







1. 爬虫简介
1.1 爬虫概论
网络爬虫(Web crawler)也叫网络蜘蛛(Web spide)自动检索工具(automatic indexer),是一种”自动化浏览网络“的程序,或者说是一种网络机器人。
爬虫被广泛用于互联网搜索引擎或其他类似网站,以获取或更新这些网站的内容和检索方式。它们可以自动采集所有其能够访问到的页面内容,以供搜索引擎做进一步处理(分检整理下载的页面),而使得用户能更快的检索到他们需要的信息。
通俗的讲,就是把你手动打开窗口,输入数据等等操作用程序代替。用程序替你获取你想要的信息,这就是网络爬虫
1.2 爬虫应用
1.2.1 搜索引擎
爬虫程序可以为搜索引擎系统爬取网络资源,用户可以通过搜索引擎搜索网络上一切所需要的资源。搜索引擎是一套非常庞大且精密的算法系统,搜索的准确性,高效性等都对搜索系统有很高的要求。
1.2.2 数据挖掘
爬虫除了用来做搜索外,还可以做非常多的工作,可以说爬虫现在在互联网项目中应用的非常广泛。
互联网项目通过爬取相关数据主要进行数据分析,获取价值数据。那么爬虫具体可以做那么分析,下面可以简单做一个简单了解:
1) 股票分析---预测股市
2) 社会学方面统计预测
a) 情绪地图
b) 饮食分布图
c) 票房分析预测
d) 机场实时流量
e) 公交系统实时线路
f) 火车票实时销售统计
3) App下载量分析
2. 爬虫原理
2.1 爬虫目的
一般来讲对我们而言需要抓取的是某个网站或者某个应用的内容,提取有用的价值,进行数据分析。
2.2 爬虫框架设计
为了开发的方便,也可以使用爬虫框架来开发项目中的爬虫:
一个通用的网络爬虫的框架如图所示:
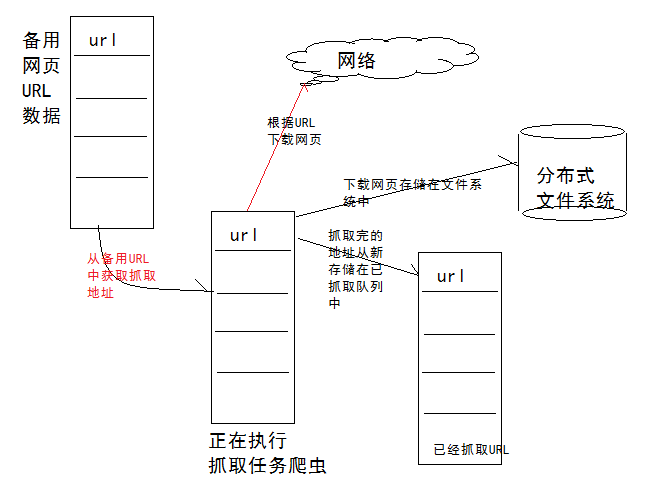
网络爬虫的基本工作流程如下:
1.首先选取一部分精心挑选的种子URL;
2.将这些URL放入待抓取URL队列;
3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的网页下载下来,存储进已下载网页库中。此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放入待抓取URL队列,从而进入下一个循环














 7472
7472










 暂无认证
暂无认证







 到【灌水乐园】发言
到【灌水乐园】发言










qq_52050276: 请问,readAll( )是有极限的吧,过大的文件应该怎样控制每次的读取长度,然后第二次可以继续往后读取呢?
sky_163: 先别格式化,可以用 WishRecy找回资料。
ღ涵成雨阳iོꦿ࿐: SyntaxError: Unexpected end of input报错了,解析不了wxss
java持续实践: 大佬2019年转行了?
weixin_51555558: 谢谢 困惑了好久了 每次都一个个试