如何得到一个强大表达力的图神经网络模型受到了研究人员的广泛关注。
其中,如何嵌入图的位置信息,更好的建模图结构是一个火热的研究话题。在本文中,我们总结图神经网络中位置信息编码的相关工作。
1. 【IJCAI2019】SPAGAN: Shortest Path Graph Attention Network
地址:https://arxiv.org/abs/2101.03464

导读:文章的核心是通过卷积编码图的局部拓扑结构到中心节点。文章提出了一个新的GCN模型,命名为最短路径的图注意力模型 Shortest Path Graph Attention Network (SPAGAN).
与传统的图神经网络模型在每层做节点的注意力不同的是,该模型通过路径计算注意力,显式的考虑节点序列的影响。
SPAGAN因此可以更好的利用图的结构信息,有效的聚合离中心节点较远的邻居节点。
在下游多个标准的节点分类数据集上,SPAGAN都取得了最优的性能。
2.【NeurIPS 2021】 Do Transformers Really Perform Bad for Graph Representation?
地址:https://arxiv.org/abs/2106.05234
代码: https://github.com/Microsoft/Graphormer.
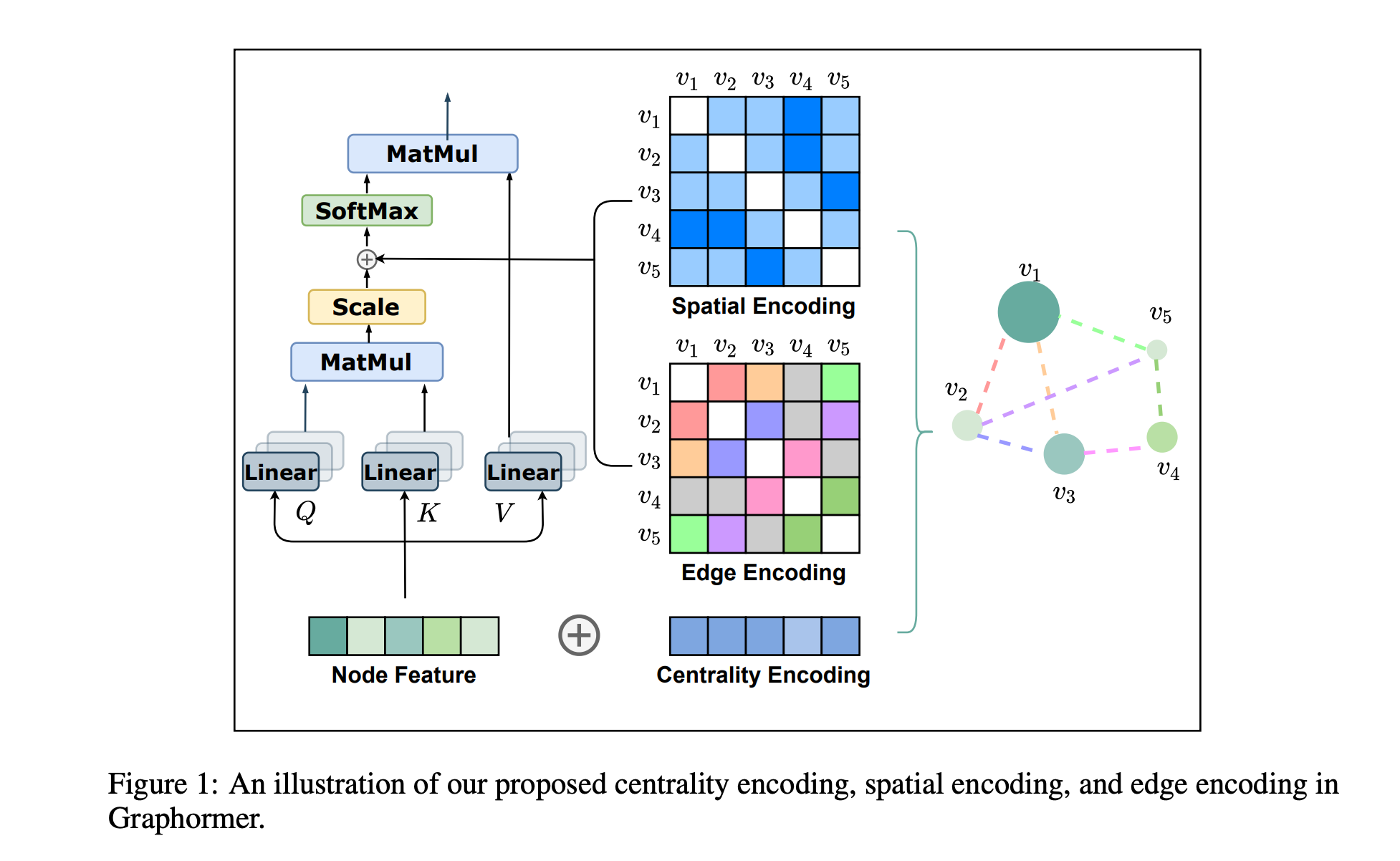
导读:文章来自MSRA,该文章在KDDCUP2021的OGB比赛中取得了冠军。
Transformer架构在许多领域的大放异彩。然而,其在图神经网络的变体GAT却并没有取得具有竞争力的表现。
在本文中,文章扩展了标准 Transformer 到图神经网络,提出Graphormer在广泛的图表示学习任务上取得优异的成绩。
模型的核心是在图中使用 Transformer 编码图的结构信息。
为此,文章提出几个简单而有效的结构编码方法,例如中心性编码(Centrality Encoding),空间编码(Spatial Encoding)和注意力的边编码(Edge Encoding in the Attention)。
Graphormer 可以超越经典表达能力不超过 1-Weisfeiler-Lehman (WL) 测试的消息传递图神经网络模型。
文章关于图结构信息的编码和刻画对语进一步设计更高效的图神经网络模型具有一定的启发价值,例如对短路径的信息编码。
3. 【PAKDD2021】 Graph Attention Networks with Positional Embeddings
地址:https://arxiv.org/pdf/2105.04037.pdf

导读:文章的切入点是图结构的异质性,希望给图注意力网络引入位置信息编码。文章提出带有位置嵌入的图注意力网络模型,捕获结构和位置信息。
在文章的架构中, 位置嵌入通过模型对图上下文的预测完成,模型联合优化节点分类的任务和上下文预测任务。
实验表明GAT-POS相比基线模型取得了较大的提升,特别是在非同质的图中。
4.【arXiv2021】Graph Neural Networks with Learnable Structural and Positional Representations
地址: https://arxiv.org/pdf/2110.07875v1.pdf
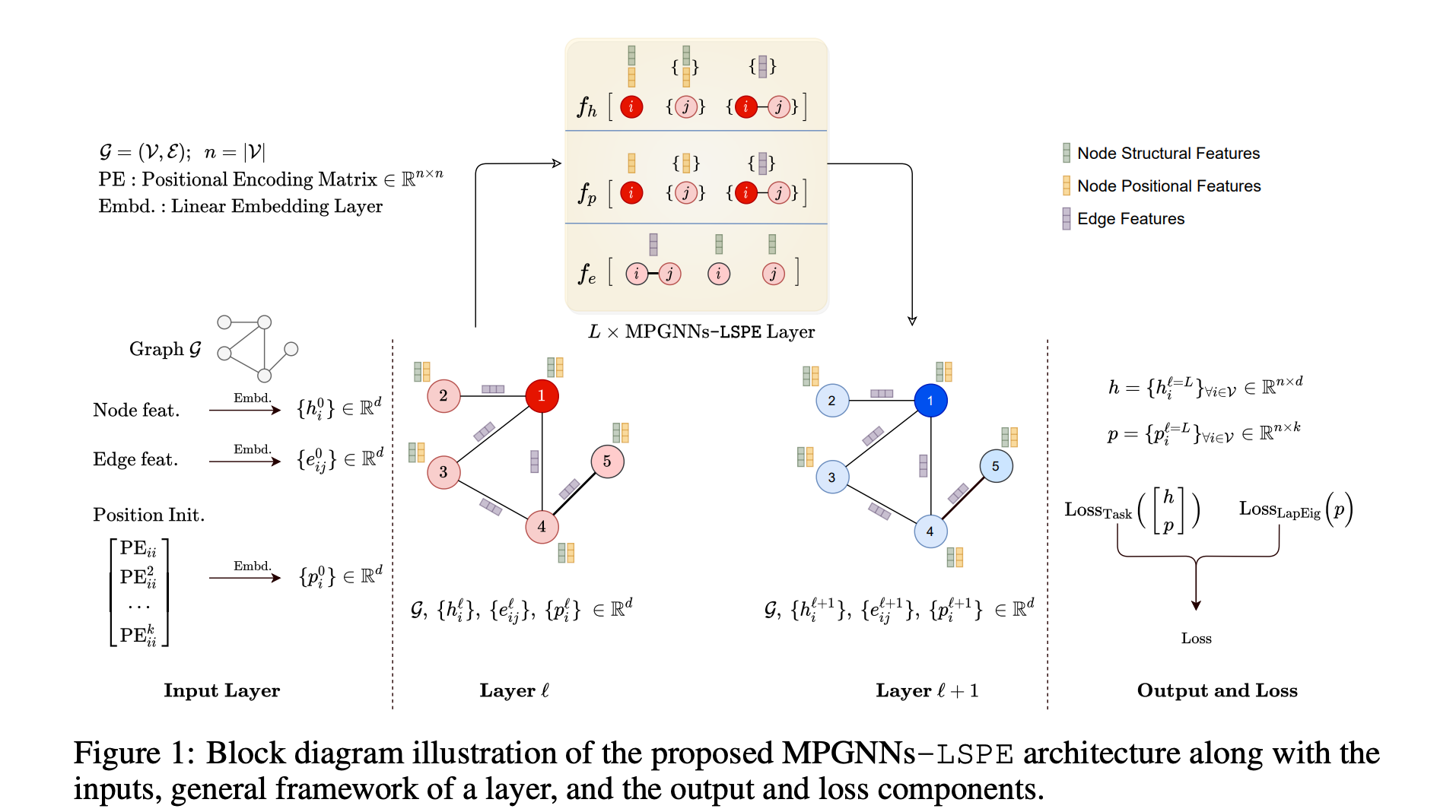
导读: 当前的图神经网络模型主要的问题是缺乏规范的位置节点的信息编码,这降低了图神经网络的表达力。
解决该问题的一种方式是引入节点的位置编码(PE),并将其注入到输入层,例如Transformer。
潜在的图 PE 是拉普拉斯特征向量。在本文中,文章建议将结构和位置表示解耦,进而是网络更容易学习到这两个基本属性。
文章引入了LSPE(可学习结构和位置)的新型通用架构编码,发现在多个分子数据集上都有较大的性能提升。

评论
沙发等你来抢