合工大Python爬虫实验——按关键词爬取新闻网站

 已于 2023-05-12 12:27:31 修改
已于 2023-05-12 12:27:31 修改
 阅读量3.3k
阅读量3.3k
 收藏
57
收藏
57


 点赞数
10
点赞数
10
时隔一年,笔者又拿着实验报告来写篇博客。
实验原理
爬虫实验使用了Python中的requests、beautifulsoup、json和pandas库,requests用于发送HTTP请求,beautifulsoup用于处理并解析响应的HTML文档,json用于解析json数据,pandas用于数据储存。
1、HTTP请求构造
HTTP协议定义Web客户端如何从Web服务器请求Web页面,以及服务器如何把Web页面传送给客户端。HTTP协议采用了请求/响应模型。客户端向服务器发送一个请求报文,请求报文包含请求的方法、URL、协议版本、请求头部和请求数据。服务器以一个状态行作为响应,响应的内容包括协议的版本、成功或者错误代码、服务器信息、响应头部和响应数据。
HTTP/1.1协议中共定义了八种方法来以不同方式操作指定的资源:
GET HEAD POST PUT DELETE TRACE OPTIONS CONNECT
爬虫大多用的就是GET或者POST
2、响应数据处理
对于请求的响应,一般情况下,有html 和 json 两种格式。
HTML数据的解析原理:HTML以尖括号为标记,内部元素分为块元素与行内元素。利用beautifulsoup可以选择目标元素内的文本,爬取并存储即可完成数据解析。
Json数据解析:JSON类似于XML,是一种数据交换格式。JSON 是 JavaScript 原生格式,这意味着在 JavaScript 中处理 JSON 数据不需要任何特殊的 API 或工具包。解析后直接分析键值对即可提取目标信息。
实验设计
从实验原理出发,模拟整个请求响应流程,防止爬虫被网站阻拦。系统流程与结构如下:
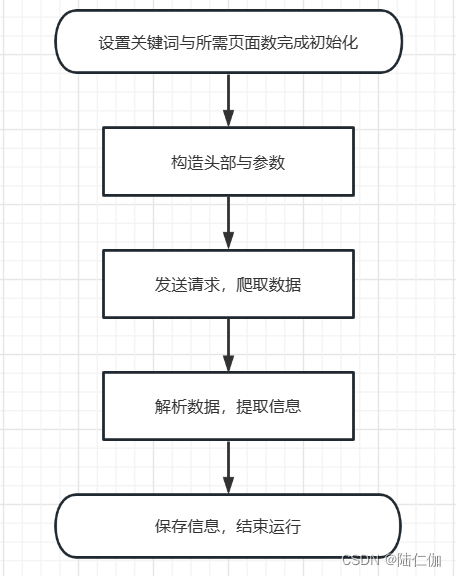
爬虫程序流程如下图:
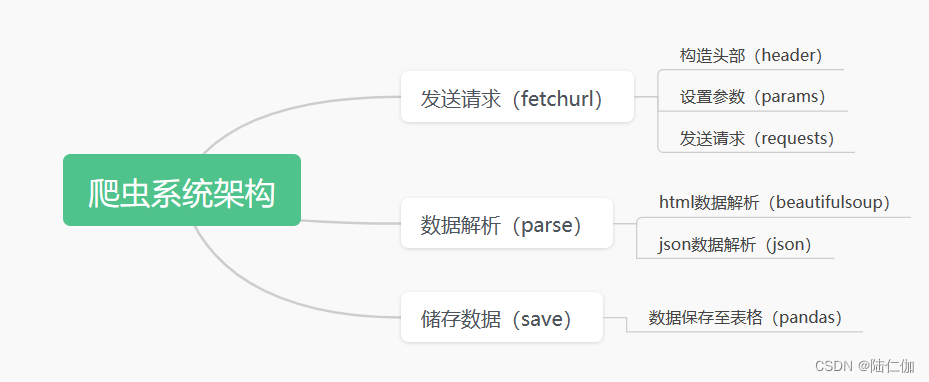
系统架构如下图:
关键问题及其解决方法
爬取信息失败,未能获得正常响应
根据分析,修改header以及参数后发现,原因在于header中没有加入Referer这一键值对,导致网站将程序将程序的请求判定为爬虫。
在一些网站信息的获取过程中,只有在指定的站点发起请求,服务器才会允许返回数据(这样可以防止资源被盗用在其他网站使用)。因此加入Rerferer使得问题解决。
解决方法:在相关网站打开开发者工具,观察目标数据包的头部,如下:
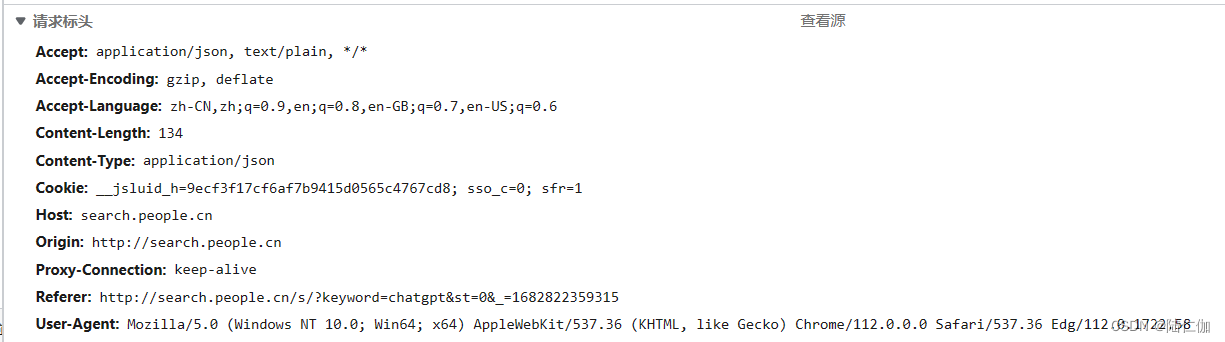
根据实际情况合理构造头部即可获得正常响应。
获得正常响应,但获得的数据并不符合关键词
针对这一问题,同样从url,headers以及参数方向考虑,由于url与headers并不设计到关键词的值,因此考虑参数的值与格式。
解决方法:
打开工具查看实际参数

构造相同参数进行测试
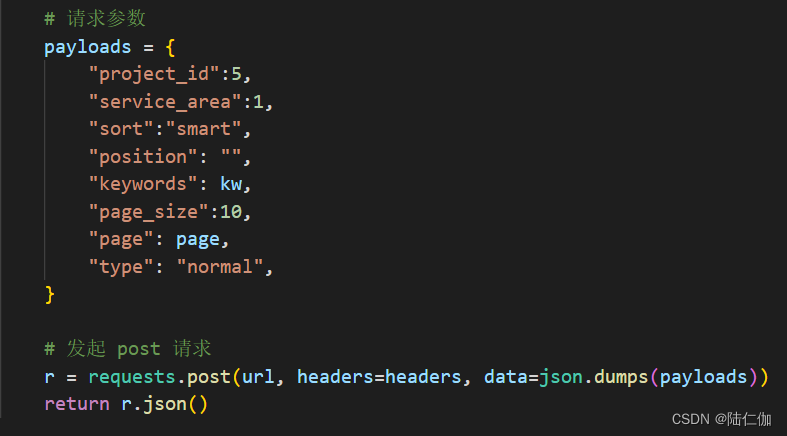
结果返回失败,于是考虑格式,发现南方新闻网参数的接收格式为application/x-www-form-urlencoded; charset=UTF-8,直接接收表单,不需要将参数json处理再传输,于是直接发送参数,然后即得到正确结果。
设计结果
参数设置:可根据实际需要,设置关键词
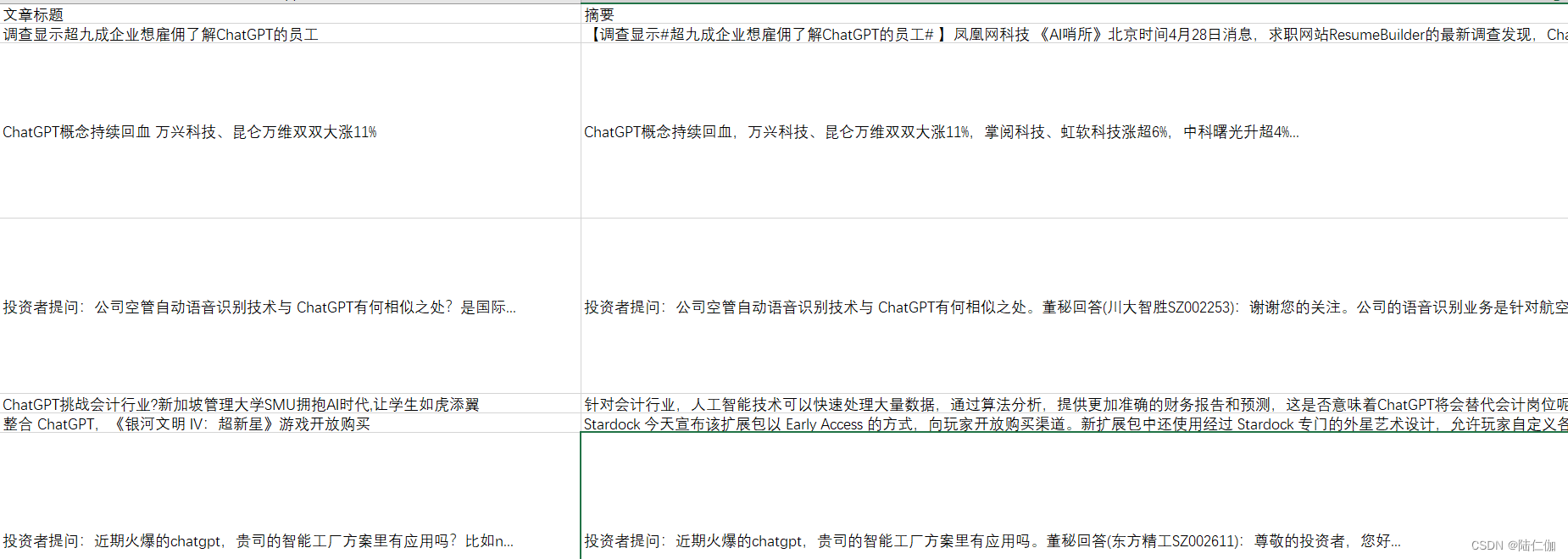
爬取结果展示:
南方新闻网:

新浪新闻:

爬虫源码如下:
南方新闻网爬虫源码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import os
def fetchUrl(url, kw, page):
# 请求头
headers={
"accept":"*/*",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"origin":"https://search.southcn.com",
"referer": "https://search.southcn.com/?keyword=chatgpt&s=smart&page={}".format(page),
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58",
}
# 请求参数
payloads = {
"project_id":5,
"service_area":1,
"sort":"smart",
"position": "",
"keywords": kw,
"page_size":10,
"page": page,
"type": "normal",
}
# 发起 post 请求
r = requests.post(url, headers=headers, data=payloads)
return r.json()
def parseJson(jsonObj):
#解析数据
records = jsonObj["data"]["news"]["list"]
for item in records:
# 解析了"文章id", "标题", "副标题", "发表时间", "编辑", "版面", "摘要", "链接"
pid = item["id"]
editor = item["editor"]
content = item["digest"]
displayTime = item["pub_time_detail"]
subtitle = item["sub_title"]
title = BeautifulSoup(item["title"], "html.parser").text
url = item["url"]
yield [[pid, title, subtitle, displayTime, editor, content, url]]
def saveFile(path, filename, data):
# 如果路径不存在,就创建路径
if not os.path.exists(path):
os.makedirs(path)
# 保存数据
dataframe = pd.DataFrame(data)
dataframe.to_csv(path + filename + ".csv", encoding='utf_8_sig', mode='a', index=False, sep=',', header=False )
if __name__ == "__main__":
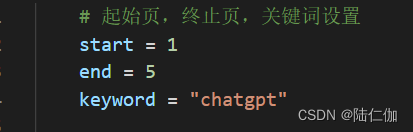
# 起始页,终止页,关键词设置
start = 1
end = 5
keyword = "chatgpt"
# 保存表头
headline = [["文章id", "标题", "副标题", "发表时间", "编辑", "摘要", "链接"]]
saveFile("./data/", "southcn", headline)
#爬取数据
for page in range(start, end + 1):
url = "https://search.southcn.com/api/search/all"
html = fetchUrl(url, keyword, page)
for data in parseJson(html):
saveFile("./data/", "southcn", data)
print("第{}页爬取完成".format(page))
新浪新闻网爬虫:
import requests
from bs4 import BeautifulSoup
import pandas as pd
import os
from lxml import etree
def fetchUrl(url, kw,page):
# 请求头
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"content-type": "application/x-www-form-urlencoded",
"origin": "https://search.sina.com.cn",
"referer": "https://search.sina.com.cn/news",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36 Edg/112.0.1722.58",
}
# 请求参数
payloads = {
"q":kw,
"c":"news",
"range":"all",
"size":10,
"page":page
}
# 发起 post 请求
r = requests.post(url, headers=headers, data=payloads)
return r
def parseHtml(htmlObj):
html_selector = BeautifulSoup(htmlObj.text,'lxml')
news = html_selector.find_all("div",attrs = {'class': 'box-result clearfix'})
# 解析数据
for item in news:
# 解析"文章标题", "摘要", “来源与发表时间", "链接"
title = item.find("a").text
content = item.find("p",attrs = {"class":"content"}).text
origin = item.find("span",attrs = {"class":"fgray_time"}).text
url = item.find("a")['href']
yield [[title, content,origin, url]]
def saveFile(path, filename, data):
# 如果路径不存在,就创建路径
if not os.path.exists(path):
os.makedirs(path)
# 保存数据
dataframe = pd.DataFrame(data)
dataframe.to_csv(path + filename + ".csv", encoding='utf_8_sig',
mode='a', index=False, sep=',', header=False)
if __name__ == "__main__":
# 起始页,终止页,关键词设置
start = 1
end = 3
keyword = "chatgpt"
# 保存表头
headline = [["文章标题", "摘要", "来源与发表时间", "链接"]]
saveFile("./data/", "sinanews", headline)
# 爬取数据
for page in range(start, end + 1):
url = "https://search.sina.com.cn/news"
html = fetchUrl(url, keyword, page)
for data in parseHtml(html):
saveFile("./data/", "sinanews", data)
print("第{}页爬取完成".format(page))














 2711
2711










 合肥工业大学
合肥工业大学








 到【灌水乐园】发言
到【灌水乐园】发言










盛一碗阳光: 您好,同请教您爬新闻内容的问题解决了吗
煎饼果孒o○: 我看了那个网页,感觉改的没问题,,但就是爬不出内容
煎饼果孒o○: 您好,如果想把新闻内容也爬出来需要怎样修改
CSDN-Ada助手: 恭喜您写出了这么精彩的博客,非常感谢您分享您的Python爬虫实验经验。您的文章非常有用,帮助了我们更好地理解如何按关键词爬取新闻网站。接下来,我希望您能够继续保持创作热情,分享更多的Python实践经验,不断提升自己的技能水平。期待您的下一篇博客! CSDN 正在通过评论红包奖励优秀博客,请看红包流:https://bbs.csdn.net/?type=4&header=0&utm_source=csdn_ai_ada_blog_reply3,我们会奖励持续创作和学习的博主,请看:https://bbs.csdn.net/forums/csdnnews?typeId=116148&utm_source=csdn_ai_ada_blog_reply3
CSDN-Ada助手: 不知道 算法 技能树是否可以帮到你:https://edu.csdn.net/skill/algorithm?utm_source=AI_act_algorithm