MapReduce 原理、过程详解与优化 Yarn Hdfs Mapreduce 三者联系
最新推荐文章于 2024-04-22 10:46:48 发布

weixin_41734687
 最新推荐文章于 2024-04-22 10:46:48 发布
最新推荐文章于 2024-04-22 10:46:48 发布
 阅读量3.1k
阅读量3.1k
 收藏
37
收藏
37
 点赞数
8
点赞数
8
最新推荐文章于 2024-04-22 10:46:48 发布
阅读量3.1k
收藏
37

 点赞数
8
点赞数
8




一 Mapreduce Yarn Hdfs三者联系
(比喻有不恰当的地方,但更容易理解三者之间的关系)
Mapreduce,Yarn,Hdfs三者之间的关系,可以用电脑来进行解释。大体可以理解为:windows系统电脑上的一个视频播放软件(mapreduce),通过windows操作系统(yarn)找到存在电脑硬盘(hdfs)上的电影,然后视频播放器播放电影
- Yarn 相当于电脑的操作系统,统管电脑的资源调配
- Mapreduce相当于电脑上的一个应用程序,电脑上可以有很多应用程序
- Hdfs相当于电脑的硬盘,存储文件
Yarn,Mapreduce,Hdfs三者是解藕的,电脑必须要有操作系统,目前Yarn比较合适,电脑必须要有硬盘存储数据,目前一般用Hdfs;但是电脑可以有很多应用程序,所以Spark,Mapreduce,Kafka等都可以当作运行在Yarn系统上的应用程序。
Yarn Mapreduece Hdfs 联系

- 1.mapreduce在客户端启动mapreduce application master(简称mam),mam
- 2.mam想resourcemanager申请运算资源
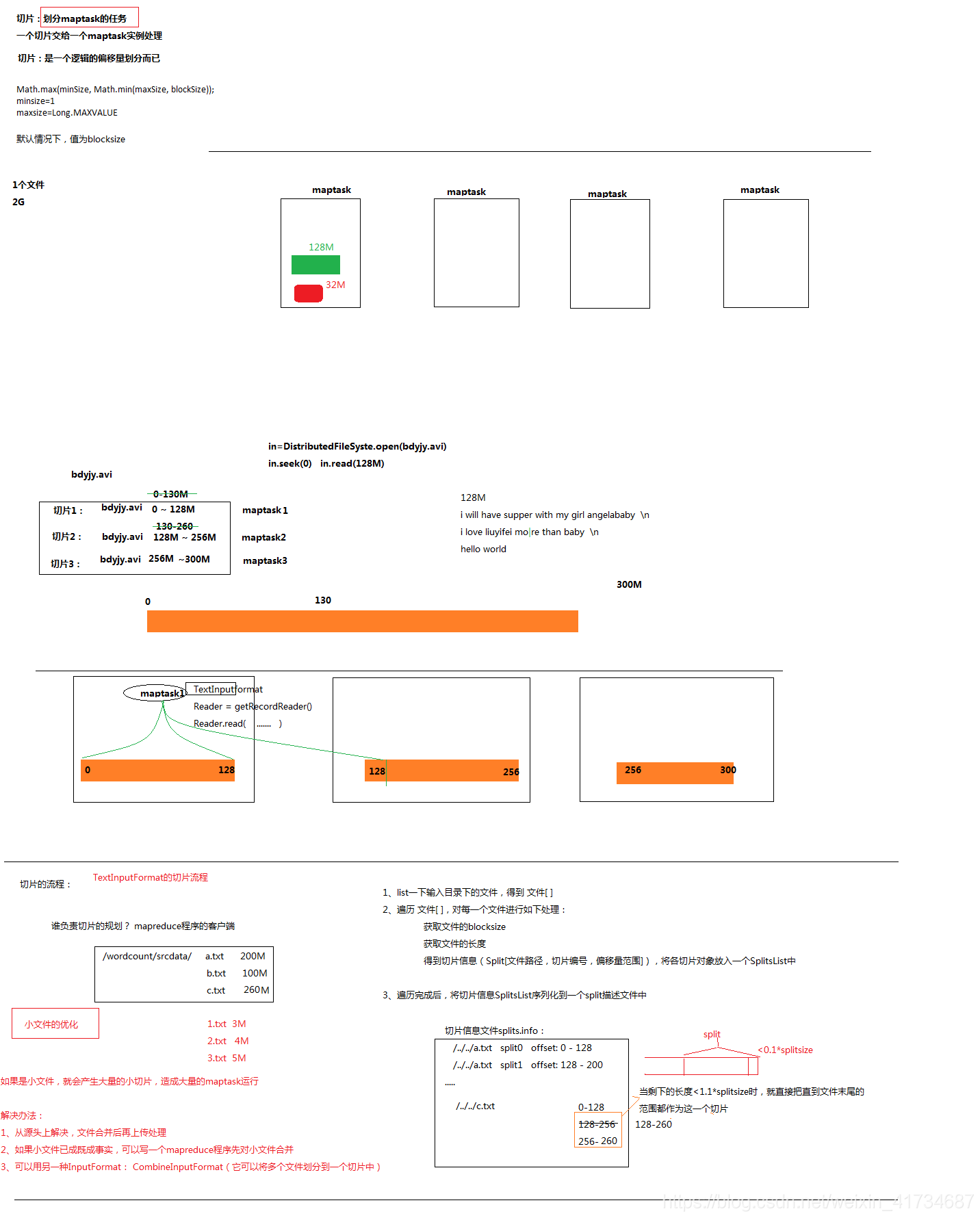
- 3.mam拿到运算资源后,遍历hdfs上的文件,然后规划启动多少个maptask和reducetask
- 4.mam把mapreduce程序分发到各个节点
- 5.各个节点利用nodemanager管理运算资源,各个节点启动container容器进行运算,即执行maptask,reduecetask
二 Mapreduce
2.1.Mapreduce介绍
Maprecude是一个分布式程序运算框架,是用户基于hadoop的数据分析应用的核心框架
Mapreduce: 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式程序,并运行在一个hadoop集群上
maprecude运行全流程

mapreduce原理

Maptask任务切片机制
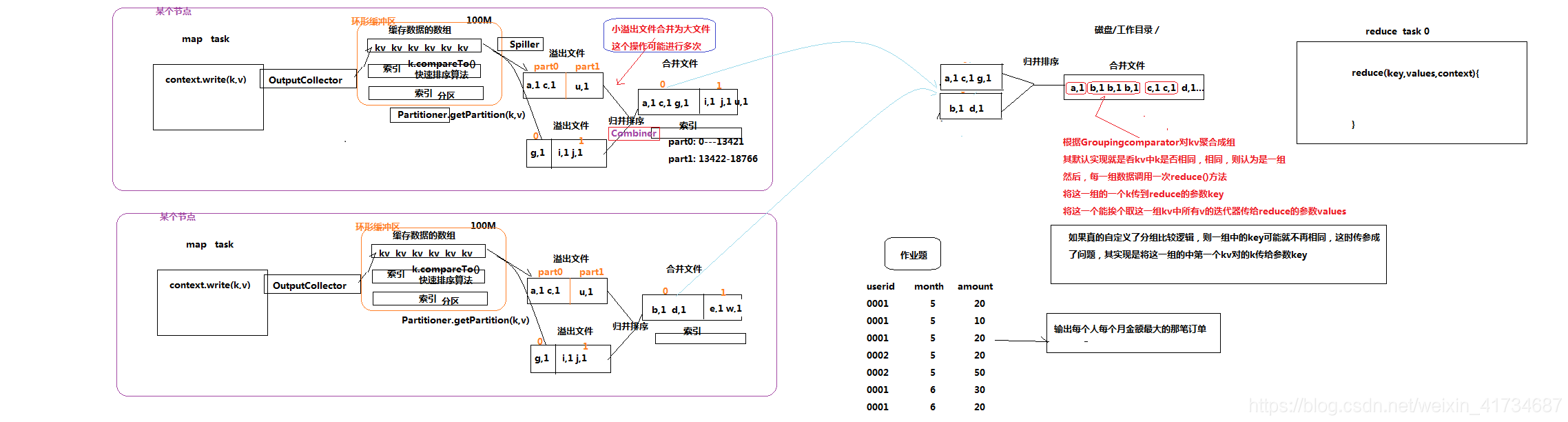
mapreduce 的shuffle原理
Mapreduce Yarn 工作机制
















 9300
9300










 暂无认证
暂无认证


















 到【灌水乐园】发言
到【灌水乐园】发言










登峰大数据: 请教:数仓各层之间,要执行多个SQL,完成后,再往下执行下一层的SQL。NIFI中如何执行完一批SQL后,再执行下一批SQL呢?
Ana10g: 请问Impala连接数据之后架构是空的是什么情况,初始sql要怎么填写
吵吵叭火: 谢谢
hjsw1: 这个是什么算法
LRJasd: 同学,你用连通图做的时候,如何筛选掉的弱边关系 ,怎么设置的时间衰减