MySQL中使用索引优化
最新推荐文章于 2024-05-29 10:47:58 发布

阳862
 最新推荐文章于 2024-05-29 10:47:58 发布
最新推荐文章于 2024-05-29 10:47:58 发布
 阅读量572
阅读量572
 收藏
收藏
 点赞数
点赞数
最新推荐文章于 2024-05-29 10:47:58 发布
阅读量572
收藏

 点赞数
点赞数
目录
数据准备
避免索引失效应用-全值匹配
避免索引失效应用-最左前缀法则
避免索引失效应用-其他匹配原则
1、
2、
3、
4、
5、

一.使用索引优化
索引是数据库优化最常用也是最重要的手段之一,通过索引通常可以帮助用户解决大多数的MySQL的性能优化问题。
数据准备
use world;
create table tb_seller(
sellerid varchar(100),
name varchar(100),
nickname varchar(50),
password varchar(60),
status varchar(1),
address varchar(100),
createtime datetime,
primary key(sellerid)
);
insert into tb_seller values('alibaba','阿里巴巴','阿里小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('baidu','百度科技有限公司','百度小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('huawei','华为科技有限公司','华为小店','e10adc3949ba59abbe057f20f883e','0','北京市','2088-01-01 12:00:00'),
('itcast','传智播客教育科技有限公司','传智播客','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('itheima','黑马程序员','黑马程序员','e10adc3949ba59abbe057f20f883e','0','北京市','2088-01-01 12:00:00'),
('luoji','罗技科技有限公司','罗技小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('oppo','oppo科技有限公司','oppo官方旗舰店','e10adc3949ba59abbe057f20f883e','0','北京市','2088-01-01 12:00:00'),
('ourpalm','掌趣科技股份有限公司','掌趣小店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('qiandu','千度科技','千度小店','e10adc3949ba59abbe057f20f883e','2','北京市','2088-01-01 12:00:00'),
('sina','新浪科技有限公司','新浪官方旗舰店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00'),
('xiaomi','小米科技','小米官方旗舰店','e10adc3949ba59abbe057f20f883e','1','西安市','2088-01-01 12:00:00'),
('yijia','宜家家居','宜家官方旗舰店','e10adc3949ba59abbe057f20f883e','1','北京市','2088-01-01 12:00:00');
-- 创建组合索引
create index index_seller_name_sta_addr on tb_seller(name,status,address);避免索引失效应用-全值匹配
该情况下,索引生效,执行效率高。
-- 避免索引失效应用-全值匹配
-- 全值匹配,和字段匹配成功即可,和字段顺序无关
explain select * from tb_seller ts where name ='小米科技' and status ='1' and address ='北京市';
explain select * from tb_seller ts where status ='1' and name ='小米科技' and address ='北京市';避免索引失效应用-最左前缀法则
该情况下,索引生效,执行效率高。
-- 避免索引失效应用-最左前缀法则
-- 如果索引了多列,要遵守最左前缀法则,指的是查询从索引的最左前列开始,并且不跳过索引中的列
explain select * from tb_seller ts where name='小米科技';-- key_lem:403
explain select * from tb_seller ts where name='小米科技' and status ='1';-- key_lem:410
explain select * from tb_seller ts where status ='1' and name='小米科技' ;-- key_lem:410,依然跟顺序无关
-- 违反最左前缀法则,索引失效
explain select * from tb_seller ts where status ='1';-- 违反最左前缀法则,索引失效
-- 如果符合最左前缀法则,但是出现跳跃某一列,只有最左列索引生效
explain select * from tb_seller where name='小米科技' and address='北京市';-- key_lem:403
避免索引失效应用-其他匹配原则
该情况下,索引生效,执行效率高。
1、

-- 避免索引失效应用-其他匹配原则
-- 范围查询右边的列,不能使用索引
explain select * from tb_seller where name= '小米科技' and status >'1' and address='北京市';-- key_lem:410,没有使用status这个索引
-- 不要在索引列上进行运算操作,索引将失效。
explain select * from tb_seller where substring(name,3,2) ='科技';-- 没有使用索引
-- 字符串不加单引号,造成索引失效。
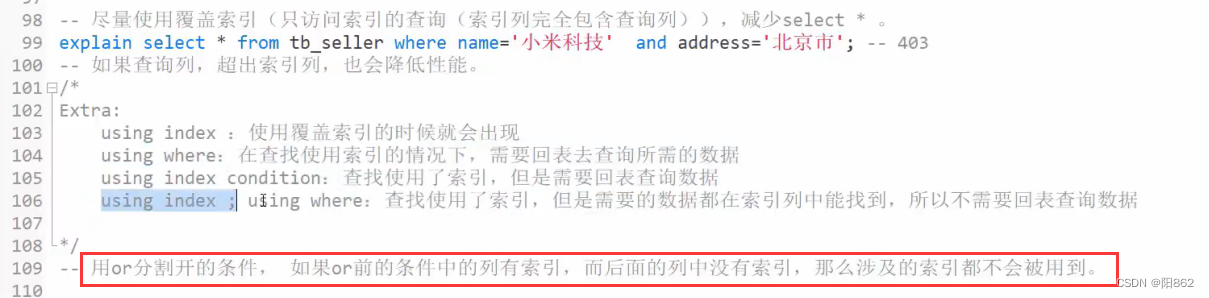
explain select * from tb_seller where name='小米科技' and status = 1 ;-- key_lem:403,没有使用status这个索引2、
explain中的extra列
| extra | 含义 |
| using filesort | 说明mysq|会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,称为“文件排序" ,效率低。 |
| using temporary | 需要建立临时表(temporary table)来暂存中间结果,常见于order by和group by;效率低 |
| using index | SQL所需要返回的所有列数据均在一棵索引树上,避免访问表的数据行,效率不错。 |
| using where | 在查找使用索引的情况下,需要回表去查询所需的数据 |
| using index condition | 查找使用了索引,但是需要回表查询数据 |
| using index;using where | 查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询数据 |




但是再加有个password

3、
4、


5、
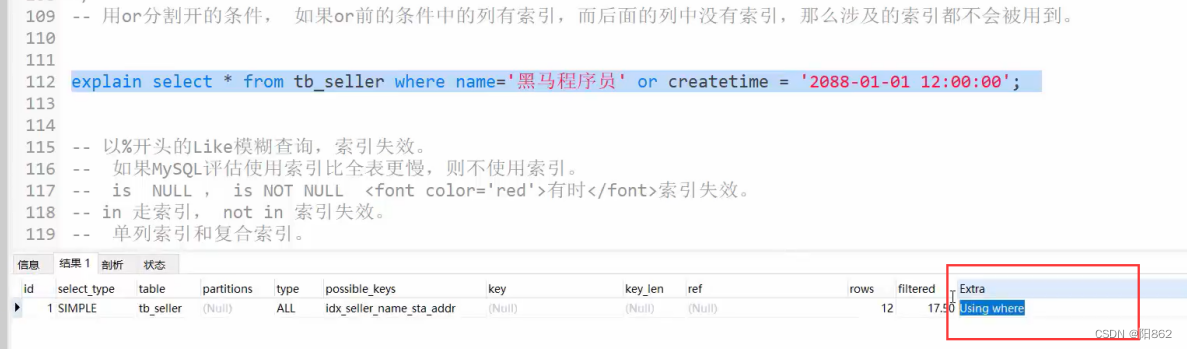
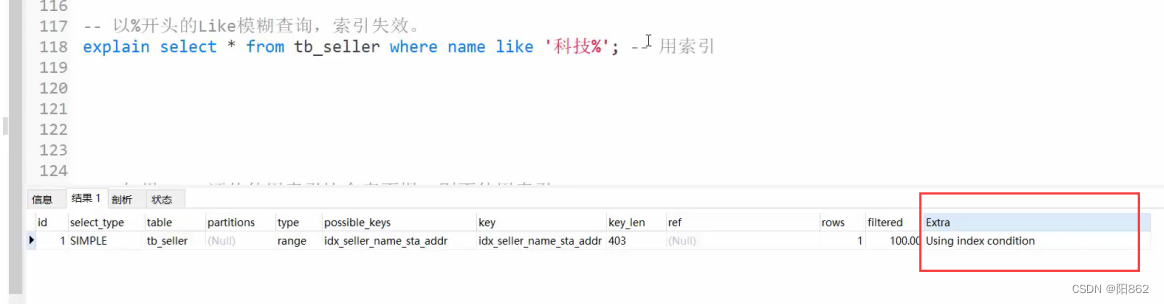
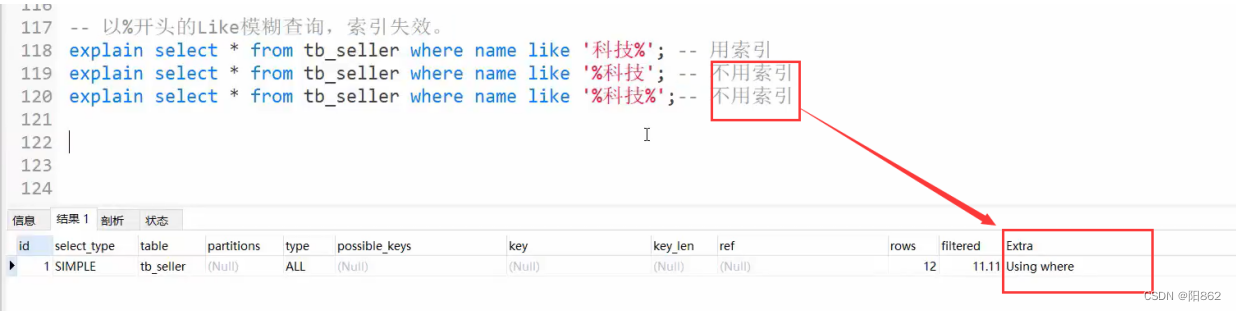
- 如果MySQL评估使用索引比全表更慢,则不使用索引。
- is NULL , is NOT NULL有时有效,有时索引失效。
- in走索引,not in索引失效。
- 单列索引和复合索引,尽量使用符合索引




验证

创建了单一的三个索引,最后面where全使用了但explain显示只用了index_name

















 10万+
10万+










 暂无认证
暂无认证























 到【灌水乐园】发言
到【灌水乐园】发言












残浪980: 请问我想给前15个国家设置不同的颜色改怎么弄呢
Boning Lin: itheima 怕不是大师兄喔
做而论道_CS: 由补码换算到十进制数,也极其简单。 你只需记住:【补码首位的权,是负数】。 一般的八位二进制数,各个位的权是: 128、64、32、16、8、4、2、1; 如果是八位的补码,各个位的权则是: -128、64、32、16、8、4、2、1。 例如,补码是:1110 0001, 它代表的十进制是:-128 + 64 + 32 + 1 = -31。 又如,补码是:0110 0001, 它代表的十进制是:0 + 64 + 32 + 1 = +97。 你看吧,仅仅使用【进制转换】,就完事了! 哪里还需要用到原码反码? ------------ 实际上,二进制数,它就是数! 什么原码反码补码,都是不存在的事! 不存在,为什么还要讲、还要学、还要考研? 因为,计算机老师讲这些,可以赢得丰厚的利益! 所以,这些老师,才会如此毁人不倦坑人不浅!
做而论道_CS: 在两位十进制数运算中,舍弃进位,就是减去了一百。 所以,加 99,再减 100,当然就是 “-1” 了。 八位二进制数是:0000 0000 ~ 1111 1111。 也就是十进制数:0 ~ 255。 如果有进位,就是:256。 此时,加上 255 (1111 1111),再舍弃进位 256, 这不也就是-1 吗? 所以:+255 (1111 1111),就是-1; 同理:+254 (1111 1110),就是-2; +253 (1111 1101),就是-3; 。。。 +128 (1000 0000),就是-128。 这些正数,就是计算机专家 “发明” 的补码。 另外,加上 127 (0111 1111),是不会出现进位的。 那么,也就不用舍弃进位,也就不用减 256 了。 所以,加上 127,就不会出现 “减法的作用”。 因此,0 ~ 127,这些就是 “正数”。 而 128 ~ 255,就是负数:-128 ~ -1。 于是,0~ 255,就代表了:-128 ~ +127。 ------------------ 老外的算术能力很差,不懂什么是进位, 更弄不懂什么是舍弃进位。 所以,就编造了一套谎言: 机器数真值符号位原码反码补码正数三码相同 负数取反加一符号位不变符号位也参加运算模 我们的老师,数学底子也很差啊! 小学的算术,都看不透,就被老外忽悠瘸了! 天天喋喋不休的:原码反码取反加一。。。 也不知道有多少学生因此而挂科。
做而论道_CS: 哪有什么原码反码补码呀! 虽然,计算机使用的,是二进制数。 但是,二进制数,也是数,和十进制数,是雷同的。 二进制数,并不是什么原码反码补码。 符号位,也是根本就不存在的。 所谓的“补码”,不过是一道小学算术题而已。 所谓的“补码”,与什么进制,都没有关系。 所谓的“补码”,也不是计算机专家发明的。 另外,在码长八位时,各码的范围如下。 原码:-127 ~ +127; 反码:-127 ~ +127; 补码:-128 ~ +127。 看到了吧? -128 只有补码,没有原码和反码。 没有原码,你拿什么取反? 没有反码,你拿什么加一? 取反加一,不可用! -128 的补码,你是怎么得来的呢? 实际上,取反加一,根本就没有任何理论依据。 只是计算机专家用来唬弄老外的! 你还想跟着老外学算术? 你直接就掉坑里了! ------------------ 你看看十进制数吧,两位的:0~99。 最大值 99,就能当做“负一”来用。 如:27 + 99 = (一百) 26 27 - 1 = 26 只要你忽略进位,仍旧保持两位数,它们就是相等的。 由此可知,舍弃了进位: 正数,就能当做负数来用。 加法,也就能实现减法运算。 在计算机中,舍弃进位,会怎样: 可以省略减法器,简化硬件! 只需配置一个加法器,便可走遍天下。 如果你明白什么是 “舍弃进位”: 你就会懂得 “补码的来源与意义”。 老外,是不懂这些的。 所以,才编造了:符号位原码。。。