排序算法 时间、空间复杂度

 最新推荐文章于 2023-11-13 22:20:24 发布
最新推荐文章于 2023-11-13 22:20:24 发布
 阅读量110
阅读量110
 收藏
1
收藏
1


 点赞数
点赞数
概念
1、时间复杂度
(1)时间频度 一个算法执行所耗费的时间,从理论上是不能算出来的,必须上机运行测试才能知道。但我们不可能也没有必要对每个算法都上机测试,只需知道哪个算法花费的时间多,哪个算法花费的时间少就可以了。并且一个算法花费的时间与算法中语句的执行次数成正比例,哪个算法中语句执行次数多,它花费时间就多。一个算法中的语句执行次数称为语句频度或时间频度, 记为T(n)。
(2)时间复杂度 在刚才提到的时间频度中,n称为问题的规模,当n不断变化时,时间频度T(n)也会不断变化。但有时我们想知道它变化时呈现什么规律。为此,我们引入时间复杂度概念。 一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,用T(n)表示,若有某个辅助函数f(n),使得当n趋近于无穷大时,T(n)/f(n)的极限值为不等于零的常数,则称f(n)是T(n)的同数量级函数。记作T(n)=O(f(n)),称O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
在各种不同算法中,若算法中语句执行次数为一个常数,则时间复杂度为O(1),不发生交换时间复杂度为O(0)。另外,在时间频度不相同时,时间复杂度有可能相同,如T(n)=n2+3n+4与T(n)=4n2+2n+1它们的频度不同,但时间复杂度相同,都为O(n2)。
常见的时间复杂度,按数量级递增排列依次为:常数阶O(1)、对数阶O(log2n)、线性阶O(n)、线性对数阶O(nlog2n)、平方阶O(n^2)、立方阶O(n^3)、k次方阶O(n^k)、指数阶O(2^n)。随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低。
2、空间复杂度
空间复杂度(Space Complexity)是对一个算法在运行过程中临时占用存储空间大小的量度。一个算法在计算机存储器上所占用的存储空间,包括存储算法本身所占用的存储空间,算法的输入输出数据所占用的存储空间和算法在运行过程中临时占用的存储空间这三个方面。算法的输入输出数据所占用的存储空间是由要解决的问题决定的,是通过参数表由调用函数传递而来的,它不随本算法的不同而改变。存储算法本身所占用的存储空间与算法书写的长短成正比,要压缩这方面的存储空间,就必须编写出较短的算法。
空间复杂度并不是指所有的数据所占用的空间,而是使用的辅助空间的大小,比如两个矩阵的运算,在中间设置了一个中间矩阵来保存一些数据,这些空间叫做空间复杂度。空间复杂度的运算非常麻烦,一般简单的算法空间复杂度都是O(1),比较复杂的会告知空间复杂度,记住就好了。
3、算法的稳定性
百度解释:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,ri=rj,且ri在rj之前,而在排序后的序列中,ri仍在rj之前,则称这种排序算法是稳定的;否则称为不稳定的。
稳定意思是说原本键值一样的元素排序后相对位置不变,学习的时候,可能编的程序里面要排序的元素都是简单类型,实际上真正使用的时候,可能是对一个复杂类型的数组排序,而排序的键实际上只是这个元素中的一个属性,对于一个简单类型,数字值就是其全部意义,即使交换了也看不出什么不同。。。但是对于复杂的类型,交换的话可能就会使原本不应该交换的元素交换了。。
比如,一个“学生”数组,按照年龄排序,“学生”这个对象不仅含有“年龄”,还有其他很多属性,稳定的排序会保证比较时,如果两个学生年龄相同,一定不交换。
排序算法,是程序开发中最基本的一项任务。教科课上讲的排序算法大概有7-8种,快速排序(QuickSort)是使用最广泛的一种基于比较排序的算法。
一 快速排序
1. 快速排序算法介绍
快速排序是由东尼·霍尔所发展的一种排序算法。在平均状况下,排序 n 个项目要Ο(n log n)次比较。在最坏状况下则需要Ο(n^2)次比较,但这种状况并不常见。事实上,快速排序通常明显比其他Ο(n log n) 算法更快,因为它的内部循环(inner loop)可以在大部分的架构上很有效率地被实现出来。快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
快速排序的思想很简单,排序过程只需要三步:
1. 从数列中挑出一个元素,称为 “基准”(pivot)
2. 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
3. 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
摘自: http://zh.wikipedia.org/wiki/快速排序
2. 快速排序算法演示
举例来说,现在有一组数据[9,23,12,11,43,54,43,2,12,66],怎么对其按从小到大顺序排序呢?

Step1,选择第一个元素9作为分隔值,把小于9的数字放左边,大于等于9的数字放右边。原来的一个数组就被分成了3个部分,左边+分隔值+右边=[2]+9+[23 12 11 43 54 43 12 66]
Step2, 选择Step1数组左边的第一元素2作为分隔值,左边只有一个元素,左边排序完成。选择Step1数组右边的第一个元素23作为分隔值,把小于23的数字放左边,大于等于23的数字放右边,得到[ 12 11 12 ] 23 [ 43 54 43 66 ]。
Step3,选择Step2数组以23分隔的左边第一个元素12作为分隔值,把小于12的数字放左边,大于等于12的数字放右边,得到[ 11 ] 12 [ 12 ]。选择Step2数组以23分隔的左边第一个元素43作为分割值,把小于43的数字放左边,大于等于43的数字右边,得到 [] 43 [ 54 43 66 ]。
Step4,对Step3数组以12分隔的左右两边进行排序,都只有一个元素,排序完成。对Step3数组以43分隔左右两进行排序,左边无元素,右边第一个元素54作为分隔值,得到[ 43 ] 54 [ 66 ]。
Step5,对Step4数组以54分隔的左右两边进行排序,都只有一个元素,排序完成。
最后,后整个数组拼接在一起就得到排序结果:[2 9 11 12 12 23 43 43 54 66 ]
我们看到快速排序,其实就是一种分而治之的办法。网上还有很多快速排序的优化方法,可以尽一步减少时间复杂度和空间复杂度的开销。
原文链接: http://blog.fens.me/algorithm-quicksort-nodejs/
二 桶排序
1. 桶排序介绍
桶排序(Bucket sort)是一种基于计数的排序算法,工作的原理是将数据分到有限数量的桶子里,然后每个桶再分别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。当要被排序的数据内的数值是均匀分配的时候,桶排序时间复杂度为O(n)。桶排序不同于快速排序,并不是比较排序,不受到时间复杂度 O(nlogn) 下限的影响。
桶排序按下面4步进行:
1. 设置固定数量的空桶。
2. 把数据放到对应的桶中。
3. 对每个不为空的桶中数据进行排序。
4. 拼接从不为空的桶中数据,得到结果。
桶排序,主要适用于小范围整数数据,且独立均匀分布,可以计算的数据量很大,而且符合线性期望时间。
2. 桶排序算法演示
举例来说,现在有一组数据[7, 36, 65, 56, 33, 60, 110, 42, 42, 94, 59, 22, 83, 84, 63, 77, 67, 101],怎么对其按从小到大顺序排序呢?
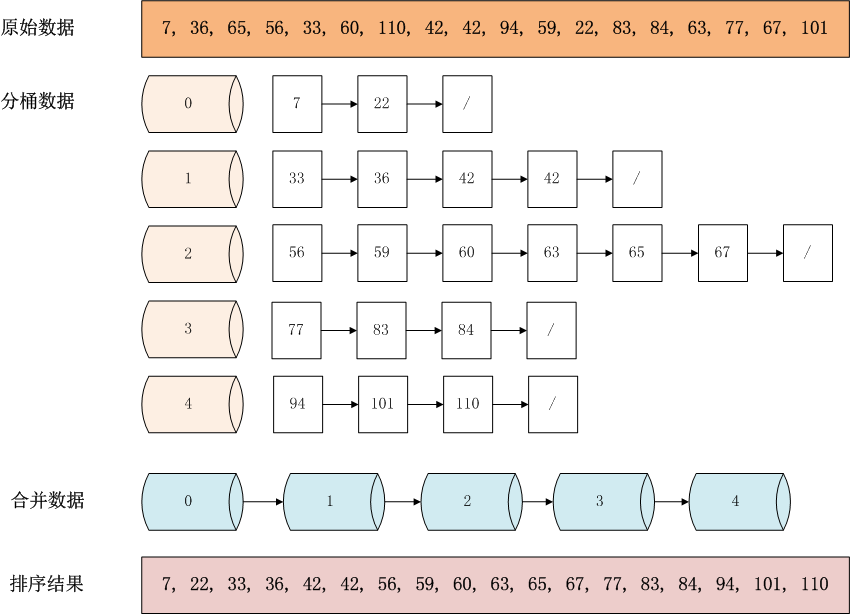
操作步骤说明:
1. 设置桶的数量为5个空桶,找到最大值110,最小值7,每个桶的范围20.8=(110-7+1)/5 。
2. 遍历原始数据,以链表结构,放到对应的桶中。数字7,桶索引值为0,计算公式为floor((7 – 7) / 20.8), 数字36,桶索引值为1,计算公式floor((36 – 7) / 20.8)。
3. 当向同一个索引的桶,第二次插入数据时,判断桶中已存在的数字与新插入数字的大小,按照左到右,从小到大的顺序插入。如:索引为2的桶,在插入63时,桶中已存在4个数字56,59,60,65,则数字63,插入到65的左边。
4. 合并非空的桶,按从左到右的顺序合并0,1,2,3,4桶。
5. 得到桶排序的结构
原文链接: http://blog.fens.me/algorithm-bucketsort-nodejs/
转载于:https://blog.51cto.com/tianxingzhe/1651182














 1349
1349










 暂无认证
暂无认证







 到【灌水乐园】发言
到【灌水乐园】发言










2301_81273039: 想进群
qq_62115839: 有设置密码但是先决条件还显示红感叹号怎么回事
comtumacy: 好像这样的模式不能把返回值一层一层传出去,传进去的参数也没啥大用处
爆爆米花.: 问一下可以代做jsp吗
0深水蓝0: up住真的写的好详细啊,小弟请教疑问,为什么我从16bit的CR2文件,在camera raw里面导出成dng格式之后,dng文件是14bit的?