用户访问网站详细流程

 最新推荐文章于 2024-03-10 19:36:47 发布
最新推荐文章于 2024-03-10 19:36:47 发布
 阅读量1.8w
阅读量1.8w
 收藏
32
收藏
32


 点赞数
4
点赞数
4


一、DNS解析
当我们把这个网址输入到浏览器并回车之后,首先第一步会检查客户端本地的hosts和DNS缓存,客户端的DNS缓存,检查完之后,因为第一次请求一般本地的DNS缓存是没有的,一般这个hosts文件我是做测试使用的,这里面也是没有结果的,那么在这种情况下的话我们会找localDNS。
localDNS就是我们在本地计算机网卡里面配置的DNS服务器,里面会配置两台,一般优先使用的话是NDS1,在这种情况下找到localDNS,找到localDNS之后首先是查看它本地的一个缓存。
但在第一次查找情况下里面是没有的,那么它会把请求发到这个全球13台DNS根服务器,DNS根服务器它管理的只是顶级域名,也称为一级域名,然后在这种情况下,它会把结果传送给localDNS,发给这个localDNS的就是一级域名,一级域名里面我们把这些服务器称为NS服务器,而一级域名一般一组的话是6台,在这种情况下localDNS获取到一级域名也称为顶级域名NS服务器之后会找到一级域名的这些NS服务请求,请求2级域名,接下来这个一级域名的NS服务器会把二级域名服务器发给localDNS,(因为一级域名管理的是二级域名)这样情况下localDNS获取到二级域名之后它会再次发起请求, 比如说我们今天所讲的blog.csdn.net,这个.csdn属于一个二级域名,blog就是一个主机名,在这种情况下localDNS会在二级域名NS服务器那查询到这一条A记录,查询到这条A记录之后,首先第一它会把这个缓存结果在localDNS缓存一份并把这个结果返回客户端,这整个解析过程中我们有发现有一个叫缓存的东西,客户端也有缓存,在localDNS里面也有缓存,这缓存是无处不在的。
这缓存有个缓存周期叫ttr,一般这个ttr我们有3中可以选着,
(1)比较常用的选着我们选着600秒,一般对这条记录不怎么修改可以用这个选着,(2)如果改得特别频繁的话我们可以设置为1秒,
(3)不频繁是更改或是一年更改一次易或者一次也不更改我们可以设置成3600秒,我们为什么要设置呢?设置大小有什么优缺点呢?我们把这个ttr设置得越大客户端在解析的过程中就速度越快,因为你设置的越大它对这个localDNS或是在客户端本地缓存时间越长,基本上NDS查询都是在本地缓存查询,只有查询不到才去请求服务器,所以请求本地比请求服务器更快更高效。如果时间太短,客户端请求不是使用本地缓存那么请求DNS就是用这种递归和迭代那么速度就慢了,如果是自己搭建的NDS服务器的话那么它本身服务器压力也是很大,因为它会接收到N多的这种递归查询和迭代查询,所以它压力也会比较大。当这个客户端获取到DNS服务器地址之后接下来就到下面TCP连接了。
二、TCP三次握手建立连接
1、TCP服务器进程先创建传输控制块TCB,时刻准备接受客户进程的连接请求,此时服务器就进入了LISTEN(监听)状态;
2、TCP客户进程也是先创建传输控制块TCB,然后向服务器发出连接请求报文,这是报文首部中的同部位SYN=1,同时选择一个初始序列号 seq=x ,此时,TCP客户端进程进入了 SYN-SENT(同步已发送状态)状态。TCP规定,SYN报文段(SYN=1的报文段)不能携带数据,但需要消耗掉一个序号。
3、TCP服务器收到请求报文后,如果同意连接,则发出确认报文。确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时也要为自己初始化一个序列号 seq=y,此时,TCP服务器进程进入了SYN-RCVD(同步收到)状态。这个报文也不能携带数据,但是同样要消耗一个序号。
4、TCP客户进程收到确认后,还要向服务器给出确认。确认报文的ACK=1,ack=y+1,自己的序列号seq=x+1,此时,TCP连接建立,客户端进入ESTABLISHED(已建立连接)状态。TCP规定,ACK报文段可以携带数据,但是如果不携带数据则不消耗序号。
5、当服务器收到客户端的确认后也进入ESTABLISHED状态,此后双方就可以开始通信了。

三、http请求报文阶段
三次握手完毕后,客户端与服务器才正式开始传送数据,这时候才会去发送http的请求报文,(http请求报文它主要包含——请求行、请求头部、空白行、请求主体)
(1)请求行
1)请求方法(常用的请求方法)GET、HEAD、POST、PUT (POST 一般注册用户单机提交需要向服务器端发送信息并且写入到服务器端,比如写到数据库之类的,这样就可以用到POST方法;GET的话就是浏览页面比如说你打开一个博客,浏览的情况下它会用到GET方法;HEAD像我们做测试的时候,比如curl -i https://blog.csdn.net 就可以查看它的头部信息;PUT它可以理解为一个替换,像还有一些DELETE、TRACE可能不是很常用。)
2)资源地址(我们称为URL)
3)http协议版本,得到广泛使用的有3个版本,HTTP/0.9、HTTP/1.0、HTTP/1.1,HTTP/0.9已经被淘汰了,现在主流用的是HTTP/1.1,它比HTTP/1.0做了一些优化,1.1相比较1.0的话它有个自由连接keepalived。
(2)请求头部主要包括服务器和客户端的版本信息,你是用了Windows还是用了Linux,还是用了其他客户端信息,还有一些字符集、hosts信息。对应的响应报文里面就是时间、服务器的版本信息
(3)请求报文——才到空白行——然后到请求主体,如果你是请求的话 请求主体是空的,只有上传请求主体才是有内容的;然后对应的响应报文
四、网站及整个网站集群内部工作请求阶段
【网站】在这时候的话网页又分为3种,
1)1种是静态的——静态的话就是没有交互式的,服务器那边页面是什么客户端这边显示就是什么中间不会有任何改变它的文件后缀名常见的以html、shtml、Xml、CSS,静态没有一些交互式的功能,特效都没办法显示。
2)2种动态的——提供数据库访问、可以提供用户的登录注册、特效很多,常见的后缀名asp、php、jsp
3)3种伪静态,其实就是动态转静态,利用一个Rewrite重写的技术把它变成一个静态的网站,当我们访问一个网站的时候,它会进行一个Rewrite重写,再去指向真实的地址去数据库里面找。
4)为什么要做一个伪静态呢?其实方便搜索引擎方便去收入,因为搜索引擎对动态网站中的URL里面的?&效果不是很好,所以需要用这么一个技术去欺骗搜索引擎提供一个网站的排名和seo优化等等,这就是我们网站的3种常用的类型。
【网站内部集群】 我们知道一个网页看似是一个网页,实际上它里面包含了很多,可能也嵌入了一些其他资源类型,在整个页面加载的过程中,我们进行一次TCP连接就可以把整个资源的数据阐述完毕,当我们这个http请求报文,接收这个报文的负载均衡服务器,负载均衡服务器在企业中常见的有:硬件的有F5,软件的有七层的nginx,四层的有LVS;通过这个负载均衡会把这个请求发送到后端的静态WEB服务器(常见的Apache、nginx、Lighttpd)静态服务器的话会把这个静态请求直接响应给客户端,但是如果我们这个网站架构了CDN的话,那么最终像客户端返回这个静态请求CDN缓存服务器,一般情况下我们现在的网站都为动态网站,动态网站就需要一个动态的web服务器(一般常用的Tomcat等等)动态服务器的话就负责这些动态请求以及程序的解析,当然这个过程中可能涉及到结构化数据而这些数据会存储在后端的数据库服务器中,像互联网公司常用的mysql,当然为了数据库查询体验更好我们还会在前端部署数据库的缓存服务器,常用的redis和memcached等等,在这个过程中我们一直有听到数据库它存储的是结构化数据,而非结构化数据,像大型的公司阿里云就把它称为对象,比如像附件、图片、视频、音频等等,我们一般会存储在存储服务器上,因为这些也属于静态支援,我们会把它放在CDN上,提升用户的体验,加快用户的体验速度。这就是我们后端整个网站内部集群工作流程。
五、http响应报文阶段
内部工作流程完了数据已经准备好了接下来就像客户端发送这个http响应报文,主要也分为4个部分
1)首先第一部分起始行(协议版本,数字状态码:200代表OK;301代表永久跳转;403代表服务器做了限制没有权限访问;404代表用户访问的页面不存在;500代表服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理;502代表作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应;503代表临时的服务器维护或者过载,服务器当前无法处理请求;504代表作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。)最后才到响应主体——展现给用户看的界面)
2)第二部分响应头部类型(媒体类型、私有连接及时间、字符集等等)
3)第三部分空行
4)第四部分响应主体(响应头的结束以及响应主体的开始)
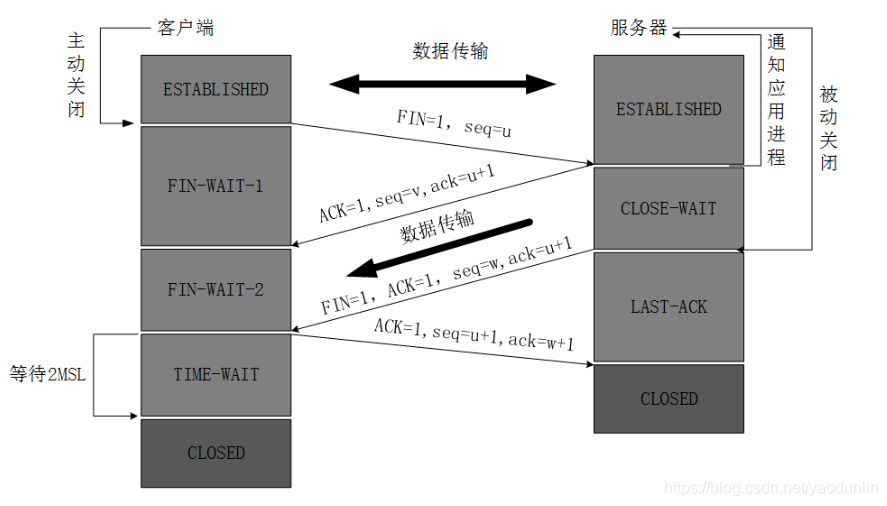
六、TCP4次挥手阶段
私有连接超时后才进入TCP的4次断开
1、客户端进程发出连接释放报文,并且停止发送数据。释放数据报文首部,FIN=1,其序列号为seq=u(等于前面已经传送过来的数据的最后一个字节的序号加1),此时,客户端进入FIN-WAIT-1(终止等待1)状态。 TCP规定,FIN报文段即使不携带数据,也要消耗一个序号。
2、服务器收到连接释放报文,发出确认报文,ACK=1,ack=u+1,并且带上自己的序列号seq=v,此时,服务端就进入了CLOSE-WAIT(关闭等待)状态。TCP服务器通知高层的应用进程,客户端向服务器的方向就释放了,这时候处于半关闭状态,即客户端已经没有数据要发送了,但是服务器若发送数据,客户端依然要接受。这个状态还要持续一段时间,也就是整个CLOSE-WAIT状态持续的时间。
3、客户端收到服务器的确认请求后,此时,客户端就进入FIN-WAIT-2(终止等待2)状态,等待服务器发送连接释放报文(在这之前还需要接受服务器发送的最后的数据)。
4、服务器将最后的数据发送完毕后,就向客户端发送连接释放报文,FIN=1,ack=u+1,由于在半关闭状态,服务器很可能又发送了一些数据,假定此时的序列号为seq=w,此时,服务器就进入了LAST-ACK(最后确认)状态,等待客户端的确认。
5、客户端收到服务器的连接释放报文后,必须发出确认,ACK=1,ack=w+1,而自己的序列号是seq=u+1,此时,客户端就进入了TIME-WAIT(时间等待)状态。注意此时TCP连接还没有释放,必须经过2∗∗MSL(最长报文段寿命)的时间后,当客户端撤销相应的TCB后,才进入CLOSED状态。
6、服务器只要收到了客户端发出的确认,立即进入CLOSED状态。同样,撤销TCB后,就结束了这次的TCP连接。可以看到,服务器结束TCP连接的时间要比客户端早一些。














 1826
1826










 暂无认证
暂无认证





















 到【灌水乐园】发言
到【灌水乐园】发言










weixin_53262354: 引用「/etc/init.d/libvirtd restart」 systemctl start libvirtd
CSDN-Ada助手: 不知道 云原生入门 技能树是否可以帮到你:https://edu.csdn.net/skill/cloud_native?utm_source=AI_act_cloud_native
管哥-运维: 开源的没有导出功能 付费版才有。
Haydn_Hong: 工单数据无法导出,这个功能非常有用。
hexiaoqiang_learn: 写的这是什么