谁都知道,大模型是当下人工智能领域最重要的前沿技术方向。
世界上以AI为核心抓手的科技巨头,如谷歌、微软、OpenAI、英伟达等,最近几年基本上都在搞自己的大模型。
从BERT、GPT-3、再到风光无限的Switch Transformer,模型参数数量突破天际,SOTA性能记录一刷再刷。

在国内,相关方也在推出超大规模智能模型。但这些在论文和实验中大显神威「刷榜如喝水」的大模型,最后都要面对一个绕不过去的问题:
如何落地?如何让各行各业真正用得起?
要知道,不是每个行业、每家公司都像科技巨头般财大气粗,中小公司面对天量的参数规模,高昂的训练成本,往往只能选择放弃。
在百度WAVE SUMMIT 2022深度学习开发者峰会上,百度集团副总裁、深度学习技术及应用国家工程研究中心副主任吴甜针对这个问题给出了清晰的答案:
大模型要「降低门槛,匹配需求」
吴甜提出,今年是大模型的落地关键年,要做好落地,需要解决的关键问题是前沿的大模型技术如何与真实场景的方方面面要求相匹配。
大模型是工具,但不能只是「刷榜」的工具,要成为促进产业发展的工具。作为工具的大模型,需要有「自降门槛」的觉悟,进一步贴近产业实际。
为此,百度提出了支撑大模型落地的三个关键路径:
一是要建设更适配应用场景的模型体系。
二是提供更有效的配套工具和方法,充分考虑落地应用的全流程问题。
三是打造开放的生态,以生态促创新。
模型十连发,目的只有一个
我们先来简单回顾一下百度在WAVE SUMMIT 2022深度学习开发者峰会上带来的大模型新发布。
与那些用一个大模型通吃所有问题的思路不同,百度的目的是要建设一个可以产业落地、全面的、有层次的体系。

这个模型体系,包含学习了足够多数据与知识的基础大模型,面向常见AI任务专门学习的任务大模型,以及引入行业特色数据和知识的行业大模型。
基础大模型具有学习的数据、知识量大、参数规模大特点,通用性最高。本次的重点发布是融合任务相关知识的千亿大模型ERNIE 3.0 Zeus和多任务视觉表征学习VIMER-UFO 2.0。
但直接使用基础模型往往会与场景上苛刻的应用需求会有一定差距,所以百度在通用模型基础上,增加了两类模型:任务大模型和行业大模型。
任务大模型主要面向特定任务,如NLP领域的信息抽取、对话、搜索等,以及视觉领域的商品图文搜索,文档图像理解等。
不过,无论大模型的性能有多强,参数量如何突破天际,最终还是要看它在哪个领域真正发挥作用,看它能给千千万万从业者和普通人带来什么实际便利。
换句话说,大模型的厉害,不仅要体现在论文里的SOTA,还要让行业内的用户真正用得上、用得好,进而带动产业发展和升级。
所以,我们看到了最后一类「行业大模型」的发布。
还是业内首发的那种。

行业大模型,顾名思义,可以理解为针对特定行业进行知识增强后的大模型。
行业大模型基于通用的文心大模型挖掘相关的行业数据,再融合学习行业特有的大数据和知识,进一步提升大模型对行业应用的适配性。
除了引入了行业里特有的知识和特有的数据外,为了更好地学习行业中的特色知识,行业大模型的研发团队还和拥有深度行业Know-how认知的专家们一起设计了相应的预训练任务,将通用模型真正变成对于行业来说效果更适用的模型。
最后再对模型进行大规模无监督的联合训练,进一步提升大模型的行业应用能力。
值得一提的是,这次百度选择了两个与人们日常生活距离最近的行业:能源和金融。
原因也很简单,一是这两个领域的数字化转型智能化升级的基础较好;二是智能化升级的诉求比较强烈,有场景,有需求。
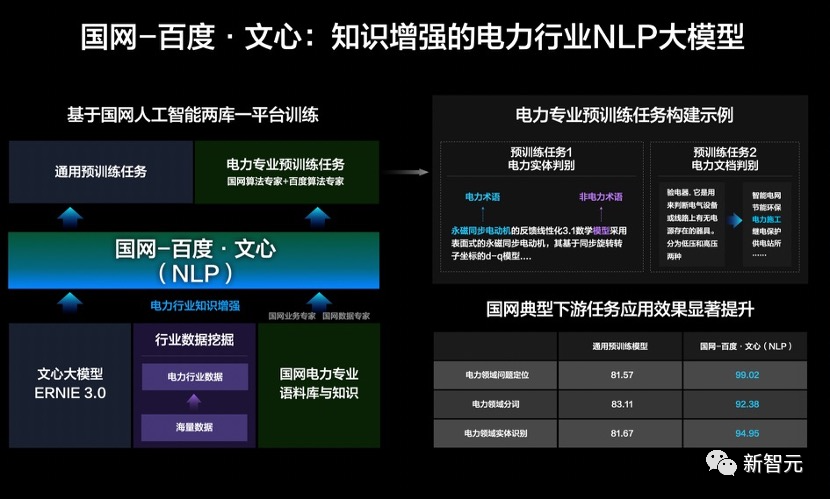
具体来说,在能源电力行业,百度和国网联合研发了知识增强的NLP大模型国网-百度·文心。
基于通用文心大模型,在海量数据中挖掘了电力行业数据,百度与国网专家们一起,引入电力业务积累的样本数据和特有知识。
在训练中,结合双方在预训练算法和电力领域业务与算法的经验,设计出电力领域实体判别、电力领域文档判别等算法作为预训练任务,让文心大模型深入学习电力专业知识,在国网场景任务应用效果提升。
从结果上看,国网-百度·文心大模型不仅提升了传统电力专用模型的精度,而且大幅降低了研发门槛,实现了算力、数据、技术等资源的统筹优化。
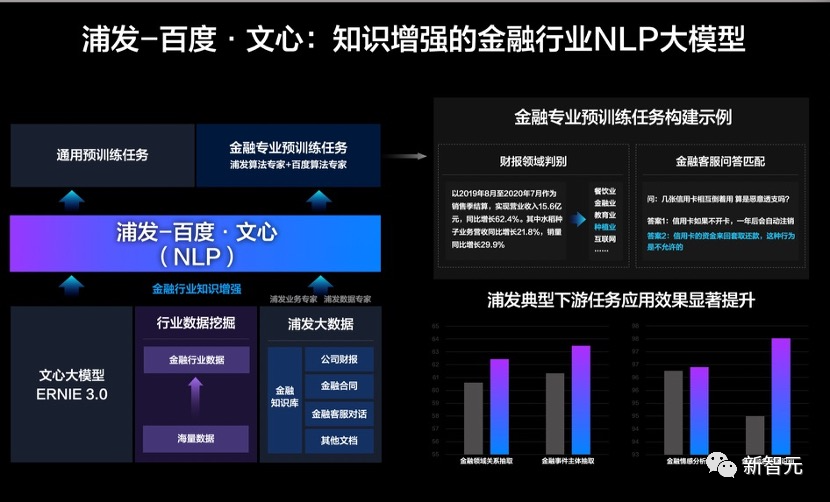
相似的思路,在金融领域,百度和浦发联合研发了知识增强的金融行业NLP大模型浦发-百度·文心。
基于通用文心大模型挖掘金融行业数据,结合浦发场景积累的行业数据与知识,进行大规模无监督数据联合训练。
其中,双方技术和业务专家一起设计了针对性的财报领域判别、金融客服问答匹配等预训练任务,实现了金融行业结构化知识增强。
最后,浦发-百度·文心不仅能够很好的支持金融语义相似度、金融事件主体抽取等各类行业场景中的NLP任务,而且在一系列典型的应用中取得了显著提升。
此外,飞桨文心大模型已经在媒体、医疗等行业都产生了巨大价值。
例如在保险领域应用中,智能解析能力将文本处理效率提升30倍;在医疗领域应用中,将每份病历的检查时间,从30分钟缩短到了秒级别。
「榨干」模型性能
高性能的大模型是基础,现在基础有了,下一个问题就是,用户怎样才能用着舒服,把模型的性能发挥到极致?
为了尽可能地实现这个目标,本次百度与10个大模型一同发布的,还有一套全方位的工具和平台,包括大模型开发套件、大模型API、内嵌了大模型能力的EasyDL和BML开发平台,面向不同类型的开发者,全面释放大模型的使用效能,进一步降低应用门槛。
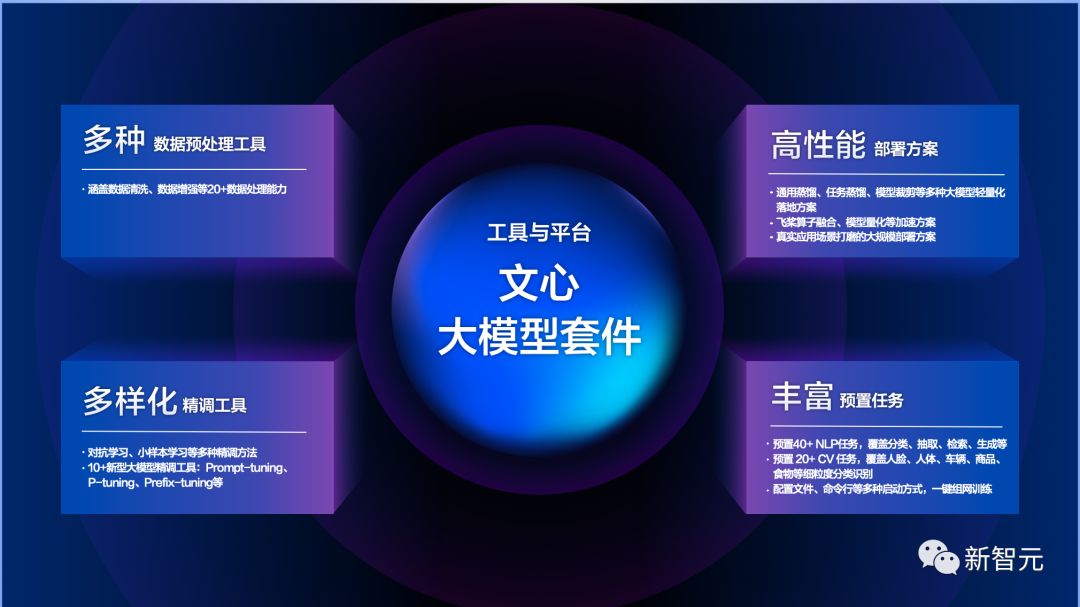
「文心大规模套件」主要包括四个方面的工具:
多种数据预处理工具:覆盖数据清洗、数据增强等20种以上的数据处理能力。
多样化精调工具:涵盖对抗学习、小样本学习等多种精调方法。提供10余种大模型精调工具,如Prompt-turning、P-turning、Prefix-turning等。
高性能部署方案:涵盖通用蒸馏、任务蒸馏、模型裁剪等大规模轻量化落地方案、以及飞桨算子融合、模型量化等加速方案。以及经历真实场景打磨的大规模部署方案。
丰富的预置任务:预设了多领域的丰富任务。包括40多种NLP任务,涵盖分类、抽取、检索、生成等。20多种计算机视觉任务,涵盖人脸、人体、车辆、商品、食物等细粒度分类识别。
在这些预制任务下,提供配置文件、命令行等多种启动方式、实现一键组网训练。
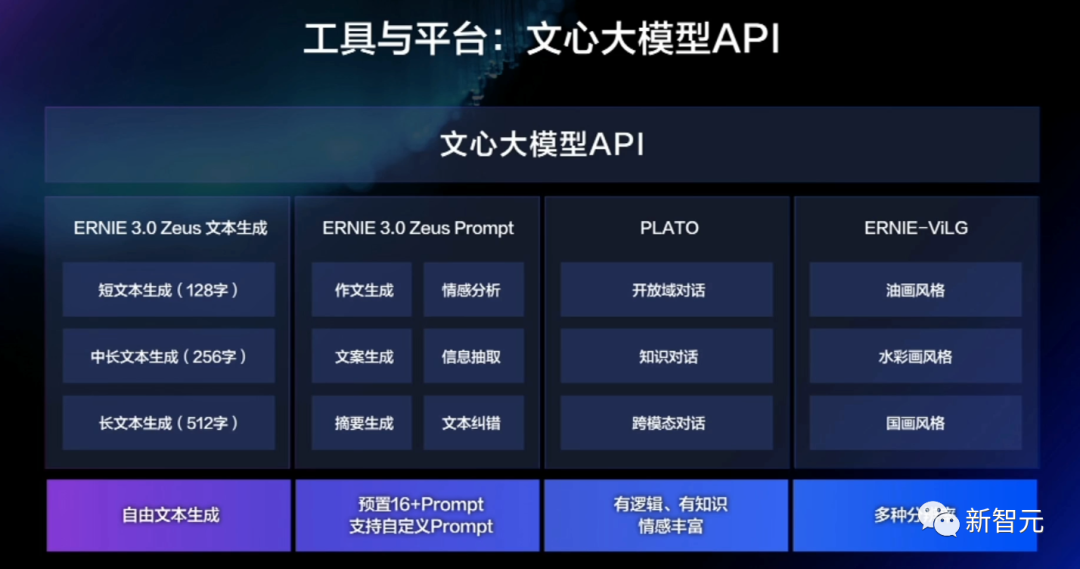
如果想要更直接简便的服务,可以直接使用大模型API、内置了文心大模型能力的EasyDL和BML开发平台,面向不同算法能力的开发者,全面释放大模型的使用效能。
无论是文本生成、信息提取、对话还是AI画家,这套API都能满足用户多角度、全方位的需求。
目前,ERNIE 3.0 Zeus、PLATO、ERNIE-ViLG都可以供使用者通过API直接访问调用。

目前在EasyDL和BML平台上已有1万多用户用到了预训练大模型,创建了超过3万任务,通过大模型机制进行AI应用模型开发,数据标注量平均降低70%,效果平均提升10.7%。