HashMap为什么扩容重新计算位置后,还能找到以前数据的位置

向着百万年薪努力的小赵
 已于 2022-07-19 21:09:19 修改
已于 2022-07-19 21:09:19 修改
 阅读量1.9w
阅读量1.9w
 收藏
11
收藏
11
 点赞数
6
点赞数
6
已于 2022-07-19 21:09:19 修改
阅读量1.9w
收藏
11

 点赞数
6
点赞数
6
于 2022-07-09 22:41:57 首次发布



关于HashMap的详解文章请移步:
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
HashMap在进行扩容时,使用的rehash方式非常巧妙,因为每次扩容都是翻倍,与原来计算的 (n-1)&hash的结果相比,只是多了一个bit位,所以节点要么就在原来的位置,要么就被分配到"原位置+旧容量"这个位置。
怎么理解呢?例如我们从16扩展为32时,具体的变化如下所示:

因此元素在重新计算hash之后,因为n变为2倍,那么n-1的标记范围在高位多1bit(红色),因此新的index就会发生这样的变化:
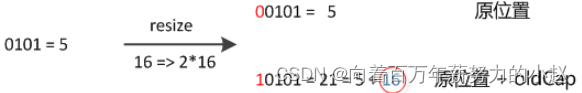
说明:5是假设计算出来的原来的索引。这样就验证了上述所描述的:扩容之后所以节点要么就在原来的位置,要么就被分配到"原位置+旧容量"这个位置。
因此,我们在扩充HashMap的时候,不需要重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就可以了,是0的话索引没变,是1的话索引变成“原索引+oldCap(原位置+旧容量)”。可以看看下图为16扩充为32的resize示意图:
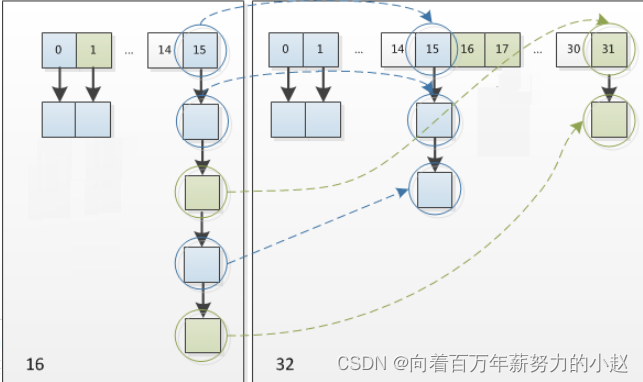
正是因为这样巧妙的rehash方式,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,在resize的过程中保证了rehash之后每个桶上的节点数一定小于等于原来桶上的节点数,保证了rehash之后不会出现更严重的hash冲突,均匀的把之前的冲突的节点分散到新的桶中了。
















 4万+
4万+












 Java领域新星创作者
Java领域新星创作者










































 到【灌水乐园】发言
到【灌水乐园】发言












晓钰别浪: 为什么我用gcd,negate等方法会报错?
小泽991: 黑白的
xxxp_2654616130: 真的这么好啊,博主回答下
飞鹰猪头: eg、例子: //支付金额 BigDecimal paymentPrice = orderItemList.stream().map(OrderItem::getPaymentPrice) .reduce(BigDecimal.ZERO, BigDecimal::add); --------------------------讲解: 这段代码使用 Java 8 的 Stream API 对订单项列表进行处理。首先,通过`orderItemList.stream()`将订单项列表转换为流。然后,使用`map(OrderItem::getPaymentPrice)`对每个订单项应用`getPaymentPrice()`方法,将每个订单项的支付价格提取出来。接下来,使用`reduce(BigDecimal.ZERO, BigDecimal::add)`将所有的支付价格进行累加,初始值为`BigDecimal.ZERO`,并使用`BigDecimal::add`作为累加的操作。 总而言之,这段代码的作用是计算订单项列表中所有订单项的支付价格之和,并将结果存储在`paymentPrice`变量中。
DBCce: 喔,我不晓得是以2为底