项目实战:ES的增加数据和查询数据

 最新推荐文章于 2024-05-06 10:47:30 发布
最新推荐文章于 2024-05-06 10:47:30 发布
 阅读量3.8k
阅读量3.8k
 收藏
5
收藏
5


 点赞数
点赞数

文章目录
- 背景
- 在ES中增加数据
- 新建索引
- 删除索引
- 在ES中查询数据
- 查询数据总数量
- 项目具体使用(实战)
- 引入依赖
- 方式一:使用配置类连接对应的es服务器
- 创建配置类
- 编写业务逻辑----根据关键字查询相关的聊天内容
- 在ES中插入数据
- 总结提升
背景
最近需要做一个有关查询聊天记录的功能,通过资料了解到使用ES可以方便我们快速查询内容。自己进行ES框架的搭建,感兴趣的可以看博客进行学习:https://blog.csdn.net/weixin_45309155/article/details/132686375?spm=1001.2014.3001.5501
ES搭建好之后就是应用了,下面就先总结一下关于最近在项目中的应用。
在ES中增加数据
因为在要在项目中进行增加数据。查阅资料需要有索引。所以要先进行索引的创建。这部分是先在postman中调用接口进行创建索引。
新建索引
在postman中,使用接口:
http://116.XXXXXX:9200/chat
IP地址+端口号+你需要创建的索引名称。请求类型为put
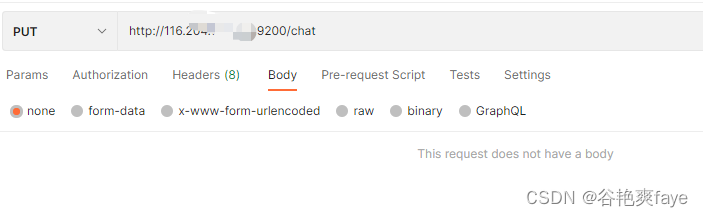
如果创建成功之后就会显示如下代码:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "chat"
}
删除索引
在postman中使用接口:
http://116.XXXXXX:9200/chat
P地址+端口号+你需要删除的索引名称。请求类型为delete
如果删除成功会显示代码:
{
"acknowledged": true
}
这里需要注意的是:当你删除索引的时候,如果该索引下有数据内容的话,会把对应的数据进行删除。
在ES中查询数据
在postman中使用接口:
http://116.XXXXX:9200/chat/_search
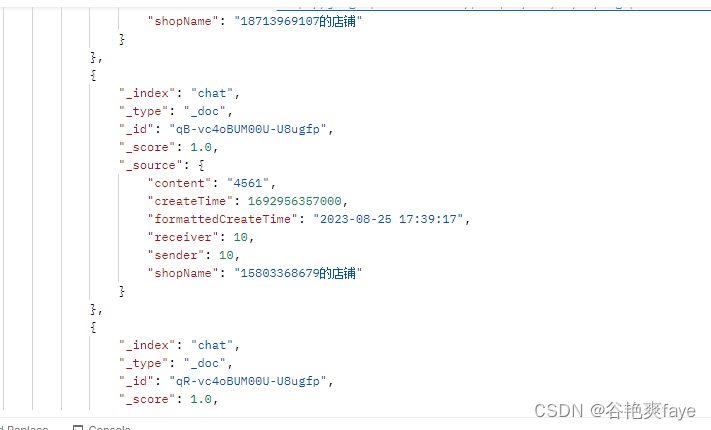
如果有内容,就可以看到相应插入的数据
查询数据总数量
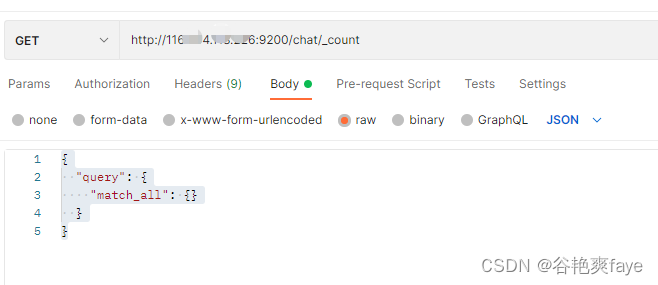
在postman中使用接口
http://116.XXXXX:9200/chat/_count
请求类型为get
请求体为:
{
"query": {
"match_all": {}
}
}
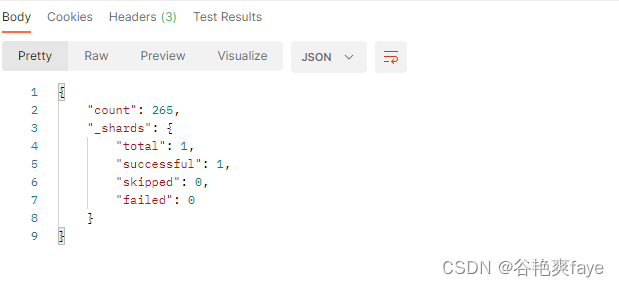
如果有数据的话会显示数据的总数;
项目具体使用(实战)
引入依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client-sniffer</artifactId>
<version>${elasticsearch.version}</version>
</dependency>
方式一:使用配置类连接对应的es服务器
创建配置类
@Configuration
public class ElasticSearchClientConfig {
@Bean
public RestClientBuilder restClientBuilder() {
RestHighLevelClient restHighLevelClient =new RestHighLevelClient (RestClient.builder(new HttpHost("ES的ip地址",9200,"http")));
return client;
}
}
编写业务逻辑----根据关键字查询相关的聊天内容
这里需要入参:需要查询的关键字keyword
public List<Map<String, Object>> search(String userId,String fileName, String keyword) throws IOException {
ArrayList<Map<String, Object>> resultList = new ArrayList<>();
try {
if (userId.isEmpty()||fileName.isEmpty()||keyword.isEmpty()){
throw new Exception();
}
// 构建查询条件
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
// 匹配receiver或sender为userId的文档
boolQueryBuilder.should(QueryBuilders.termQuery("receiver", userId));
boolQueryBuilder.should(QueryBuilders.termQuery("sender", userId));
// 部分匹配content字段的关键字
MatchQueryBuilder contentQueryBuilder = QueryBuilders.matchQuery(fileName, keyword);
boolQueryBuilder.must(contentQueryBuilder);
// 创建搜索请求,chat为索引值
SearchRequest searchRequest = new SearchRequest("chat");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
// 执行搜索
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 解析结果
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
Map<String, Object> sourceAsMap = documentFields.getSourceAsMap();
Object receiver = sourceAsMap.get("receiver");
Object sender = sourceAsMap.get("sender");
if ((receiver != null && receiver.toString().equals(userId)) || (sender != null && sender.toString().equals(userId))) {
resultList.add(sourceAsMap);
}
}
return resultList;
}catch (Exception e){
e.printStackTrace();
}
return resultList;
}
在ES中插入数据
public Boolean parseContent() throws IOException {
List<SendMessagePojo> list= queryContent();//需要插入的内容
BulkRequest bulkRequest = new BulkRequest();
for (int i = 0; i < list.size(); i++) {
bulkRequest.add(new IndexRequest("chat").source(JSONObject.toJSONString(list.get(i)), XContentType.JSON));
}
try {
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
return !bulk.hasFailures();
}catch (Exception e){
e.printStackTrace();
}
return null;
}
插入到es时,不需要提前定义列名,当你什么实体的类型的值时,就可以直接按照你的实体名称进行存储。
上面两段业务代码可以根据自己的业务代码进行修改调整。
总结提升
Elasticsearch (ES) 是一个分布式搜索和分析引擎,它具有强大的实时数据处理能力。以下是关于ES增加和删除业务场景的总结,旨在提升您对ES的理解。
ES的增加业务场景
- 数据索引和搜索
ES的主要用途之一是将数据索引到Elasticsearch集群中,并使用其强大的搜索功能来查询和检索数据。以下是一些使用ES进行数据索引和搜索的业务场景:
电子商务网站:将商品信息索引并快速搜索,实现商品的全文搜索、过滤和排序。
新闻网站:将新闻文章索引到ES中,通过关键字搜索、相关性排序等功能提供高效的全文搜索服务。
日志分析:将日志数据索引到ES,利用其强大的搜索和聚合功能来实时分析和监控系统日志。
社交媒体分析:将社交媒体数据索引到ES,通过搜索和聚合功能来分析用户行为、趋势和情感分析等。
2. 实时数据处理
ES对实时数据处理的支持使其成为处理大规模实时数据流的理想选择。以下是一些使用ES进行实时数据处理的业务场景:
监控和告警系统:将实时产生的监控指标和日志数据索引到ES中,通过实时搜索和聚合功能进行告警和异常检测。
实时日志分析:将实时产生的日志数据索引到ES中,通过搜索和聚合功能快速分析应用程序或系统的实时日志。
事件处理和通知:将实时事件索引到ES中,通过实时搜索和推送功能来处理事件并发送通知。
3. 数据聚合和分析
ES提供了强大的聚合和分析功能,可以对大规模数据集进行高效的数据挖掘和分析。以下是一些使用ES进行数据聚合和分析的业务场景:
业务智能报表:利用ES的聚合功能,对大规模数据进行聚合和汇总,生成业务智能报表和可视化图表。
用户行为分析:通过对用户行为数据的聚合和分析,提取用户喜好、兴趣和行为模式等信息,用于个性化推荐和营销策略。
数据探索和发现:通过搜索和聚合功能,对数据集进行探索和发现,挖掘数据中的潜在模式、关联性和趋势。
ES的删除业务场景
- 数据清理和过期数据删除
由于ES的索引是基于倒排索引的,对于长时间未更新的数据,可能会占用不必要的磁盘空间和内存资源。以下是一些使用ES进行数据清理和过期数据删除的业务场景:
日志数据清理:定期删除旧的日志数据,以保持ES集群的性能和存储效率。
缓存数据刷新:根据数据的过期时间,在ES中实现缓存数据的自动刷新和删除。
2. 数据保护和隐私合规
根据隐私法规和合规要求,需要定期删除或销毁某些类型的数据。以下是一些使用ES进行数据保护和隐私合规的业务场景:
用户数据删除:根据用户的请求或特定时间段,删除包含敏感信息的用户数据。
合规数据保留:根据法律法规的要求,对特定类型的数据进行保留期限管理和数据销毁操作。
总结来说,ES的增加和删除功能可以应用于各种业务场景,包括数据索引和搜索、实时数据处理、数据聚合和分析,以及数据清理和隐私合规。通过充分利用ES的功能,可以提升数据的可发现性、实时性和分析能力,从而为业务带来更大的价值。
















 796
796











 Java领域优质创作者
Java领域优质创作者
































 到【灌水乐园】发言
到【灌水乐园】发言












追梦杰瑞: 用AI跑个问题,复制粘贴进来就成一篇文章了?
2401_84309770: 原理非常棒
눈_눈131: 我看的那个课说springboot 1.x版本需要用这个注解,2.x版本不用,然后我的3.x版本又需要用
wtt199210: 如果我是服务器端,客户端不能更改的情况下,服务器端要如何设置呢
谷艳爽faye: 我这里没有做这个需求,所以没有这部分代码