
MPT-7B:MosaicML发布的的MPT(MosaicML Pretrained Transformer)模型族,包括MPT-7B,一个从头开始训练的Transformer,用1T文本和代码Tokens进行训练。 MPT-7B在MosaicML平台上进行了9.5天的训练,没有人为干预,成本约为200,000美元,可用于商业用途。
此外,MosaicML还发布了三个优化过的MPT-7B变体:MPT-7B-Instruct,MPT-7B-Chat和MPT-7B-StoryWriter-65k+,用于指令、对话生成和超长输入。所有模型都可用于预训练,微调和部署。

可以训练、微调和部署自己的私人MPT模型。除了基本的MPT-7B外,我们还发布了三个微调的型号:MPT-7B-Instruct、MPT-7B-Chat和MPT-7B-StoryWriter-65k+,最后一个使用65k令牌的上下文长度。
https://www.mosaicml.com/blog/mpt-7b
获得了商业使用许可(与LLaMA不同)。
在大量的数据上进行训练(与LLaMA的1T标记相比,Pythia为300B,OpenLLaMA为300B,而StableLM为800B)。
由于ALiBi,准备处理极长的输入(我们在高达65K的输入上进行训练,可以处理高达84K的输入,而其他开源模型为2K-4K)。
为快速训练和推理进行了优化(通过FlashAttention和FasterTransformer)。配备了高效的开源训练代码。
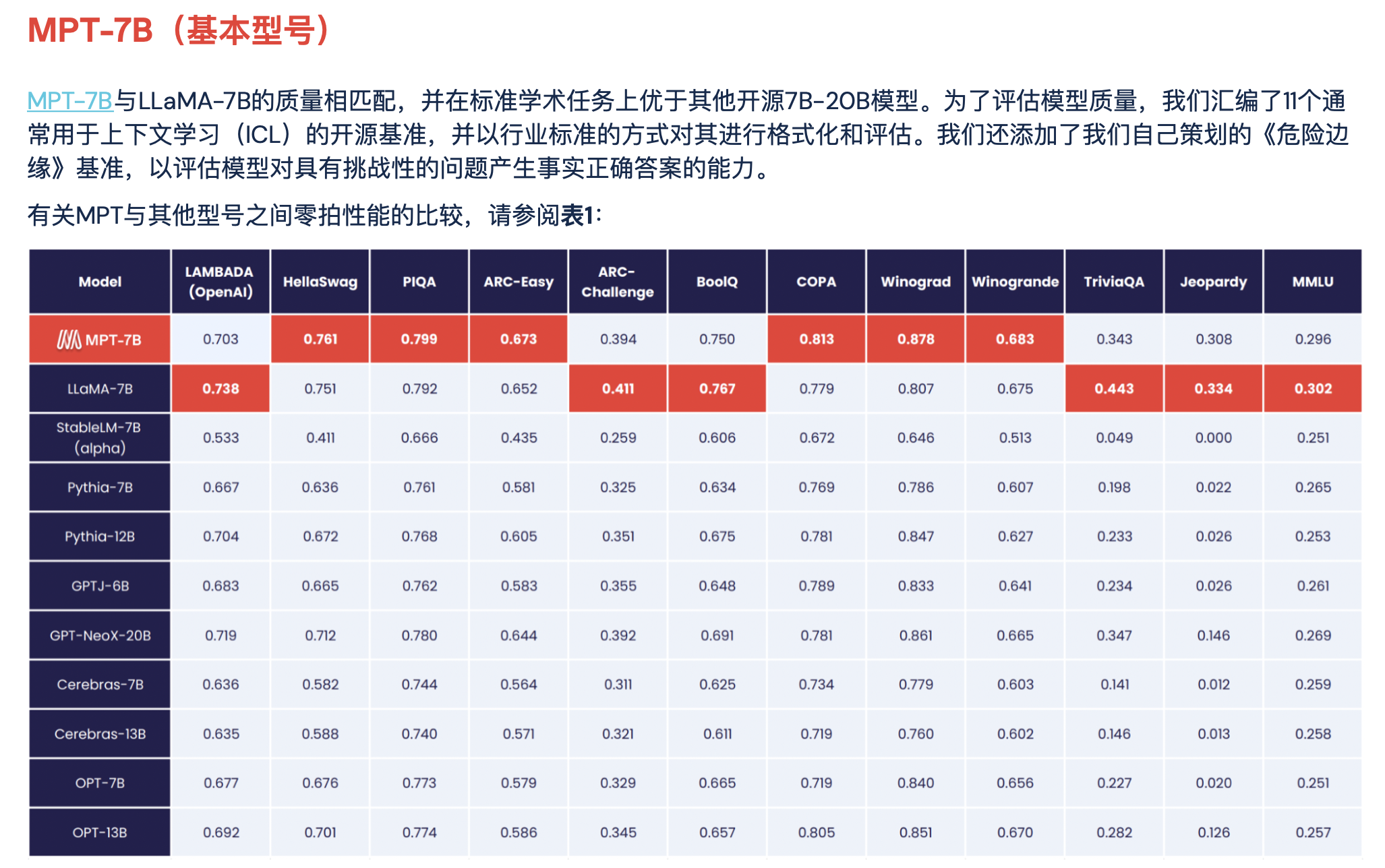
我们在一系列基准上对MPT进行了严格的评估,MPT达到了LLaMA-7B设定的高质量标准。

评论
沙发等你来抢