Co-Occurrence Matrix——共现矩阵的计算方法

 最新推荐文章于 2024-04-07 16:51:50 发布
最新推荐文章于 2024-04-07 16:51:50 发布
 阅读量9.1k
阅读量9.1k
 收藏
53
收藏
53


 点赞数
14
点赞数
14

Co-Occurrence Matrix——共现矩阵的计算方法
- Co-Occurrence Matrix的介绍
- Co-Occurrence Matrix的生成
- Co-Occurrence Matrix的范例
- Co-Occurrence Matrix存在的问题及解决方法
- Co-Occurrence Matrix的优缺点
- SVD方法存在的问题
Co-Occurrence Matrix的介绍
Co-Occurrence Matrix 是 具有固定上下文窗口的共现矩阵 (Co-Occurrence Matrix with a fixed context window)。
遵循的基本原理是:类似的词往往出现在一起,并且会有类似的上下文,例如,苹果是一种水果,芒果是一种水果。(Similar words tend to occur together and will have a similar context for example — Apple is a fruit. Mango is a fruit.)因此,苹果和芒果往往有一个类似的背景,即水果。(Apple and mango tend to have a similar context i.e fruit.)
- 共现(Co-occurrence)——对于给定的语料库,一对单词(如 w 1 w1 w1和 w 2 w2 w2)的共现是指它们在上、下文窗口中同时出现的次数。
For a given corpus, the co-occurrence of a pair of words say w1 and w2 is the number of times they have appeared together in a Context Window.
- 上下文窗口(Context Window)——指的是某个单词w的上下文范围的大小,也就是前后多少个单词以内的才算是上下文?一般,上、下文窗口由数字和方向指定。
Context window is specified by a number and the direction.
\quad
比如一个Context Window Size = 2的示意图如下:

Co-Occurrence Matrix的生成
如何生成Co-Occurrence矩阵(How to form the Co-occurrence matrix)?
1. 由语料库中所有不重复单词构成矩阵A以存储单词的共现次数。(The matrix A stores co-occurrences of words.)
2. 人为指定Context Window大小,计算每个单词在指定大小的上下文窗口中与它周围单词同时出现的次数。(In this method, we count the number of times each word appears inside a window of a particular size around the word of interest.)
3. 依次计算语料库中各单词对的共现次数。(Calculate this count for all the words in the corpus.)
Co-Occurrence Matrix的范例
范例一:
让我们通过一个例子具体示范Co-Occurrence Matrix的生成过程:
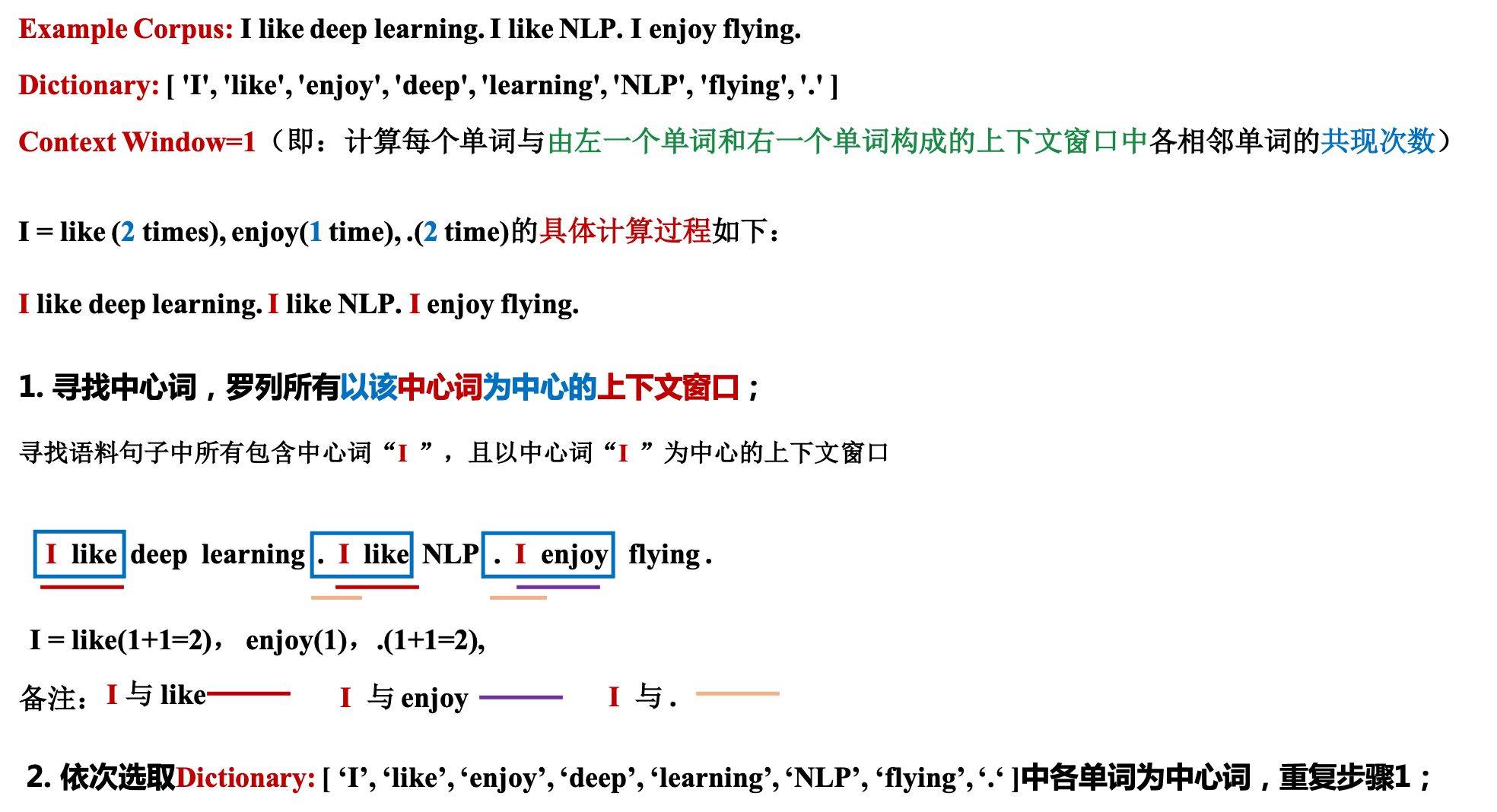
- 假设我们的语料库包含以下三句话(Let our corpus contain the following three sentences:):
I enjoy flying.
I like NLP.
I like deep learning.
- 构造由语料库中所有不重复单词生成的单词Dictionary(From the above corpus, the list of unique words present are as follows:)
Dictionary: [ 'I', 'like', 'enjoy', 'deep', 'learning', 'NLP', 'flying', '.' ]
- 假设上下文窗口
Context Window的大小等于1,这意味着每个单词的上下文单词都是由左一个单词,右一个单词构成。(Let window size =1,This means that context words for each and every word are 1 word to the left and one to the right.) - 依次计算由语料库中所有不重复单词构成的矩阵A中各单词与其左(右)一个单词在上下文窗口中同时出现的次数。
I = enjoy(1 time), like(2 times) # I和enjoy共现1次,I和like共现2次
enjoy = I (1 time), flying(2 times)
flying = enjoy(1 time)
like = I(2 times), NLP(1 time), deep(1 time)
NLP = like(1 time)
deep = like(1 time), learning(1 time)
learning = deep(1 time)
共现次数的计算过程如下图所示:
- 最终生成的co-occurrence matrix如下所示:
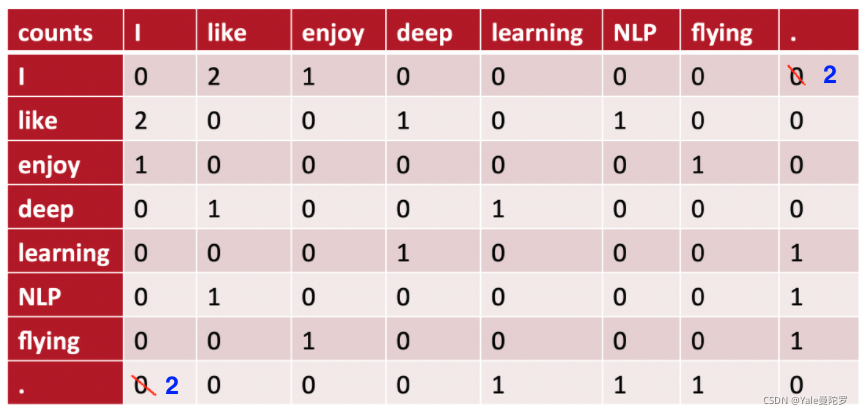
上图摘自《 Part 7: Step by Step Guide to Master NLP – Word Embedding in Detail》,不过原图在计算"I"与"."的共现次数时存在错误,此处已修改更正。
范例二:
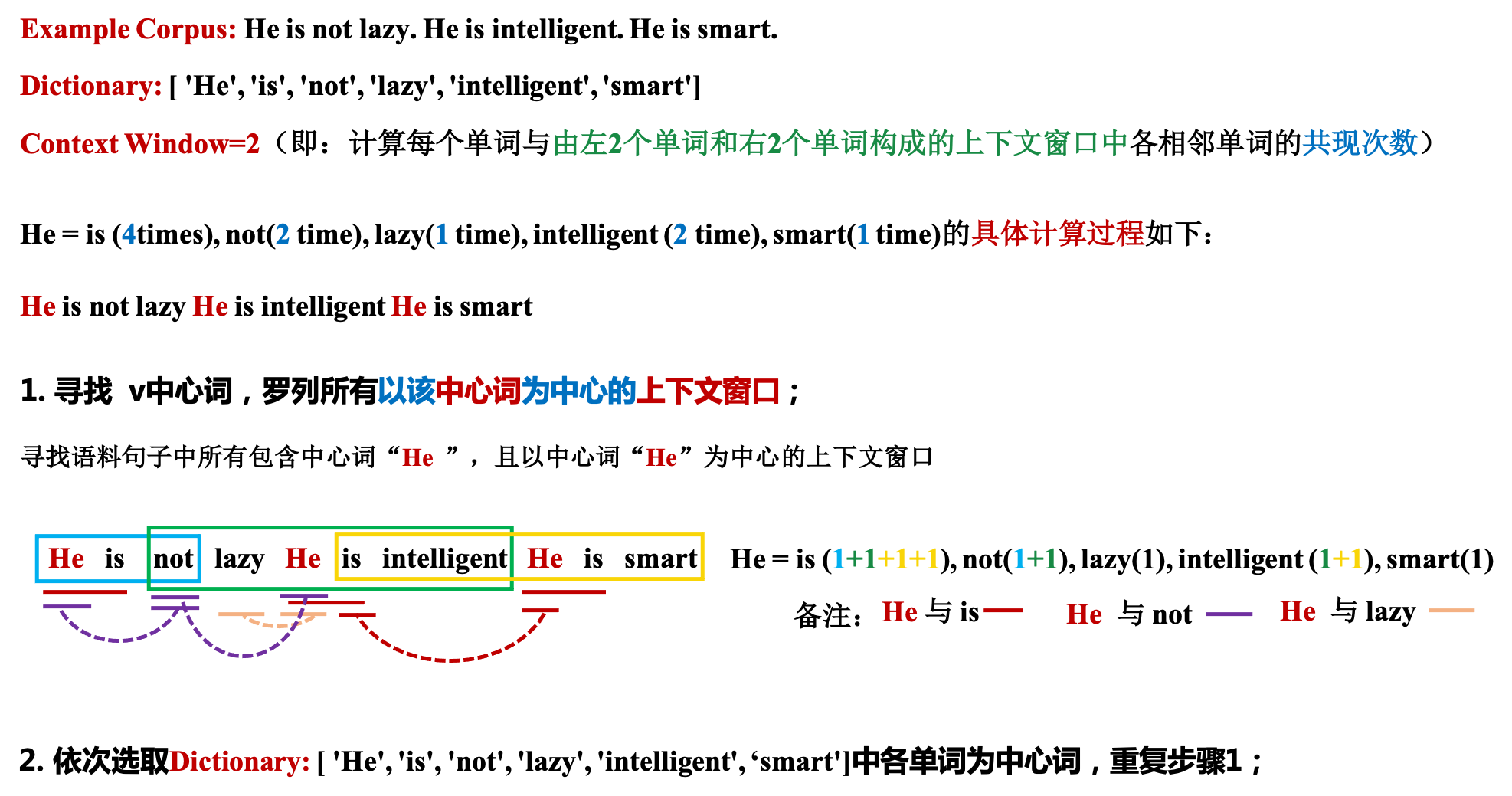
假设我们有如下的语料库:
He is not lazy.
He is intelligent.
He is smart.
我们假设Context Window=2,那么我们就可以得到如下的co-occurrence matrix:
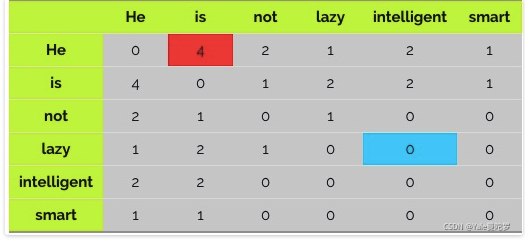
备注:此处不考虑标点符号"."
\quad
上图红框(Red cell)表示“He”和“is”在上下文窗口等于2时的共现次数,这里我们观察到这个数字是4。为了理解和可视化计数,具体共现情况如下图:

共现次数的计算过程如下图所示:
Co-Occurrence Matrix存在的问题及解决方法
Co-Occurrence Matrix存在的问题:
- 共现矩阵增加了字典或词汇的大小(Increase in size with dictionary or vocabulary.)
- 对于一个庞大的语料库,这个共现矩阵可能变得非常复杂(
高维),后续分类模型面临稀疏性问题,模型的健壮性较差。(For a huge corpus, this co-occurrence matrix could become really complex (high-dimension) and subsequent classification models face the issue of sparsity. Models are less robust.)
Co-Occurrence Matrix的解决方法:
降维——我们只将“大部分”重要信息存储在固定的、少量的维度中,即:密集向量而不是稀疏向量。尺寸通常在25–1000维左右。(We only store “most” of the important information in a fixed, small number of dimensions that is a dense vector instead of a sparse vector.The dimension size is usually around 25 – 1000.)
奇异值分解(SVD)和主成分分析(PCA)是两种特征值方法,主要用于将高维数据集降维,同时保留重要信息。(Singular value decomposition(SVD) and principal component analysis(PCA) are two eigenvalue methods used to reduce a high-dimensional dataset into fewer dimensions while retaining important information.)
参考链接: Part 7: Step by Step Guide to Master NLP – Word Embedding in Detail
共现矩阵的PCA分解:
\quad
请记住,这个具有固定上下文窗口的共现矩阵不是通常使用的词向量表示。相反,这个共现矩阵使用 PCA、SVD 等技术分解为因子,这些因子的组合形成词向量表示。
\quad
举例而言,如果你对一个大小为 N × N N×N N×N 的共现矩阵 K K K执行 P C A PCA PCA分解,你将获得 V V V 个主成分。你可以从这 V V V 个主成分中选择 k k k 个分量,因此,组成新矩阵的形式为 N × k N×k N×k。
\quad
此时,一个单词,将在 k k k 维中表示(不用在 N N N 维中表示),但仍能捕获几乎相同的语义。通常, k k k 的数量级为几百。
\quad
因此, P C A 分 解 PCA分解 PCA分解的作用就是将一个Co-Occurrence 矩阵 K K K分解为三个矩阵, U U U, S S S 和 V V V,其中 U U U 和 V V V都是正交矩阵。重要的是, U U U 和 S S S 的点积表示单词向量, V V V表示单词上下文。
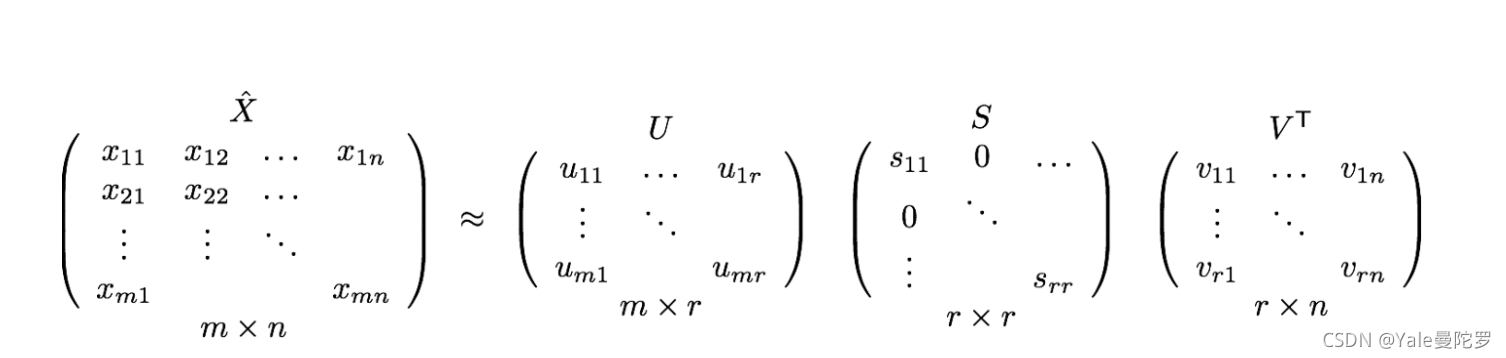
共现矩阵的优点
- 保留了单词之间的语义关系。即男人和女人往往比男人和苹果更亲近。
- 以 SVD 为核心,产生比现有方法更准确的词向量表示。
- 使用因式分解,这是一个定义明确的问题,可以有效地解决。
- 必须计算一次,并且一旦计算就可以随时使用。从这个意义上说,它比其他人更快。
共生矩阵的缺点
- 它需要巨大的内存来存储共现矩阵。
但是,这个问题可以通过在系统之外分解矩阵来规避,例如在 Hadoop 集群等中,并且可以保存。
Co-Occurrence Matrix的优缺点
Co-Occurrence Matrix的优点:
1. 它保留了单词之间的语义关系。(It preserves the semantic relationship between words.)
例如,男人和女人往往比男人和苹果更加亲密。
2.它以奇异值分解(SVD)为核心,是一种比现有方法更精确的词向量表示法。( It uses Singular Value Decomposition (SVD) at its core, which produces more accurate word vector representations than existing methods.)
3.它使用因子分解,这是一个可以被更好定义的问题,而且可以被有效地解决。(It uses factorization which is a well-defined problem and can be efficiently solved.)
4.共现矩阵只需计算一次,后续可以重复使用。因此,它比其他的词向量表示法更快。( If we compute this matrix once, then it can be used anytime wherever required. So, In this sense, it is faster than others.)
Co-Occurrence Matrix的缺点:
存储共现矩阵,需要消耗大量内存。 但是,为了解决这个问题,我们可以将矩阵分解出系统(例如在Hadoop集群中)来避免。
SVD方法存在的问题
SVD(Singular Value Decomposition)奇异值分解是机器学习中最重要的矩阵分解方法,它 能够将一个任意形状的矩阵分解成一个正交矩阵和一个对角矩阵以及另一个正交矩阵的乘积。
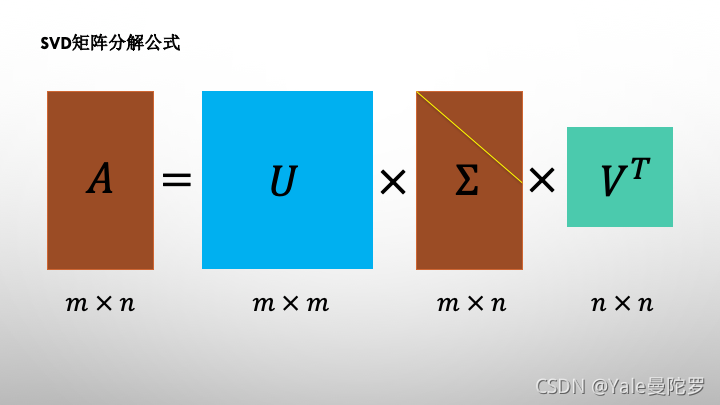
参考链接: Co-occurrence matrix & Singular Value Decomposition (SVD)
关于SVD详细的分解、计算后续会进一步补充。
1. 矩阵的维度经常变化(新词添加非常频繁,语料库大小也会经常变化)。(The dimensions of the matrix change very often (new words are added very frequently and corpus changes in size).)
2. 矩阵是非常稀疏的,因为大多数单词不会出现。(The matrix is extremely sparse since most words do not cooccur.)
3. 矩阵通常是高维的(106*106)。(The matrix is very high dimensional in general ( 106 *106 ))
4. 执行SVD的训练成本是正常成本的平方倍。(Quadratic cost to train (i.e. to perform SVD))
5. 需要在X上加入一些hacks来解释词频的严重不平衡。(Requires the incorporation of some hacks on X to account for the drastic imbalance in word frequency)
您可以在这里找到共现矩阵和SVD的实现。

















 288
288



































 到【灌水乐园】发言
到【灌水乐园】发言












sunshine1324: ROI pooling应该是fast RCNN中提出来的吧
Yang_03: 牛的大佬!
Yang_03: https://github.com/django-extensions/django-extensions/issues/92 根据这个改动可以
MickeyCV: 用mmdetection这个工具包,一大把fasterrcnn预训练模型,参考我的帖子一步步配,为了解决这个问题我自己当起了博主
Yang_03: 请问后面有找到别的可下载的链接吗?