python如何爬取网页视频_快就完事了!10分钟用python爬取网站视频和图片
 最新推荐文章于 2024-04-16 16:27:39 发布
最新推荐文章于 2024-04-16 16:27:39 发布
 阅读量6k
阅读量6k
 收藏
21
收藏
21


 点赞数
3
点赞数
3
原标题:快就完事了!10分钟用python爬取网站视频和图片
话不多说,直接开讲!教你如何用Python爬虫爬取各大网站视频和图片。

638855753
网站分析:
我们点视频按钮,可以看到的链接是:http://www.budejie.com/video/

接着我们点开网页源码,看下面之处
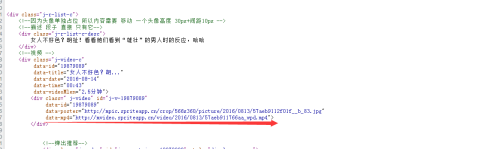
接着我们把那个下面画红线的链接点开,可以看到是个视频。
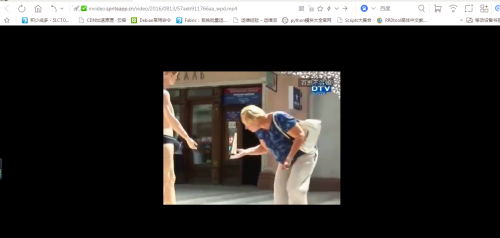
下面我进行相似的操作点图片按钮,可以看到链接:http://www.budejie.com/pic/

接着我们点开网页源码。
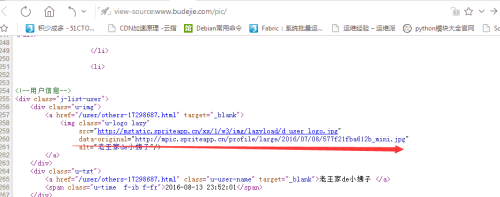
相同操作,我们点开链接:http://mpic.spriteapp.cn/ugc/2016/07/07/577d9f0cdd67d_1.jpg
基本上就是这么个套路,也就用了python的两个模块 一个urllib 一个re正则
效果图:
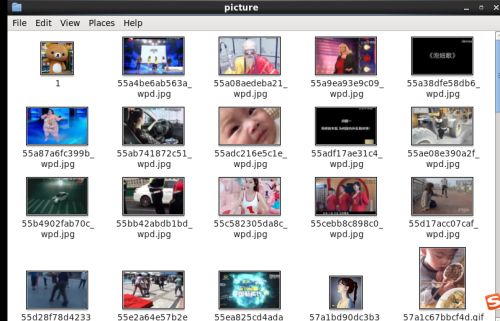
这个是我爬下来的图片
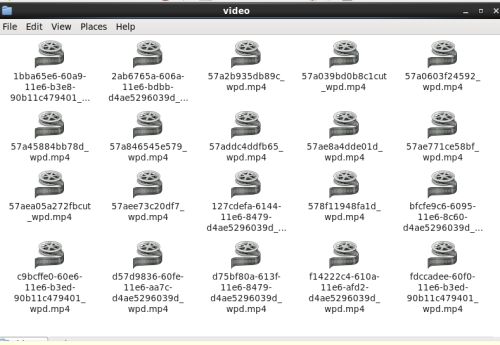
这个是我爬下来的视频
这个是我把Linux上的视频拖一下到Windows上给大家看效果。

下面直接上代码!!!
爬视频的代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
importurllib,re
defgeturl:
html = urllib.urlopen("http://www.budejie.com/video/").read
reg = r'data-mp4="(.*?)"'
returnre.findall(reg,html)
forpage inrange(1,100):
fori ingeturl:
printi #i是视频的链接地址
video = urllib.urlopen(i).read
fwc = open('./video/%s'%i.split('/')[-1],'wb')
fwc.write(video)
fwc.close
爬图片的代码
# -*- coding:utf-8 -*-importurllib,redefgeturl:html = urllib.urlopen("http://www.budejie.com/pic/").readreg = r'data-original="(.*?)"'returnre.findall(reg,html)forpage inrange(1,100):fori ingeturl:printi #i是图片的链接地址video = urllib.urlopen(i).readfwc = open('./picture/%s'%i.split('/')[-1],'wb')fwc.write(video)fwc.close
声明:本文于网络整理,著作权归原作者所有,如有侵权,请联系小编删除。返回搜狐,查看更多
责任编辑:














 1353
1353















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









