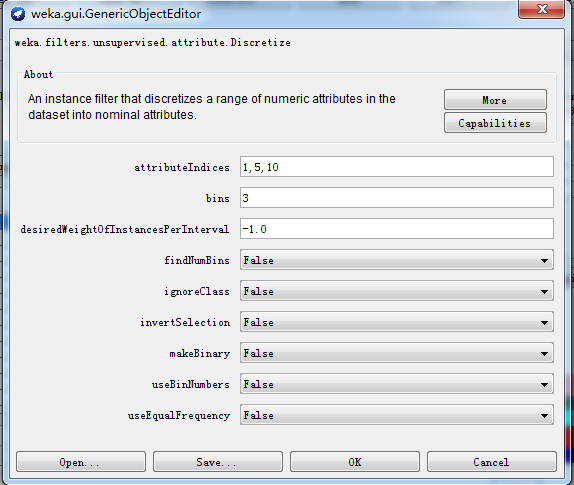
数据挖掘实验报告
——K-最临近分类算法
学号:311062202 姓名:汪文娟
一、 数据源说明
1.数据理解
选择第二包数据Iris Data Set,共有150组数据,考虑到训练数据集的随机性和多样性,选择rowNo模3不等于0的100组作为训练数据集,剩下的50组做测试数据集。
(1)每组数据有5个属性,分别是:1. sepal length in cm
2. sepal wrowNoth in cm
3. petal length in cm
4. petal wrowNoth in cm
5. class:
-- Iris Setosa
-- Iris Versicolour
-- Iris Virginica
(2) 为了操作方便,对各组数据添加rowNo属性,且第一组rowNo=1。
2.数据清理
现实世界的数据一般是不完整的、有噪声的和不一致的。数据清理例程试图填充缺失的值,光滑噪声并识别离群点,并纠正数据中的不一致。
a) 缺失值:当数据中存在缺失值是,忽略该元组(注意:本文选用的第二组数据Iris Data Set的Missing Attribute Values: None)。
…… …… 余下全文