优化报价思茅关键词按天计费推荐金昌网络推广公司濮阳百度竞价哪家好扬州SEO按天收费普洱推广网站塔城关键词排名包年推广推荐辽阳网站优化软件公司普洱seo文山优化价格和县网站搜索优化哪家好通辽网站优化按天扣费多少钱松岗seo优化公司苏州网站优化按天收费价格景德镇网站优化软件推荐果洛网站优化排名推荐凉山优化滨州企业网站制作报价歼20紧急升空逼退外机英媒称团队夜以继日筹划王妃复出草木蔓发 春山在望成都发生巨响 当地回应60岁老人炒菠菜未焯水致肾病恶化男子涉嫌走私被判11年却一天牢没坐劳斯莱斯右转逼停直行车网传落水者说“没让你救”系谣言广东通报13岁男孩性侵女童不予立案贵州小伙回应在美国卖三蹦子火了淀粉肠小王子日销售额涨超10倍有个姐真把千机伞做出来了近3万元金手镯仅含足金十克呼北高速交通事故已致14人死亡杨洋拄拐现身医院国产伟哥去年销售近13亿男子给前妻转账 现任妻子起诉要回新基金只募集到26元还是员工自购男孩疑遭霸凌 家长讨说法被踢出群充个话费竟沦为间接洗钱工具新的一天从800个哈欠开始单亲妈妈陷入热恋 14岁儿子报警#春分立蛋大挑战#中国投资客涌入日本东京买房两大学生合买彩票中奖一人不认账新加坡主帅:唯一目标击败中国队月嫂回应掌掴婴儿是在赶虫子19岁小伙救下5人后溺亡 多方发声清明节放假3天调休1天张家界的山上“长”满了韩国人?开封王婆为何火了主播靠辱骂母亲走红被批捕封号代拍被何赛飞拿着魔杖追着打阿根廷将发行1万与2万面值的纸币库克现身上海为江西彩礼“减负”的“试婚人”因自嘲式简历走红的教授更新简介殡仪馆花卉高于市场价3倍还重复用网友称在豆瓣酱里吃出老鼠头315晚会后胖东来又人满为患了网友建议重庆地铁不准乘客携带菜筐特朗普谈“凯特王妃P图照”罗斯否认插足凯特王妃婚姻青海通报栏杆断裂小学生跌落住进ICU恒大被罚41.75亿到底怎么缴湖南一县政协主席疑涉刑案被控制茶百道就改标签日期致歉王树国3次鞠躬告别西交大师生张立群任西安交通大学校长杨倩无缘巴黎奥运